
【Jina Reader API】Webページをマークダウンに変換!LLMに記事のリライトをさせてみた

- Jina AIは様々な便利ツールをAPIとして公開している
- Jina Reader APIは任意のWebページをマークダウンに変換してくれる
Jina Reader APIは、指定したURLからウェブコンテンツを抽出し、大規模言語モデル(LLM)が処理しやすいクリーンな形式に変換します。操作は非常に簡単で、URLを1つ入力するだけで主要な情報が抽出され、不要なHTMLタグやスクリプトが除去された質の高いデータを得ることが可能です。
本記事は、マルチモーダルAI をめざしている Jina AI の学習リソース生成機能の Jina Reader API について調べてみました。
最新の情報を効率的に収集・整理し、AIに供給したいと考えている方は必見です。ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Jina Reader APIの概要
ざっくりいうと、任意のウェブコンテンツをLLMが学習しやすい形式に変換するためのツールです。
ウェブコンテンツを効率的に抽出し、大規模言語モデル(LLM)が利用できる形式に変換するための強力なツールで、特に、開発者や研究者が最新の情報をAIに供給する際に役立ちます。
このAPIは、特定のURLからコンテンツを取得し、不要な要素を除去した後、クリーンで読みやすいテキストを生成します。これにより、LLMがより正確で信頼性の高い応答を生成することが可能です。
Jina Reader APIの機能は以下です。
- 簡単なURL指定: ユーザーは処理したいウェブページのURLを指定するだけで、APIが自動的にコンテンツを取得します。URLの前に「https://r.jina.ai/」を追加することで、簡単にアクセスできます。
- コンテンツのクリーンアップ: APIは、取得したコンテンツからHTMLタグやスクリプトを取り除き、テキストの質を向上させます。これにより、LLMが処理しやすい形式に変換されます。
- ストリーミングモード: 大規模または動的なウェブページに対しては、ストリーミングモードを利用することで、コンテンツが利用可能になると同時に処理を開始できます。これにより、初回のレスポンス時間を短縮し、ユーザー体験を向上させます。
- PDFサポート: Jina Reader APIは、PDFファイルのURLを指定することで、その内容を迅速に解析し、テキストとして抽出することも可能です。これにより、さまざまな形式の情報を扱うことができます。
このAPIは、特に情報をリアルタイムで取得し、LLMに学習させる様なプロジェクトでは非常に有用ですね。例えば、最新のニュース記事や研究論文を迅速に取得し、AIモデルに供給することで、常に最新の情報を基にした応答を生成することができます。
Jina Reader APIは、開発者が自分のアプリケーションに組み込むことで、情報検索やデータ処理の効率を大幅に向上させることが可能です。特に、AIを活用したアプリケーションやサービスを構築する時に、データの質や、ユーザー目線の情報を生成できるとのこと!
繰り返しにはなりますが、Jina Reader APIは、ウェブコンテンツを効果的に処理し、LLMに適した形式に変換するための重要なツールで、新しい可能性がありそうです。
Jina Reader-LMとの違い
Jina Reader APIとJina Reader-LMは、どちらもJina AIが提供するツールですが、主な目的と機能においていくつかの重要な違いがあります。
Jina Reader APIの特徴
Jina Reader APIは、ウェブページのURLを指定することで、そのページから主要なコンテンツを抽出し、クリーンなテキスト形式に変換することを目的としています。
このAPIは、HTMLから不要な要素を取り除き、LLM(大規模言語モデル)が処理しやすい形式に整形します。特に、ストリーミングモードを利用することで、大規模なウェブページでも迅速にデータを取得できる点が特徴です。
Jina Reader-LMの特徴
一方、Jina Reader-LMは、HTMLからMarkdown形式への変換に特化した小型言語モデルです。Reader-LMは、ノイズの多いHTMLを自動的にクリーンアップし、構造化されたMarkdown形式に変換する能力を持っています。
これにより、広告やスクリプトなどの不要な要素を排除し、必要な情報のみを保持することができます。Reader-LMは、特に長いコンテキストを処理できる能力を持ち、256Kトークンまで対応可能です。
主な違い
- 機能の焦点: Jina Reader APIは、主にデータの抽出と整形に焦点を当てているのに対し、Reader-LMはHTMLからMarkdownへの変換に特化しています。
- 処理方法: Jina Reader APIは、ルールや正規表現を使用してコンテンツを処理しますが、Reader-LMは機械学習モデルを利用して、より高度なテキスト処理を行います。
