
【InstantID】AIが本気を出した!マルチバース人物画像を生成できるAIの使い方を徹底解説
- 1枚の画像から多様なスタイル変換を実現するAIツール「InstantID」
- 顔認識とテキスト情報を統合処理し、高品質な生成を行う独自構造
- 商用利用も可能なApache License 2.0対応でビジネス導入に適する
2024年1月15日、入力された画像を様々なスタイルに変換できる「InstantID」が公開されました。この手法を用いることで、1枚の画像を入力するだけで、様々なスタイルに編集できるんです、、、!
InstantIDのGitHubでのスター数は、7000を超えており、注目度の高さがうかがえます。
この記事ではInstantIDの使い方や、有効性の検証まで行います。本記事を熟読することで、InstantIDの凄さを実感し、ただの画像編集AIには戻れなくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
InstantIDの概要
InstantIDは、1枚の画像を入力するだけで、その画像を様々なスタイルに変換することができるAIツールです。ControlNetと同じような効果を持ちます。

上記の様に、左端の入力画像をもとにStyle 1~Style 8まで、幅広くスタイル変換できるのです。以下の図は、InstantIDのモデル構造です。
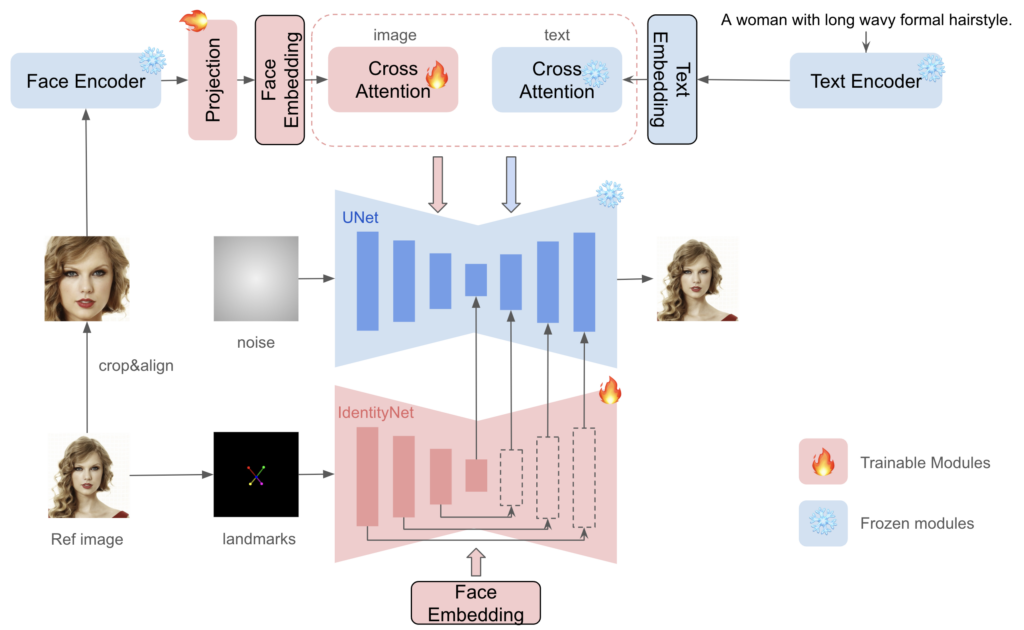
本モデルにおける以下の3つの重要な要素で、顔やテキストの情報を処理しています。
- 顔の詳細情報を埋め込むFace Encoder
- Face EmbeddingとText Embeddingを通す2つのクロスアテンション
- 目や鼻の位置など顔の特徴(landmarks)を抽出するIdentityNet
上記の3つの要素で「顔」と「テキストプロンプト」の情報を処理し、拡散モデル(UNet)に送り込みます。そして、その情報をもとに、拡散モデルが画像を生成するのです。
また、UNet自体は学習しないので、もともとのText-Imageの生成能力を維持でき、既存の学習済みモデルやControlNetsと互換性があるそうです。さらに、テスト時のチューニングを必要としないので、特定のテキストに対して、微調整のために複数の画像を収集する必要がなく、1つの画像を1回推論するだけで済むそう。
こうすることで、以下のように、1つの画像を様々なスタイルに変換できるのです。

なお、ControlNetも利用できるWebUI版のStable Diffusionについて知りたい方はこちらの記事をご覧ください。

InstantIDのライセンス
Apache License 2.0の下、誰でも無償で商用利用することが可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
\画像生成AIを商用利用する際はライセンスを確認しましょう/

