
Meta「SAM3・SAM 3D」次世代ビジョンAIの特徴・仕組み・使い方・活用事例を徹底解説
- SAM3は画像・動画を対象に、テキスト指示だけでセグメンテーション・トラッキングが可能なビジョンモデル
- SAM 3Dは単一画像から物体・人体の3D構造を推定でき、SAM3のマスクと組み合わせて高精度な3D復元が行える
- 両モデルともPlaygroundとGitHub、fal.aiでの提供がされており、誰でもすぐに試せる環境が整っている
2025年11月、Metaから新たなモデルが登場!
今回リリースされた「SAM3・SAM 3D」で、SAM3は領域抽出、SAM 3Dは1枚の画像から「物体や人体を3Dとして再構築するモデル」です。
領域抽出や自動追跡、3Dモデルの生成など どのように活用すればいいのか不明な点も多いかと思います。
そこで本記事ではSAM3・SAM 3D両者の概要や仕組み、実際の使い方、活用事例について解説します。本記事を最後までお読みいただければ、上記の不明点が解決できるでしょう。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
SAM3・SAM 3Dの概要
SAM3とSAM 3Dは、Metaが開発したSegment Anythingシリーズの最新モデルであり、画像・動画・3D理解を扱う技術。両者は同じSegment Anythingに属していますが、目的と得意領域が大きく異なります。
SAM3の概要
SAM3は、テキスト・視覚プロンプト・例示画像など複数の指示形式に対応し、画像や動画内の対象物を精密に検出・分割・追跡できるモデルです。従来のセグメンテーションは「どこに何があるか人間が教える」必要がありましたが、SAM3は概念を理解して自動検出します。
特に、短いテキストを入力するだけで関連する物体を一括抽出できる「テキストプロンプト」や、画像内で同種の物体を指定して抽出する「Exemplar Prompts」などが特徴。

SAM 3Dの概要
SAM 3Dは、自然画像から物体や人物を3D構造として復元することに特化したモデルです。
提供されているモデルは2種類で、SAM 3D Objectsは単一の画像から、物体の形状・テクスチャ・空間的な配置を推定し、3Dモデルとして再構築。
SAM 3D Bodyは人体の3D姿勢や体形を推定するためのモデルで、姿勢が崩れている場合や一部が隠れている場合でも推定を行えます。
さらに、多数の実世界画像からメッシュを生成・評価する大規模なデータエンジンを構築し、約100万枚の画像に対して約314万のメッシュを生成したことが明かされています。


SAM3・SAM 3Dの仕組み
SAM3とSAM 3Dは、どちらも視覚情報を高度に処理するモデルです。しかし、その内部構造やアプローチは異なります。また、SAM3DはSAM 3D ObjectsとSAM 3D Bodyに分けられます。
SAM3の仕組み
SAM3は、言語・例示・視覚プロンプトを1つのモデルで扱う統合型アーキテクチャを採用。モデルは大きく「テキストエンコーダ」「画像エンコーダ」「検出モジュール」「トラッキングモジュール」に分かれ、これらが連携して動作します。
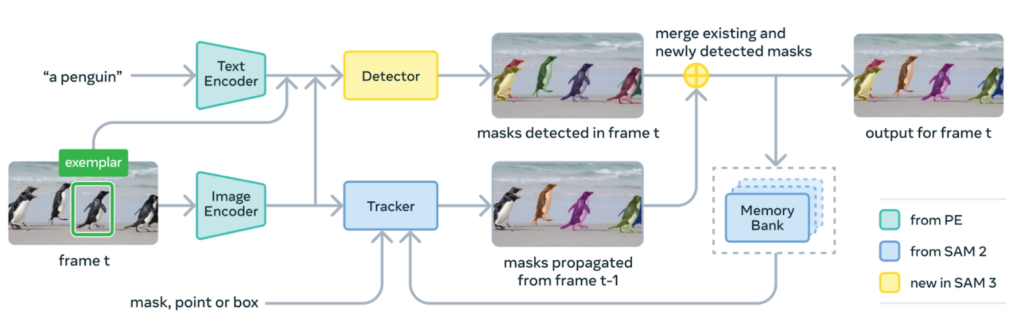
短い語句やフレーズを受け取った場合には、テキストの意味内容を解釈したうえで、画像内のどの領域が該当するかを推定できるように内部表現へ変換します。
また、画像や動画を入力する際には、フレーム内の視覚的な特徴を抽出し、対象物の形状や位置関係を把握するための特徴量として整理。さらに、例として指定されたボックスや画像が与えられた場合には、その特徴を参考にしながら、同種の対象を探索できる状態に整えます。
検出とトラッキングは共通のPerception Encoder(PE)と呼ばれるビジョンバックボーンを共有しており、この設計により効率的な処理が可能です。検出はDETRベースのモデルで、テキスト・ジオメトリ・画像の例示に基づいて条件付けられ、トラッキングはSAM 2のトランスフォーマーエンコーダ・デコーダアーキテクチャを継承し、動画セグメンテーションとインタラクティブな修正をサポートしています。
