
検索・分類を強化する「ModernBERT」長文対応可能なAIモデル徹底解説

- 従来のBERTよりも高速・高性能・高精度
- 8192トークンという非常に長い文脈にも対応可能
- トレーニングデータは2兆トークン以上
2024年12月19日、Answer.AIとLightOnが共同開発したModernBERTが発表されました!
ModernBERTは従来のBERTよりも高速で高性能で8192トークンの長い文脈にも適応が可能です。GLUEスコアでハイスコアを取りつつも処理速度が早く、非常に効率的なモデルでもあります。
本記事ではModernBERTの特徴からgoogle colaboratoryでの実装方法までお伝えします。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
ModernBERTの概要
ModernBERTは2018年に発表されたBERTの後継であり、Answer.AIとLightOnによって開発されました。今回発表されたModernBERTはbaseとlargeの2種類です。
- ModernBERT-base:22層、149億パラメータ
- ModernBERT-large:28層、395億パラメータ
ModernBERTは従来のBERTに比べて高速・高性能で長文処理が可能です。
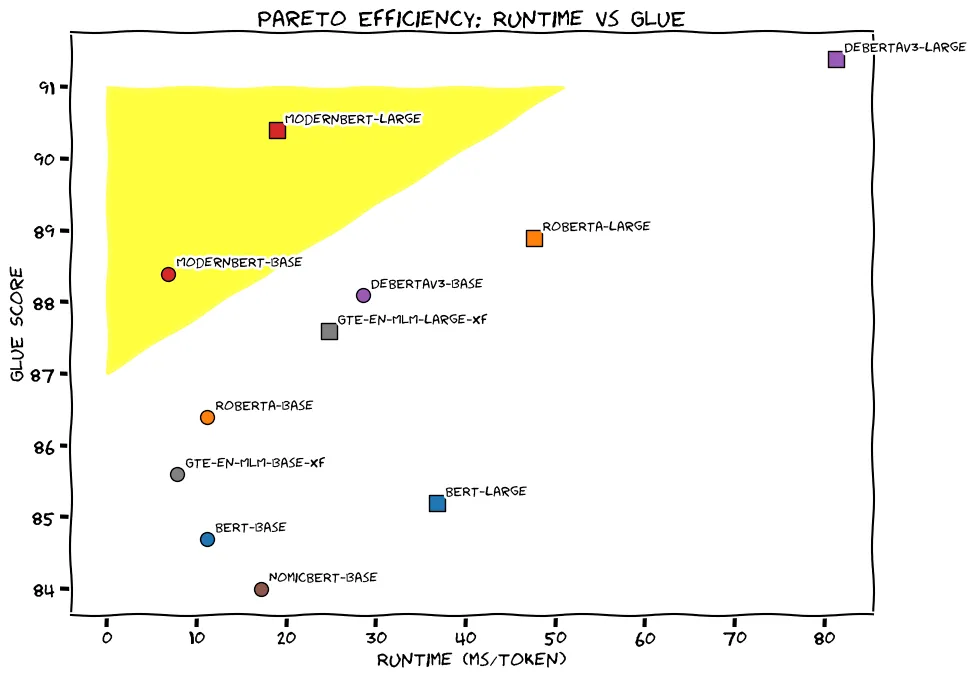
上記の画像からわかるように、ModernBERTはGLUEスコアが高く処理時間も短いため、効率の良いモデルと言えます。実用性が高く、特にリソースに限りのある環境や高速処理が求められるタスクにおいてModernBERTは実力を発揮するでしょう。
GLUEスコア:英語圏における自然言語のベンチマーク。同義語の言い換えや質疑応答といった言語に関するテストデータが含まれていて、総合的な言語能力のスコアを算出する。10種類のタスクから構成されています。
ModernBERTの処理速度
ModernBERTの処理速度が高速になった理由として3つの技術が挙げられます。
- UnpaddingとSequence Packing
- Alternating Attention
- Flash Attention
それぞれ解説します。
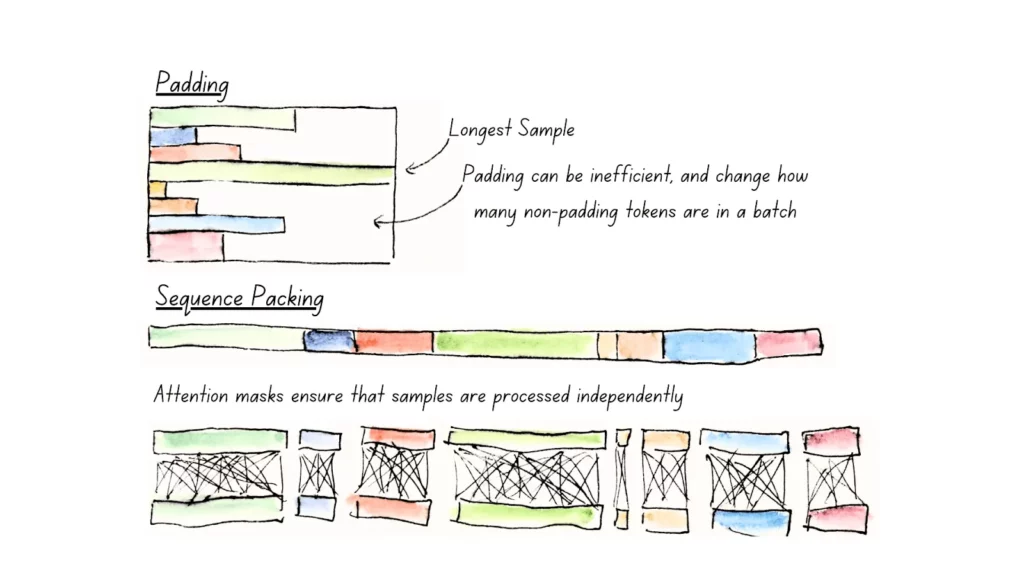
UnpaddingとSequence Packing
モデルが処理するデータには、通常、ミニバッチ間でシーケンスの長さを揃えるためにパディングトークンと呼ばれる不要なトークンが挿入されます。
Unpaddingは、これらのパディングトークンを除去し、実際に意味のあるトークンのみを処理する手法です。
Sequence PackingはUnpaddingと併用される技術であり、モデルの計算リソースを効率化するためにシーケンスを埋め込む手法です。
ミニバッチ内のシーケンスを再配置し、可能な限りスペースを無駄にしないよう詰め込み、各バッチのシーケンス長を均一化することで、モデルの処理効率を最大化します。
その結果、Unpaddingでは、計算負荷を削減し、最大で20%のパフォーマンス向上を実現し、長文タスクや変動するシーケンス長のデータセットで力を発揮することが可能です。
また、Sequence Packingを用いることでトレーニング中のメモリ消費を抑えつつ、計算の無駄を削減し、GPUの効率を最大化しています。
