
【DreamGaussian】必要なのは1枚の画像のみ!1分で3D画像を作る画像生成AIの使い方やインストール方法

皆さんは、DreamGaussianという3D画像生成ツールを知っていますか?
このツールは、1枚の画像から超高速で3Dコンテンツに変換できるもので、その速度は既存の手法よりなんと約10倍も速いんです!
たった1枚の画像から10倍も速く3D化できるなんてすごいですよね!
今回は、DreamGaussianの概要や仕組み、実際に使ってみた感想をお伝えします。
是非最後までご覧ください!
- 1枚の画像から3Dコンテンツが作成可能
- 従来の方法よりも10倍高速
- image to 3Dとtext to 3Dの2パターンあり
\生成AIを活用して業務プロセスを自動化/
DreamGaussianの概要
DreamGaussianは、1枚の画像から超高速で高画質の3Dコンテンツを生成できる、3D画像生成AIツールです。従来の手法とは一線を画す手法で最適化とテクスチャの精緻化を行い、結果としてたった1枚の画像から、高品質の3Dコンテンツを超高速で生成できます。
そんなDreamGaussianの特徴は以下の4つです。
高効率:従来の手法に比べ、格段に効率が向上しており、3Dコンテンツの生成開始から完了までわずか2分で行うことができます。
3Dガウススプラッティング:効率を向上させるための主な技術として、3Dガウススプラッティングモデルを使用。これにより、3D生成タスクのための高速な収束が可能となっています。
UV空間でのメッシュ抽出:このプロセスを踏むことで、テクスチャが正確にモデル表面に適用され、歪みや伸びが最小限に抑えられるため、リアルな3Dモデルの生成が可能です。
テクスチャの精緻化:このプロセスでUVマッピングで3Dモデルに適用されるテクスチャの解像度をあげたり、詳細を調整することで、モデルの品質を向上させることができます。
image to 3Dとtext to 3D:画像から3Dコンテンツを生成できることに加え、テキストからも3Dコンテンツの生成ができます。
従来とは違う新しい手法を用いることで、10倍も速度が速くなっただけでなく、より高精細にかつテキストからも3Dコンテンツを生成できるようになったということですね!
ここからは、公開されている情報をもとに、DreamGaussianの性能紹介をした後に、実際に使ってみてどのようなものが生成されるか見ていこうと思います。
性能
こちらの公式ページを参考にして性能紹介をしていきます。
DreamGaussian
まずは以下の動画をご覧ください。
これは、従来の手法であるNeRFとDreamGaussianの3Dへの変換時間を示したもので、DreamGaussianは2分以内で完了しているのに対し、NeRFは同等の品質のものを生成するのに15分ほどかかっており、DreamGaussianの性能の高さが伺えます。
次は、DreamGaussianを使用して、画像から3Dに変換されたものを見ていきましょう。
こちらは上の画像から3D化したものを下に表示したもので、高品質な3Dモデルが生成できている事が分かります。
次に、テキストから3Dに変換されたものです。
画像が絵のようになっているのが特徴的ですが、テキストを正確に捉えたものになっていると思います。
また、テキストから3Dにする過程で生成した画像も出力できるようです。
これを見ると、テキストから高精細な画像も生成することができているので、画像生成フレームワークとしても使えそうです。
画像生成までできるとなると、画像生成AIの代わりとして使い、さらにはその画像を3D化できるので、本当に革新的なツールだと思います。
最後に、この革新的な機能を可能にしている技術である、3Dガウススプラッティングとメッシュテクスチャの精緻化の流れの動画をご覧ください。
3Dガウススプラッティング
メッシュテクスチャの精緻化
それでは実際にDreamGaussianを使用して、生成時間やどのようなものが生成されるか見ていきましょう!
なお、高速で画像生成できるAIツールについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

