
【Qwen3-TTS-Flash】日本語含む10言語対応の多言語音声生成モデルを徹底解説

- Alibaba発の最新テキスト音声合成(TTS)モデル
- 英語・日本語・中国語・フランス語などの10言語に加え、北京語や上海語、広東語など多様な中国方言もサポートするマルチリンガル・マルチダイアレクト対応
- 公式発表によると、ベンチマークで既存モデルを上回る性能を誇り、特に「発話の安定性」と「音色の類似度」において優位性がある
2025年9月23日、Alibaba社は次世代のテキスト音声合成(TTS)モデル「Qwen3-TTS-Flash」をリリースしました!
Qwen3-TTS-Flashは17種類の音声プリセットを備えており、英語・日本語・中国語・フランス語などの10言語に加え、北京語や上海語、広東語など多様な中国方言もサポートするマルチリンガル・マルチダイアレクト対応モデルです。
Qwen3シリーズの音声合成モデルとして、長い文章でも安定して読み上げられる安定性が特徴で、従来モデルと比べて大幅にレイテンシも低減されているとのこと。
本記事では、Qwen3-TTS-Flashの性能や類似ツールとの違い、使い方までを徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Qwen3-TTS-Flashの概要

Qwen3-TTS-Flashは、Alibaba CloudのQwen3ファミリーに属するフラッグシップ音声合成モデルで、ユーザーが入力したテキストを多様な声色で自然に読み上げます。
公式発表によると「マルチティンバー・マルチリンガル・マルチダイアレクト」の音声合成が可能であるとされていて、17種類の音声プリセットが用意されています。これらのプリセットは男性・女性、ニュース風やナレーション調など異なる声質を持ち、声色パラメータを切り替えるだけで別の話者のような音声に切り替えられます。
サポート言語は、中国語・英語・フランス語・ドイツ語・ロシア語・イタリア語・スペイン語・ポルトガル語・日本語・韓国語の10言語で、さらに中国語については、台湾語・上海語・広東語・四川語・北京語・南京語・天津語・陝西語といった複数の方言にも対応しています。
モデル開発チームは、長文テキストでも発話が途切れにくい安定性を強調しており、音声中の発音ミスや雑音を最小限に抑えるよう改良されています。
なお、Qwen3シリーズの最新大規模言語モデル「Qwen3-Next-80B-A3B」について知りたい方は、以下の記事も参考にしてみてください。
類似TTSツールとの違い
Qwen3-TTS-Flashの大きな特徴は、他言語・他方言への対応力と音声の安定性にあります。
海外のTTS技術(Google AudioLM、OpenAI TTS-1、ElevenLabsなど)は英語性能が高いものの、中国語や地域方言に対応しているものは限られています。一方で、本モデルは中国語だけでなく上海語や広東語など主要な方言をネイティブレベルで合成可能です。また、17種の音声プリセットを切り替えられる点も他モデルとの違いとして挙げられます。
さらに、公式ベンチマークではSeedTTSやMiniMax、GPT-4o Audio Preview、ElevenLabsなどを上回る性能が報告されていて、特に発話のヨレや音飛びが少ない安定性と、声色の自然さにおいて優位であることが示されています。
このように、Qwen3-TTS-Flashはマルチ言語合成と高い音声品質を両立しており、従来モデルや他社製品とは一線を画しています。


Qwen3-TTS-Flashの性能
