
【やってみた】StableCode、Stability AIの自動コード生成を実践解説

画像生成AIツール「Stable Diffusion」で有名なStability AIがなんと自動コード生成ツール「Stable Code」を発表しました。
コーディングをサポートするために開発されたLLMだということで、今後多くの注目が集まることでしょう。
そこで今回は、Stability AIのStable Codeの概要や導入方法、そして実際に触ってみた感想を紹介します。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Stable Codeの概要
Stable Codeは、StabilityAIが開発したコード生成専門LLM(Code LLM)です。
stack-dataset(v1.2)というデータからプログラムの書き方を学習させたあと、
人気言語であるPythonやGo、Java、Javascript、C、C++を重点的に学ばせているのが特徴です。
データ量は、560Bトークン(5600億の単語)なので、技術書に換算すると1000万冊に相当するんだとか。
めちゃくちゃ賢そうですよね。
このStable Codeのできることは2つあります。
まずは、自然言語でプログラムを書くこと。
例えば、「CPUコアの数を数えるプログラムをPythonで書いて」などと指示すると、要望にあったプログラムを出力してくれます。これには、命令モデル(Instruct model) を利用します。
次はプログラムを補完すること。
書き途中のプログラムがあれば、その続きをStable Codeが考えて提案してくれます。
もし自分の成果物イメージにあっていたら採用するだけ。
すべて採用せずとも、ヒントとして活用できるので行き詰まったときなどに便利な機能です。
このときは、補完モデル(Completion model)を利用します。
利用方法は、
- Google Colab 上でプログラムを実行する
- 拡張機能を使う(ただし、プログラムの補完機能のみ)
基本的に、LLMの利用料金は無料です。
ただし、1.の方法はGoogle Colabの利用料が月額1179円ほどかかります。
それでは、導入方法を見ていきましょう。
Stable Codeの導入方法
先述したように、Stable Codeの機能を次の順番で解説します。
- 自然言語でプログラムを書く
- プログラムを補完する
筆者の場合、以下の公式チュートリアルでエラーが出たので
それを修正したプログラムを公開しています。
ぜひ参考にしてください!
自然言語でプログラムを書く
以下は実際に動かしたプログラムです。まずはこちらからGoogle Colabを開きます。

ランタイム→ランタイムのタイプを変更 をクリック。

V100 GPUを選んで、ハイメモリにして保存

以下を実行する
pip install transformers 
次にHugging Faceのアクセストークンを取得します。
こちらのリンクにアクセス。必要に応じてアカウントの作成やログインをしてください。

以下のページにアクセスしたら、New tokenをクリック

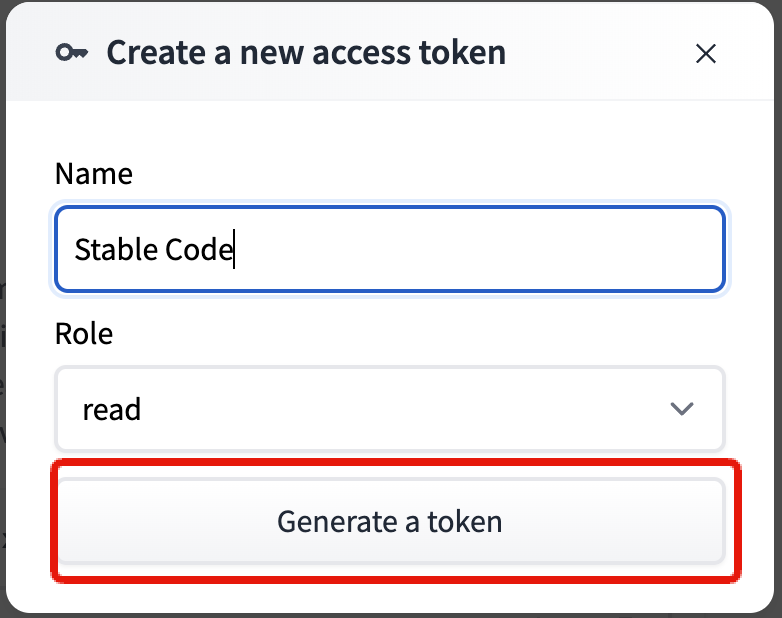
以下のようにして、Generate a tokenをクリック。
Role:read
Name:何でもOK(今回はStable Codeにしました。)
アクセストークンをコピー。