- 出力形式: Jina Reader APIは一般的なテキスト形式を出力しますが、Reader-LMはMarkdown形式に特化しているため、特定の用途においてより適した出力が得られます。
このように、Jina Reader APIとJina Reader-LMは、それぞれ異なるニーズに応じた機能を提供しており、ユーザーは目的に応じて適切なツールを選択することができます。
Jina Reader APIの料金
Jina Reader APIの料金体系は非常に柔軟で、ユーザーにとって利用しやすい設計になっています。以下に、主な料金のポイントをまとめます。
| プラン | 特徴 | 料金 | トークン | その他 |
|---|---|---|---|---|
| 無料プラン | 基本的な利用に最適 | APIキーなし:1分あたり20リクエスト<br>APIキーあり:1分あたり200リクエスト | 初回登録時:1Mトークン無料 | 特定のレート制限あり |
| 有料プラン(拡張プラン) | 大規模な利用やビジネス用途に最適 | リクエスト数無制限(プランによる) | 利用量に応じて変動 | 詳細は公式サイトで確認 |
| トークン | リクエストごとに消費 | 初回登録時:1Mトークン無料 | 超過分は追加料金 | 効率的な利用が求められる |
なお、HTMLをMarkdownに変換してくれるJinaのAPIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

注意点
Jina Reader APIを利用する際には、いくつかの注意点があります。以下に主なポイントを挙げます。
1. レート制限
Jina Reader APIにはレート制限が設けられています。無料プランでは、APIキーなしでの利用は1分あたり20リクエスト、APIキーを使用することで1分あたり200リクエストまで増加します。
これを超えるリクエストを行うと、エラーが返されるため、利用計画を立てる際にはこの制限を考慮する必要があります。
2. データの正確性
APIが抽出するデータの正確性は、元のウェブページの構造や内容に依存します。特に、動的に生成されるコンテンツや複雑なHTML構造を持つページでは、期待通りの結果が得られない場合があります。
したがって、重要なデータを扱う場合は、抽出結果を必ず確認することが推奨されます。
3. APIキーの管理
APIキーは、サービスへのアクセスを制御する重要な要素です。APIキーが漏洩すると、不正利用される可能性があるため、適切に管理することが重要です。
また、APIキーを使用する際には、セキュリティ対策を講じることが求められます。
4. 利用規約の遵守
Jina Reader APIを利用する際は、利用規約を遵守する必要があります。
特に、商用利用やデータの再配布に関しては、規約に明記された条件を確認し、適切に対応することが求められます。これに違反すると、サービスの利用が制限される可能性があります。
5. サポート体制の確認
APIの利用に関して問題が発生した場合、サポート体制が整っているかを確認しておくことが重要です。
特に、技術的なトラブルや不具合が発生した際に迅速に対応できるかどうかは、プロジェクトの進行に大きな影響を与える可能性があります。
これらの注意点を考慮しながら、Jina Reader APIを効果的に活用することで、より良い結果を得ることができるでしょう。


Jina Reader APIの使い方
概要でも記載のとおりJina Reader APIの使い方は下記のとおりとてもシンプルです。
特別な技術的知識がなくても簡単に利用できます。以下に、基本的な手順を説明します。
1. URLの準備
まず、処理したいウェブページのURLを用意します。例えば、https://example.comのような形式です。
2. APIの呼び出し
Jina Reader APIを利用するには、URLの前にhttps://r.jina.ai/を追加します。これにより、指定したURLのコンテンツを取得するリクエストを作成します。具体的には、以下のようにURLを構成します。
https://r.jina.ai/https://example.com
このURLにアクセスすることで、Jina Reader APIが指定されたウェブページのコンテンツを処理し、LLM(大規模言語モデル)に適した形式に変換します。
3. レスポンスの確認
APIにリクエストを送信すると、レスポンスとしてクリーンなテキストが返されます。このテキストは、元のウェブページの主要な情報を保持しており、HTMLタグやスクリプトなどの不要な要素は除去されています。
レスポンスは通常、Markdown形式で提供されるため、他のアプリケーションやシステムに簡単に統合できます。
4. ストリーミングモードの利用(オプション)
大規模なウェブページや動的なコンテンツを扱う場合、ストリーミングモードを利用することも可能です。このモードを有効にするには、リクエストヘッダにAccept: text/event-streamを設定します。
