
新世代の生成AIモデル「Liquid Foundation Models」登場!効率性と性能を徹底解説
Liquid AI は、マサチューセッツ工科大学(MIT)のスピンオフ企業で、あらゆる規模で強力で効率的な汎用AIシステムを構築することを目指しており、ついに2024年9月30日、Liquid Foundation Models (LFM) と呼ばれる新しい種類の生成AIモデルをリリースしました!LFMは従来の生成AIに比べて非常に長い、32,000トークンを提供可能。
本記事では、Liquid Foundation Models (LFM) について従来の生成AIと何が異なるのか、詳しく解説しますので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Liquid AIの概要
Liquid AIは、あらゆる規模で対応可能かつ効率的な汎用AIシステムを構築することを使命とする、MITから生まれたFoundation Models企業です。
Foundation Modelsとは、特に大規模なデータセットを用いて事前に学習されたAIモデルのことを指します。これらのモデルは、特定のタスクに限らず、さまざまなタスクに適応できる汎用的なモデルとして機能します。例えば、画像認識、自然言語処理、音声認識など、幅広い応用分野に対応可能。
Liquid AIは最初の生成AIモデルシリーズであるLiquid Foundation Models (LFM)を開発。LFMはあらゆる規模で最先端のパフォーマンスを実現しながら、メモリーフットプリントを小さく抑え、より効率的な推論を実現する、新世代の生成AIモデルです。
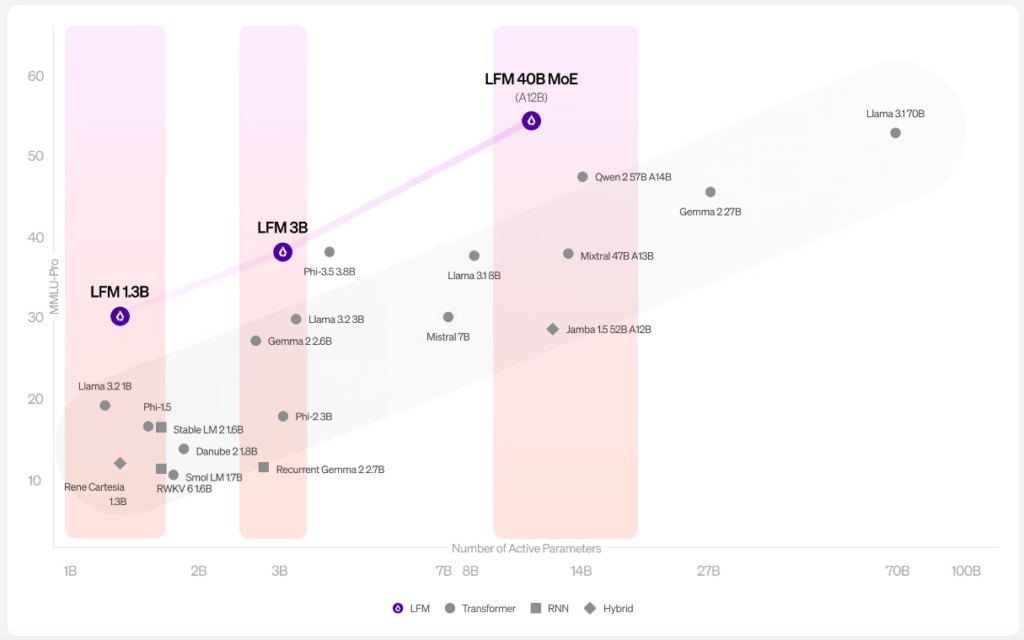
発表されたモデルは1B、3B、40Bの三種類。いずれも従来のTransfer modelと比較するとハイパフォーマンスであることがわかります。
LFMの特徴
Liquid AIによるとLFMは5つの特徴があると発表しています。
- 最先端のパフォーマンス
- 効率性
- 長いコンテキスト長
- 多様なタスクに対応
- 構造化されたアーキテクチャ
それぞれ解説します。
最先端のパフォーマンス
LFMは、1B、3B、40Bの各規模において、品質の面で高性能なパフォーマンスを達成。
例えば、LFM-1Bは、1Bカテゴリの様々なベンチマークで最高スコアを達成しており、この規模ではハイパフォーマンスのモデルです。