以下プログラムの
access_token = “your-access-token”
をコピーしたものと置き換え実行しましょう。
モデルをダウンロードするための処理です。
from transformers import AutoModelForCausalLM, AutoTokenizer
access_token = “your-access-token”
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablecode-instruct-alpha-3b", use_auth_token=access_token)
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/stablecode-instruct-alpha-3b",
trust_remote_code=True,
use_auth_token=access_token,
torch_dtype="auto"
)モデルの設定が終わったら、以下のコードを実行しましょう!
model.cuda()
inputs = tokenizer("###Instruction\nGenerate a python function to find number of CPU cores###Response\n", return_tensors="pt",return_token_type_ids=False).to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.2,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))実行するとこのような出力が。

実際のプログラムは以下です。
def get_cpu_count():
"""
Returns the number of CPU cores in the system
"""
cpu_count = int(os.sysconf("SC_NPROCESSORS_ONLN"))
return cpu_count
result = get_cpu_count()
print(f"Number of CPU cores: {result}")正しいプログラムが書けているのか実行して確認してみると、
「os module が定義されていないよ」
というエラーが……

意外なケアレスミスですね。
以下のように修正して再度実行すると……
import os # 追加
def get_cpu_count():
"""
Returns the number of CPU cores in the system
"""
cpu_count = int(os.sysconf("SC_NPROCESSORS_ONLN"))
return cpu_count
result = get_cpu_count()
print(f"Number of CPU cores: {result}")無事に動きましたー。

CPUコアの数もあっているので、OKです!
次は、プログラムの補完機能について見ていきましょう。
プログラムを補完する
これは、Google Colabで実行する方法の他に、Visual Studio codeの拡張機能の使い方もご紹介します。
VS codeの拡張機能
まずは、こちらのページにアクセスして拡張機能をインストール。
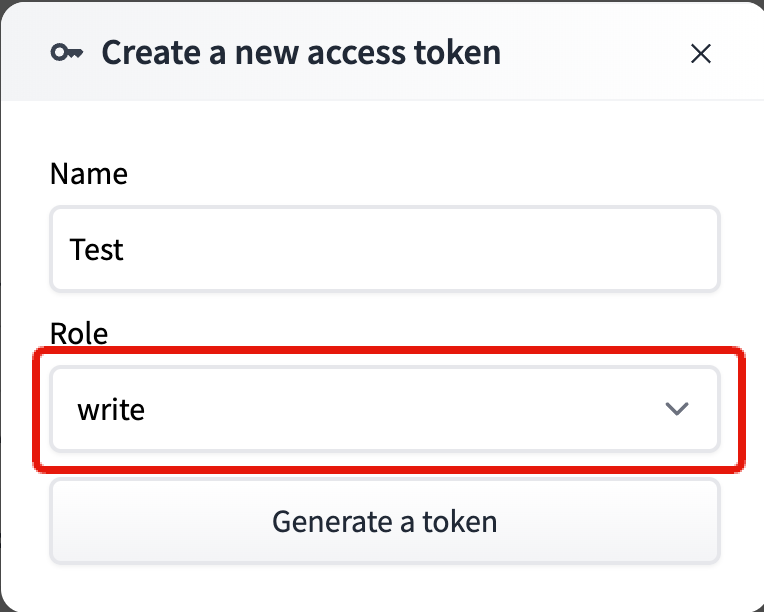
その後、以下のHugging Faceサイトにサインアップなどして、AccessTokenを取得します。
Role はWriteを選択してくださいー。
次はVisual Studio Code上でする作業です。
まずは、Cmd/Ctrl+Shift+P とタイプして、以下の画面を出す。
次はHugging Face Code: Set API tokenと入力。