Qwen3-TTS-Flashは、公式発表のベンチマーク結果で最先端の音声合成性能を発揮しています。中国語と英語において特に低いWER(単語誤り率)を達成し、イタリア語・フランス語なども含む4言語でトップクラスの結果となっています。これらの評価では、SeedTTSやMiniMax、ElevenLabsなどの既存モデルを上回り、特に「発話の安定性」と「音色の類似度」において優位性が確認されています。
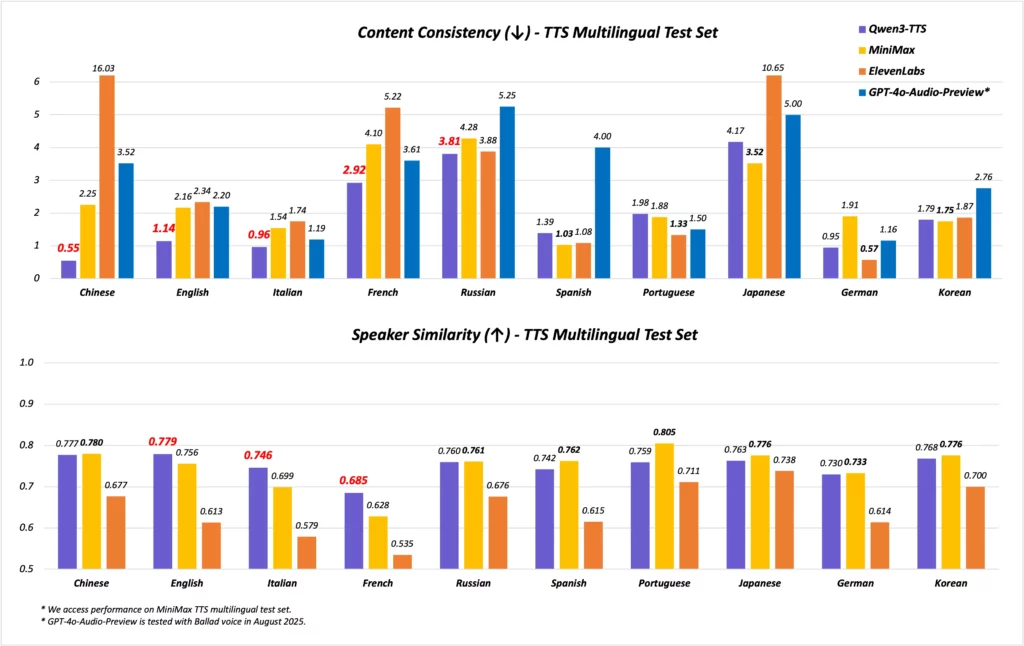

また、レイテンシやリアルタイムファクターも大きく改善されています。公式テストでは、単一並列時における最初の音声パケット到着時間が97msと、従来モデルであるQwen-TTSのおよそ200msに対し半分以下に短縮されています。
Qwen3-TTS-Flashのライセンス
Qwen3-TTS-Flashの正式なライセンス条項は現時点で明示されていませんが、Qwenシリーズの従来モデルはApache 2.0などオープンライセンスで公開されてきた経緯があります。
公式発表でも「通常のオープンソースライセンスの下でモデルチェックポイントが公開予定」と述べられていて、商用利用や改変、再配布も許諾される可能性はあります。一方で、現状ではモデル本体はAPI経由での利用に限定されており、現時点では独自に再配布や改変する形では提供されていないとも案内されています。
今後ライセンス詳細が公開された際には、特許利用を含む条項を必ず確認するようにしましょう。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | 不明 | |
| 改変 | 不明 | |
| 配布 | 不明 | |
| 特許使用 | 不明 | |
| 私的使用 | 不明 |


Qwen3-TTS-Flashの料金
Qwen3-TTS-Flashは、Alibaba CloudのDashScopeプラットフォーム経由で利用でき、文字数課金方式が採用されています。利用料金は1万文字あたり0.8元(約15円)です。100文字あたりに換算すると、約0.0012元(約0.02円)に相当します。
| プラン | 料金 | 無料枠 |
|---|---|---|
| Alibaba Cloud DashScope | 0.8元/1万文字(約15円) | 2,000文字(90日間有効) |
新規ユーザー向けにモデルごとに2000文字のトライアル無料枠が提供されているので、有効活用すると良いかと思います。
Qwen3-TTS-Flashの使い方
Qwen3-TTS-Flashの利用方法は、HuggingFaceデモページ経由とAlibaba Cloud DashScopeの2つの方法があります。
HuggingFaceデモ
HuggingFaceデモページにアクセスすると以下の画面が表示されるかと思いますので、赤枠内に読ませたいテキストを入力しましょう。
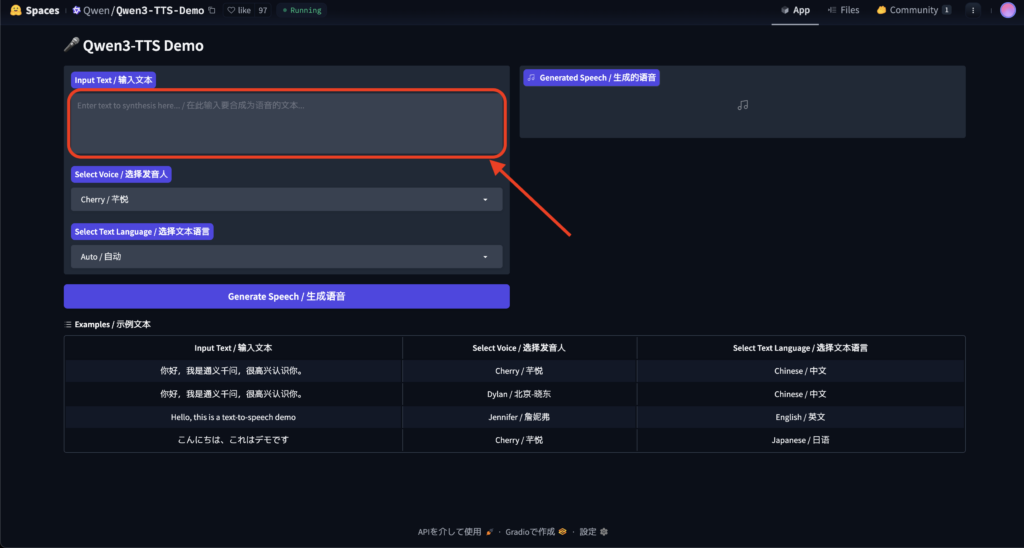
試しに、「こんにちは。私はQwen3-TTS-Flashです。」と入力、言語のプルダウンで日本語を選択して、音声生成してみます。
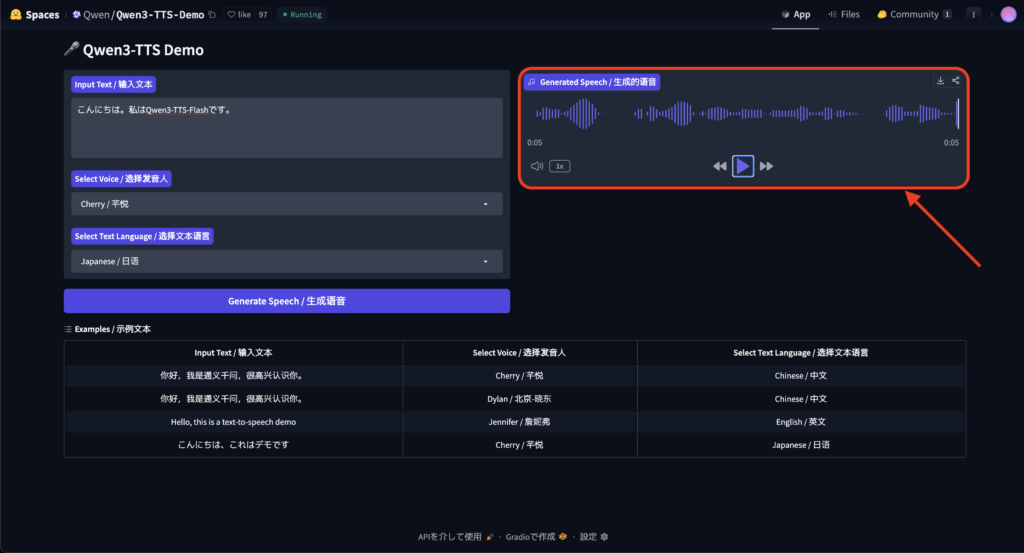
5秒ほどで生成されました。生成された音声はこちら。
正直、精度はいまひとつです。Qwen3-TTS-Flashの強みである長文テキストでも試してみましょう。夏目漱石「吾輩は猫である」の冒頭部分のテキストを入力とします。
吾輩わがはいは猫である。名前はまだ無い。
