
【Metaが公開したSpirit LM】音声とテキストを融合したマルチモーダルAIを解説
Metaから新たなマルチモーダル言語モデルがリリース!
2024年10月18日にMetaから、テキストと音声を自由に組み合わせられるオープンソースのマルチモーダル言語モデルであるMeta Spirit LMがリリースされました。
Meta Spirit LMは従来の音声の表現の弱点を克服し、音声とテキストの両方で自然な発話生成が可能となり、音声認識、テキスト生成、音声分類など、異なるモダリティを跨いだ学習が可能です!
この記事では、Meta Spirit LMの概要と、Google Colaboratoryでの実装方法について詳しく解説します。
最後まで読むことで、Meta Spirit LMの実装が可能になりますので、ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Meta Spirit LMの概要
Meta Spirit LMは、テキストと音声を自由に組み合わせることができるMeta初のオープンソースマルチモーダル言語モデル。Meta Spirit LMは、音声認識、テキスト読み上げ、音声分類などの新しいタスクを複数のモダリティで実行できるように開発されました。
Meta Spirit LMの特徴は次の点です。
音声とテキストのシームレスな融合
従来のテキスト読み上げは、自動音声認識(ASR)で音声をテキストに変換し、その後テキストを生成し、最終的に音声合成(TTS)で読み上げるプロセスがありました。
この方法では、表現力が失われることがありましたが、Meta Spirit LMは音声とテキストを直接処理することで、この問題を解決しています。
単語レベルのインターリーブ学習
Meta Spirit LMは、音声とテキストのデータを単語レベルで交互に学習する「インターリーブ方式」を採用しており、これにより異なるモダリティ間で自然な生成が可能になっています。
2つのバージョン
Meta Spirit LMには2つのバージョンがあります。
- Spirit LM Base: 音声モデリングに音声記号を用いており、標準的な生成タスクに向いています。
- Spirit LM Expressive: ピッチやスタイルの記号を使用し、感情(興奮、怒り、驚きなど)を反映した音声を生成します。
Meta Spirit LMの技術
Meta Spirit LMを実現している技術はSPIRIT-LMです。
SPIRIT-LMはLlama 2ベースの事前学習済みのテキスト言語モデルをさらに音声モダリティに拡張したもので、音声とテキストのデータを単語レベルでインターリーブトレーニングすることで、より自然で表現力豊かな生成を可能にしています。
また、SPIRIT-LMは、Few-shot学習にも対応しており、少ないサンプルでも新しいタスクを学習できる能力を持っています。これにより、音声分類や感情表現の生成といった多様なタスクにも適応できるのが特徴。
さらに、SPIRIT-LM EXPRESSIVEは、新しく導入されたSPEECH-TEXT SENTIMENT PRESERVATIONベンチマークで、音声やテキストの感情表現を維持しながら生成も可能。これにより、感情豊かな音声やテキストの生成が可能で、表現力が求められる音声生成にも適しています。
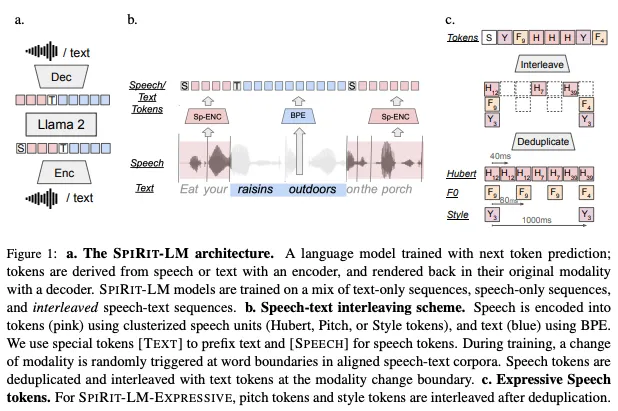
Meta Spirit LMのベンチマーク
SPIRIT-LMの音声とテキストの理解力を評価するために、いくつかのタスクでテストされています。
例えば、sWUGGYでは、音声における単語と非単語を正確に識別できるかどうかを評価し、sBLIMPでは、文法的に正しい文と間違った文を聞き分ける能力を評価。
さらに、StoryClozeというタスクでは、短い物語の続きとして適切な結末を選ぶ能力が問われており、これはモデルが意味理解や常識をどれほど持っているかを表しています。
また、MMLUは、テキストモダリティにおけるLLMの一般的な評価ベンチマークとして使用されており、音声分類タスクでは音声から意図を分類する能力を測定。
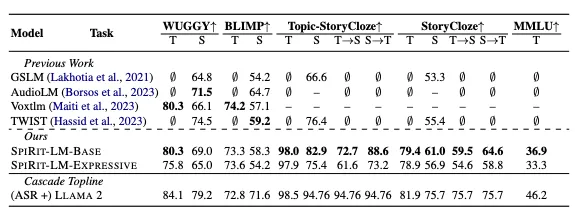
さらに、音声とテキストの生成能力を評価するためには、ASRやTTSといった評価も実施されています。
ASRでは、生成された音声をテキストに書き起こし、元のテキストと比較して正確さを評価。
また、TTSでは、入力されたテキストに基づいて音声を生成し、その生成された音声をWhisperといった最先端のモデルで再度テキストに変換し、正確さを評価します。
SPIRIT-LMの表現力を評価するためには、音声再合成タスクやSPEECH-TEXT SENTIMENT PRESERVATION(STSP)ベンチマークが使用されます。
音声再合成タスクでは、生成された音声が元の音声とどれだけ似ているか、特に表現スタイルやピッチの観点から評価されます。STSPベンチマークでは、感情が含まれた音声やテキストがプロンプトとして与えられたとき、モデルがその感情を保持したまま音声やテキストを生成できるかどうかが評価されます。
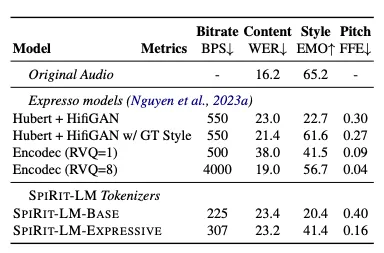
SPIRIT-LMにおける意図分類
SPIRIT-LMでは、自然言語処理や音声認識において重要である意図分類についても評価しています。
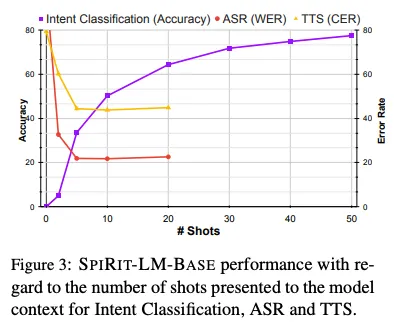
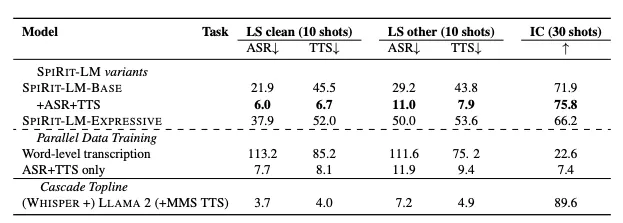