先ほどのAPIキーを入力して、Enterを押すと完了。

本当に動くかテストしましょう。
pythonのファイルを作り、def main() と入力。
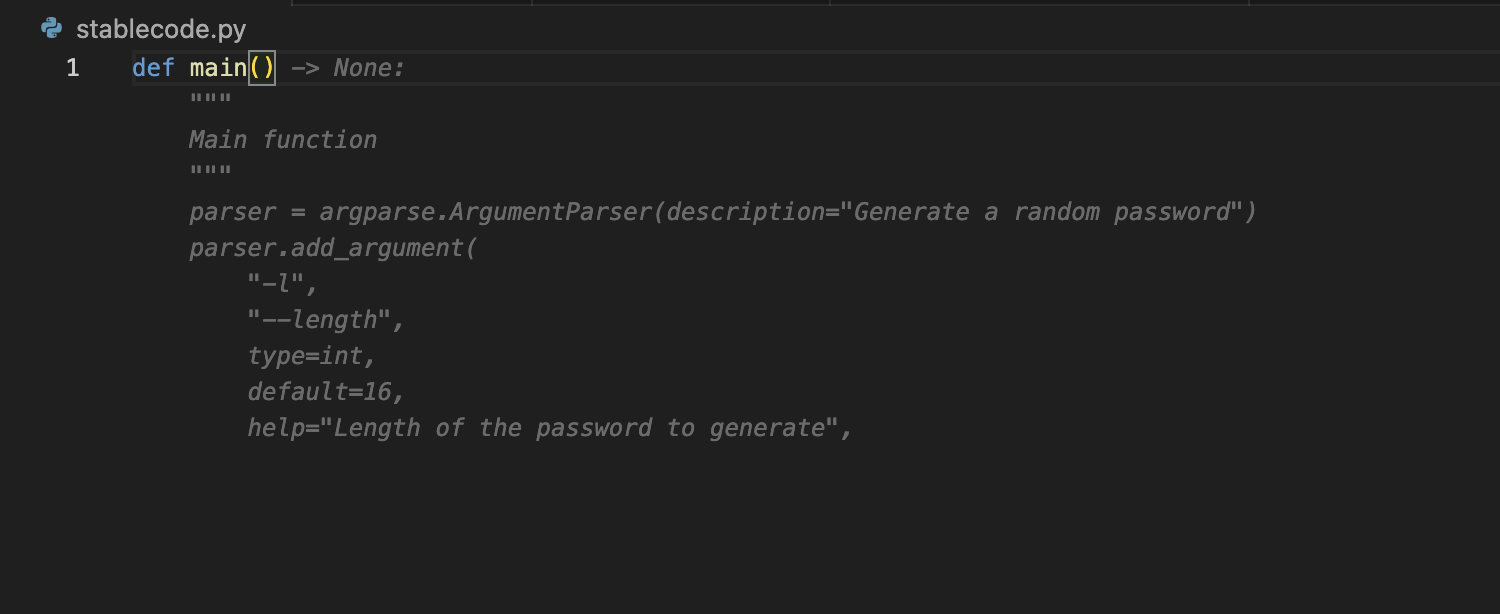
うっすらプログラムの候補が出てきたのでOKです!
次はGoogle Colabでの方法を見ていきましょう!
Google Colabで実行
自然言語でプログラムを書く手順と基本的には変わりません。
まずは、以下からGoogle Colabを開きます。
ランタイム→ランタイムのタイプを変更 をクリック。
V100 GPU を選んで、ハイメモリにして保存
以下を実行する。
pip install transformers モデルをダウンロードするために、以下を実行する
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablecode-completion-alpha-3b-4k")
model = AutoModelForCausalLM.from_pretrained("stabilityai/stablecode-completion-alpha-3b-4k", trust_remote_code=True, torch_dtype="auto")モデルのダウンロードが終わったら、以下を実行。
model.cuda()
#
inputs = tokenizer("import torch\nimport torch.nn as nn", return_tensors="pt",return_token_type_ids=False).to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=500,
temperature=1,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))するとこのような出力結果が。
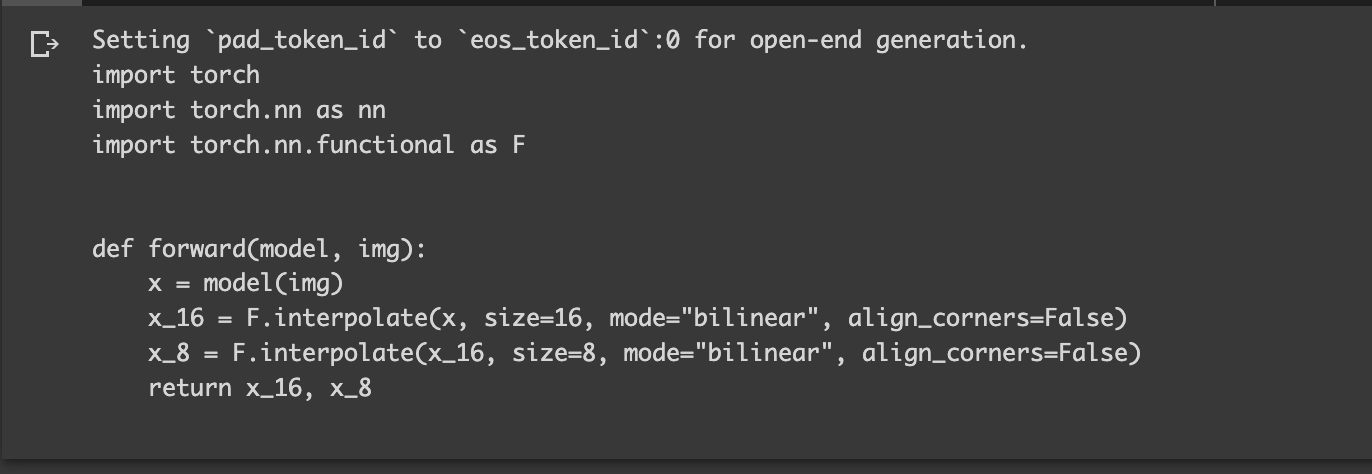
import torch.nn as nn
に続くプログラムを書いてくれていますね。
ちなみに、このプログラムは動かないので、この出力を再度、以下のように入力して実行すると良いでしょう。
#2回目以降
model.cuda()
inputs = tokenizer(
"""
#1回目の出力
import torch