また、LFM-3Bは、7Bや13Bの旧世代のモデルよりも優れており、Phi-3.5-miniと同等のベンチマーク結果を残しながらも、サイズは18.4%小さく抑えられています。
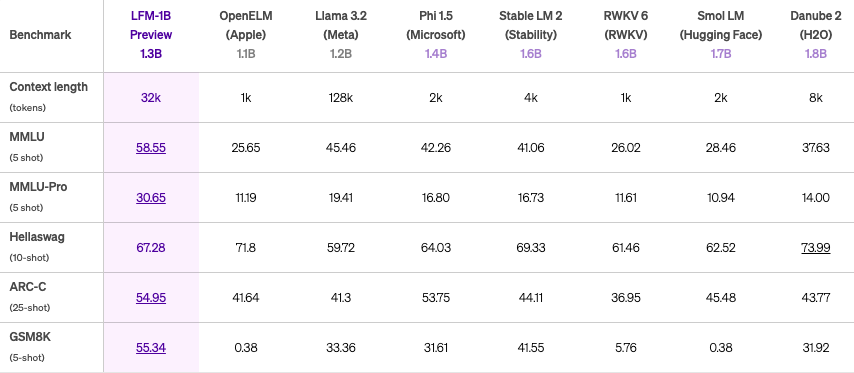
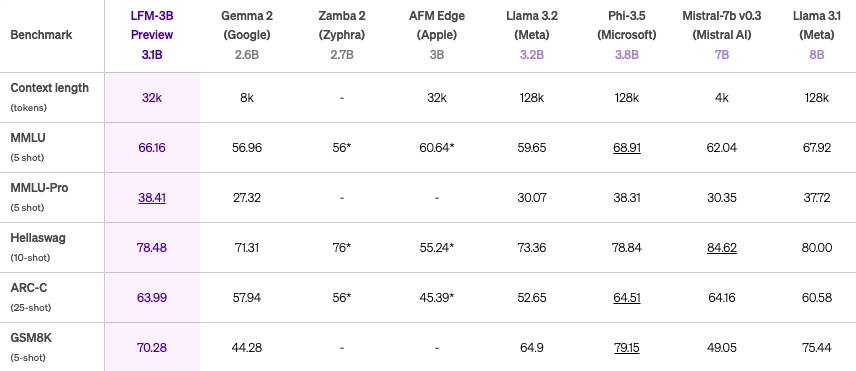
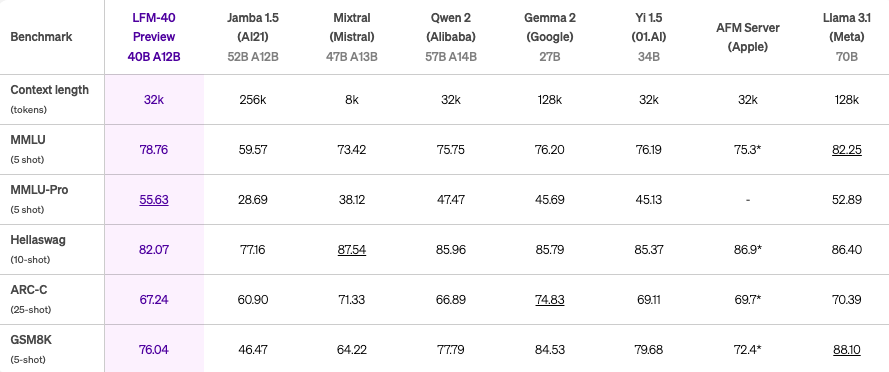
※上から1B、3B、40Bのベンチマーク
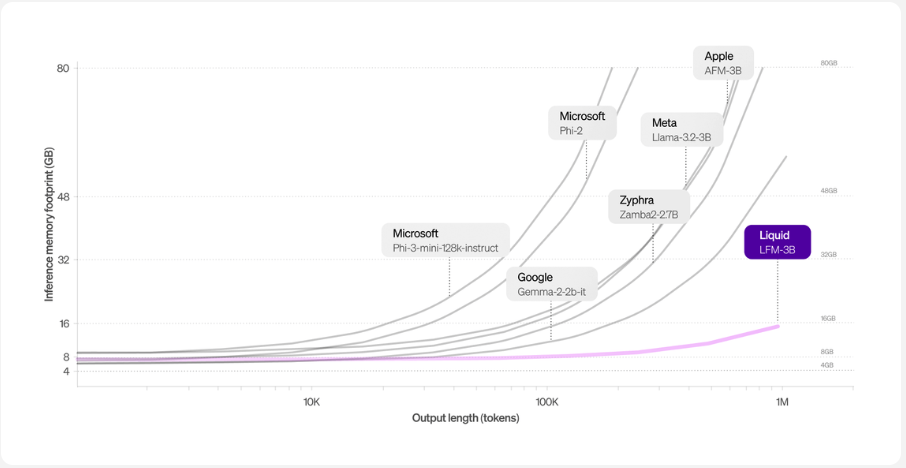
効率性
LFMは、Transformerアーキテクチャと比較してメモリーフットプリントが削減されています。これは、TransformerベースのLLMのKVキャッシュが入力シーケンスの長さに比例して増加する長い入力の場合に特に当てはまります。 例えば、他の3Bクラスのモデルと比較して、LFMは最小限のメモリーフットプリントを維持しています。
長いコンテキスト長
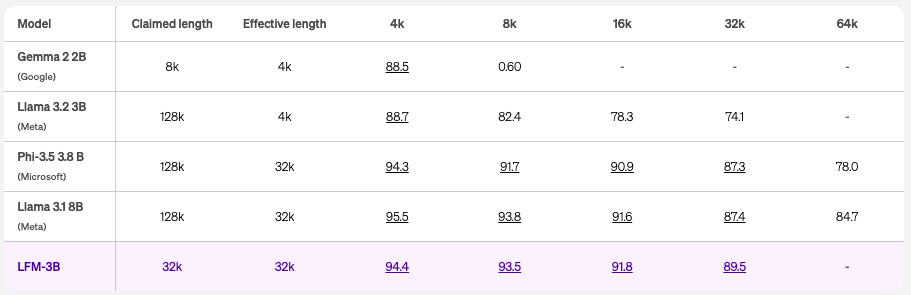
LFMは、32,000トークンのクラス最高のコンテキスト長を提供するように最適化されており、この規模における効率性の限界を押し上げています。
これは、RULERベンチマークによって確認されており、対応するスコアが85.6を超える場合、長さは「効果的」とされます。この非常に効率的なコンテキストウィンドウにより、エッジデバイスで初めて長文のタスクが可能になります。
開発者にとっては、ドキュメント分析や要約、コンテキストを認識したチャットボットとのより有意義なインタラクション、Retrieval Augmented Generation (RAG) のパフォーマンス向上など、アプリケーションへの応用も期待できます。
多様なタスクに対応
LFMは、汎用AIモデルとして、ビデオや音声、テキスト、時系列、信号など、あらゆる種類のシーケンシャルデータをモデル化するのに使用可能。
現在、LFMが対応している言語と内容は、一般的な知識、数学および論理的推論、効率的かつ効果的な長文タスクに優れています。また、英語を主要言語とし、スペイン語、フランス語、ドイツ語、中国語、アラビア語、日本語、韓国語の多言語機能も備えています。
構造化されたアーキテクチャ
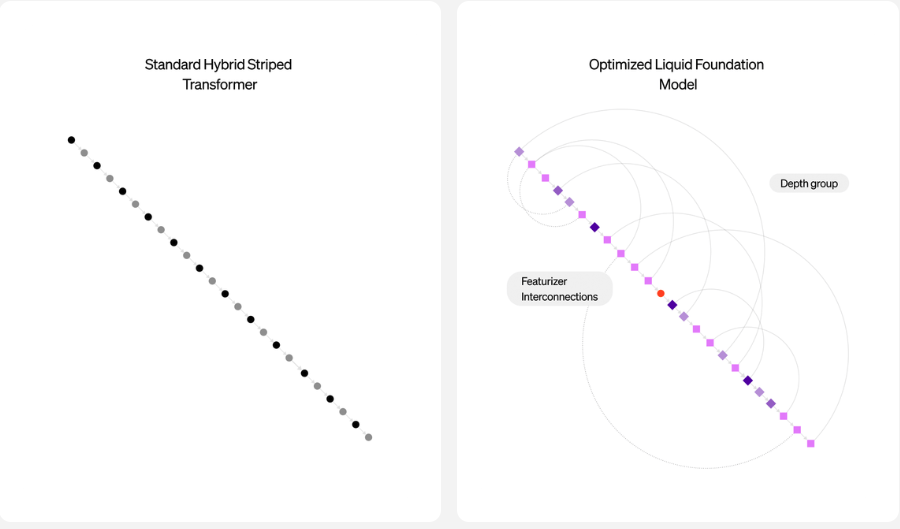