DreamGaussianで使うことができる機能
GitHubのNewsを確認してみると、DreamGaussianで使える機能がいくつか増えているようです。
それぞれの機能がどういったものか、どのように使うかをそれぞれ解説します。
MVDream
MVDreamは、3D生成のためのマルチビュー拡散モデルです。この技術は、複数の視点を利用して3Dオブジェクトやシーンを生成することを目的としています。
テキストから画像(Text-to-Image)への生成、さらには複数フレームの生成に対応しており、Gradioで使うことも可能です。
MVDreamをDreamGaussianで使用する際には、いくつか設定が必要。
MVDreamの設定はこちら
input: # 入力画像のパス(GUIでも設定可能)
prompt: # テキストプロンプト(GUIでも入力可能)
negative_prompt: # ネガティブプロンプト(デフォルトで設定済み)
mvdream: True # MVDreamを使用する場合はTrueに設定
imagedream: False # ImageDreamは無効
stable_zero123: False # Stable-Zero123も無効
iters: 500 # Stage 1の学習イテレーション数
iters_refine: 50 # Stage 2の学習イテレーション数
batch_size: 1 # バッチサイズ
radius: 2.5 # カメラの距離
fovy: 49.1 # カメラの視野角
min_ver: -30 # カメラの最小仰角
max_ver: 30 # カメラの最大仰角上記はすでにGitHubに用意されているyamlファイルに記載されているので、GitHubのyamlファイルを読み込めばOKです。
コマンドラインで実行する場合は、以下のコマンドです。
python main.py --config text_mv.yamlgoogle colaboratoryで使用する際は、以下を変更します。
MVDreamの変更前はこちら
#@title training!
# stage 1
%run main.py --config configs/image.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=True
# stage 2
%run main2.py --config configs/image.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=TrueMVDreamの変更後はこちら
# stage 1: Gaussian Splatting (MVDream)
%run main.py --config configs/text_mv.yaml prompt="A futuristic cityscape" save_path={NAME} elevation={Elevation} force_cuda_rast=True
# stage 2: メッシュ生成 (MVDream)
%run main2.py --config configs/text_mv.yaml prompt="A futuristic cityscape" save_path={NAME} elevation={Elevation} force_cuda_rast=Trueこれでgoogle colaboratory上でMVDreamを有効にできます。
Stable-Zero123
Stable Zero123は、単一の画像から高品質な3Dオブジェクトを生成するための画期的な技術。
このモデルは、従来のZero1-to-3やZero123-XLといった先行モデルを遥かに凌ぐ性能を持ちます。
改良されたトレーニングデータセットと仰角条件付け(Elevation Conditioning)を導入することで、視点を変えた際にもリアリティのある描写が可能となり、より精密で質の高い3Dモデルを生み出せるようになっています。
Stable Zero123をDreamGaussianで使用する際にも、いくつか設定が必要です。
Stable Zero123の設定はこちら
# Stable-Zero123を有効化
mvdream: False
imagedream: False
stable_zero123: True
# Zero123の重み付け設定
lambda_sd: 0
lambda_zero123: 1
input: # 入力画像のパス(必須)
prompt: # テキストプロンプト(オプション)
elevation: 0 # 入力画像の推定仰角
ref_size: 256 # 参照画像の解像度
iters: 500 # Stage 1の学習イテレーション数
iters_refine: 50 # Stage 2の学習イテレーション数
radius: 2 # カメラの距離
fovy: 49.1 # Zero123のレンダリング設定に合わせた視野角
min_ver: -30 # カメラの最小仰角
max_ver: 30 # カメラの最大仰角上記はすでにGitHubに用意されているyamlファイルに記載されているので、GitHubのyamlファイルを読み込めばOKです。
コマンドラインで使用する場合は、以下のコマンドを入力してください。
python main.py --config image_sai.yaml --input path/to/your/image.pngStable-Zero123は主に単一の入力画像から3Dモデルを生成するために使用されます。そのため,
MVDreamと異なり、入力画像が必要であり、テキストプロンプトのみからの生成はできません。
こちらをgoogle colaboratoryで使う際には、以下のとおりに変更します。
Stable-Zero123の変更前はこちら
#@title training!
# stage 1
%run main.py --config configs/image.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=True
# stage 2
%run main2.py --config configs/image.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=TrueStable-Zero123の変更後はこちら
# stage 1: Gaussian Splatting (Stable-Zero123)
%run main.py --config configs/image_sai.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=True
# stage 2: メッシュ生成 (Stable-Zero123)
%run main2.py --config configs/image_sai.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=TrueImageDream
ImageDreamは、テキストプロンプトや画像を基に3Dオブジェクトやシーンを生成するための強力なツールです。
この技術は、複数の視点からの高品質な画像を生成する「マルチビュー拡散モデル」として設計されています。ImageDreamは、3D構造のリアルな再現を可能にするだけでなく、テクスチャ付きの3Dメッシュを生成し、様々な分野で応用できる柔軟性を持っています。
また、ソフトシャーディング技術を導入することで、自然な光の表現や詳細な質感を伴う3Dオブジェクトの生成を実現しています。
これにより、クリエイティブなデザインプロセスや学術研究、VR/ARコンテンツ制作など、多くの応用分野での利用が期待されています。
DreamGaussianで使用する際は、いくつか設定が必要になります。
ImageDreamの設定はこちら
# ImageDreamを有効化
mvdream: False
imagedream: True
stable_zero123: False
lambda_sd: 1
lambda_zero123: 0
min_ver: -5 # 最小仰角
max_ver: 0 # 最大仰角
radius: 2.5 # カメラ距離
warmup_rgb_loss: True
iters: 500 # Stage 1の学習イテレーション
iters_refine: 50 # Stage 2の学習イテレーション
batch_size: 1
ref_size: 256 # 参照画像の解像度上記はすでにGitHubに用意されているyamlファイルに記載されているので、GitHubのyamlファイルを読み込めばOKです。
コマンドラインで使用する場合は、以下のコマンドを入力してください。
python main.py --config imagedream.yaml --input path/to/your/image.pnggoogle colaboratoryで使用する際は以下です。
ImageDreamの変更前はこちら
#@title training!
# stage 1
%run main.py --config configs/image.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=True
# stage 2
%run main2.py --config configs/image.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=TrueImageDreamの変更後はこちら
# stage 1: Gaussian Splatting (ImageDream)
%run main.py --config configs/imagedream.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=True
# stage 2: メッシュ生成 (ImageDream)
%run main2.py --config configs/imagedream.yaml input=data/{IMAGE_PROCESSED} save_path={NAME} elevation={Elevation} force_cuda_rast=True
dreamgaussianのgoogle colaboratoryが用意されているので、そちらの「training!」でそれぞれ読みこむyamlファイルを変更すればOKです。
DreamGaussianのライセンスおよび料金
DreamGaussianは「MIT License」でライセンスされています。MIT Licenseもとで公開されたソフトウェアは、商用・非商用を問わず、無料で利用、コピー、変更、組み合わせ、再配布することができます。
該当のライセンスについて詳しくは公式ページをご確認ください。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕ |
| 改変 | ⭕ |
| 配布 | ⭕ |
| 私的利用 | ⭕ |
\画像生成AIを商用利用する際はライセンスを確認しましょう/