import torch.nn as nn
import torch.nn.functional as F
def forward(model, img):
x = model(img)
x_16 = F.interpolate(x, size=16, mode="bilinear", align_corners=False)
x_8 = F.interpolate(x_16, size=8, mode="bilinear", align_corners=False)
return x_16, x_8
"""
, return_tensors="pt",return_token_type_ids=False).to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=500,
temperature=1,
do_sample=True,
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))以上で導入方法は終わりです。

Stable Codeを実際に触ってみた感想
自然言語でプログラムを書く命令モデルについて
プログラム初学者から経験者まで利用できる。
作ってもらいたいものを言語化できているのであればかなり便利。
プログラムを補完する補完モデルについて
あくまでサポート役で、ユーザーはプログラムを理解していないと持て余す気がした。
細かい修正を怠らずに、そして成果物の方向を理解していれば問題ない。
まとめ
Stable Codeは、StabilityAIが開発したコード生成専用LLM(Coding LLM)。
5600億単語(560Bトークン)から、プログラミングを学習し、その後人気のある言語(PythonやGo、Javaなど)を集中的に学習している。
このLLMは、2種類ある。
1つ目は、命令モデル(Instruct model)。
自然言語でプログラムを書くことを指示できる。
プログラム初学者から経験者までの万人向け。
学習や仕事に役立つ。
2つ目は、補完モデル(Completion model)。
書き途中のプログラムの続きを予想し提案してくれる。
プログラム経験者向け。
特に、補完されてできていくプログラムが正しいのか判断できる人や、補完がなくてもプログラムがかける人向け。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