この一連の流れにより、編集作業や分析タスクで必要となる対象領域を、安定した精度で抽出できる仕組みが作られています。
データエンジンとpresence token
SAM3の性能を支える重要な要素として、大規模なデータエンジンと「presence token」と呼ばれる新しい仕組みがあります。
データエンジンは、人間とAIが協力して高品質な学習データを生成する仕組みです。
約400万個のユニークな概念ラベルを自動的に注釈付けし、SAM3の学習に使用。このデータエンジンは、人間のアノテーターだけで作業する場合と比較して、約2倍のスループットを実現しています。
presence tokenは、物体の認識(what)と位置特定(where)を分離するために導入された学習済みのグローバルトークンです。
従来のモデルでは、各提案クエリが「何があるか」と「どこにあるか」の両方を同時に判断する必要があり、これが性能のボトルネックとなっていました。
presence tokenは画像全体のコンテキストから「指定された概念が画像内に存在するか」を判断する役割のみを担い、個々の提案クエリは「存在する場合にどこにあるか」の位置特定を行います。
SAM 3D Objectsの仕組み
SAM 3D Objectsは、単一の画像から物体の形状や質感、空間的な配置を読み取り、3Dメッシュとして復元するために設計されたモデル。
SAM 3D Objectsには視覚情報を細かく分解しながら立体構造を導き出す多段階の推定プロセスがあります。
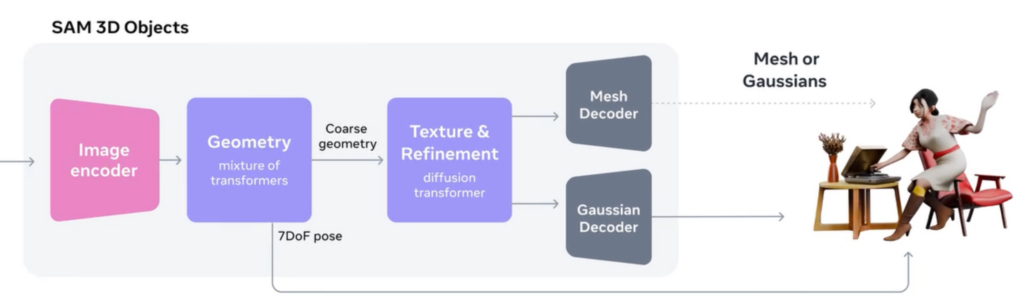
はじめに、画像全体を解析することで輪郭や表面の手触り、物体同士の位置関係などを特徴量として取り出します。こうした情報が整理されることで、モデルは物体の基本的な形を描き出すための土台を得られる仕組みです。
続いて、抽出された特徴を基に立体化の処理が進みます。物体の大まかな形状を形成したあと、表面の細部やテクスチャを重ねていくことで、視覚的な一貫性を備えた立体へと発展。
また、物体がどの向きに配置されているかといった姿勢の推定も並行して行われ、最終的には実物に近いメッシュが生成される構造になっています。
注意点としては、画像だけで自動的に3D化できるわけではありません。SAM3で3D化したい物体のマスクを作成し、作成したマスクを入力として、SAM 3D Objectsで3Dメッシュを生成します。
SAM 3D Objectsで生成された3DメッシュはPLY、OBJ、GLB形式で出力が可能で、BlenderやHoudini、Mayaなどで読み込むことができます。
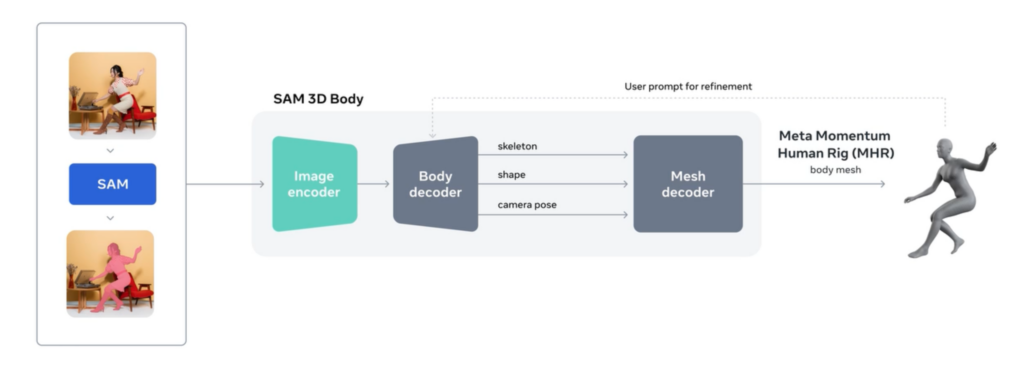
SAM 3D Body の仕組み
SAM 3D Bodyは、単一の画像から人体の立体構造を推定するために設計されたモデルです。姿勢が崩れている場合や身体の一部が隠れているケースでも推定を試みます。
モデルには、骨格と体の形状を分離して扱えるMeta Momentum Human Rig(MHR)が使用されており、人の体を理解するために機能しています。

MHRを使用することで、骨格の動きと外見的なシルエットをそれぞれ独立して扱えるようになり、構造の読み取りや編集を行いやすい形にできます。
基本的には動画のみで3D復元を行いますが、動画のみでは難しい場合に補助プロンプトを使用します。
補助プロンプトのタイプとしては、関節位置を手動で指定する2Dキーポイントと、SAM3で作成した人物のセグメンテーションマスクの2種類。
特に効果を発揮するケースは、複数人が重なるなどの遮蔽がある場合、ダンスやヨガのような手足の複雑なポーズ、近接した複数人物の識別が困難な場合です。
これらの状況では、2Dキーポイントで隠れた関節を補正したり、テキスト指示で動作を明示したり、マスクで各人物を分離することで、より正確な3D復元ができます。