LFMは、動的システム、信号処理、数値線形代数の理論に深く根ざした計算ユニットを使用して構築された大規模ニューラルネットワークです。
LFMは構造化オペレーターで構成されており、アーキテクチャは制御されています。また、LFMは適応性があり、あらゆる規模のAIの基盤として機能します。
Liquid AIのライセンス
Liquid AIのライセンスはMITライセンスです。そのため、基本的には商用利用や改変、私的利用など全て可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、軽量化されたLlama3.2について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Liquid AIの使い方
LFM発表直後の2024/10/1時点では、Liquid Playground、Lambda Chat、Perplexity Labsでのみ使用可能です。近々Cerebras InferenceでLFMが使用できるようになる予定です。
いずれもLiquid AIのホームページから利用することができます。
Liquid AIのLFMは日本語にも対応しているのか検証してみた
Liquid AIのLFMは従来のTransferモデルに比べて性能が高いと報告されています。そこで実際にどれくらいの性能を有しているのか、検証してみました。
今回は日本語のタスクをプロンプトとして入力して、その答えを確認したいと思います。
プロンプトとして入力したのは次の2つです。
取引先に対して、アポイントメントのメールを作成してください。
あなたは、優秀なビジネスマンです。以下の内容をもとに、メールの返信内容を出力してください。
#受信したメール内容
○○様
お世話になっております。
お忙しいところ失礼いたします。
現在進行中の施策について情報共有したいことがあり、ミーティングをお願いできればと思っております。
ご都合の良い日時をお知らせいただけますと幸いです。
以下の時間帯で、ご都合が合う時間がございましたらご教示ください。
8/6(火): 10:00~18:00
8/7(水): 10:00~18:00
お忙しいところ恐縮ですが、何卒よろしくお願いいたします。
合わせて、ミーティングの際に使用させていただく資料も共有させていただきます。
お手すきの際にご確認いただけると幸いです。
#返信に含める内容
– 8月7日(水)17:00~18:00の日程が参加可能
– 資料がまとまっていてキレイであることを褒める
