
GoogleのPaliGemma 2を試してみた!初心者でも使える機能と使ってみた感想まとめ

2024/12/5、Googleより新たな視覚言語モデル「PaliGemma 2」が登場!
PaliGemma 2はPaliGemmaの改良版として、3B・10B・28Bパラメータのモデルが登場し、解像度も複数サポートすることで柔軟性が向上。DOCCIデータセット(高精度な画像キャプション生成を目指す特化型データセット)でファインチューンされたモデルも公開され、高精度なキャプション生成能力が示されています。
- モデルサイズは3種類
- 物体検出・OCRも可能
- 高解像度で性能向上
本記事では、PaliGemma 2が従来のものとどう変わったのか、どのように使うのか解説をします。本記事を最後まで読めば、PaliGemma 2を使いこなせるようになります!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
PaliGemma 2の概要
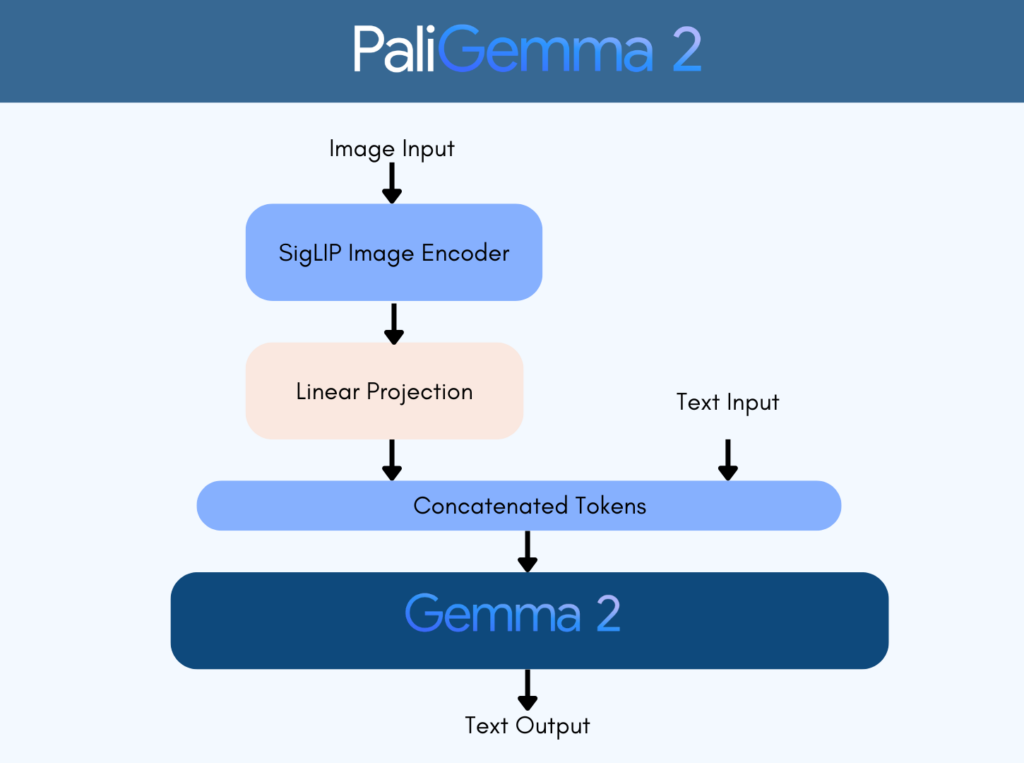
PaliGemma 2はSigLIPを使用した画像エンコーダーとGemma 2言語モデルを組み合わせた新しいモデルであり、3B、10B、28Bパラメータの3つのサイズで提供され、入力解像度は224×224、448×448、896×896に対応しています。
DOCCIデータセットを用いたファインチューニングにより、詳細な画像キャプション生成が可能です。
DOCCIデータセット:画像と言語の研究を目的に設計されたデータセットで、テキストから画像 (T2I) と画像からテキスト (I2T) の両モデルのトレーニングと評価が可能。
SigLIPについて
SigLIP(Sigmoid Loss for Language-Image Pre-Training)は、画像と言語の組み合わせに対する学習アルゴリズムを改良したモデルです。
CLIPでは一般的なソフトマックス正規化を使用しますが、SigLIPではシンプルなペアワイズで計算される損失関数を採用し、Sigmoid関数を利用しています。
このアプローチは、ソフトマックス正規化とは異なり、バッチ全体のペアワイズ類似度のグローバルビューを必要とせず、バッチサイズの拡大が可能な一方で、小規模バッチサイズでも高い性能を発揮します。
結果として、SigLIPはリソースが限られた環境でも画像と言語の学習効率を大幅に向上させる、新しい手法として注目されています。
PaliGemma 2の事前トレーニング
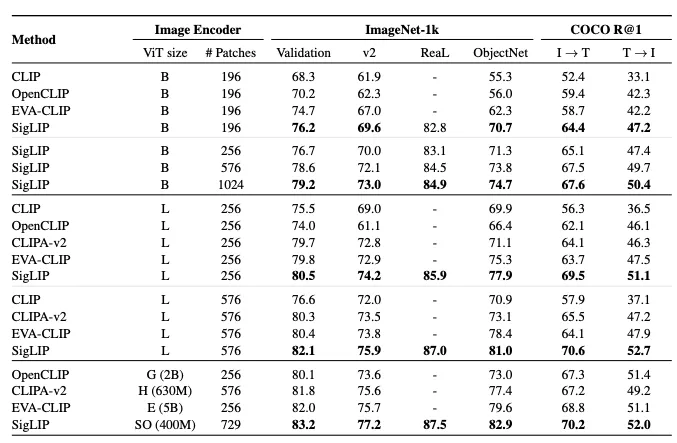
PaliGemma 2の事前トレーニングには、多言語対応の大規模な画像テキストデータセットが用いられています。
主な事前トレーニングデータセットは、次のとおりです。
- WebLI:ウェブ上の公開データを活用した大規模な多言語画像テキストペアデータセット。
- CC3M-35L:英語の画像テキストペア(キャプション付き画像)をベースに、Google Cloud Translation APIを用いて34言語に翻訳。
- OpenImages:オブジェクト認識に関する質問応答形式のデータ。
- WIT:Wikipediaから収集した画像と言語データセット。
- VQ2A:質問応答タスクのためのデータセットで、Google Cloud Translation APIを利用して多言語化。