推論の流れとしては、まず画像から得られる視覚情報をもとに、人体の主要な特徴を抽出。
その際、セグメンテーションマスクや2Dのキーポイントといった追加情報を組み合わせることで、ユーザーの意図に沿った形で予測を誘導できる構造になっています。複数の入力が揃うことで、関節の位置や身体の向きなどをより安定して推定でき、結果として自然な3Dモデルの生成につながります。
なお、Metaの次世代動画トラッキングAIであるCoTracker3について詳しく知りたい方は、下記の記事を合わせてご確認ください。
SAM3・SAM 3Dの特徴
SAM3とSAM 3Dは、Segment Anythingシリーズの中でも最新世代の技術として位置づけられており、それぞれが異なる特徴を持っています。
SAM3の特徴
SAM3は、画像や動画に写る対象を切り出したり追跡したりするための処理を幅広く扱えるモデルとして設計されており、従来のシリーズと比べても操作のしやすさや応用範囲が大きく広がっています。

各種の評価指標では、テキストを使った指示でも視覚的な指示でも高い性能が示されており、静止画だけでなく動画に対するマスク生成や追跡でも安定した精度を発揮。こうした特徴は、実務の場で必要となる処理の再現性を高めるうえで重要なポイントといえます。
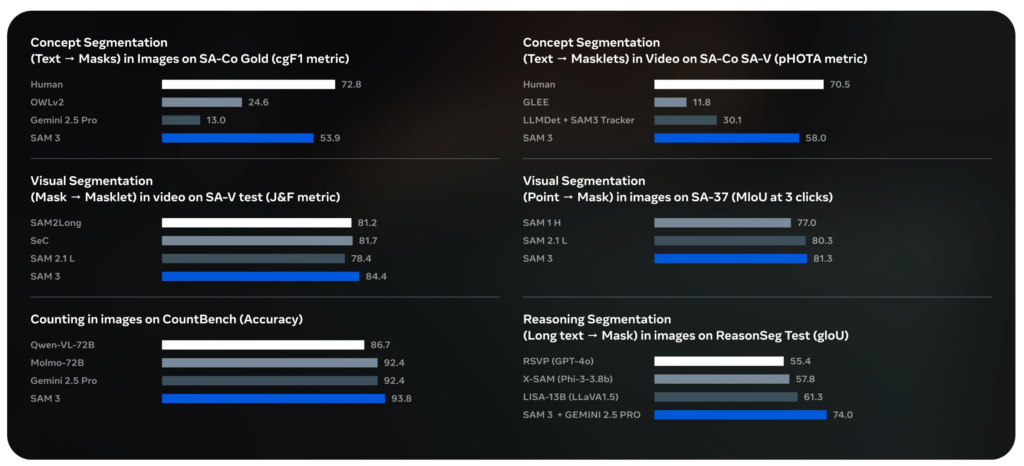
ベンチマーク性能
SAM3は、SA-Coベンチマークおよび既存のベンチマークで、高い性能を発揮しています。
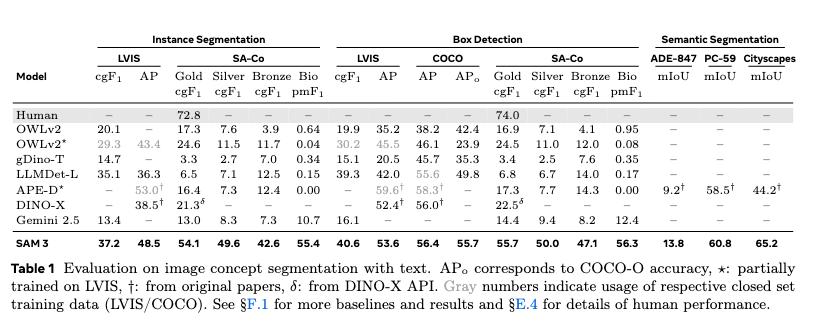
SA-Co/Goldでの評価では、SAM3はcgF₁スコア54.1を達成。これは人の約74%に相当し、競合であるOWLv2*と比較して2倍以上の精度です。
COCOベンチマークでは、ボックス検出でAP 56.4を達成し、競合モデルを上回る結果となりました。
セマンティックセグメンテーションにおいても、ADE-847でmIoU 13.8、PC-59でmIoU 60.8、Cityscapesで65.2という高いスコアを記録。
これらの評価指標は、テキストを使った指示でも視覚的な指示でも高い性能が示されており、静止画だけでなく動画に対するマスク生成や追跡でも安定した精度を発揮しています。
SAM3 Agent
SAM3には、複雑なテキストプロンプトを処理するための「SAM3 Agent」という拡張機能があります。
SAM3 Agent は、Multimodal Large Language Model(MLLM)とSAM3を組み合わせたシステムで、SAM3単体では対応が難しい複雑な言語クエリのセグメント化が可能。
SAM3は基本的にシンプルな名詞句に制限されていますが、SAM3 Agentを使用することで、より長い参照表現や推論が必要なクエリにも対応可能になります。
SAM 3D Objects の特徴
SAM 3D Objectsは、単一の画像から物体の立体構造を自然な形で復元できる点が大きな特徴。
写っている物体の形状や質感、配置を手がかりに立体化を進めることで、実際の見た目に近いメッシュを得られるよう設計されています。小さな物体や一部が隠れているケースでも、画像中の手がかりや周囲の背景情報を組み合わせながら推定を行うため、安定した復元ができる仕組みです。
こうした特性を支えているのが、大規模なデータエンジンの存在。現実世界の3Dデータが不足しがちな問題を補うため、独自の方式で大量の学習データが整えられています。
さらに、複数の物体をまとめて扱える点も特徴のひとつです。画像内で対象を複数選択すると、それぞれに対してメッシュが生成されるため、密度の高いシーンであっても全体像を立体的に再構築できます。これにより、物体単体の復元だけでなく、空間全体の理解にも対応できる柔軟性が備わっています。
SAM 3D Body の特徴
SAM 3D Bodyは、姿勢が大きく崩れていたり、身体の一部が隠れていたりする状況でも推定を行える点が特徴。単一画像から自然な立体表現に近い人体モデルを生成できるよう設計されています。