どこで生れたかとんと見当けんとうがつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪どうあくな種族であったそうだ。この書生というのは時々我々を捕つかまえて煮にて食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌てのひらに載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始みはじめであろう。この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶やかんだ。その後ご猫にもだいぶ逢あったがこんな片輪かたわには一度も出会でくわした事がない。のみならず顔の真中があまりに突起している。そうしてその穴の中から時々ぷうぷうと煙けむりを吹く。どうも咽むせぽくて実に弱った。これが人間の飲む煙草たばこというものである事はようやくこの頃知った。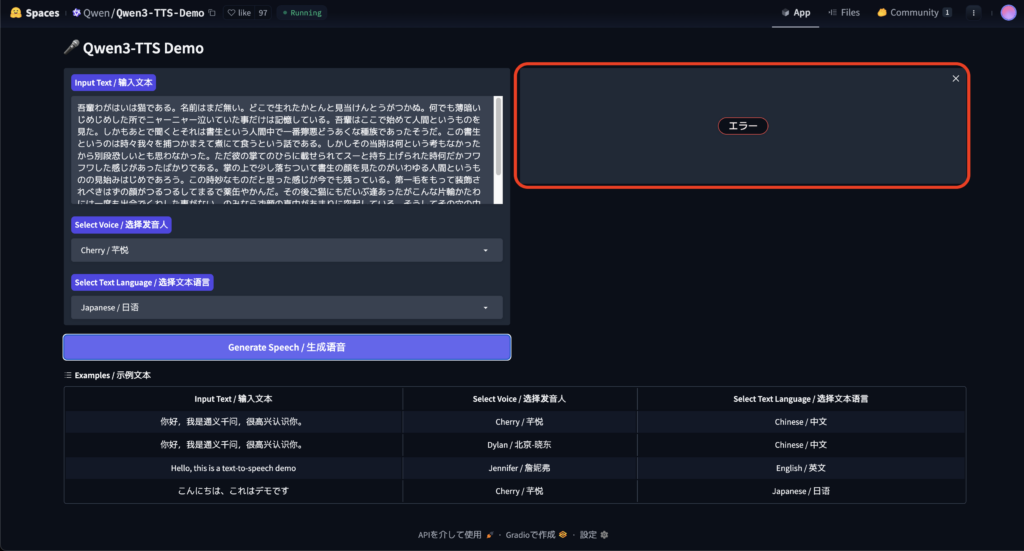
500文字程度のテキストなのですが、生成途中でエラーとなってしまいました。試しに300文字程度までテキストを削減するとうまく生成されました。
吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。この書生というのは時々我々を捕まえて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始めであろう。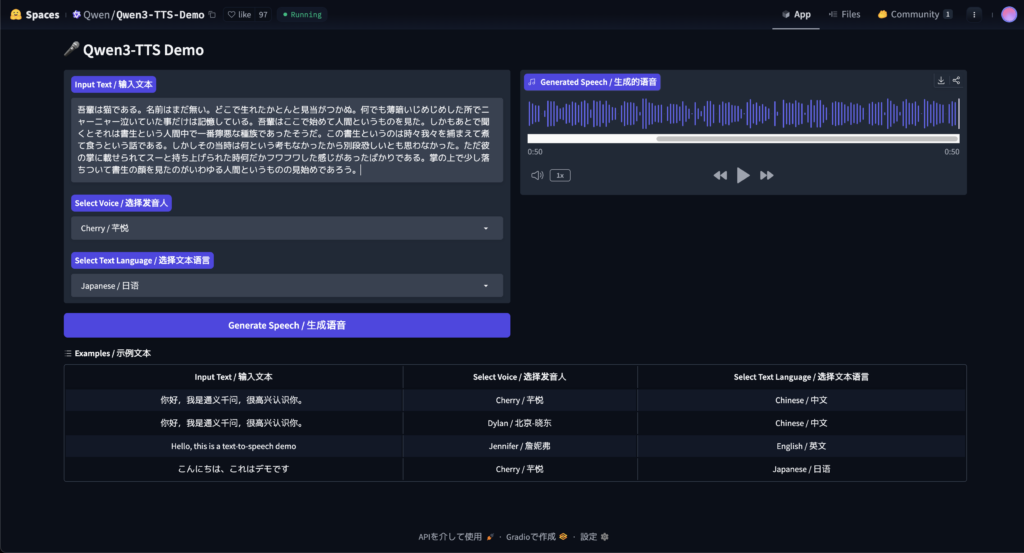
長文テキストでも途切れることなく雑音もありませんが、読み方が間違っていたり、不自然な部分があるのは否めませんね。日本語の精度はあまり高くはない印象でした。
Alibaba Cloud DashScope
APIキーの取得: Alibaba Cloud DashScopeのサービスを利用するには、まずアカウント作成後にAPIキー(DASHSCOPE_API_KEY)を取得します。取得したキーは環境変数に設定するか、コード内で指定します。
環境構築: DashScopeのSDKをインストールします。Pythonであればdashscopeライブラリを、JavaであればDashScope Java SDKを用います。必要に応じて音声出力用ライブラリ(Pythonだとpyaudioなど)も準備します。
音声合成リクエスト: 公式ドキュメントでは、Pythonのdashscopeライブラリを使う例が示されています。モデル名を"qwen3-tts-flash"、テキストをtextパラメータで指定し、音色はvoice="Cherry"、言語はlanguage_type="指定したい言語"で指定します。以下はレスポンスから音声URLを取得するサンプルコードです。
response = dashscope.MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen3-tts-flash",
text="こんにちは、世界",
voice="Cherry",
language_type="Japanese",
stream=False
)
audio_url = response.output.audio.url音声ファイルの取得: 取得したaudio_urlにHTTPリクエストを送ると、音声ファイルをダウンロードできます。
ストリーミング再生(任意): stream=Trueオプションを指定すると、生成中の音声データを逐次受信できます。返ってきた各チャンクのaudio.data(Base64エンコード)をデコードして再生や保存ができるようです。
Qwen3-TTS-Flashを使ってみた