DreamGaussianの使い方
では実際にDreamGaussianを実装します。
DreamGaussianを使う場合、GPUメモリを消費するため、Google Colaboratoryの有料版でないと動かないかもしれません。
コードはGitHubに記載されているものを参考に実装します。
DreamGaussianを動かすのに必要なPCのスペック
今回、DreamGaussianはGoogleColabで動かしました。
必要なスペックやパッケージは下記のとおりです。
■GoogleColab Pro
・GPU:V100
・ハイメモリ
■必要なパッケージ
・torch 2.1
・CUDA12.1
DreamGaussianのインストール方法
公式Githubページで「image to 3D」と「text to 3D」の2つのGoogle Colabノートブックが公開されているのですが、2025年2月現在では残念ながら、そのままコードを実行すると各所でエラーが発生すると思います。
そこで、エラーを出さずに3D生成ができるコードを作成しましたので、
以下のコードをGoogleColabに貼り付けて、そのまま実行してみてください!
1.環境設定
# 1. Fix numpy to a 1.x version (compatible with TF, gensim, etc) and upgrade matplotlib
!pip install -U "numpy<2.0.0" "matplotlib>=3.8.0"
# 2. Install core Python requirements for DreamGaussian (except torch, assuming torch==2.6.0 is already installed in Colab)
!pip install -U einops plyfile dearpygui huggingface_hub diffusers accelerate transformers \
xatlas trimesh PyMCubes pymeshlab "rembg[gpu,cli]" omegaconf ninja
# 3. Install the diff_gaussian_rasterization module (Python 3.11 compatible wheel)
!pip install -U https://huggingface.co/spaces/Mightypeacock/wheels-for-colab/resolve/main/diff_gaussian_rasterization-0.0.0-cp311-cp311-linux_x86_64.whl
# 4. Install the simple_knn module (Python 3.11 compatible wheel)
!pip install -U https://huggingface.co/spaces/Mightypeacock/wheels-for-colab/resolve/main/simple_knn-0.0.0-cp311-cp311-linux_x86_64.whl
# 5. Install other external dependencies from source as in official instructions
!pip install -U git+https://github.com/NVlabs/nvdiffrast.git
!pip install -U git+https://github.com/ashawkey/kiuikit.git
# (Optional) If using text-to-3D or ImageDream features, install their repos:
# pip install -U git+https://github.com/bytedance/MVDream.git
# pip install -U git+https://github.com/bytedance/ImageDream.git#subdirectory=extern/ImageDream
!echo "Environment setup complete. All packages installed."# DreamGaussian リポジトリをクローン
!git clone -q https://github.com/dreamgaussian/dreamgaussian.git
%cd dreamgaussian
# 必要なPythonライブラリをインストール (静かに(-q)インストール)
!pip install -q einops plyfile dearpygui huggingface_hub diffusers accelerate transformers xatlas \
trimesh PyMCubes pymeshlab rembg[gpu,cli] omegaconf ninja
# Gaussian Splatting関連ライブラリのインストール(CUDA実装)
!git clone -q --recursive https://github.com/ashawkey/diff-gaussian-rasterization.git
!git clone -q https://github.com/DSaurus/simple-knn.git
!pip install -q ./diff-gaussian-rasterization
!pip install -q ./simple-knn
# NVIDIAのDifferentiable Rasterizer (OpenGL不要なレンダリング) と kiuikit のインストール
!pip install -q git+https://github.com/NVlabs/nvdiffrast.git@main
!pip install -q git+https://github.com/ashawkey/kiuikit.git@main2.画像アップロードorダウンロード
以下コードを実行すると、「ファイルを選択」というダイアログが出るので、お好きな画像をアップロードしてください。
もしくは、サンプル画像をダウンロードできるようにしていますので、お好みのパターンで試してください。
import os, shutil
from google.colab import files
# 保存先フォルダを作成
os.makedirs('data', exist_ok=True)
print("画像をアップロードするときは、ファイル選択ダイアログで選んでください。")
uploaded = files.upload() # ここでファイル選択ダイアログが出る
if uploaded:
# アップロードされた最初のファイルを data フォルダへ移動
uploaded_filename = list(uploaded.keys())[0]
new_filename = uploaded_filename
# ファイル名にスペースやカッコがある場合の安全策:なるべくリネームする
# (必須ではありませんが、ファイルパスの特殊文字によるトラブル回避に有効)
safe_filename = uploaded_filename.replace(' ', '_').replace('(', '_').replace(')', '_')
