
【MiniGPT-5】文脈を理解してテキストと画像を同時出力できるマルチモーダルAIを使ってみた

MIniGPT-5は、画像とテキストの入力を理解し、それに対する回答を画像とテキストで出力する大規模マルチモーダルモデル(LMM)です。
このモデルは、新しい概念の導入と効率的な学習方法のおかげで、文脈にあった画像とテキストの同時生成を行うことができます。
GPT-4Vでも、テキストと画像の同時出力はできないので、それを実現したのはすごいことですよね!
今回は、MiniGPT-5の概要や仕組み、実際に使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
MIniGPT-5の概要
MIniGPT-5は、画像とテキストの入力を理解し、それに対する回答を画像とテキストで出力する大規模マルチモーダルモデル(LMM)です。
このモデルは、新しい概念の導入と、効率的な訓練手法により、LLMと画像生成モデルを一つに統合することに成功し、文章と画像を相互的に生成することを実現しています。
そんなMIniGPT-5の特徴は、以下の4つです。
- Generative Vokensの導入
- MiniGPT-5は、画像とテキストの出力をシームレスに行うための新しい概念として「generative vokens」を導入しています。
- この概念を導入することで、MiniGPT-4とStable Diffusion2を一つのモデルに統合することができます。
- interleaved vision-and-language outputs
- 画像とテキストの生成を交互に行うことで、一貫性のある物語を作成することができます。
- 2段階の訓練戦略
- MiniGPT-5は、画像の詳細な説明を必要としない2段階の訓練戦略を採用しており、効率的な学習が可能となっています。
- 分類器を使用しないガイダンス
- モデルの一貫性を強化するために、特定の分類器を使用せずにガイダンスが提供され、これは画像生成におけるvokensの効果を強化するのに役立ちます。
- 高性能
- MiniGPT-5は、VISTデータセットやMMDialogデータセットでの性能がベースモデルを大幅に上回り、人間による評価でも一貫して高い評価を得ています。
これまで、テキストと画像の入力ができても、出力はテキストでしかできないモデルが多かったのですが、MiniGPT-5は、革新的な概念や手法の導入によって、テキストと画像の同時出力が可能になり、さらにテキストと画像の一貫性と品質を維持しています。
まずは、その概念や手法といったMiniGPT-5の仕組みから解説していきます。

MiniGPT-5の仕組み
ここからは、MiniGPT-5の特徴といえる「Generative Vokens」「2段階の訓練戦略」について解説します。
Generative Vokens
Generative Vokensという言葉はなかなか聞きなれないですが、これはテキスト情報と画像情報を結合し、生成モデルを訓練する方法を提案するために定義された新しい概念です。
このGenerative Vokensは、テキストと画像の両方の特徴を表現するために使用され、その生成は、テキスト情報をエンコーダに入力してテキストの埋め込み表現を取得し、この埋め込み表現と画像情報を組み合わせることで行います。
生成モデルでは、テキスト情報とGenerative Vokensを入力とし、適切な画像を生成します。画像生成には、Latent Diffusion Model(LDM)と呼ばれる手法が使用されます。LDMでは、事前学習されたVAE(変分オートエンコーダ)とUNetを使用して、ノイズを加えた潜在特徴を生成し、生成画像の品質を向上させるための損失関数が定義されます。
かなり専門用語の多い説明になってしまいましたが、簡単に言うとMiniGPT-5は、Generative VokensによってベースモデルであるMiniGPT-4と画像生成モデルのStable Diffusionを一つのモデルに統合して、一貫性のあるマルチモーダルな出力を実現したモデルということです。
以下に、MiniGPT-5のパイプラインの構造概要図を貼り付けておきます。
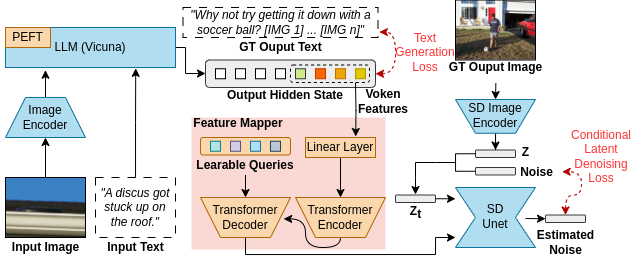
2段階の訓練戦略
MiniGPT-5は、テキストと画像のドメインの違いを考慮した2段階の訓練戦略を採用しています。これにより、画像の詳細な説明がなくとも、マルチモーダルな出力を実現しています。