Alibaba Cloud DashScopeのAPIキー経由でQwen3-TTS-Flashを試してみましょう。かんたんにGoogle Colabで実装していきます。
ModelStudioコンソールでAPIキーを取得しましょう。詳しい取得方法については、公式ページを参考にしてください。
取得したAPIキーを以下のコードで叩きます。
import getpass
api_key = getpass.getpass("Enter DASHSCOPE_API_KEY: ")
os.environ["DASHSCOPE_API_KEY"] = api_key
その後、以下のコードで音声を生成します。今回は先ほどデモサイトでも使用した吾輩は猫であるの300文字程度のテキストを入力とします。
import os
import requests
import dashscope
dashscope.base_http_api_url = 'https://dashscope-intl.aliyuncs.com/api/v1'
text = "吾輩は猫である。名前はまだ無い。どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。この書生というのは時々我々を捕まえて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始めであろう。"
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash",
api_key=os.getenv("DASHSCOPE_API_KEY"),
text=text,
voice="Cherry",
language_type="Japanese",
stream=False
)
audio_url = response.output.audio.url
save_path = "downloaded_audio.wav"
try:
response = requests.get(audio_url)
response.raise_for_status()
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"音频文件已保存至:{save_path}")
except Exception as e:
print(f"下载失败:{str(e)}")
生成された音声はこちら。
デモサイトでもAPIキー経由でも、日本語の精度は大きく変わらないようです。日本語精度のアップに期待したいですね。
英語テキストについても試してみましょう。やさしく読める英語ニュースのイチローに関する記事からテキストをお借りします。
Ichiro makes memorable Hall of Fame induction speech
Former Major League Baseball player Ichiro Suzuki delivered a heartfelt speech at a ceremony to mark his induction into the US National Baseball Hall of Fame in New York, on July 28.
“Being here today sure is like a fantastic dream,’’ Ichiro said in the 19-minute speech in English at the ceremony. He is the first Japanese-born pro baseball player to achieve the honor.
