
【Stable Cascade】ローカルでも7秒で画像を生成できるAI

2024年2月13日、Stability AI社が「Stable Cascade」というテキストから画像を生成するモデルを発表しました!
このモデルは、従来のStable Diffusionと異なり、複数の異なる画像生成モデルが組み合わされていて、より高品質な画像生成ができます。
Stability AI社は、「一般消費者向けハードウェアでのトレーニングと微調整が簡単にできます。」としており、学習の手軽さが魅力のようです。
以下の画像は実際にStable Cascadeで生成された画像です。
Cinematic photo of an anthropomorphic penguin sitting in a cafe reading a book and having a coffee.
和訳:
擬人化されたペンギンがカフェで本を読みながらコーヒーを飲んでいるシネマティックな写真。

非常にリアルで高解像度な画像ですよね。
今回はそんな高品質画像生成AIのStable Cascadeについて、概要や特徴をお伝えします。
\生成AIを活用して業務プロセスを自動化/
Stable Cascadeの概要
Stable Cascadeは、2024年2月13日にStability AI社が公開した画像生成AIモデルです。
学習コストの小ささや画像生成時のVRAM使用量の少なさを特徴とする画像生成モデル「Würstchen」をベースに開発されました。
Stable Cascadeは、「ステージA」、「ステージB」、「ステージC」の3つのモデルで構成され、各ステージに処理を分散させることで、トレーニングコストの削減、高品質な画像生成を実現しているようです。
Stable Cascadeの仕組み
ステージ構成の詳細を見ていきましょう。
以下、Stability AI社から公開されているアーキテクチャ図です。
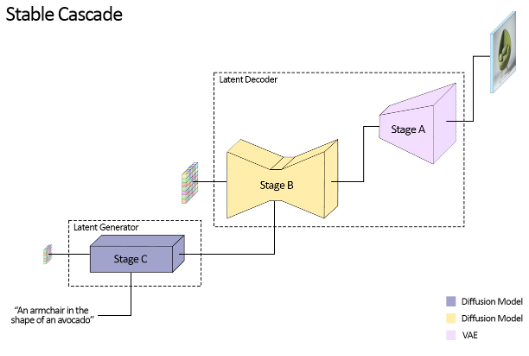
ステージCは、ユーザーが入力したテキストプロンプトから24 × 24の小さな潜在空間を生成するプロセスです。
このプロセスによって、画像生成の初期段階における計算コストが大幅に削減されます。
そして、ステージAとステージBについては、ステージCで生成された小さな潜在空間をベースに、高解像度な画像生成をするプロセスになっているようです。
ステージAについては、従来のStable DiffusionモデルにおけるVAEの役割と同様なんですね!
VAEは変分自己符号化器(Variational Auto-Encoder)という画像生成モデルの一種であり、一言で表現すると、「画像生成のための補助ツール」です。
VAEのありなし比較を見てみましょう。

一目瞭然ですね。
左がVAEなし、右がVAEありの生成画像です。
VAEなしは全体的にモヤがかかっていますが、VAEを導入することで全体がハッキリしています。
このように、VAEがあることで画像の高品質化ができちゃうんです!便利!
なお、Stable Diffusionについて詳しく知りたい方は、下記の記事を合わせてご確認ください。→Stable Diffusionとは?ローカル・ブラウザでの使い方やモデルのインストール方法を解説
少し脱線しましたが…
Stable Cascadeは、「ステージA」、「ステージB」、「ステージC」の3つのモデルを組み合わせることで、より高速で高品質な画像生成を実現しています。
Stable Cascadeのライセンス
ライセンス詳細は以下です。
Githubライセンスには商用利用可と記載がありますが、現在このモデルは非商用利用のみを許可する非商用ライセンスの下でリリースされており、商用利用は不可となっています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕ |
| 配布 | ⭕ |
| 特許使用 | ❌ |
| 私的使用 | ⭕ |
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Stable Cascadeにできること・機能
ここからは、さらに詳しくStable Cascadeの機能を紹介していきます。
単純にテキストから画像を生成する以外のこともできるようなので要チェックです!
Text-to-Image
まずは、擬人化されたペンギンの例でもご紹介したText-to-Imageです。
Beautiful female Final Fantasy character, beautiful scenery of starry night.
和訳:
ファイナルファンタジーの美しい女性キャラクター、星降る夜の美しい風景。
高品質なのがよく分かりますね!
Image-to-Image
Image Vatiationでは、与えられた画像から画像埋め込みを抽出し、バリエーションを生成します。
以下、左の画像がオリジナルで、右の4つが生成されたバリエーションです。

