
【Vcoder】GPT-4V超えの最強マルチモーダルLLMの使い方〜実践まで

WEELメディア事業部LLMライターのゆうやです。
Vcoderは、補助的な知覚モダリティを利用して、マルチモーダル大規模言語モデル(MLLM)のオブジェクトレベルの認識タスクを改善するアダプターです。

Vcoderを使用することで、他のタスクのパフォーマンスを維持しながら、マルチモーダル大規模言語モデル(MLLM)の画像認識能力を向上させることができます。
現在、VCoder LLaVA-1.5とVCoder-DS LLava-1.5の2種類のチェックポイントがHuggingFace Hubで公開されており、ダウンロードして使用できます。
また、MLLMをオブジェクトレベルの知覚タスクで訓練・評価するためのCOSTデータセットも公開しています。
今回は、Vcoderの概要と使ってみた感想をお伝えします。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Vcoderの概要
Vcoderは、補助的な知覚モダリティを利用して、マルチモーダル大規模言語モデル(MLLM)のオブジェクトレベルの認識タスクを改善するアダプターです。
Vcoderを使用することで、他のタスクのパフォーマンスを維持しながら、マルチモーダル大規模言語モデル(MLLM)の画像認識能力を向上させることができます。
現在、VCoder LLaVA-1.5とVCoder-DS LLava-1.5の2種類のチェックポイントがHuggingFace Hubで公開されており、ダウンロードして使用できます。
また、MLLMをオブジェクトレベルの知覚タスクで訓練・評価するためのCOSTデータセットも公開しています。
次に性能について説明します。
Vcoderのオブジェクト認識スキルは、GPT-4Vを含む既存のMLLMよりも優れており、これはMLLMの問題の一つである「Moravec’s Paradox in Perception」(知覚におけるモラヴェックのパラドックス)の解決に目をつけたからです。
モラヴェックのパラドックスとは、マルチモーダル LLM が単純な視覚認識タスクでは失敗する一方で、複雑な視覚推論タスクでは成功する現象のことです。
以下の画像のように、GPT-4Vは「画像では何が起こっていますか?」という質問に対しては正確に答えられるのに対し、「画像に何人映っていますか?」という質問には10人と誤った回答をすることがあります。

Vcoderはこの問題を解消しているため、GPT-4Vなどの既存のMLLMと比較して、オブジェクト認識スキルを持っています。
ここからは、実際にVCoder-DS LLava-1.5を使用して、GPT-4Vと比較しながら性能を検証していきます。
まずは使い方から説明します。
なお、LLaVA 1.5について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【LLaVA 1.5】オープンソース版GPT4-Vの使い方~比較レビューまで
Vcoderの使い方
Vcoderは、ローカルにインストールして使う方法と、Hugging Face Spaceでオンラインデモを使う方法の2種類あります。
ローカルにインストールして使用する場合は、以下のコマンドを入力してください。
リポジトリをクローン
git clone https://github.com/SHI-Labs/VCoder
cd VCoder仮想環境のセットアップとパッケージのインストール。
conda create -n vcoder python=3.10 -y
conda activate vcoder
pip install --upgrade pip
conda install -c "nvidia/label/cuda-11.7.0" cuda-toolkit
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -e .
pip install ninja
pip install flash-attn --no-build-isolationモデルをロードするために以下のスクリプトを実行。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("shi-labs/vcoder_ds_llava-v1.5-13b")以下のコマンドを実行してgradio web UIを起動。
CUDA_VISIBLE_DEVICES=0 python -m vcoder_llava.serve.gradio_app --model-path shi-labs/vcoder_ds_llava-v1.5-13bオンラインデモは、以下のリンクにアクセスするだけで使用できます。
早速使っていきましょう!

Vcoderを実際に使ってみた
今回はオンラインデモを使用していきます。
アクセスすると以下のような画面になります。
画像を入力する箇所が三か所あり、それぞれ元の画像と、segmentation maps、depth mapを入力します。
なお、segmentation mapsは同じくShi-Labが提供しているOneFormer Demoで、depth mapはDINOv2を使用することで取得できます。
画像の説明をさせるだけであれば、元の画像とsegmentation mapsだけで十分なので、今回の検証ではこの2つを入力して推論を実行させます。
まずは、あらかじめ用意されていたExampleを実行してみます。