(和訳)
イチロー氏、米野球殿堂入り表彰式典でスピーチ
元メジャーリーグベースボール選手のイチロー氏は、7月28日にニューヨークで行われた米野球殿堂入り表彰式典で心のこもったスピーチを行った。
英語で行った19分間のスピーチでイチロー氏は、「今ここにいることは、まるで素晴らしい夢のようです」と述べた。彼はこの栄誉を受けた最初の日本出身のプロ野球選手である。import os
import requests
import dashscope
dashscope.base_http_api_url = 'https://dashscope-intl.aliyuncs.com/api/v1'
text = "Ichiro makes memorable Hall of Fame induction speech Former Major League Baseball player Ichiro Suzuki delivered a heartfelt speech at a ceremony to mark his induction into the US National Baseball Hall of Fame in New York, on July 28. “Being here today sure is like a fantastic dream,’’ Ichiro said in the 19-minute speech in English at the ceremony. He is the first Japanese-born pro baseball player to achieve the honor."
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash",
api_key=os.getenv("DASHSCOPE_API_KEY"),
text=text,
voice="Cherry",
language_type="English",
stream=False
)
audio_url = response.output.audio.url
save_path = "downloaded_audio.wav"
try:
response = requests.get(audio_url)
response.raise_for_status()
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"音频文件已保存至:{save_path}")
except Exception as e:
print(f"下载失败:{str(e)}")
英語の音声生成はクオリティ高めですね。
以上、検証結果としてはやはり日本語の精度が物足りないので、今後のアップデートや強化モデルのリリースに期待といったところです。
気になる方は、いろんなパターンで音声生成を試してみてください。
まとめ
Qwen3-TTS-Flashは、Alibabaが開発した最先端の多言語対応音声合成モデルです。
17種類の音色プリセットと複数言語・方言のサポートを備えており、中国語と英語で優れた精度と安定性を持ち、既存のTTSモデルを上回る評価結果が報告されています。料金は文字数に応じた従量制、API経由で簡単に呼び出すことができます。
今後、モデルのチェックポイントが公開されれば、さらに幅広い用途への展開が期待されます。
気になる方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