if safe_filename != uploaded_filename:
new_filename = safe_filename
shutil.move(uploaded_filename, os.path.join('data', new_filename))
input_image_path = os.path.join('data', new_filename)
print(f"Uploaded image saved to: {input_image_path}")
else:
# アップロードがなければサンプル画像をダウンロード
sample_url = "https://raw.githubusercontent.com/opencv/opencv/master/samples/data/lena.png"
sample_path = os.path.join('data', 'sample.jpg')
!wget -q {sample_url} -O {sample_path}
input_image_path = sample_path
print(f"No upload detected. Sample image downloaded to: {input_image_path}")3.画像の前処理
import os
# 背景除去と中心化: 512x512 RGBA画像を出力
!python process.py "{input_image_path}" --size 512
# 前処理後のファイル名 (_rgba.png が付きます)
NAME = os.path.splitext(os.path.basename(input_image_path))[0]
processed_image_path = os.path.join('data', f"{NAME}_rgba.png")
print(f"Processed RGBA image saved as: {processed_image_path}")4.TensorRTをColab環境にインストール
!apt-get update && apt-get install -y tensorrt
import os
os.environ['LD_LIBRARY_PATH'] += ':/usr/lib/x86_64-linux-gnu/'5.3D生成&メッシュ精細化
import subprocess
# 画角 (必要に応じて調整: 正面 = 0, 俯瞰なら -30 など)
Elevation = 0
# Stage 1: メッシュ生成
cmd_stage1 = [
"python", "main.py",
"--config", "configs/image.yaml",
f"input={processed_image_path}",
f"save_path={NAME}",
f"elevation={Elevation}",
"force_cuda_rast=True"
]
print("Running Stage 1: Gaussian Splatting...")
result = subprocess.run(cmd_stage1, capture_output=True, text=True)
if result.returncode != 0:
print("ERROR in Stage 1:", result.stderr)
else:
print("Stage 1 (Gaussian Splatting) completed successfully.")# Stage 2: メッシュ精細化
cmd_stage2 = [
"python", "main2.py",
"--config", "configs/image.yaml",
f"input={processed_image_path}",
f"save_path={NAME}",
f"elevation={Elevation}",
"force_cuda_rast=True"
]
print("Running Stage 2: Mesh Refinement...")
result = subprocess.run(cmd_stage2, capture_output=True, text=True)
if result.returncode != 0:
print("ERROR in Stage 2:", result.stderr)
else:
print("Stage 2 (Mesh Refinement) completed successfully.")6.出力確認&可視化
!echo "Generated files in logs/:"
!ls -lh logs | grep {NAME}import os
output_video = f"{NAME}_rotation.mp4"
obj_path = f"logs/{NAME}.obj" # Stage 2で生成されたOBJ
cmd_render = [
"python", "-m", "kiui.render",
obj_path,
"--save_video", output_video,
"--wogui", # GUI無効
"--force_cuda_rast" # CUDAベースのラスタライザを使用
]
print(f"Rendering 360° video to {output_video}...")
result = subprocess.run(cmd_render, capture_output=True, text=True)
if result.returncode != 0:
print("ERROR during rendering:", result.stderr)
else:
print(f"Video rendering completed. Saved as {output_video}")
# Colabで動画を再生するには:
from IPython.display import HTML
from base64 import b64encode
with open(output_video, 'rb') as f:
video_data = f.read()
video_url = f"data:video/mp4;base64,{b64encode(video_data).decode()}"
display(HTML(f"""<video width="512" height="512" controls>
<source src="{video_url}" type="video/mp4">
</video>"""))2025年2月現在では、GoogleColabでDreamGaussianデモを行う場合、上記コードをお使いいただければエラーなく3D生成までたどり着けるかと思います。
もしくは、Stable DiffusionのColabで有名なcamenduru氏がDreamGaussian用のColabノートブックを公開していますので、こちらからお試しいただくのもいいかもしれません。※1
text to 3Dに関しては、以下の画像のPromptの部分だけ任意のものに書き換えればあとは実行するだけです。
プロンプト例として、
a photo of an icecreamと入力されている箇所です。