この図は、SPIRIT-LM-BASEモデルの意図分類(Intent Classification)、自動音声認識(ASR: Word Error Rate)、およびテキスト音声変換(TTS: Character Error Rate)におけるパフォーマンスです。図は、Few-shot学習のショット数(# of Shots)に対するそれぞれの評価タスクの性能の変化を視覚化。
図を読み解くと、縦軸が精度やエラーレートを示し、横軸がモデルに与えられるショット数(モデルが見たサンプル数)を表しています。
グラフには3つの異なる指標が含まれており、紫線が意図分類の精度(Accuracy)、赤線がASRの単語エラーレート(WER: Word Error Rate)、そして黄色線がTTSの文字エラーレート(CER: Character Error Rate)です。
図からわかるように、意図分類の精度(紫線)はショット数が増えるにつれて向上し、安定した高精度に達します。一方、ASR(赤線)とTTS(黄色線)はエラーレートが低下し、モデルがより多くのショットを見るにつれてパフォーマンスが向上する様子が示されています。


Meta Spirit LMのライセンス
Meta Spirit LMはNoncommercial Research Licenseです。そのため、基本的には商用利用不可です。
研究目的であっても商業的な利益を得る目的や金銭的な報酬を目的とした使用は許可されていません。また、研究成果を商用目的で使用することも禁じられています。
配布も可能ではありますが、第三者に配布する際には、ライセンスのコピーを一緒に提供することが義務付けられており、配布の目的も非商用利用に限定され、商用目的での再配布は認められていません。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明 |
| 私的使用 | ⭕️ |
なお、音声検索や高度な音声分類が可能なCLAPについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
Meta Spirit LMの使い方
Meta Spirit LMをgoogle colaboratoryで実装しますが、まずは使用許可を得る必要があります。
Meta Spirit LMのリクエストページがあるので、そちらからリクエストを送ります。
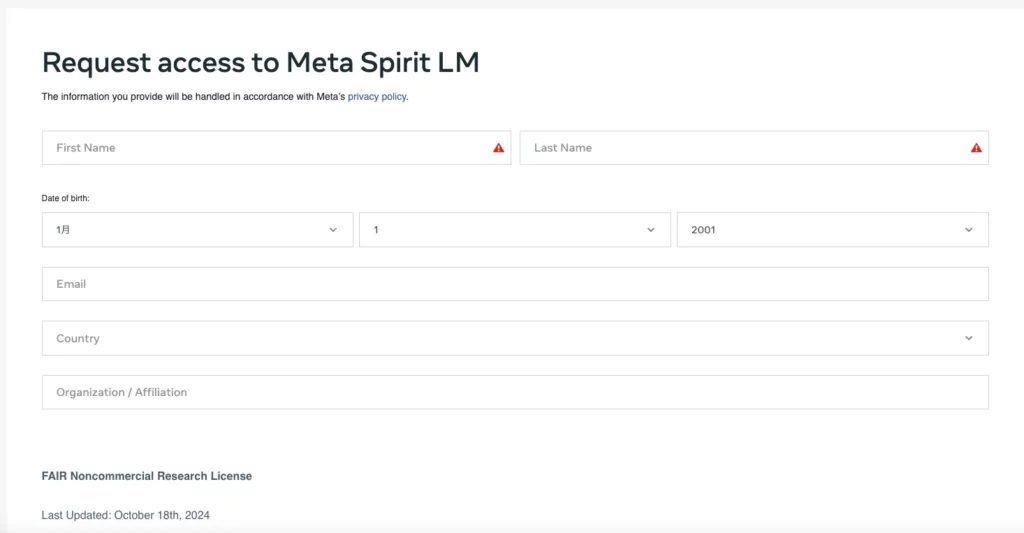
僕がリクエストを送った時は5分くらいで使用許可が返ってきたので、すぐに許可されると思います。
またGitHubページはこちらです。
google colaboratoryでMeta Spirit LMを実装してみる
GitHubにコードは上がっているのですが、Google Colaboratoryでそのまま実行すると、エラーが頻発してうまく動かない場合があります。いくつか注意点があるので、参考にしてください。
■PythonのバージョンPython 3.8以上
■使用ディスク量70.7GB
■GPU RAMの使用量14.6GB
■システムRAMの使用量3.9GB
まずはコードを紹介しておきます
クローンから必要ライブラリのインストールをするまでは少し時間を空けた方がいいかもしれません。google colaboratory上でspiritlmフォルダが反映されるのに少し時間かかります。
クローンのコードはこちら
!git clone https://github.com/facebookresearch/spiritlm.git必要ライブラリのインストールはこちら
%cd spiritlm
!pip install -r requirements.txt
!pip install -e '.[eval]'tokenizerのダウンロードはこちら
!wget -O spiritlm_speech_tokenizer.zip "メールにきているリンク"
!unzip spiritlm_speech_tokenizer.zipspiritlm_base_7bのダウンロードはこちら
!wget -O spiritlm_base_7b.zip "メールに来ているリンク"
!unzip spiritlm_base_7b.zipspiritlm_expressive_7bのダウンロードはこちら
!wget -O spiritlm_expressive_7b.zip "メールに来ているリンク"
!unzip spiritlm_expressive_7b.zip※ここからが注意点です
spiritlm_base_7bとspiritlm_expressive_7bのダウンロード終了時に以下のように聞かれます。
‘replace checkpoints/README.md? [y]es, [n]o, [A]ll, [N]one, [r]ename: と表示されるので「N or n」で回答してください。
「Y」と答えていたら、インストール済みのライブラリを適切に読み込めなくなってしまいました。
次に、/content/checkpoints/speech_tokenizerを/content/spiritlm/checkpointsに移動します。そうしないと以下のエラーが出てしまうので注意してください。
FileNotFoundError: [Errno 2] No such file or directory: ‘/content/spiritlm/checkpoints/speech_tokenizer/hubert_25hz/mhubert_base_25hz.pt’
この二点に注意すれば、スムーズに実装できます。
プロンプトをもとに音声を生成するコードはこちら
from spiritlm.model.spiritlm_model import Spiritlm