極端なポーズや複雑な関節の向きにも対応しようとする仕組みが整えられており、日常的な動作から特殊な体勢まで幅広いケースを扱える柔軟性があります。
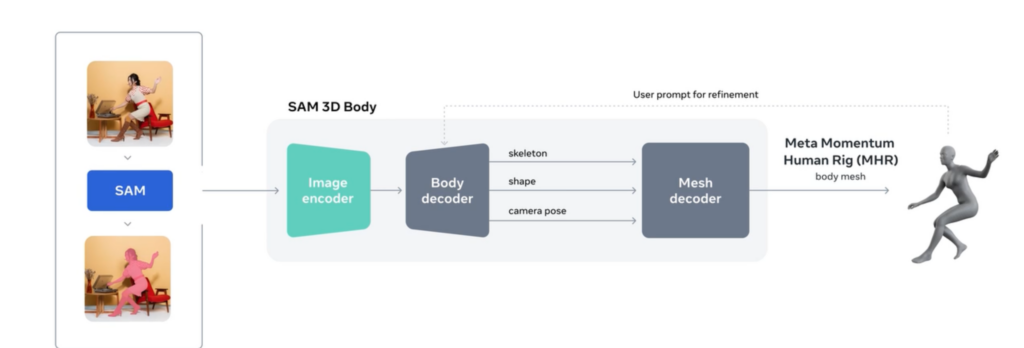
画像だけでなくセグメンテーションマスクや2Dキーポイントを追加の情報として組み合わせられる点も特徴です。
こうした補助的な情報を与えることで、モデルの振る舞いを利用者の意図に沿った方向へ誘導でき、より自然な姿勢や形状の生成につなげられます。複数の入力に対応できる構造によって、操作の自由度が高く、状況に応じた細やかな調整を行える点がSAM 3D Bodyの強みといえます。
SAM3・SAM 3Dの安全性・制約
SAM3に関する安全性と制約については、公式ページに記載がありませんでしたが、SAM 3Dには利用にあたって注意しておくべき点がいくつかあります。
SAM3Dの安全性・制約
SAM 3Dには、3D復元における限界がいくつか示されており、特に物体復元と人体復元の両面で注意すべき点があります。
まずSAM 3D Objectsでは、生成されるメッシュの解像度に一定の制約があり、細部まで精密に再現したい場合には限界が生じることがあります。
複雑な造形を持つ物体ほど細かな特徴が失われやすく、再現性に差が出る可能性が高いです。
また、物体間の物理的な関係性を推定する仕組みは備わっていません。シーンに複数の物体が存在する場合でも、それぞれを独立したものとして扱うため、接触や重なりといった関係性を考慮した推定は行われません。
SAM 3D Bodyにも特有の制約があります。姿勢や遮蔽にある程度対応できる一方で、どの程度の条件まで見極められるのかは明らかではなく、照明や画像品質など環境によって結果が変動する可能性があります。
さらに、人体を扱うためのMHR形式についても、どこまでの構造を表現できるのか、また構造上の制限がどのように働くのかが示されていないため、扱い方によっては意図しない結果につながる恐れもあります。
推論品質の限界
基本的にシンプルな名詞句に対応するよう設計されており、複数の属性を含む複雑なクエリや長い参照表現には対応できません。
「左側の人物が持っている赤いバッグ」のような関係性と属性の組み合わせや「最も大きな車の近くにある看板」のような推論が必要な指示はSAM3では処理が難しい場合があります。
ただし、SAM3 AgentをMLLMと組み合わせることで、こうした複雑なクエリにも対応可能になります。
オープンボキャブラリーの性質上、視覚的曖昧性も課題となります。
「mouse」がデバイスなのか動物なのかといった多義性や「大きい」「居心地の良い」などの主観的記述の解釈は状況に依存。
また、「鏡」にフレームを含めるかどうかといった境界の曖昧さや遮蔽とぼやけにより物体の範囲が不明確な場合もあります。SAM3はこうした曖昧性に対処するため、presence tokenや複数のマスク候補を予測する仕組みがありますが、完全に解決できるわけではありません。
SAM3・SAM3Dの料金
SAM3・SAM3Dともに料金については公開されていません。GitHubやHugging Faceからモデルをダウンロードして利用します。
Hugging Faceからモデルをダウンロードする場合には、事前に申請が必要なので利用前には申請するようにしておきましょう。
また、fal.aiでSAM3とSAM 3Dを使うことができ、料金は下記のようになります。
| API名 | 料金 | 処理単位 |
|---|---|---|
| SAM 3 Image | $0.005 | 1画像あたり |
| SAM 3 Video | $0.005 | 16フレームあたり |
| SAM 3 Image RLE | $0.005 | 1画像あたり |
| SAM 3 Video RLE | $0.005 | 16フレームあたり |
| SAM 3 Vision (Embed) | $0.005 | 1埋め込みあたり |
