
【MVDream】TikTok、ByteDanceのテキストから高精度の3D画像を生成するAIモデルを使ってみた

WEELメディア事業部LLMリサーチャーの中田です。
8月31日、TikTokを運営するByteDanceから「MVDream」が公開され、誰でも簡単にテキストプロンプトから3D生成できるようになりました。
これを用いることで、以下のような高品質な3Dを生成できるんです…!
GitHubのスター数は900ほどですが、ByteDanceの技術ということもあり、TikTokにも何かしら反映されるでしょう。
この記事ではMVDreamの使い方や、有効性の検証まで行います。本記事を熟読することで、MVDreamの凄さを実感し、思い思いの3Dキャラクターを量産したくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
MVDreamの概要
MVDreamは画像拡散モデルの一種で、テキストから2Dや3Dを生成できるAIモデルです。
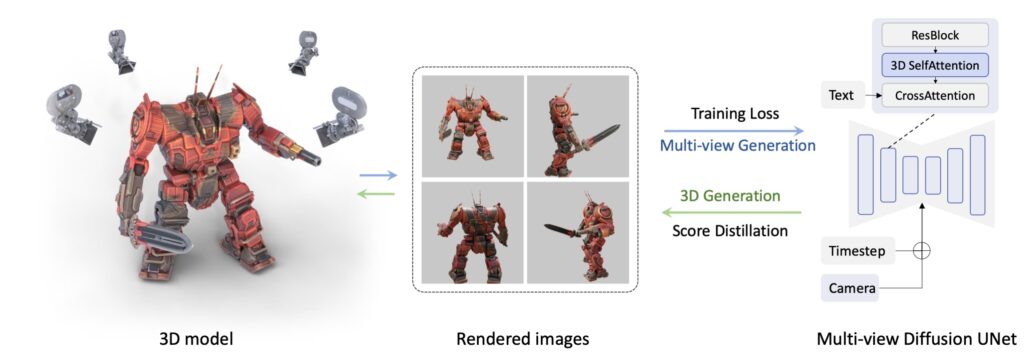
また、MVDreamはByteDanceとカリフォルニア大学サンディエゴ校の共同プロジェクトで、テキストプロンプトからリアルな3Dモデルを生成できることを示しています。具体的なMVDreamの生成能力は、以下のプロジェクトページで確認することができるので、ぜひ参考にしてください。※1
DreamFusionやMagic3Dなど従来の2D-lifting手法は、Stable Diffusionのような2D拡散モデルを使って3D構築を試みるものです。しかし、これらの手法では、顔が複数生成されてしまうことや視点ごとにコンテンツが変化してしまう(=Content Drift)という問題がありました。
そこで、MVDreamは上記の問題に対して、複数視点を同時に生成する拡散モデル(Multi-view diffusion model)を構築し、2Dと3Dデータ両方を活用して、一貫性のある複数画像を同時に生成して3Dモデルを作成します。