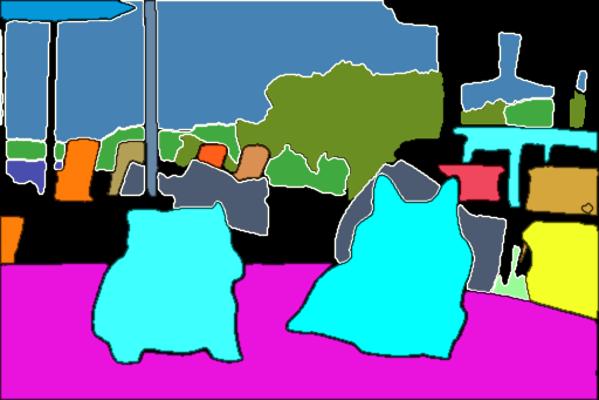
プロンプト
What objects can be seen in the image?画像にはどんなものが写っていますか?
結果はこのようになりました。
The objects present in the image are sky, tree, pillow, mountain, grass, water, two dogs, bed, dining table, umbrella, four chairs.空、木、枕、山、草、水、2匹の犬、ベッド、ダイニングテーブル、傘、4脚の椅子。
おおよそ正しく画像を認識して、写っている物体をリストアップしてくれました。
名前は少し違いますが、かなり小さく写っている海の水や、パラソルも認識しており、かなり高い認識能力を持っていることが伺えます。
実際に使えることが分かったので、ここからはGPT-4Vと比較して、どの程度の精度で画像を認識して出力してくれるのか検証します。
なお、日本語特化型のマルチモーダルについて知りたい方はこちらの記事をご覧ください。
→【Japanese Stable CLIP】Stability AI開発の日本語特化型マルチモーダルAIを使ってみた!
Vcoderの推しポイントである高い画像認識能力は本当なのか検証してみた
ここからはマルチモーダルLLMの代名詞的存在であるGPT-4Vとの比較を行って、本当にVcoderがGPT-4Vを超える画像認識能力を持っているのか検証します。
まずは先ほどの実際に使ってみたで入力した画像とプロンプトをGPT-4Vにも入力してみます。
結果はこのようになりました。
In the image, there are two Corgi dogs wearing black harnesses. They are sitting on what appears to be a blue mat on the floor of an outdoor deck area.
Behind the dogs, there are wooden tables with orange cushions on the seats. In the background, there are speakers mounted on poles and a view of a body of water, suggesting this might be a lakeside or seaside location.
The setting looks like a leisure or dining area, possibly part of a resort or outdoor restaurant.画像には黒いハーネスをつけた2匹のコーギー犬が写っている。彼らは屋外のデッキエリアの床に敷かれた青いマットのようなものの上に座っている。犬たちの後ろには木製のテーブルがあり、座席にはオレンジ色のクッションが置かれている。背景にはポールに取り付けられたスピーカーと水辺の景色があり、湖畔か海辺であることを示唆している。レジャーエリアかダイニングエリアのようで、おそらくリゾートか屋外レストランの一部だろう。
GPT-4Vも正しく画像を認識してくれており、文章で画像の様子を詳細に説明してくれました。
Vcoderでは出力されなかったスピーカーや、青いマットなどの説明も含まれており、この検証ではGPT-4Vの方が優秀だと感じました。
次に、以下の画像を入力して、画像に写っている人数を教えてもらいます。

プロンプト
How many people are in the image?画像には何人写っていますか?
結果はこのようになりました。
Vcoder
There are five people in the image.画像には5人写っています。
GPT-4V
There are six people in the image.画像には6人写っています。
結果はGPT-4Vが正解で、Vcoderの回答は誤りです。
見えにくいですが、右側の後ろの方に女の子が一人写っており、Vcoderはこの子を認識できなかったようです。
Vcoderは、モラヴェックのパラドックスを解決したとしていましたが、人数を認識するという簡単なタスクを間違えてしまっています。
最後に、以下の画像を入力して画像内で何が起こっているか説明してもらいます。

プロンプト
What is happening in the image?結果はこのようになりました。
Vcoder
In the image, a group of people, including children, are gathered around an arcade-style game, playing a video game and having fun.画像の中では、子供たちを含む人々がアーケードスタイルのゲームの周りに集まり、ビデオゲームをして楽しんでいる。
GPT-4V
In the image, there are children gathered around an arcade game, which appears to be an air hockey table.
They are engaged in playing or watching the game, with one child leaning forward, possibly taking a shot or defending a goal.
The environment suggests an indoor arcade or entertainment venue, as indicated by the neon lights and the presence of other arcade machines in the background.
The children seem to be enjoying themselves, immersed in the excitement of the game.画像では、エアホッケー台と思われるアーケードゲームの周りに子供たちが集まっている。彼らはゲームに興じているか観戦しており、1人の子供が前かがみになって、おそらくシュートを打っているかゴールを守っている。背景のネオンや他のゲーム機の存在から、屋内のゲームセンターか娯楽施設であることがわかる。子供たちはゲームの興奮に浸り、楽しんでいるようだ。
Vcoderは、途中まではよかったのですが、最後に「ビデオゲームをして楽しんでいる」と出力しており、誤った内容になっています。
一方のGPT-4Vは、画像の説明は基本的に正しく、アーケードゲームの内容も推測して文章を出力してくれています。
Vcoderはこの検証でも簡単なタスクを間違えてしまいました。
今回の検証の結果をまとめると、VcoderはGPT-4Vが正解した簡単なタスクを連続で間違えてしまっており、ベンチマーク通りの性能は実証できず、モラヴェックのパラドックスは解決できていないように感じました。
今回はこのような結果になりましたが、Vcoderは今後もチューニングモデルなどが開発予定なので、期待しましょう!
まとめ
Vcoderは、補助的な知覚モダリティを利用して、マルチモーダル大規模言語モデル(MLLM)のモラヴェックのパラドックスを解決し、オブジェクトレベルの認識タスクを改善するアダプターです。
Vcoderを使用することで、他のタスクのパフォーマンスを維持しながら、マルチモーダル大規模言語モデル(MLLM)の画像認識能力を向上させることができます。
実際に使ってみた感想は、GPT-4Vが正解した簡単なタスクで誤った回答をしてしまい、ベンチマーク通りの性能を実証することはできず、モラヴェックのパラドックスは解決できていないように感じました。
今後、チューニングモデルなどが開発予定なので、将来的にはさらなる高度なオブジェクト認識とマルチモーダル学習を実現して、映画「マトリックス」のような世界観になるかもしれませんね!

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