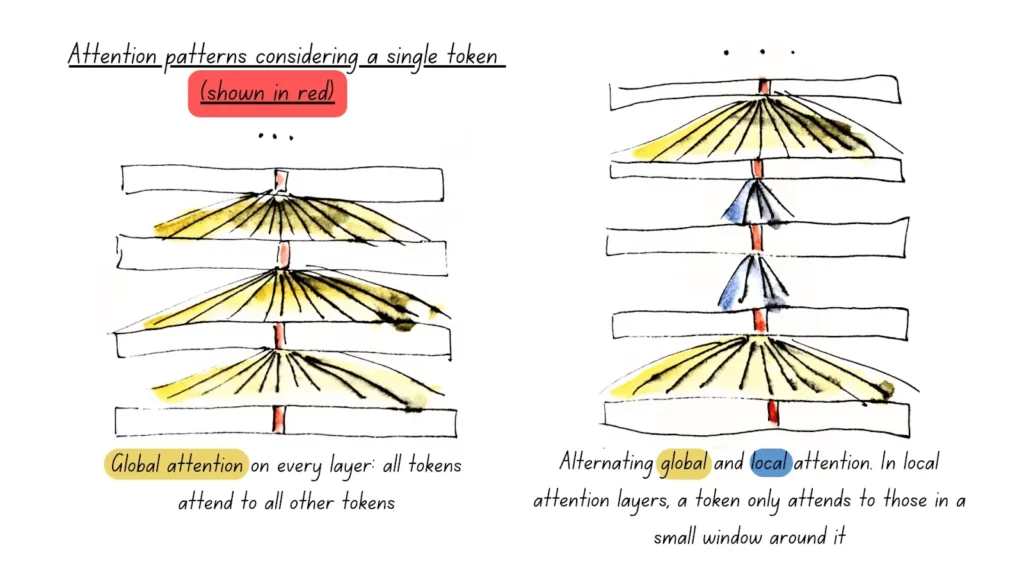
Alternating Attention
Alternating Attentionは注意機構(Attention)を「グローバル」と「ローカル」の2種類に分け、交互に切り替えて計算コストを削減する技術です。
グローバルアテンションでは、各トークンが全ての他のトークンを参照。そのため、計算コストは高くなりますが、全体の関係を把握できます。
一方でローカルアテンションはトークンが近隣のトークンのみに注目をしており、計算コストは低いですが局所的な関係のみに集中します。
ModernBERTでは、グローバルアテンションを3層ごとに適用し、それ以外の層ではローカルアテンションを使用しており、その結果、全体の計算負荷を抑えつつ、必要な情報の抽出能力を維持しています。
Flash Attention
Flash Attentionは注意機構を計算する際のメモリと計算効率を向上させるための最新技術です。
通常のアテンション計算では膨大なメモリを消費しますが、Flash Attentionはメモリアクセスを最適化し、GPU上で効率的に処理することができます。
ModernBERTではグローバルアテンション用とローカルアテンション用を採用しており、メモリ使用量を大幅に削減し、計算速度を向上させています。
ModernBERTの性能
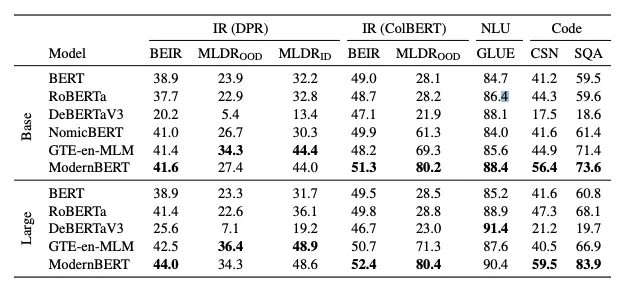
ModernBERT-BaseはGLUEスコアで88.4、ModernBERT-Largeは90.4という高性能を持っています。
そのほかのタスクでも高性能を発揮しており、情報検索タスクとしてのBEIRスイート評価では、短文脈と長文脈の両方で最先端の性能を達成。特に、長文タスクの評価指標であるMLDRベンチマークでは他モデルを大きく上回っています。
他にもCodeSearchNetおよびStackOverflow-QAで最高の精度を記録しており、プログラミングデータを含む事前学習により、コード関連の理解と検索能力も向上しています。
長文処理が可能
ModernBERTは最大8192トークンの長文を処理できます。長文のテキスト検索(MLDRタスク)で高いスコアを示し、他の長文脈対応モデル(GTE-en-MLMなど)よりも高い精度を発揮しています。
従来のBERTは512トークンまでだったため、長いテキストを一つのベクトルに変換できず、小さなチャンクに分けてベクトル変換をしていました。
しかし、ModernBERTが登場したことにより、これまで小さなチャンクにわけていた処理を行わずに一つのベクトルに変換が可能になり、RAGの実装時に重宝されるモデルとなりました。
ModernBERTでできること
ModernBERTでできることはいくつかあり、例えば、自然言語処理タスクとして、文の分類や質問応答、文の類似性評価などができ、さらに、情報検索として、ドキュメント検索やデータベースからの検索なども可能です。
ModernBERTの応用例
ModernBERTは自然言語処理タスクを得意としていますので、顧客レビュー分析やカスタマーサポート用のチャットボットなどの応用例が考えられるでしょう。
またドキュメント検索もできますので、RAGに組み込むことも考えられます。チャットアプリに自社のドキュメントを読み込ませて自社専用のドキュメント検索チャットボットなんかも開発ができますね。