オリジナル画像から、様々なバリエーションの画像が出力されているのがわかります。
Inpainting / Outpainting
Inpainting / Outpaintingでは、一部がマスクされた画像とテキストを同時に入力することで、画像の一部を生成画像で埋めることができます。

以下は、上段がマスクされた画像、下段が生成された画像です。

こんなこともできちゃうんですね…!
Canny
Cannyは、輪郭画像を入力することで、輪郭を適用した画像生成ができる機能です。
こちらも上段が入力画像で下段が出力画像です。

Super Resolution
Super Resolutionでは、生成画像の解像度を向上させることができちゃうんです。

ぱっと見では分かりづらいかもしれませんが、男性、子猫の画像ともに右側の画像がくっきりしていますね。
Stable CascadeとSDXLの生成スピードを比較してみた
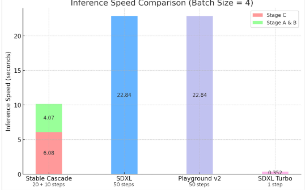
Stability AI社によると、StableCascadeが先行モデル(SDXL、Playground v2)との推論速度比較において、約半分以下の時間で画像を生成できるとされてますが、果たして本当なのか!?
検証
今回Stable Cascadeの比較対象はPlayground v2とします。
- Stable Cascade、Playground v2の画像生成時間を比較
- Google Colabの有料ハードウェア(A100 GPU)にて実行
- 入力プロンプトは「Cat wearing sunglasses(サングラスをかけた猫)」
まずはPlayground v2の画像生成時間を計測します。
最初に必要なライブラリをインポートしましょう。
!pip install transformers accelerate safetensors diffusers
from diffusers import DiffusionPipeline
import torch続いて、以下コードを実行すると「Cat wearing sunglasses(サングラスをかけた猫)」というプロンプトによる画像生成ができます。
%%time
pipe = DiffusionPipeline.from_pretrained(
"playgroundai/playground-v2-1024px-aesthetic",
torch_dtype=torch.float16,
use_safetensors=True,
add_watermarker=False,
variant="fp16"
)
pipe.to("cuda")
prompt = "Cat wearing sunglasses"
image = pipe(prompt=prompt, guidance_scale=3.0).images[0]
image.save("cat.png")実行時間は41秒
生成された画像は以下です。

続いて本題のStable Cascadeです。
純粋に以下のようにライブラリインポートを行うと、画像生成処理の段階でRuntimeErrorがでました。
!pip install git+https://github.com/kashif/diffusers.git@wuerstchen-v3こちらのページを参考に、以下コードでインストールし直すことでエラー解消ができました。
!pip install git+https://github.com/kashif/diffusers.git@a3dc21385b7386beb3dab3a9845962ede6765887 --force
import torch
from diffusers import StableCascadeDecoderPipeline, StableCascadePriorPipelineさあ、いよいよ画像生成です!
%%time
prior = StableCascadePriorPipeline.from_pretrained(
"stabilityai/stable-cascade-prior",
torch_dtype=torch.bfloat16,
).to("cuda")
decoder = StableCascadeDecoderPipeline.from_pretrained(
"stabilityai/stable-cascade",
torch_dtype=torch.float16,
).to("cuda")
%%time
prompt = "Cat wearing sunglasses"
prior_output = prior(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=4.0,
num_images_per_prompt=1,
num_inference_steps=20
)
decoder_output = decoder(
image_embeddings=prior_output.image_embeddings.half(),
prompt=prompt,
guidance_scale=0.0,
output_type="pil",
num_inference_steps=10
).images
decoder_output[0].save("cat_stable_cascade.png", "PNG")生成された画像

実行時間は7秒
期待以上のスピードです…
実行環境にも左右されるかもしれませんが、Stable Cascadeの性能はホンモノのようですね。
検証結果
Stable CascadeはPlayground v2よりも性能面で優れていて、Playground v2の半分以下の時間で画像生成をすることができるようです。
なおPlayground v2について詳しく知りたい方は、下記の記事を合わせてご確認ください。→【Playground v2】Stable Diffusionの2.5倍美しい!芸術的な画像に特化したAIを使ってみた
Stable Cascadeで高速な画像生成を試してみよう
Stable Cascadeは、2024年2月13日にStability AI社が公開した画像生成AIモデルで、手軽に高品質な画像を生成してくれます。
Stable Cascadeの特徴をまとめます。
- Stable Cascadeは3つのモデルで構成され、学習コスト削減、高品質な画像生成が担保されている。
- 現在は商用利用不可。
- Stable Cascadeでできることは、テキストからの画像生成だけでなく、画像から画像生成、オリジナル画像からのバリエーション生成、マスク部分の塗りつぶしなど多岐にわたる。
先行類似ツールのベースモデルよりもクオリティが高く、今後のアップデートが楽しみですね!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