DreamGaussianを実際に使ってみた
DreamGaussianを実際に使ってみます。
まずはimage to 3Dを使っていきます。
以下の画像を3D変換させてみました!

すると、、、
約1分ほどで3D化が完了し、以下のように動画で出力されました。
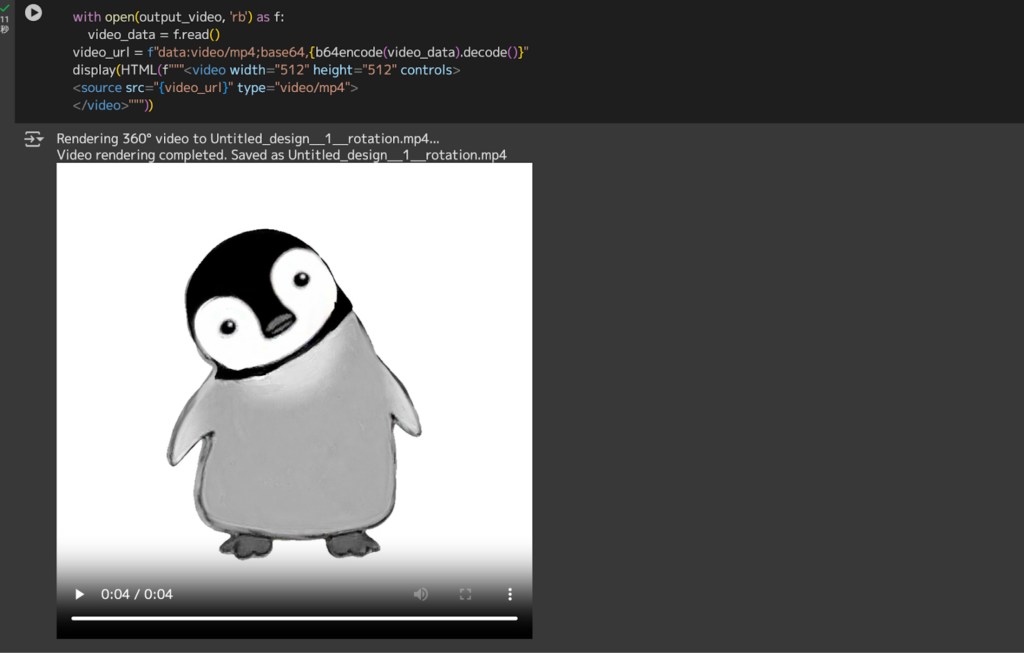
この動画をGPT-4でgifにしてもらったものがこちらです。