その他にも論文の分類や検索など、テキストを主とした処理で様々な場面で活躍するでしょう。
ModernBERTのライセンス
ModernBERTのライセンスはApacheライセンス 2.0。Apacheライセンス 2.0は特許ライセンスを含んでいるため、商用利用を含む幅広い使用が可能。再配布や改変時に、元のライセンス条項と表示が求められます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、洗練されたUIのオープンRAGシステムについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

ModernBERTの使い方
ModernBERTの使い方はHugging Faceに掲載されています。
こちらを元にgoogle colaboratoryで実装します。
ModernBERTをgoogle colaboratoryで実装
◼︎システム RAM
3.9 / 83.5 GB
◼︎GPU RAM
1.5 / 40.0 GB
◼︎ディスク
34.8 / 112.6 GB
◼︎GPUの種類:A100
◼︎プラン:有料
まずは必要ライブラリなどのインストールをします。
必要ライブラリのインストールはこちら
!pip install triton
!pip install flash-attn
!pip install transformers
!pip install torch
!pip install git+https://github.com/huggingface/transformers.gitインストールが終了したらサンプルコードを動かせばOKです。
サンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
# デバイスの確認
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# モデルの読み込み(bfloat16を使用)
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# テキストの処理
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt").to(device)
# 推論の実行(自動混合精度を使用)
with torch.cuda.amp.autocast():
outputs = model(**inputs)
# マスクされた位置の予測を取得
mask_token_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, mask_token_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print(f"Predicted word: {predicted_token}")結果はこちら
Predicted word: Parisモデルのダウンロード時間を含めて結果出力までは約43秒で、かなり高速な印象を受けました。
モデルダウンロード済みで実行すると2秒くらいで完了しました。
ModernBERTとBERT-baseモデルを比較検証
まずModernBERTでいくつか基本的なタスクを行い、できる内容を確認します。
基本タスクとしては、まず以下の2つのタスクを行ってみます!