まず、最初の訓練段階では、Classifier-free Guidance(CFG)と呼ばれる手法を使用し、条件付き生成と無条件生成の両方で学習することで、条件付き生成の結果を改善することができ、それによって生成トークンの効果を増強します。
次の2つ目の段階では、テキストと画像の特徴の調整を重視したトレーニングを行います。これによって、画像から抽出した視覚的特徴とテキストを効果的に融合させることを目指します。
さらに、これらの訓練戦略に加えて、分類器を使用しないガイダンスを組み込みこんでいます。これにより、モデルが特定のVokensに焦点を当てやすくなったり、ノイズが低減されることから、画像生成におけるvokensの効果を強化できます。
このような仕組みでモデルを学習させることで、高品質なテキストと画像の相互的生成が可能になります。
実際、CC3M validation setを使用したモデル性能の比較実験では、同じ最先端モデルのGILLの性能を凌駕する結果になりました。
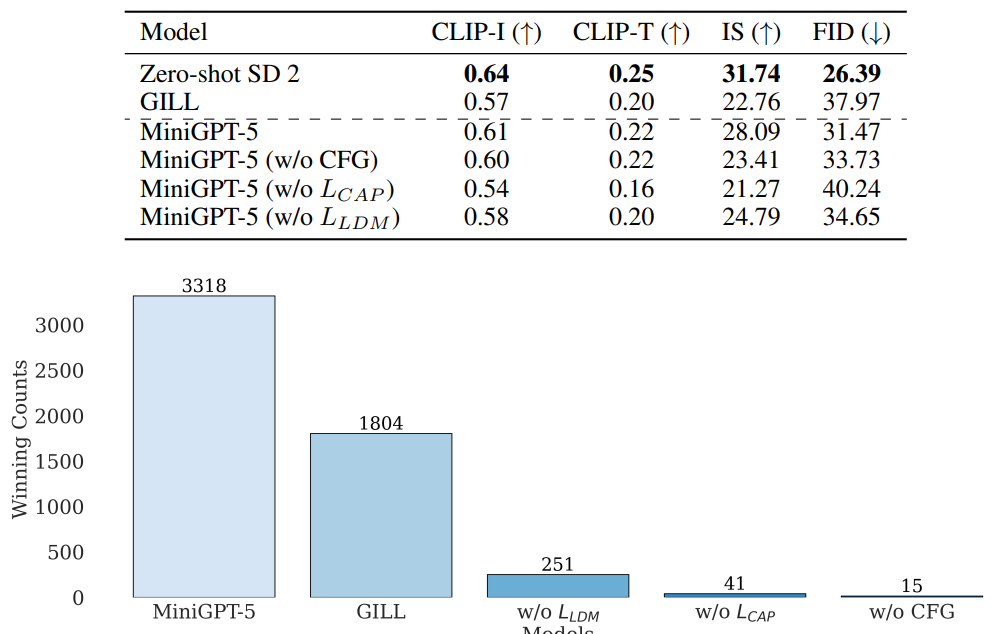
このモデルは、十分凄い性能を有しているのですが、開発者たちはこれを、将来の学術研究のための「プロトタイプ」だとしており、今後これをベースにさらに高性能なモデルが開発されることが予想されます。
非常に楽しみですね!
ここからは、MiniGPT-5の本当の実力を探るべく、実際に使っていこうと思います。
まずは使い方から解説します。
なお、テキストで画像を加工できるAIについて知りたい方はこちらをご覧ください。
→【InstantID】マルチバースの人物画像を生成できるAIで有名人をアメリカの高校生にしてみた
MiniGPT-5の使い方
まず、公式GitHubのリポジトリをクローンします。
MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens
git clone https://github.com/eric-ai-lab/MiniGPT-5.git次に、MiniGPT-5のディレクトリに移動します。
cd MiniGPT-5新しくPython3.9の仮想環境を作ります。
conda create -n minigpt5 python=3.9
conda activate minigpt5以下のコードを実行して、必要なパッケージなどのインストールを行います。
pip install -r requirements.txtここまで完了したら、次に事前にトレーニングされた重みをダウンロードします。
このモデルでは、Vicuna V0 7Bを使用しているので、以下のページから重みをダウンロードしてきてください。
重みのダウンロードが完了したら、モデルのconfigファイルのVicunaの重みのパスを自分がダウンロードしたものに変更します。
変更箇所は、minigpt4/configs/models/minigpt4.yamlの16行目です。
次に、MiniGPT-5のチェックポイントをダウンロードします。
これは、上述のGitHub上でダウンロードすることができますので、Stage 1: CC3M、Stage 2: VIST、Stage 2: MMDialogの3つすべてダウンロードして、WEIGHT_FOLDERというフォルダを新たに作り、そこに保存してください。
これで、実行の準備は完了です。
早速試していきましょう!
なお、画像も出力できるAIエージェントについて知りたい方はこちらをご覧ください。
→Open Interpreterがついに画像出力にも対応!使い方から実践までを解説【画像付き】
MiniGPT-5を実際に使ってみた
私の環境ではスペックが足りず動かなかったので、web上で動くモデルが登場次第、使ってみて更新します!
ブックマークをしてお待ちください。
MiniGPT-5の推しポイントである一貫性のある出力は本当なのか検証
実際に使え次第、更新します!
ブックマークをしてお待ちください。
MiniGPT-5のこれからに期待!
MIniGPT-5は、画像とテキストの入力を理解し、それに対する回答を画像とテキストで出力する大規模マルチモーダルモデル(LMM)です。
このモデルは、Generative Vokensという新しい概念の導入と、2段階の戦略を持った効率的な訓練手法により、LLMと画像生成モデルを一つに統合することに成功し、文章と画像を相互的に生成することを実現しています。
このモデルは、将来の学術研究のための「プロトタイプ」だとされており、今後これをベースにさらに高性能なモデルが開発されることが予想されるので、期待して待ちましょう!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