事前トレーニングにより、視覚言語タスクでの性能が大幅に向上し、特にファインチューニング時に、モデルが新たなタスクやドメインに迅速に適応ができます。
PaliGemma 2とPaliGemmaの違い
PaliGemmaはGemma 1(2Bパラメータ)の言語モデルを採用しており、PaliGemma 2はGemma 2ファミリーを採用。また、PaliGemma 2はモデルサイズが3B、10B、28Bと豊富です。
また、PaliGemmaはキャプション生成やVQA、短い動画に限定されたタスクが中心だったのに対し、PaliGemma 2ではテキスト検出・認識や表構造認識、分子構造認識、放射線画像報告生成など汎用性が向上しています。
PaliGemma 2モデルのキャプション生成性能はこちら。解像度を高くすることで、多くのタスクにおいて性能が向上し、テキスト情報が重要なデータセットでは、解像度の向上により大幅な性能向上を示しています。
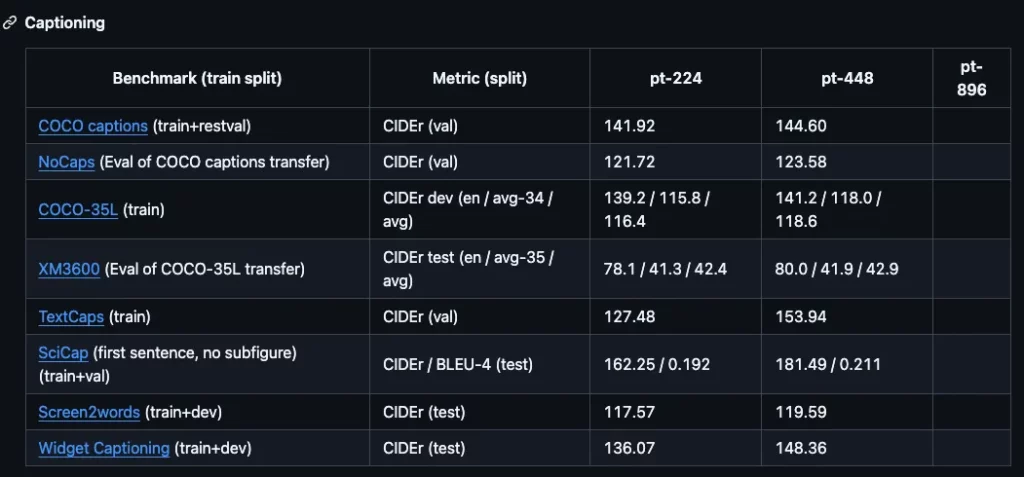
パフォーマンスとしては、PaliGemmaは同等の解像度とサイズで、従来のVLMと競合する性能であったのに対して、PaliGemma 2は同じ解像度とモデルサイズで、PaliGemmaを上回る性能を示し、高解像度および大規模モデルで大幅な改善を実現。
まとめるとPaliGemma 2は、PaliGemmaをもとに、モデルのサイズや解像度、対応タスクを大幅に広げ、多様な分野に活用可能になった視覚言語モデルです。特に、新たなタスク対応や高解像度対応による性能向上が際立っています。


PaliGemma 2のライセンス
PaliGemma 2のライセンスは「gemma」とされています。
ライセンスgemmaはGemmaモデルの利用規約に基づきます。特許使用については明記がありません。また、それ以外の項目についても可能ではあるものの、さまざまな条件があります。
商用利用については、利用規約の遵守・必要に応じて適用法規に準拠する必要があります。改変は改変内容を明示し改変後も規約の条件を遵守、配布は「Gemma利用規約」のコピーを配布先に提供する必要などがあります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明 |
| 私的使用 | ⭕️ |
なお、ベンチマークでGPT-4oを超えた!GoogleのGeminiモデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

PaliGemma 2の使い方
PaliGemma 2を実装します。デモ版も用意されているのでまずはデモ版を使ってみます。
視覚言語モデルなので、画像をアップロードしてどういう感情なのか読み取ってもらいましょう。
画像をアップロードして、質問内容を「どんな感情?」入力します。questionと書かれていますが、日本語で書いても回答はしてくれますが回答は英語でangryになりました。
ちなみにPaliGemma 2では物体識別やOCRも行えます。
プロンプトは「List all objects visible in this image and Read all the text visible in this image.」としました。
和訳:この画像に表示されているすべてのオブジェクトをリストアップし、この画像に表示されているすべてのテキストを読む。
結構細かく丁寧に出力してくれたように思います。次はgoogle colaboratoryを使って実装してみます。