| SAM 3D Objects | $0.02 | 1生成あたり |
| SAM 3D Body | $0.015 | 1推論あたり |
| SAM 3D Align | $0.02 | 1シーンあたり |


SAM3・SAM3Dのライセンス
SAM3・SAM 3DのライセンスはSAM Licenseです。
| 用途 | 可否 | 条件・注意点 |
|---|---|---|
| 商用利用 | ⭕️ | ただし、軍事・ITAR・原子力・スパイ・武器関連は禁止。輸出規制・制裁への準拠が必要 |
| 改変 | ⭕️ | 派生物を作成できる。ただし配布時は同じSAM Licenseを適用する必要がある |
| 配布 | ⭕️ | ただし同じSAM Licenseの下でのみ配布可能 |
| 私的利用 | ⭕️ | |
| 特許利用 | ⭕️ |
なお、Meta開発の音声入力だけで一瞬でAIアバターを作成できるAudio2Photorealについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

SAM3・SAM3Dの使い方
SAM3・SAM3DともにPlaygroundが用意されています。
いずれもサンプル画像が用意されているので、サクッと使うことが可能。また、Metaのアカウントがなくても試しに使うことができるので、まずは使ってみたい、という方はぜひご利用ください。
SAM3をローカル環境で実行する方法
SAM3をローカル環境で実行するには、環境構築とチェックポイントの入手が必要です。
また、必要な環境要件は下記です。
- Python3.12以降
- PyTorch2.7以降
- CUDA12.6以降対応GPU
- GPU VRAM推奨16GB以上
筆者はApple SiliconのMacなので、今回はApple SiliconのMacで実装する方法について解説をします。
まずはHugging Faceでモデル使用の申請を出しておきましょう。
モデル使用の承認がされるとメールがきます。もしくはHugging FaceのGated Repos Statusでも確認できます。
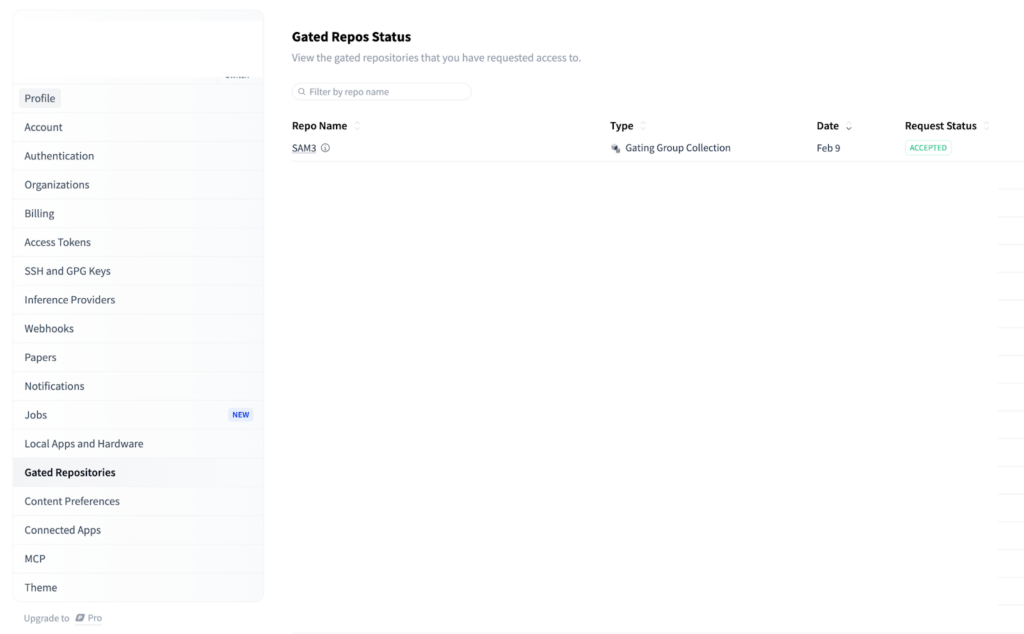
承認されたら実装の準備をしていきましょう。まずはconda環境を作成します。
conda create -n sam3-mps python=3.11 -y
conda activate sam3-mps続いてMPS対応のPyTorchをインストールします。
pip install --upgrade pip
pip install torch torchvisionここで一度動作確認をしておきます。
python - << 'EOF'
import torch
print("torch:", torch.__version__)
print("mps available:", torch.backends.mps.is_available())
print("mps built:", torch.backends.mps.is_built())
EOFmps available: TrueになっていればOK。
次にTransformersを入れますが、必ずGitHub版を入れるようにします。
pip install git+https://github.com/huggingface/transformersここでも一度確認をします。
python - << 'EOF'
import transformers
print(transformers.__version__)
EOF5.xx.dev0 のような dev版表示ならOKです。
またモデルを使用するためにはHugging Faceへのログインも必要なのでcliを入れて、Hugging Faceにログインします。
pip install -U huggingface_hub
huggingface-cli loginトークンを聞かれるので、アクセストークンを入力してください。