from spiritlm.speech_tokenizer import spiritlm_base
from spiritlm.model.spiritlm_model import OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
import IPython.display as ipd
from scipy.io.wavfile import write
from google.colab import files
# モデルのロード (spirit-lm-base-7b)
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-base-7b")
# 音声トークナイザーを初期化してモデルに設定
speech_tokenizer = spiritlm_base()
spirit_lm.speech_tokenizer = speech_tokenizer
# テキストを音声に変換
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="Hello, this is a text to speech conversion using Spirit LM.", # 変換するテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=0.9,
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力を確認
print(output)
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("generated_speech.wav", 16000, output[0].content)
files.download("generated_speech.wav")Meta Spirit LMではcontentに入力したテキストがそのままの形で忠実に音声として読み上げられるというより、モデルが学習した知識や推論に基づいて、適切な形式で音声を生成します。
そのため、入力テキストが正確にそのまま音声になるとは限りません。
Meta Spirit LMでいろいろ喋らせてみた
まずは日本語に対応しているかを確認してみました
サンプルコードはこちら
from spiritlm.model.spiritlm_model import Spiritlm
from spiritlm.speech_tokenizer import spiritlm_base
from spiritlm.model.spiritlm_model import OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
import IPython.display as ipd
from scipy.io.wavfile import write
from google.colab import files
# モデルのロード (spirit-lm-base-7b)
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-base-7b")
# 音声トークナイザーを初期化してモデルに設定
speech_tokenizer = spiritlm_base()
spirit_lm.speech_tokenizer = speech_tokenizer
# テキストを音声に変換
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="おはよう。今日も1日頑張ろう", # 変換するテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=0.9,
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力を確認
print(output)
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("generated_speech.wav", 16000, output[0].content)
files.download("generated_speech.wav")contentを日本語にしても日本語では喋ってくれないようです。
次に感情を込めて喋ってもらいます。
spiritlm_expressiveを使ったサンプルコードはこちら
from spiritlm.model.spiritlm_model import Spiritlm
from spiritlm.speech_tokenizer import spiritlm_base
from spiritlm.model.spiritlm_model import OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
import IPython.display as ipd
from scipy.io.wavfile import write
from google.colab import files
# モデルのロード (spirit-lm-base-7b)
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-base-7b")
# 音声トークナイザーを初期化してモデルに設定
speech_tokenizer = spiritlm_base()
spirit_lm.speech_tokenizer = speech_tokenizer