MVDreamの技術
MVDreamの中心技術は3つです。
- Inflated 3D Self-Attention
- Camera Embeddings
- Multi-view Diffusion Training
それぞれarxivに掲載されている論文を元に解説をします。※2
Inflated 3D Self-Attention
Inflated 3D Self-Attention(膨張型3D自己注意)は2D Attentionの空間拡張による多視点統合です。
Stable Diffusionなど従来の拡散モデルは「1画像 = 1サンプル」で処理。これを「複数のカメラ視点」 = 1つのサンプルと捉えて空間的に連結したToken列として処理する、というのがInflated 3D Self-Attentionの原理です。
動画生成モデルでは、フレーム間の整合性を保つために「Temporal Attention(1D的)」が使われますが、MVDreamでは使用できません。
MVDreamは時系列ではなく空間的に異なる視点であるため、同じピクセル位置 = 同じ意味とは限りません。異なる角度から見た物体は、同じ部位が違う位置に写るため、Temporal Atentionでは整合性を保てず、Content Driftが発生します。
論文内では、新たな3D Attention層を追加することは、一貫性は得られるが生成品質が著しく低下。そこで高品質なまま一貫性も確保できるように既存2D Attention層を膨張して視点方向に拡張するという手法を採用しています。※2
“Note that we also experimented with incorporating a new 3D self-attention layer rather than modifying the existing 2D one. However, we found that such a design compromised the generation quality of multi-view images.”
“The proposed strategy of inflated 2D self-attention achieves the best consistency among all without losing generation quality.”
引用:MVDream: Multi-view Diffusion for 3D Generation
Camera Embeddings
Camera Embeddings(カメラ条件の埋め込み)は、Attentionにおける視点ごとの識別情報の埋め込みです。
多視点画像を同時生成するには「どの画像がどの視点か」を明示する必要があります。人間で言えば、「これは背面から見た図」「これは斜め前から見た図」と認識するメタ情報です。
MVDreamでは、カメラの外部パラメータ(4×4行列)を2層MLPで低次元ベクトルに変換し、Attentionに埋め込むことで、これを実現。
通常のText-to-Imageモデルは視点の違いを考慮しないため、基本的にはすべて正面からの図になります。そのため、モデルに「この画像は〇〇方向から見たものだ」と理解させなければ、複数画像が一貫した物体を生成できません。
Camera Embeddingsを採用することで、同じプロンプトから明確に異なる視点の画像が生成可能、視点ごとの画像がすべて同じ物体を異なる方向から見たものになる、SDSによる3D最適化時にも、正確なカメラ制御が可能といった効果があります。
つまりCamera Embeddingsは明確な視点制御を実現するために不可欠な技術です。
Multi-view Diffusion Training
Multi-view Diffusion TrainingはMVDreamが従来の2D拡散モデルでは不可能だった3D的整合性(multi-view consistency)を学習段階から獲得する仕組み。
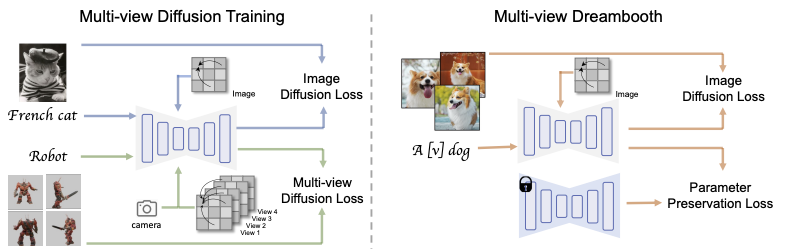
MVDreamは「2D拡散モデルの柔軟さ・多様さ」を維持しつつ、「3D的に矛盾しない画像群」を生成できるようにすることを目指しています。そのために、MVDreamの学習は以下の2つのパートから構成されています。
- Image Mode(通常の2D画像学習)
- Multi-view Mode(3Dデータを使った多視点学習)
Image Modeは、従来のテキストから画像を生成する2D拡散モデル(例:Stable Diffusion)と同様の学習方法。このモードでは、テキストとそれに対応する単一の画像(1ビュー)を入力として使用し、ノイズ予測の誤差に基づく損失関数(Image Diffusion Loss)を用いて学習が行われます。
Multi-view Modeは、3Dオブジェクトを複数のカメラ視点からレンダリングした画像群(例:4視点)と、それぞれのカメラの外部パラメータを使って訓練する学習モードです。
このモードでは、テキストと複数画像、およびカメラ情報を同時に入力し、拡散モデルが一貫性のあるマルチビュー画像を同時生成できるようになることを目指して学習。
ここでは、通常の2D拡散損失に加えて、視点間の構造的整合性を評価するMulti-view Diffusion Lossが導入されます。
MVDreamの料金体系とライセンス
MVDreamオープンソースとして公開されており、Apache-2.0ライセンスのもとで無料で使用することができます。
| 利用用途 | 可否 |
|---|---|
| 私的利用 | ⭕️ |
| 商用利用 | ⭕️ |
| 特許利用 | ⭕️ |
| 改変 | ⭕️ |
| 再配布 | ⭕️ |
なお、ByteDanceが開発した動画生成AIについて知りたい方はこちらの記事をご覧ください。