これで準備は完了です。下記のコードをsam3_run.pyとして保存をして、実行してください。
import os
import numpy as np
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForMaskGeneration
MODEL_ID = "facebook/sam3"
IMAGE_PATH = ".png"
OUT_MASK = "sam3_mask.png"
OUT_OVERLAY = "sam3_overlay.png"
def main():
print("torch:", torch.__version__)
print("mps available:", torch.backends.mps.is_available())
device = "mps" if torch.backends.mps.is_available() else "cpu"
print("device:", device)
if not os.path.exists(IMAGE_PATH):
raise FileNotFoundError(f"Image not found: {IMAGE_PATH}")
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForMaskGeneration.from_pretrained(MODEL_ID).to(device)
model.eval()
image = Image.open(IMAGE_PATH).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
inputs = {k: v.to(device) if hasattr(v, "to") else v for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
pred = outputs.pred_masks # torch tensor on device
print("pred_masks:", pred.shape, pred.device)
m = pred[0, 0]
m = m.max(dim=0).values
m_min = float(m.min().item())
m_max = float(m.max().item())
if m_max - m_min < 1e-8:
m_norm = torch.zeros_like(m)
else:
m_norm = (m - m_min) / (m_max - m_min)
mask_bin = (m_norm > 0.5).to(torch.uint8) # 0/1
mask_np = (mask_bin.detach().cpu().numpy() * 255).astype(np.uint8) # [H, W] 0/255
mask_img = Image.fromarray(mask_np, mode="L")
mask_img.save(OUT_MASK)
base = image.resize(mask_img.size, Image.BILINEAR)
base_np = np.array(base).astype(np.float32)
alpha = 0.45
overlay_np = base_np.copy()
overlay_np[mask_np > 0] = overlay_np[mask_np > 0] * (1 - alpha) + 255 * alpha
overlay_img = Image.fromarray(np.clip(overlay_np, 0, 255).astype(np.uint8), mode="RGB")
overlay_img.save(OUT_OVERLAY)
print(f"SAVED: {OUT_MASK}")
print(f"SAVED: {OUT_OVERLAY}")
print("DONE: mask save succeeded.")