少しいびつで、荒い部分もありますが、たった1枚の画像から数分で生成されたものと考えれば十分だと思います。
無事に動作する事が確認できたので、この後はもっと複雑な画像を入力して、生成結果や時間がどのように変化するか見ていきます。
DreamGaussianの推しポイントである高速生成は本当なのか?
まずはシンプルに動物の画像から。

生成時間:2分
生成3D

生成時間は2分と、速いですが体の後ろ部分がうまく生成出来ておらず、高精細とは言い難いです。
もしかしたら、体の一部がポートレートでボケてしまっているのが原因かもしれません。
次にこちらの画像を変換します。

平面的なイラストで、なかなかこれを3Dにするのは難しいと思いますが、結果はどうでしょうか。
生成時間:1分
生成3D

やはり裏の部分はキレイに生成できないようで、裏面だけ色褪せているようになっています。
ですが、立体感は出ているので、もう少し情報があれば完璧な変換が出来そうです。
最後にこちらの画像の変換です。

複雑な模様で、これを3D化するのはかなり難易度が高く時間がかかりそうな予想です。
生成時間:50秒
生成3D

こちらも少し荒い気はしますが、1枚の画像から変換されたものと考えれば上出来です。
また、予想に反してこれまでで一番速い生成時間でした。
これらの結果から、どのような画像でも基本的に生成時間はあまり変わらず、わずか数分で3Dに変換してくれる事が分かりました。
なお、日本人が開発した超高速画像生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

DreamGaussianの活用事例
DreamGaussianの活用事例を3つご紹介します!
1.AIで生成した画像を3D化
上記Noteの例では、StableDiffusionで生成したキャラクターの画像を、DreamGaussianを使って3Dモデリングしています。
AIツールを使い分けて理想の完成形に近づけていく良い例ですね。
2.Text-To-3D
上記のポストでは、4つの3D画像が生成されています。
凹凸形状の特徴的な3D画像が作られていることが分かりますね。
3.3D生成AIツール比較
活用事例とは少しズレますが、
Tripo、Meshy、DreamGaussianの比較ポストがありましたのでご紹介します。
TripoやMeshyなど後発ツールの方が性能は高そうですね。。
ただ、DreamGausasianにはDreamGausasianの良さもあります。
完全に筆者の主観ですが、今流行りのソフビっぽさがあってレトロさが好きですね。
DreamGaussianの注意点
- 運用環境・リソースへの配慮
- DreamGaussianのモデル規模によっては、CPUのみでの推論に時間がかかる可能性があります。スムーズな生成を行いたい場合は、GPU(VRAM容量)を十分に確保した環境を用意することを推奨します。大規模な学習・Fine-tuningが必要な場合は、クラウド環境や高性能GPUサーバの利用を検討するようにしましょう。
- MITライセンス下での責任・保証の限界
- MITライセンスではソフトウェアに対する保証が基本的に付与されません。「現状のまま」(as is) で提供されているため、トラブルが生じても開発元は責任を負いません。実際の運用で生じた問題(誤情報の公表、データ漏洩など)については、利用者自身が責任を負う必要があります。プロジェクトで利用する際は、社内規定や法令への適合性、セキュリティリスクの管理を行えるようにしておきましょう。
- デモ環境
- 2025年2月現在では残念ながら、GitHub上で公開されているHuggingFaceやGradioデモon Colabは機能していません。DreamGaussianを利用する場合は、Gradioを経由しない手法かローカル環境で試すようにしましょう。
DreamGaussian FAQ(よくある質問)
まとめ
DreamGaussianは、従来の手法とは一線を画す、3DガウススプラッティングやUV空間でのメッシュ抽出手法を用いて、最適化とテクスチャの精緻化を行い、たった1枚の画像から、高品質の3Dコンテンツを超高速で生成できます。
従来手法よりも10倍程度速い2分ほどで3D変換が行えると謳っているDreamGaussianですが、実際はどうなのか検証したところ、どのような画像でも1〜3分ほどで変換出来ました。
また、画像からの変換だけでなく、テキストから高品質の画像を生成して、3D変換してくれる機能もあり、画像生成AIの代わりとしても使用できるなど、活用の幅がとても広いです。
もし本記事を読んでDreamGaussianが気になった方は、是非試してみてください!参考記事
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