これにより、コンテンツが利用可能になると同時に処理を開始し、初回のレスポンス時間を短縮できます。
5. JSON出力の利用(オプション)
APIはJSON形式での出力もサポートしています。
JSON出力を希望する場合は、リクエストヘッダにAccept: application/jsonを設定します。これにより、URL、タイトル、コンテンツのフィールドを含む構造化されたデータが得られます。
https://r.jina.ai/のサンプルコード
curl -X GET "https://r.jina.ai/YOUR_URL" -H "Authorization: Bearer YOUR_API_KEY"説明: YOUR_URLには処理したいウェブページのURLを、YOUR_API_KEYには有効なAPIキーを入力します。
https://s.jina.ai/のサンプルコード
curl -X GET "https://s.jina.ai/YOUR_SEARCH_QUERY" -H "Authorization: Bearer YOUR_API_KEY"説明: YOUR_SEARCH_QUERYには検索したいキーワードを、YOUR_API_KEYには有効なAPIキーを入力します。
https://r.jina.ai/とGPTを使ってWEEL記事をリライトしてみた
ターゲットURLに対してhttps://r.jina.ai/ を使ってコンテンツテキストの抽出します。
前述のとおりターゲットURLのまえに「https://r.jina.ai/ 」をつけてアクセスするだけでHTMLタグが外されて、テキストコンテンツを抽出する事もできますが、今回のワークフローは
「Pythonでhttps://r.jina.ai/→マークダウン→GPT or Claudeに入力し、リライトさせる→リライト案を出力」としました。
ちなみにリライト対象のターゲットURLはWEELのサイトの下記にしています。
https://weel.co.jp/media/security-risk
まず、r.jina のAPIを触るための認証keyとPythoのサンプルコードを https://jina.ai/ のサイトから取得します。
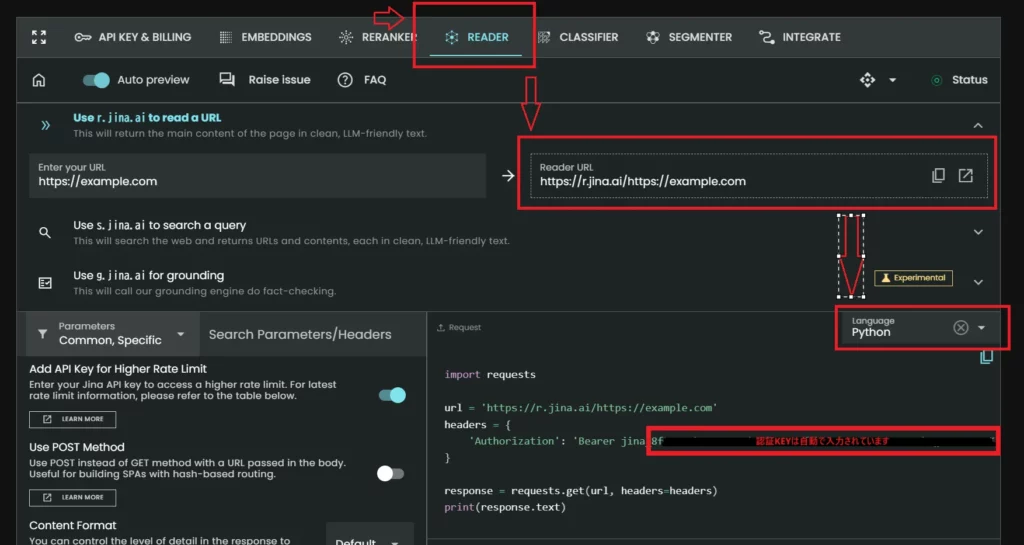
APIの認証keyは自動で入力されていました。対象のPythonコードをコピーして、Claudeに「このコードを使用して、マークダウン形式で出力するPythonコードを生成してください」とお願いすると以下のコードが生成されるので、xx.pyで保存します。
出力されたコードはこちら
import requests
from datetime import datetime
import os
def get_rewritten_content(url):
"""
Jina AIのリライトAPIを使用してウェブページのコンテンツを取得し、ファイルに保存する
Args:
url (str): リライトしたいウェブページのURL
Returns:
tuple: (保存したファイルパス, 取得したコンテンツ)
"""
# URLを正しい形式に変換
jina_url = f'https://r.jina.ai/{url}'
# ヘッダーにAPIキーを設定
headers = {
'Authorization': 'Bearer jina_xxxxxxx'
}
try:
# APIリクエストを実行
response = requests.get(jina_url, headers=headers)
response.raise_for_status() # エラーチェック
# 現在の日時を取得してファイル名に使用
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# ファイル名を生成(カレントディレクトリに保存)
filename = f'jina_rewrite_{timestamp}.md'
# ファイルに保存
with open(filename, 'w', encoding='utf-8') as f:
f.write(response.text)
print(f'ファイルを保存しました: {os.path.abspath(filename)}')
return filename, response.text
except requests.exceptions.RequestException as e:
error_msg = f"エラーが発生しました: {str(e)}"
print(error_msg)
return None, error_msg
# リライトしたいURLを指定して実行
target_url = 'https://weel.co.jp/media/security-risk'
filename, content = get_rewritten_content(target_url)
if filename:
print(f'\n保存されたファイルの内容:')
print('-' * 50)