google colaboratoryでPaliGemma 2を実装する
google colaboratoryで使うにはHugging Faceで承認を受ける必要があります。
Authorizeをクリック後、Googleのポリシーに同意する画面に移るので同意すればすぐにアクセスできるようになります。
実装した時のgoogle colaboratory環境は以下です。
◼︎Pythonバージョン
Python3.8以上
◼︎システム RAM
18.7 / 83.5 GB
◼︎GPU RAM
0.0 / 40.0 GB
◼︎ディスク使用量
38.3 / 112.6 GB
まずはライブラリのインストールを行います。
!pip install transformers pillow torchHugging Faceのログインはこちら
from huggingface_hub import login
# ここにトークンをペースト
login(token="your_token")サンプルコードはこちら
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration
from transformers.image_utils import load_image
import torch
# モデルID
# 3B / 10B / 28Bから選択
model_id = "google/paligemma2-3b-pt-224"
# モデルとプロセッサをロード
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float32)
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Colab上の画像パス
file_path = "" # あなたの画像パスを指定
image = load_image(file_path)
# プロンプトに画像トークンを追加
# 空欄でも可能
prompt = ""
# 入力データを作成
inputs = processor(text=prompt, images=image, return_tensors="pt")
# キャプション生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100, do_sample=True)
decoded = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated Caption:", decoded)読み込ませた画像はこちらです。

プロンプトを空欄にして画像を読み込ませた結果がこちらです。
結果はこちら
You are passing both `text` and `images` to `PaliGemmaProcessor`. The processor expects special image tokens in the text, as many tokens as there are images per each text. It is recommended to add `<image>` tokens in the very beginning of your text and `<bos>` token after that. For this call, we will infer how many images each text has and add special tokens.