if __name__ == "__main__":
main()今回使用する画像はこちらの記事で生成した画像です。
生成したオーバーレイ画像とマスク画像がこちら。


上記画像が出力できたことからも、SAM3はM4 Macでも動くことが確認できました。
SAM3で動画の処理
続いて動画の処理もしていきたいと思います。
動画の処理をする場合には、conda install -c conda-forge av -yを追加しておきましょう。
その後、下記の内容で新規ファイルを作成し、実行すればOKです。
import os
import numpy as np
import torch
from PIL import Image
from transformers import Sam3VideoModel, Sam3VideoProcessor
from transformers.video_utils import load_video
MODEL_ID = "facebook/sam3"
VIDEO_PATH = ".mp4"
TEXT_PROMPT = "person"
MAX_FRAMES = 30
OUT_MASK = "sam3_video_mask_frame0.png"
OUT_OVERLAY = "sam3_video_overlay_frame0.png"
def _to_pil(frame):
if isinstance(frame, tuple):
frame = frame[0]
if isinstance(frame, Image.Image):
return frame
return Image.fromarray(frame)
def main():
if not torch.backends.mps.is_available():
raise RuntimeError("MPS が利用できません。Apple Silicon + 対応PyTorchを確認してください。")
device = torch.device("mps")
print("device:", device)
if not os.path.exists(VIDEO_PATH):
raise FileNotFoundError(f"Video not found: {VIDEO_PATH}")
video_frames, _ = load_video(VIDEO_PATH)
if len(video_frames) == 0:
raise RuntimeError("動画フレームが読み込めませんでした。動画ファイルを確認してください。")
video_frames = video_frames[:MAX_FRAMES]
print("frames loaded:", len(video_frames))
video_frames = [_to_pil(f).convert("RGB") for f in video_frames]
model = Sam3VideoModel.from_pretrained(
MODEL_ID,
torch_dtype=torch.float16,
).to(device)
model.eval()
processor = Sam3VideoProcessor.from_pretrained(MODEL_ID)
inference_session = processor.init_video_session(
video=video_frames,
inference_device=device,
processing_device="cpu",
video_storage_device="cpu",
dtype=torch.float16,
)
inference_session = processor.add_text_prompt(
inference_session=inference_session,
text=TEXT_PROMPT,
)
outputs_per_frame = {}
for model_outputs in model.propagate_in_video_iterator(
inference_session=inference_session,
max_frame_num_to_track=len(video_frames) - 1,
show_progress_bar=True,
):
processed = processor.postprocess_outputs(inference_session, model_outputs)
outputs_per_frame[model_outputs.frame_idx] = processed
print("processed frames:", len(outputs_per_frame))
if 0 not in outputs_per_frame:
raise RuntimeError("frame 0 の出力が見つかりませんでした。")
f0 = outputs_per_frame[0]
if "masks" not in f0:
raise KeyError(f'Expected key "masks" in processed outputs. keys={list(f0.keys())}')
masks = f0["masks"]
if hasattr(masks, "detach"):
masks = masks.detach().cpu().numpy()
else:
masks = np.asarray(masks)
if masks.ndim != 3 or masks.shape[0] == 0:
raise RuntimeError(f"マスクが生成されませんでした。masks.shape={masks.shape}")
m = (masks[0] > 0).astype(np.uint8) * 255 # 0/255
mask_img = Image.fromarray(m, mode="L")
mask_img.save(OUT_MASK)
frame0 = video_frames[0]
base = frame0.resize(mask_img.size, Image.BILINEAR)
base_np = np.array(base).astype(np.float32)
alpha = 0.45
overlay = base_np.copy()