print(content)保存されたxx.pyをコマンドプロンプトから実行すると、同じディレクトリ内にマークダウン形式のxx.mdファイルが生成されます。

生成されたxx.mdファイルをChatGPTに添付して、「添付した「jina_rewrite_20241124_121750.md」ファイルを 誤字脱字や文章の不自然さ、内容の齟齬のチェックの観点で、考えて、考えて、考えて校正し、校正結果をマークダウン形式で生成してください。」しつこいくらいに考えてもらうと精度が上がります(笑)
が、結果は校正の指摘が生成されてしまったので、「校正結果をもとに「jina_rewrite_20241124_121750.md」をリライトしてください」とお願いしたところ想定の結果となりました。
リライトの結果はこちら
以下は、校正結果に基づいてリライトした内容です。校正案を適用し、読みやすさや一貫性を向上させています。
—
# 生成AIのセキュリティリスクとは?発生事例や課題、対策を徹底解説
**みなさんは、生成AIに伴うセキュリティリスクをご存じですか?**
生成AIには、**機密情報の漏洩**、[**プロンプトインジェクション**](https://weel.co.jp/media/chatgpt-jailbreak-prompt)、[**ハルシネーション**](https://weel.co.jp/media/hallucination)、**ディープフェイク**など、様々なリスクが存在します。これらのリスクを無視してAIを活用すると、企業の信頼が損なわれたり、法的問題に発展したりする可能性があります。
実際に、社内の機密情報がAIを通じて外部に漏洩した事例も報告されています。
本記事では、生成AIに伴うセキュリティリスク、対策方法、実際の情報漏洩事例を詳しく解説します。この記事を通じて、生成AIを安全に利用するための知識を深めましょう。
ぜひ、最後までご覧ください。
—
## 目次
1. [生成AI活用に伴うセキュリティリスクとは](#生成AI活用に伴うセキュリティリスクとは)
2. [生成AIで発生したセキュリティリスクの事例4選](#生成AIで発生したセキュリティリスクの事例4選)
3. [企業が直面する生成AIの課題](#企業が直面する生成AIの課題)
4. [生成AI活用におけるセキュリティリスク対策](#生成AI活用におけるセキュリティリスク対策)
5. [生成AIに伴うセキュリティリスクを理解して活用しよう!](#生成AIに伴うセキュリティリスクを理解して活用しよう)
—
## 生成AI活用に伴うセキュリティリスクとは

生成AIの活用には多くの利点がありますが、**IPA(情報処理推進機構)**が指摘するように、セキュリティリスクも大きな課題です。生成AIの活用に伴う主なリスクとして、以下の5つが挙げられます。
– **機密情報の流出(著作権、商標権などの侵害)**
– **プロンプトインジェクション**
– **ハルシネーション**
– **ディープフェイク**
– **なりすましメールなどへの悪用**
これらのリスクを理解し、適切な対策を講じることで、安全に生成AIを活用できます。
—
### 1. 機密情報の流出
生成AIが**膨大なデータを学習**している中には、機密情報が含まれる可能性があります。例えば、企業が誤って内部の機密データをAIに入力すると、その情報が外部に漏洩するリスクがあります。
**具体例:**
オープンソースの生成AIモデルを使用する場合、インターネット上に公開されているデータを基に学習しているため、意図せず機密情報が流出する可能性があります。これは、**法的リスクや著作権・商標権の侵害**に発展することがあります。
—
### 2. プロンプトインジェクション
プロンプトインジェクションとは、特定の入力(プロンプト)を用いて、**AIに意図しない行動や誤った回答を引き起こさせる**リスクを指します。悪意のあるユーザーがAIを操作し、不正確な情報を生成させることで、企業の信頼性が損なわれる可能性があります。
**解決策:**
– AIの回答を逐一検証する体制を構築する。
– 公開されているAIシステムへのアクセス制限を強化する。
—
### 3. ハルシネーション
ハルシネーションとは、生成AIが**事実と異なる情報や存在しないデータを生成**してしまう現象です。この問題は、AIが誤った情報を生成することで、企業の意思決定や信頼性に悪影響を及ぼします。
—
### 4. ディープフェイク
ディープフェイクは、AIを使って作られた**極めてリアルな偽の映像や音声**を指します。この技術は、詐欺や偽情報の拡散、名誉毀損といった問題を引き起こす可能性があります。
**具体例:**
ウクライナのゼレンスキー大統領が投降を呼びかける偽動画が作成されたことが報告されています。
—
### 5. なりすましメールなどへの悪用
生成AIは、**より巧妙で説得力のあるフィッシングメールを作成する**ためにも悪用されます。このリスクにより、企業のセキュリティが脅かされるケースが増加しています。
—