Generated Caption:
11 signs of toxic and manipulative people怒っている人の画像を読み込ませましたが、結果を和訳すると「有害で人を操る11の兆候」となりました。プロンプトはちゃんと入力しないと人が理解できない出力がされてしまうかもしれません。
PaliGemma 2とPaliGemmaの性能を比較してみた
PaliGemma 2の性能がPaliGemmaよりも向上しているのか、同じタスクを両モデルで実行してみて正確性を検証してみたいと思います。
行うタスクは次の2つです。
- 顔写真を読み込ませて感情を答えさせる
- 機械学習の本に出てくるような画像を読ませて、内容をわかりやすく説明させる
上記2つを行います。
モデルサイズは両モデルとも3Bで行います。
顔写真を読み込ませて感情を答えさせるタスク
では写真を読み込ませるタスクを行います。
プロンプトは「What emotion is being expressed in this image?」と入力します。
和訳:この画像ではどんな感情が表現されているのだろうか?
読み込ませる画像は2種類です。

コードは以下です。
paligemma2のサンプルコードはこちら
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration
from transformers.image_utils import load_image
import torch
# モデルID
# google/paligemma-3b-mix-224
model_id = "google/paligemma2-3b-pt-224"
# モデルとプロセッサをロード
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float32)
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Colab上の画像パス
file_path = "" # あなたの画像パスを指定
image = load_image(file_path)
# プロンプトに画像トークンを追加
prompt = "What emotion is being expressed in this image?"
# 入力データを作成
inputs = processor(text=prompt, images=image, return_tensors="pt")
# キャプション生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100, do_sample=True)
decoded = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated Caption:", decoded)怒っている画像のpaligemma2の結果はこちら
Generated Caption: What emotion is being expressed in this image?
angry泣いている画像のpaligemma2の結果はこちら
You are passing both `text` and `images` to `PaliGemmaProcessor`. The processor expects special image tokens in the text, as many tokens as there are images per each text. It is recommended to add `<image>` tokens in the very beginning of your text and `<bos>` token after that. For this call, we will infer how many images each text has and add special tokens.
Generated Caption: What emotion is being expressed in this image?
angerpaligemmaのサンプルコードはこちら
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration
from transformers.image_utils import load_image
import torch
# モデルID
# google/paligemma-3b-mix-224
model_id = "google/paligemma-3b-mix-224"
# モデルとプロセッサをロード
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float32)
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Colab上の画像パス
file_path = "" # あなたの画像パスを指定
image = load_image(file_path)
# プロンプトに画像トークンを追加
prompt = "What emotion is being expressed in this image?"