#条件
– 敬語を正確に使う
– 文章最後に電子署名を入れる
#出力
本文:
検証した動画は以下です。
生成結果を見ると、日本語タスクの性能はやや改善の余地があるかもしれません。まだ日本語に関するパフォーマンスの結果は報告されていませんが、公式ホームページには、日本語などの二次的な多言語能力を持つと明記されています。今後の改善に期待できそうです。
また、コーディングについても依頼をしましたが、コーディングはできないと言われてしまいました。が、少し情報の与え方を変えると、以下のようにコーディング内容を出力してくれます。
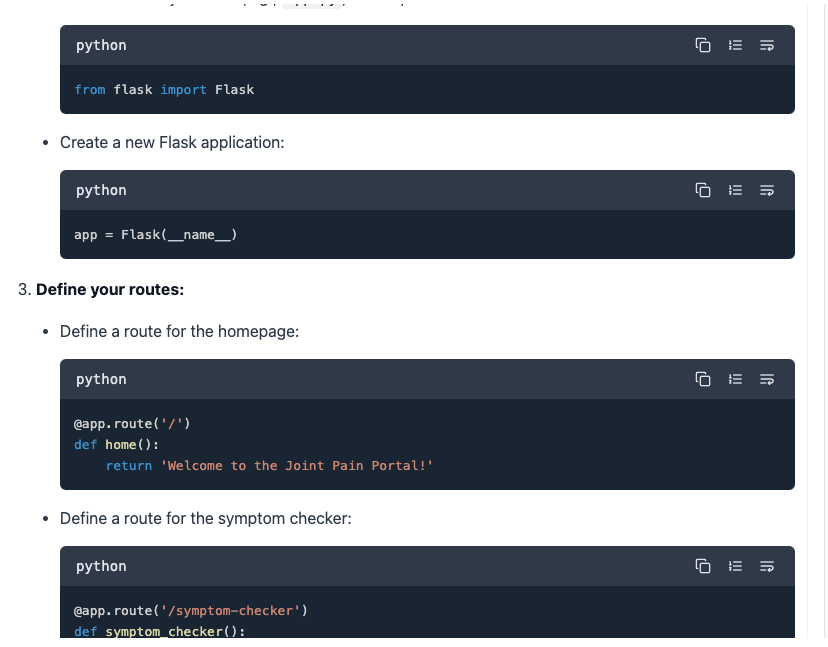
なお、オープンソースLLMの実力と具体的な使い方について詳しく知りたい方は、下記の記事を合わせてご確認ください。
LFMの活用例
LFMはメモリーフットプリントを小さく抑え、より効率的な推論が可能です。
今後、LFMは医療データの解析に特化したモデルとしても活用が期待されます。
例えば、電子カルテや画像診断データの大量データを解析し、病気の予測や診断の精度を向上させることができる可能性があります。
また、医療現場ではリアルタイムで患者のデータを分析し、医師が診断や治療方針を決定する際のサポートを行うAIアシスタントの開発が可能。LFMの効率的な推論とメモリ管理機能により、これまで扱いが難しかった大量の医療画像やテキストデータを効率的に処理し、医療現場に活用できるようになるかもしれません。
また、企業のカスタマーサポートにLFMを導入することで、ユーザーからの問い合わせに対する応答を精度の高いものにできる可能性もあります。
LFMは長いコンテキストを保持し、過去のやり取りや関連する情報を考慮に入れた精度の高いサポートが可能です。さらに、音声認識や自然言語生成を活用することで、電話やチャットでのサポートもスムーズに行えます。複雑な問い合わせにも対応できる高度なAIアシスタントを構築することで、顧客満足度を向上させ、サポート業務の効率化を実現できるでしょう。
まとめ
LFMが従来のTransferモデルと異なる点や実際の使い方、日本語タスクの性能などを本記事では解説をしました。まだまだリリース初期であり、今後の発展が非常に楽しみなAIモデルです。
ぜひ皆さんも本記事を参考に、LFMに触れてみてください!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