# テキストを音声に変換
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="The largest country in the world is", # 変換するテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=0.9,
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力を確認
print(output)
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("generated_speech.wav", 16000, output[0].content)
files.download("generated_speech.wav")次にGitHubのページにあるものを試していきたいと思います
デモコードはこちら
from spiritlm.model.spiritlm_model import Spiritlm
from spiritlm.speech_tokenizer import spiritlm_base
from spiritlm.model.spiritlm_model import OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
import IPython.display as ipd
from scipy.io.wavfile import write
from google.colab import files
# モデルのロード (spirit-lm-base-7b)
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-base-7b")
# 音声トークナイザーを初期化してモデルに設定
speech_tokenizer = spiritlm_base()
spirit_lm.speech_tokenizer = speech_tokenizer
# テキストを音声に変換
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="The largest country in the world is", # 変換するテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=0.9,
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力を確認
print(output)
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("generated_speech.wav", 16000, output[0].content)
files.download("generated_speech.wav")このように指示を与えると、入力したテキストに続く音声を生成してくれそうですね。
デモコード2はこちら
from spiritlm.model.spiritlm_model import Spiritlm
from spiritlm.speech_tokenizer import spiritlm_base
from spiritlm.model.spiritlm_model import OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
import IPython.display as ipd
from scipy.io.wavfile import write
from google.colab import files
# モデルのロード (spirit-lm-base-7b)
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-base-7b")
# 音声トークナイザーを初期化してモデルに設定
speech_tokenizer = spiritlm_base()
spirit_lm.speech_tokenizer = speech_tokenizer
# テキストを音声に変換
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="Here's a story about a llama that can speak:", # 変換するテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=0.9,
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力を確認
print(output)
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("generated_speech.wav", 16000, output[0].content)
files.download("generated_speech.wav")感情入りサンプルコードはこちら
from spiritlm.model.spiritlm_model import Spiritlm, OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
from scipy.io.wavfile import write
import IPython.display as ipd
from google.colab import files
from spiritlm.speech_tokenizer import spiritlm_base, spiritlm_expressive