# 入力データを作成
inputs = processor(text=prompt, images=image, return_tensors="pt")
# キャプション生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=100, do_sample=True)
decoded = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated Caption:", decoded)怒っている画像のpaligemmaの結果はこちら
Generated Caption: What emotion is being expressed in this image?
anger泣いている画像のpaligemmaの結果はこちら
Generated Caption: What emotion is being expressed in this image?
sadness同じタスクを行いましたがpaligemma2では泣いている画像をanger:怒り、と捉えてしまいました。どちらかといえば泣いているや悲しんでいるが適切かなと思うので、paligemmaの方が正確に捉えられている気がします。
機械学習の本に出てくるような画像を読ませて、内容をわかりやすく説明させる
次に画像の内容を説明してもらいます。説明してもらうのは、こちらの画像です。
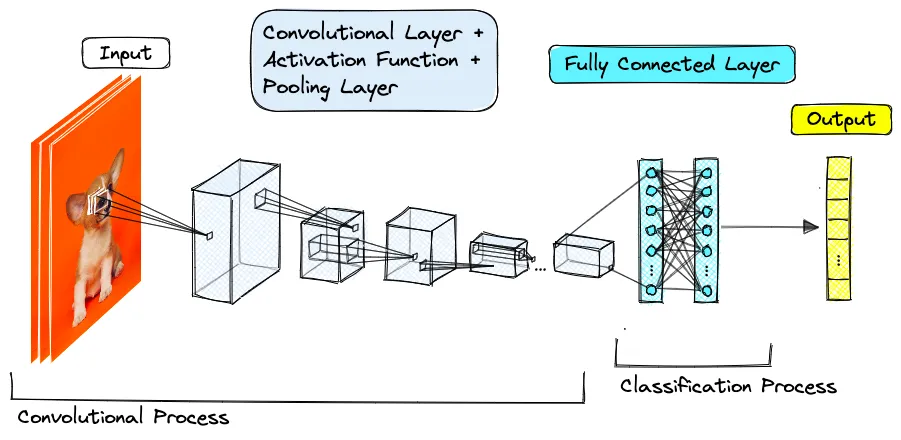
入力したプロンプトは「Please describe this image in detail, including objects, colors and actions.」です。
和訳:オブジェクト、色、アクションを含め、この画像の詳細な説明をしてください。
paligemma2のサンプルコードはこちら
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration
from transformers.image_utils import load_image
import torch
# モデルID
# google/paligemma-3b-mix-224
model_id = "google/paligemma2-3b-pt-224"
# モデルとプロセッサをロード
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float32)
processor = PaliGemmaProcessor.from_pretrained(model_id)
# Colab上の画像パス
file_path = "" # あなたの画像パスを指定
image = load_image(file_path)
# プロンプトに画像トークンを追加
prompt = "<image> <bos> Please describe this image in detail, including objects, colors and actions."
# 入力データを作成
inputs = processor(text=prompt, images=image, return_tensors="pt")
# キャプション生成
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=300, do_sample=True)
decoded = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated Caption:", decoded)paligemma2の結果はこちら
Generated Caption: Please describe this image in detail, including objects, colors and actions.
examplepaligemmaの結果はこちら
Generated Caption: Please describe this image in detail, including objects, colors and actions.
pixel-level semantic features from different categories .こちらのタスクではどちらのモデルも正確な回答はしてもらえませんでした。
畳み込みニューラルネットワークの構造を〜〜というような回答を期待していたのですが、プロンプトの影響でしょうか。感情を読み取る方がまだ知りたいことを回答してくれていたように思います。
なお、GoogleのGemmaをコーディングタスクに特化させたLLMの使い方について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではPaliGemma 2についてPaliGemmaとの変更点やgoogle colaboratoryでの使い方について解説をしました。PaliGemma 2とPaliGemmaを比較するタスクでは、こちらの思っていた回答とは異なる点もあり、まだまだこれから使い込んでいって、使い方を理解する必要があるなと感じました。
ぜひ皆さんも本記事を参考にPaliGemma 2を使ってみてください!
最後に
いかがだったでしょうか?
生成AIの活用で業務効率や顧客体験を向上させませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