- テキスト検索
- コード関連タスク
さらに、従来のBERT-Baseモデルと同じタスクを行わせてみて、どういった違いが出るかを検証してみたいと思います。
比較タスクは次の2つです。
- マスク
- 文章類似度
ModernBERTでテキスト検索
まずはテキスト検索です。
サンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModel
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
def get_text_embedding(text):
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True).to("cuda")
with torch.amp.autocast('cuda'):
outputs = model(**inputs)
return outputs.last_hidden_state.mean(dim=1)
# 文書データベース
documents = [
"Python is a popular programming language",
"JavaScript is used for web development",
"Machine learning uses statistical methods"
]
# 検索クエリ
query = "What programming languages are popular?"
query_emb = get_text_embedding(query)
# 類似度に基づいて関連文書を検索
docs_emb = torch.cat([get_text_embedding(doc) for doc in documents])
similarities = torch.cosine_similarity(query_emb, docs_emb)
# 最も関連性の高い文書を表示
top_idx = similarities.argmax().item()
print(f"Most relevant document: {documents[top_idx]}")結果はこちら
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
Most relevant document: Python is a popular programming languageしっかりと文書データベースを元に回答することができていますね。ちなみにGPT-4oでも同じように質問したら全く同じ回答が返ってきました。
コード関連タスク
次にコード関連タスクとして、Fibonacci数列を実装してもらいます。
サンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModel
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
def search_code(query, code_snippets):
query_emb = get_text_embedding(query)
code_embs = torch.cat([get_text_embedding(code) for code in code_snippets])
similarities = torch.cosine_similarity(query_emb, code_embs)
top_idx = similarities.argmax().item()
return code_snippets[top_idx]
# 使用例
code_snippets = [
"def fibonacci(n):\n return n if n <= 1 else fibonacci(n-1) + fibonacci(n-2)",
"def quick_sort(arr):\n if len(arr) <= 1: return arr",
"def binary_search(arr, x):\n left, right = 0, len(arr)-1"
]
query = "How to implement fibonacci sequence"
relevant_code = search_code(query, code_snippets)
print(f"Relevant code:\n{relevant_code}")結果はこちら
Relevant code:
def fibonacci(n):
return n if n <= 1 else fibonacci(n-1) + fibonacci(n-2)同じようにGPT-4oに質問をしたら全く同じ回答が返ってきました。
もしかしたらModernBERTはコーディングの補助としても活用できるかもしれません。ただ、ModernBERTは回答を1種類しか出力してくれませんでしたが、GPT-4oは5種類の選択肢を出してくれました。
単語マスク予測タスク
次に単語マスク予測タスクをModernBERTとBERT baseで比較します。
ModernBERTのサンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
# デバイスの確認
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# モデルの読み込み
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# マスクトークンを使用した入力テキスト
text = "The Eiffel Tower is located in [MASK]."
inputs = tokenizer(text, return_tensors="pt").to(device)
# 推論の実行
with torch.cuda.amp.autocast():
outputs = model(**inputs)
# マスクされた位置の予測を取得
mask_token_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, mask_token_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
# 上位5つの予測を表示
topk = torch.topk(outputs.logits[0, mask_token_index], k=5)
top_tokens = [tokenizer.decode(token_id) for token_id in topk.indices]
print(f"入力文: {text}")
print(f"最も確率の高い予測: {predicted_token}")
print(f"上位5つの予測: {', '.join(top_tokens)}")結果はこちら
入力文: The Eiffel Tower is located in [MASK].