overlay[m > 0] = overlay[m > 0] * (1 - alpha) + 255 * alpha
overlay_img = Image.fromarray(
np.clip(overlay, 0, 255).astype(np.uint8),
mode="RGB"
)
overlay_img.save(OUT_OVERLAY)
print("SAVED:", OUT_MASK)
print("SAVED:", OUT_OVERLAY)
print("DONE: video SAM3 succeeded.")
if __name__ == "__main__":
main()今回使用した動画はこちらです。
出力された画像がこちら。

今回の処理は動画内の人物をTEXT_PROMPT = “person”という指示のみで自動追跡・セグメンテーションして、1フレーム目の結果を画像として保存しています。
SAM3では自動追跡をプロンプトのみで実行できるので、一度決めた対象を、次のフレームでも「同じ対象」として追う場合に有効かと思います。
SAM3のプロンプト種類について
SAM 3は、複数のプロンプトタイプに対応しており、用途に応じて使い分けることで精度の高いセグメンテーションが可能です。
わかりやすいのがテキストプロンプトで、短い名詞句で対象を指定。
サンプルコードがこちら
from sam3 import build_sam3
predictor = build_sam3(checkpoint="sam3_checkpoint.pth")
masks = predictor.predict(
image=image,
text_prompt="a car"
)ポイントプロンプトは、画像上の特定の座標を指定してその位置の物体をセグメンテーションします。画像内の特定の物体を正確に指定したい場合や、複数の同種の物体から1つを選択したい場合に有効です。
サンプルコードがこちら
masks = predictor.predict(
image=image,
point_coords=[[100, 200]], # x, y座標
point_labels=[1] # 1: 前景, 0: 背景
)バウンディングボックスプロンプトは、矩形の領域を指定してその範囲内の物体をセグメンテーションします。
物体の大まかな位置とサイズが分かっている場合に有効で、他の検出モデルの出力と組み合わせて使用することも多く、物体検出とセグメンテーションのパイプラインで活用されます。
サンプルコードがこちら
masks = predictor.predict(
image=image,
box=[[50, 50, 300, 400]] # x1, y1, x2, y2
)マスクプロンプトは、既存のマスク画像を入力としてより精緻なマスクを生成。
粗いマスクを精緻化したい場合や、複数ステップでのセグメンテーション精度向上に有効です。
サンプルコードがこちら
masks = predictor.predict(
image=image,
mask_input=rough_mask
)例示画像プロンプト(exemplar)は、参照画像を提供して同様の物体をセグメンテーションします。テキストでは表現しにくい特徴的な物体や、特定のスタイル・パターンを持つ物体をセグメンテーションしたい場合に有効です。
サンプルコードがこちら
masks = predictor.predict(
image=image,
exemplar_image=reference_image
)SAM3・SAM3D活用事例
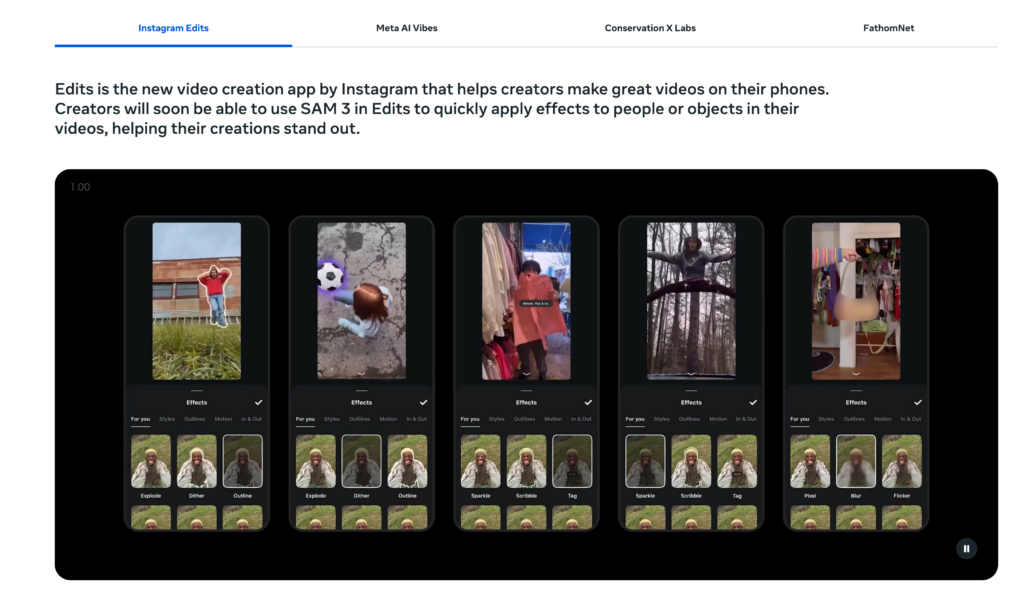
SAM3は、画像や動画を対象とした高速なセグメンテーションとトラッキングを実現するモデルであり、具体的な利用例としてMetaアプリ群で導入予定。
Instagramの動画編集アプリであるEditsでは、人物や物体を素早く切り出し、動画に効果を適用する用途が示されており、ユーザーがスマートフォン上で編集作業を行う際の効率化につながります。
スポーツ競技での活用
実際にSAM3を活用して、スポーツ競技に使用している例が見つかりました。
こちらのポストでは人物やネット、ボールを検出しています。これだけ正確に人物やボールの軌道などを検出できるのであれば、審判の補助などに使えそうですね。
また下記のポストもスポーツ競技での活用事例です。
こちらはゲートのマッピングと認識にSAM3が活用されています。
地形評価
下記のポストではポットホールの検出にSAM3が活用されています。
トレーニングはたった15分で手動アノテーション不要のようです。
SAM3・SAM3Dを実際に使ってみた
使い方の項目で画像を用いた例を提示したので、次は動画を使って実際にSAM3を使ってみます。
まずはSAM3です。今回はサッカーをプレイしている動画から特定の物体を抽出したいと思います。
最初にサッカーボールを抽出し、その後に特定の人物を抽出しましたが、特に特定の人物の抽出はスポーツ競技において、どのような動き方をしているのかなどの学びに活かせるのかなと感じました。
続いてSAM3Dです。SAM 3Dでは身体をスティックピクチャにしたいと思います。
実際の動きからスティックピクチャを作ることができるので、姿勢改善や動作フォームの確認、動きの分解などさまざまな領域で活用ができそうです。
なお、巨大モデル並みの知識容量を実現する小型モデルであるLlama 4 Scoutについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

よくある質問
ここではSAM3とSAM 3Dに関するよくある質問に回答していきます。
まとめ
本記事ではMetaが新たに発表したSAM3とSAM 3Dについて解説をしました。
SAM3は、画像や動画の中から対象を柔軟に切り出したり追跡したりでき、SAM 3Dは、1枚の画像から物体や人体を立体的に復元することができます。
いずれも使い道は多そうであり、使い方も簡単なので、ぜひ本記事を参考に皆さんも使ってみてください!

最後に
いかがだったでしょうか?
高精度セグメンテーションを実現するSAM3と、自然な立体表現を生成するSAM 3Dは、既存サービスのUX向上や新しい機能開発に大きく貢献します。導入メリットやPoCの可能性を、今すぐご相談ください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