# ベースの音声トークナイザをロード
tokenizer = spiritlm_expressive()
# Expressiveモデルのロード
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-expressive-7b")
# トークナイザをモデルに設定
spirit_lm.speech_tokenizer = tokenizer
# 感情を反映した音声生成
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="I am absolutely thrilled to be embarking on this new journey, it's going to be an incredible adventure and", # 感情を反映させたいテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=1.0, # 感情の変化を増幅させるための調整
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力された音声を再生
from scipy.io.wavfile import write
import IPython.display as ipd
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("expressive_generated_speech.wav", 16000, output[0].content)
# 音声ファイルをダウンロード
files.download("expressive_generated_speech.wav")感情入りサンプルコード2はこちら
from spiritlm.model.spiritlm_model import Spiritlm, OutputModality, GenerationInput, ContentType
from transformers import GenerationConfig
from scipy.io.wavfile import write
import IPython.display as ipd
from google.colab import files
from spiritlm.speech_tokenizer import spiritlm_base, spiritlm_expressive
# ベースの音声トークナイザをロード
tokenizer = spiritlm_expressive()
# Expressiveモデルのロード
spirit_lm = Spiritlm("/content/checkpoints/spiritlm_model/spirit-lm-expressive-7b")
# トークナイザをモデルに設定
spirit_lm.speech_tokenizer = tokenizer
# 感情を反映した音声生成
output = spirit_lm.generate(
output_modality=OutputModality.SPEECH,
interleaved_inputs=[
GenerationInput(
content="This is unbelievable! My brand new car, ruined! How can someone be so careless and disrespectful?! Seriously?!", # 感情を反映させたいテキスト
content_type=ContentType.TEXT,
)
],
generation_config=GenerationConfig(
temperature=1.0, # 感情の変化を増幅させるための調整
top_p=0.95,
max_new_tokens=200,
do_sample=True,
),
)
# 出力された音声を再生
from scipy.io.wavfile import write
import IPython.display as ipd
# 音声を再生
ipd.display(ipd.Audio(output[0].content, rate=16000))
# 音声をファイルに保存
write("expressive_generated_speech.wav", 16000, output[0].content)
# 音声ファイルをダウンロード
files.download("expressive_generated_speech.wav")なお、自然な音声と多言語対応の音声生成AIであるFish Speech 1.4について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではMeta Spirit LMについて紹介し、google colaboratoryでの実装方法をお伝えしました。
GitHubのコード通りだと、エラーが出てしまったりするので、本記事を参考に実装してみてください。また、contentに指示を入れてから、何を生成するかはわからないのとまだ日本語に対応していないことから、日本で普及するのはまだもう少し先かもしれませんね。
ただ、新たなモデルであることは間違いないので、ぜひMeta Spirit LMを実装してみてください!
最後に
いかがだったでしょうか?
マルチモーダルAIを活用することで、企業はこれまでにないレベルの自動化やパーソナライゼーションを実現し、競争力を強化できます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