## 生成AIで発生したセキュリティリスクの事例4選
以下は、生成AIの利用で実際に発生したセキュリティリスクの事例です。
1. **サムスン電子:** 社内データの漏洩を受け、従業員のAI利用を禁止。
2. **ニューヨークタイムズ:** 著作権侵害を理由にOpenAIを提訴。
3. **Group-IB:** ChatGPTアカウント情報が闇市場で取引される。
4. **Getty Images:** 画像生成AI「Stable Diffusion」を著作権侵害で提訴。
—
## 生成AI活用におけるセキュリティリスク対策
生成AIを安全に活用するためには、以下の対策が重要です。
1. **生成AIセキュリティガイドラインを参考にしたソリューション策定**
2. **従業員へのAI教育の実施**
3. **機密情報をAIで扱わない**
4. **オプトアウト機能の活用**
5. **ガバナンス体制の構築**
6. **定期的なアップデート情報の確認**
—
## 結論
生成AIの活用には多くの利点がありますが、それに伴うセキュリティリスクへの対策は欠かせません。具体的なリスクとその対応策を理解し、安全で持続可能な運用を目指しましょう。
株式会社WEELは、生成AIの導入や活用に関するサポートを提供しています。まずは[無料相談](https://weel.co.jp/company/contact/)からご連絡ください!
—
以上がリライト内容です。必要に応じてさらに調整を加えることも可能です。
以上で、「WEEL記事をリライト」が出来ました。
https://s.jina.ai/を使って最新ニュースを取得してみた
Jina AIのツールを用いてニュースを取得するコードを以下のように記述します(仮の例)
コードはこちら
import requests
# Jina AIのエンドポイント(例: ニュース検索APIのURL)
url = "https://api.s.jina.ai/v1/news" # 実際のエンドポイントは公式サイトで確認
headers = {
"Authorization": "Bearer YOUR_API_KEY", # APIキーを入力
"Content-Type": "application/json"
}
# クエリを作成(例: 最新ニュースを取得)
data = {
"query": "latest news",
"filters": {"language": "en", "category": "technology"}
}
response = requests.post(url, headers=headers, json=data)
# レスポンスの表示
if response.status_code == 200:
news = response.json()
print("取得したニュース:", news)
else:
print("エラー:", response.status_code, response.text)
検索ツールを使った「最新ニュースを取得」に関してはAPIキーの取得やソフトのインストールなど必要なようで時間的な都合により次回紹介させてください。言ってしまえば筆者のスキル不足が原因です。今後の課題ですね。
なお、エンジニア専用のGPTsについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
Jina Reader APIは、ウェブコンテンツを効率的に抽出し、大規模言語モデル(LLM)に適した形式に変換するためのツールです。
- 簡単な使用法: URLの前にhttps://r.jina.ai/を追加するだけで、指定したウェブページの主要なコンテンツを抽出できます。
- クリーンなデータ抽出: 不要なHTML要素やスクリプトを取り除き、クリーンで構造化されたデータを提供します。これにより、LLMがより正確に情報を処理できます。
- リアルタイムデータアクセス: ユーザーのクエリに基づいて、最新の情報をリアルタイムで取得することが可能です。
- PDFと画像のサポート: ウェブページだけでなく、PDFファイルや画像からもコンテンツを抽出し、画像には自動的にキャプションを付ける機能があります。
- スケーラビリティ: 高いリクエスト処理能力を持ち、小規模から大規模なアプリケーションまで対応可能です。
- ユーザーフレンドリー: APIキーを取得するだけで簡単に利用開始でき、技術的な知識が少ない開発者でも扱いやすい設計です。
このように、Jina Reader APIは、ウェブ情報をLLMにフィードする際の重要なツールであり、開発者やデータサイエンティストにとって非常に有用です。
最後に
いかがだったでしょうか?
Jina Reader APIなどのを使えば、Web上のリサーチや情報取得など、ほんの数行コードを書くだけで実現します。生成AIを安全に活用するための具体策や事例を基に、貴社のプロジェクトに最適な導入をしませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