人物の一貫性を保ちながらアニメーション化したい方は、以下の記事もご覧ください。

InstantIDの使い方
ここでは、GitHubに載っている方法を参考にして、Google ColabのA100を用いて、実行していきます。まずは、以下のコードを実行して、必要なライブラリをインストールしましょう。
!pip install opencv-python transformers accelerate insightface onnxruntime controlnet-aux
!git clone https://github.com/instantX-research/InstantID.git
%cd InstantID
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="InstantX/InstantID", filename="ControlNetModel/config.json", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/InstantID", filename="ControlNetModel/diffusion_pytorch_model.safetensors", local_dir="./checkpoints")
hf_hub_download(repo_id="InstantX/InstantID", filename="ip-adapter.bin", local_dir="./checkpoints")次に、以下のURLから、「antelopev2」をダウンロードし、中身のファイルをすべて「InstantID/models/antelopev2」のフォルダ内に置きましょう。
一部ですが、最終的に、以下のようなフォルダ構成になっています。
├── models
├── checkpoints
├── ip_adapter
├── pipeline_stable_diffusion_xl_instantid.py
└── README.md次に、以下のコードを実行して、モデルのロードをしましょう。
import diffusers
from diffusers.utils import load_image
from diffusers.models import ControlNetModel
import cv2
import torch
import numpy as np
from PIL import Image
from insightface.app import FaceAnalysis
from pipeline_stable_diffusion_xl_instantid import StableDiffusionXLInstantIDPipeline, draw_kps
# prepare 'antelopev2' under ./models
app = FaceAnalysis(name='antelopev2', root='./', providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
app.prepare(ctx_id=0, det_size=(640, 640))
# prepare models under ./checkpoints
face_adapter = f'./checkpoints/ip-adapter.bin'
controlnet_path = f'./checkpoints/ControlNetModel/'
# load IdentityNet
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
base_model = 'wangqixun/YamerMIX_v8' # from https://civitai.com/models/84040?modelVersionId=196039
pipe = StableDiffusionXLInstantIDPipeline.from_pretrained(
base_model,
controlnet=controlnet,
torch_dtype=torch.float16
)
pipe.cuda()
# load adapter
pipe.load_ip_adapter_instantid(face_adapter)最後に、以下のコードを実行して、実際に動かしてみましょう。
# load an image
face_image = load_image("./examples/sam_resize.png")
# prepare face emb
face_info = app.get(cv2.cvtColor(np.array(face_image), cv2.COLOR_RGB2BGR))
face_info = sorted(face_info, key=lambda x:(x['bbox'][2]-x['bbox'][0])*x['bbox'][3]-x['bbox'][1])[-1] # only use the maximum face
face_emb = face_info['embedding']
face_kps = draw_kps(face_image, face_info['kps'])
pipe.set_ip_adapter_scale(0.8)
prompt = "analog film photo of a man. faded film, desaturated, 35mm photo, grainy, vignette, vintage, Kodachrome, Lomography, stained, highly detailed, found footage, masterpiece, best quality"
negative_prompt = "(lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured (lowres, low quality, worst quality:1.2), (text:1.2), watermark, painting, drawing, illustration, glitch,deformed, mutated, cross-eyed, ugly, disfigured"
# generate image
image = pipe(
prompt, image_embeds=face_emb, image=face_kps, controlnet_conditioning_scale=0.8 ,ip_adapter_scale=0.8,).images[0]
display(image)ここでは、以下の画像を用いて、モデルを動かしてみます。

プロンプトは以下の通りです。
analog film photo of a man. faded film, desaturated, 35mm photo, grainy, vignette, vintage, Kodachrome, Lomography, stained, highly detailed, found footage, masterpiece, best quality
結果は以下の通りです。

お次はメガネを外してもらいましょう。結果は以下の通りです。

メガネが外れていないですね、、、
InstantIDを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
3.16GB
■RAMの使用量
2.8GB
なお、簡単に画像内の人物に着せ替えできるAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

InstantIDで著名人をアメリカの高校生にしてみた
ここでは、「サムアルトマン」と「イーロンマスク」に、以下の9人のアメリカの高校生に生まれ変わってもらいましょう。
- ラグビー部
- ギーク
- パンクバンドオタク
- チア
- カントリー系女子
- 優等生
- 卒業アルバム
- ドラマの主人公
- 不良
まずはサムアルトマン。

続いて、イーロンマスク。

両方ともギークと不良のパターンがイマイチですね。
今回は「American high school student ~」というプロンプトに簡単なキーワードを設定しているだけなので、もう少しプロンプト設計すれば、より高度なスタイル変換が可能になるでしょう。
なお、1枚の画像を3Dに変換できるAIについて知りたい方はこちらの記事をご覧ください。

まとめ
InstantIDは、1枚の画像を入力するだけで、その画像を様々なスタイルに変換することができるAIツールです。本ツールを用いることで、入力画像を、好みの画像に編集することができます。
より精巧なプロンプト設計で、より高度なスタイル変換が可能になるでしょう。
数年後には、過去の写真に写った自分の服装や表情を、自由に編集できるようになっているのかもしれないですね。
将来的には、このような技術と動画生成・3D技術を組み合わせることで、より高度なコンテンツ作成が可能になるでしょう。また、本格的にディープフェイクのリスクも、高まってくると思います。

最後に
いかがだったでしょうか?
InstantIDをはじめとする生成AIの活用は、企業のクリエイティブ制作や業務効率を一変させます。事業課題に最適な導入戦略をご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