最も確率の高い予測: Paris
上位5つの予測: Paris, France, Switzerland, Belgium, GenevaBERT-baseのサンプルコードはこちら
from transformers import BertTokenizer, BertForMaskedLM
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# GPUが利用可能な場合は使用
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
def predict_masked_word(text):
# 入力のトークン化
inputs = tokenizer(text, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
# 予測の実行
with torch.no_grad():
outputs = model(**inputs)
# マスクトークンの位置を特定
mask_token_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
# 上位5個の予測を取得
top5_tokens = torch.topk(outputs.logits[0, mask_token_index], 5)
predictions = [tokenizer.decode([token_id]) for token_id in top5_tokens.indices]
return predictions
# テスト
text = "The Eiffel Tower is located in [MASK]."
predictions = predict_masked_word(text)
print(f"Top 5 predictions: {predictions}")結果はこちら
Top 5 predictions: ['paris', 'luxembourg', 'brussels', 'france', 'monaco']正解はParisです。
ModernBERTとBERT baseの回答にはどちらもParisが含まれていました。しかし、それ以外の地名はModernBERTとBERT-baseでは異なるため、学習の違いや学習量の違いが影響しているのかもしれません。
文章類似度タスク
次に文章の類似度タスクです。
ModernBERTのサンプルコードはこちら
import torch
from transformers import AutoTokenizer, AutoModel
from torch.nn.functional import cosine_similarity
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# モデルの読み込み - AutoModel を使用
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
def get_embeddings(sentences):
# バッチ処理で効率化
inputs = tokenizer(
sentences,
padding=True,
truncation=True,
max_length=512,
return_tensors="pt"
).to(device)
with torch.amp.autocast('cuda'):
outputs = model(**inputs)
# 平均プーリングで文の埋め込みを取得
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings
# テスト文
test_pairs = [
("Paris is the capital of France.", "The main city of France is Paris."),
("I love eating apples.", "Apples are my favorite fruit."),
("The cat is sleeping.", "The dog is running."),
]
# 各ペアの類似度を計算
for sent1, sent2 in test_pairs:
# 両方の文の埋め込みを一度に取得
embeddings = get_embeddings([sent1, sent2])
emb1, emb2 = embeddings[0], embeddings[1]
similarity = cosine_similarity(
emb1.unsqueeze(0),
emb2.unsqueeze(0)
).item()
print(f"\nSentence 1: {sent1}")
print(f"Sentence 2: {sent2}")
print(f"Similarity: {similarity:.4f}")結果はこちら
Sentence 1: Paris is the capital of France.
Sentence 2: The main city of France is Paris.
Similarity: 0.9855
Sentence 1: I love eating apples.
Sentence 2: Apples are my favorite fruit.
Similarity: 0.9503
Sentence 1: The cat is sleeping.
Sentence 2: The dog is running.
Similarity: 0.9826BERT-baseのサンプルコードはこちら
from transformers import BertTokenizer, BertModel
import torch
from torch.nn.functional import cosine_similarity
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
model = model.to(device)
def get_sentence_embedding(text):
# トークン化
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
# 埋め込みの取得
with torch.no_grad():
outputs = model(**inputs)
# [CLS]トークンの出力を使用
return outputs.last_hidden_state[:, 0, :]
# テスト文
sent1 = "I love eating apples."
sent2 = "Apples are my favorite fruit."
# 埋め込みの取得と類似度の計算
emb1 = get_sentence_embedding(sent1)
emb2 = get_sentence_embedding(sent2)
similarity = cosine_similarity(emb1, emb2)
print(f"Similarity score: {similarity.item():.4f}")結果はこちら
Similarity score: 0.9593全く同じスコアにはなりませんでしたが、ほぼ同じ結果と言っていいでしょう。処理時間自体も大差はなかったので、短文ではそこまで違いが明確にはならないかもしれません。
なお、科学文献に強いAIエージェントについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではModernBERTの概要からgoogle colaboratoryでの使い方を紹介しました!
そんなModernBERTの特徴をまとめると、
- 高速・高性能:GLUEスコアなどの評価指標で高い精度を記録しながら、処理速度も向上。
- 長文対応:最大8192トークンに対応し、これまで難しかった長文処理が可能に。
- 効率的な計算技術:Unpadding、Sequence Packing、Alternating Attention、Flash Attentionを採用し、計算負荷を削減。
といったことが挙げられます。
長文にも対応したことにより、これまでやりたくてもできなかったテキスト処理を実現できるようになるため、RAGの実装などで重宝されるのではないでしょうか?
最後に
いかがだったでしょうか?
長文対応が可能なモデルを活用することで、膨大なマニュアルや契約書、技術資料から必要な情報を迅速に検索できるだけでなく、顧客対応における回答のスピードアップや業務効率化にも繋がります。
業務改善や生成AI導入を検討中の方は、この機会にぜひ次のステップをご検討ください!
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