MVDreamの使い方
今回は、Google ColabのT4で実行しました。まずは、以下のURLを参考に、threestudioのインストールを完了させておいてください。
次に、以下のコードを実行してください。
!pip install ninja
!pip install -r requirements.txtそして、以下のコードを実行して、MVDreamをインストールしましょう。
!git clone https://github.com/bytedance/MVDream extern/MVDream
!pip install -e extern/MVDreamここまで完了したら、以下のコードを実行してみてください。「an astronaut riding a horse」というプロンプトでの3D生成が可能になります。
# MVDream without shading (memory efficient)
python launch.py --config configs/mvdream-sd21.yaml --train --gpu 0 system.prompt_processor.prompt="an astronaut riding a horse"MVDreamを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.8以上
■必要なパッケージ
Pytorch 1.12以上
CUDA
20GB VRAM
MVDreamを実際に使ってみた
試しに先ほどの「an astronaut riding a horse」というプロンプトを入力してみます。すると、以下のような結果になりました。
かなり精度が高いですね!
これを応用すれば、自分の好きなキャラクターの3Dも、生成できちゃうんじゃないでしょうか?ただ、今のところ、生成した3Dオブジェクトを動かすみたいなことは、できないようです。
なお、AIによるショート動画生成について詳しく知りたい方は、下記の記事を合わせてご確認ください。

MVDreamの推しポイントである高性能3D生成は本当なのか?
ここでは、MVDreamの高性能3Dの根幹である内部構造を、詳しく解説します。
通常、3Dオブジェクトを作る際、ある2Dオブジェクトを「様々な角度」から見る必要があります。
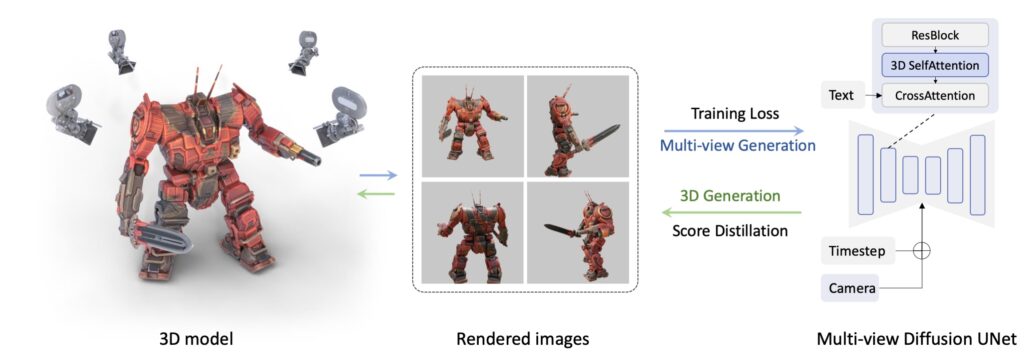
ここで、例えば「犬が虹色のカーペットの上に座っている」というテキストをモデルに入力すると、MVDreamはそれを基に「犬を様々な角度から見た画像」を生成します。そして、「DreamBooth」という技術を使用して、それら数枚の画像から新しいコンセプトを学び、それを3D生成に適用することができます。

要するに、「多角的な視点での画像を生成し、それを3Dに適用する」ということをやっているのです。


よくある質問
まとめ
MVDreamは画像拡散モデルの一種で、テキストから2Dや3Dを生成できるAIモデルです。このAIを使うことで、思い思いのキャラクターを動かせるようになるかも?
かなり精度が高く、応用次第では自分の好きなキャラクターの3Dも、生成できるでしょう。ただ、今のところ、生成した3Dオブジェクトを動かすみたいなことは、できないようです。
MVDreamの仕組みを一言で表すと「多角的な視点での画像を生成し、それを3Dに適用する」です。
数年後には、誰でもメタバース空間で自分の好きな3Dモデルを、動かせるようになっているのかもしれないですね。

最後に
いかがだったでしょうか?
最先端3D生成AIの活用事例を、自社のプロダクトにどう活かせるか。戦略立案のヒントを得たい方は必見です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

