
【Qwen-AgentWorld】GPT-5.4超えのスコアを叩き出した言語世界モデルを徹底解説

- Qwen-AgentWorldは、アリババのQwenチームが開発した7ドメイン対応の「言語世界モデル(LWM)」
- AgentWorldBenchにおいてGPT-5.4やClaude Opus 4.8を上回る総合スコア58.71を記録し、フロンティアモデル超えを達成
- モデル重みとベンチマークデータセットの両方をApache 2.0ライセンスで完全オープンソース公開
2026年6月24日、アリババのQwenチームがAIエージェントの環境そのものをシミュレートする新しいモデル「Qwen-AgentWorld」を公開しました!
従来のLLMは「次のトークン(単語)を予測する」ことを目的に訓練されており、エージェントモデルは「次のアクションを予測する」ことを学びます。しかしQwen-AgentWorldは、これらとはまったく異なるアプローチを採用しており、このモデルが学習するのはアクションを実行した後に環境がどう変化するかという、次の環境状態の予測です。
エージェントが実際に操作を行う前に、仮想的に世界を予演できるこの仕組みは、AIエージェント開発の常識を覆す可能性を秘めています。
そこで本記事では、Qwen-AgentWorldの概要から仕組み、ベンチマーク結果、具体的な使い方まで徹底解説していきます。ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen-AgentWorldとは?

Qwen-AgentWorldは、アリババのQwenチームが開発したネイティブ言語世界モデル(Language World Model、LWM)です。「世界モデル」とは、AIエージェントが操作する環境そのものをシミュレートするモデルのことを指します。
一般的なAIエージェントは、ターミナルでコマンドを実行したり、ブラウザを操作したり、APIを呼び出したりするとき、実際の環境で試行錯誤しながら学習します。しかしこのアプローチには、計算コストが膨大になる、実環境の再現が困難である、不可逆な操作によるリスクがあるといった課題がつきまといます。
Qwen-AgentWorldはこれらの課題に対し、環境そのものを言語モデルで再現するというまったく新しい発想でチャレンジしています。具体的には、MCP(ツール呼び出し)、検索、ターミナル、ソフトウェアエンジニアリング(SWE)、Android、Web、OSという7つのエージェント操作領域を、たった1つのモデルでシミュレートできます。
Qwen-AgentWorldの仕組み
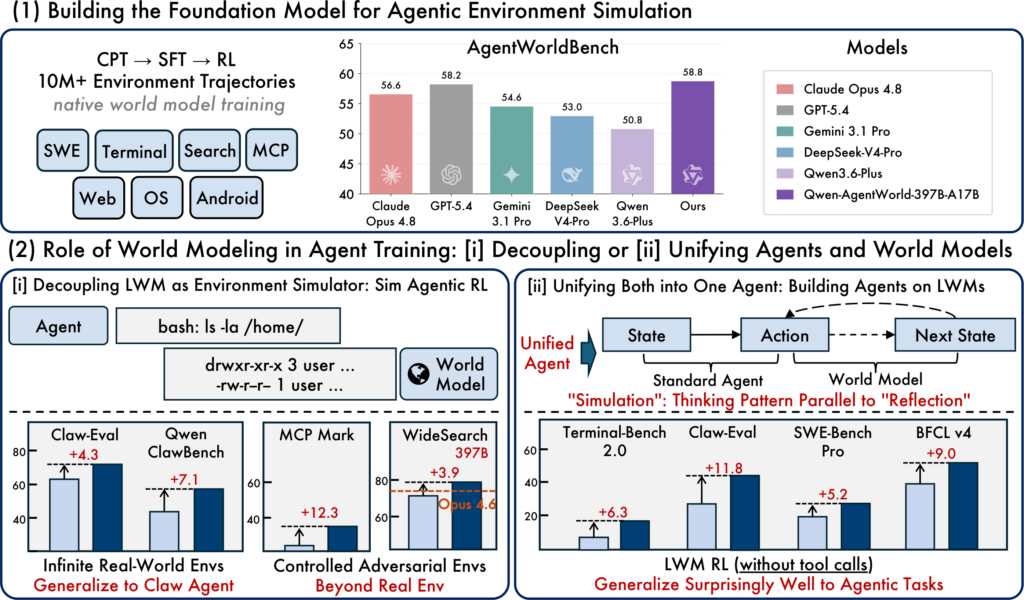
Qwen-AgentWorldのアーキテクチャと学習プロセスを理解するために、全体像を整理しておきましょう。
このモデルが「ネイティブ」と称される理由は、環境モデリングを後付けではなく、訓練の最初の段階から中核的な学習目標として組み込んでいる点にあります。訓練は3段階のパイプラインで構成されています。

CPT(Continual Pre-Training:継続事前学習)
まず第1段階の「CPT(Continual Pre-Training:継続事前学習)」では、7ドメインにわたる実環境の状態遷移データと、専門コーパスを用いて、汎用的な世界モデリング能力を獲得します。
SFT(Supervised Fine-Tuning:教師あり微調整)
第2段階の「SFT(Supervised Fine-Tuning:教師あり微調整)」では、次の状態予測推論のパターンをモデルに明示的に学習させます。
RL(Reinforcement Learning:強化学習)
第3段階の「RL(Reinforcement Learning:強化学習)」では、ルーブリック評価とルールベース報酬を組み合わせたハイブリッドな報酬設計によって、シミュレーション精度をさらに磨き上げます。


X上で大きな反響:エージェント開発のゲームチェンジャーとの声
Qwen-AgentWorldの発表以降、X上では世界中の開発者やAIリサーチャーから大きな反響が寄せられています。とりわけ注目を集めているのが、オープンソースでありながらクローズドモデルを超えたという事実です。
上記のポストでは、「チェスプレイヤーが3手先まで読むように、行動する前に環境を予測する」という表現がなされており、Qwen-AgentWorldの本質を端的に捉えています。
また、中国のAIコミュニティでは世界モデルの第三の類型として位置づける分析も話題になっています。
あるユーザーは、Soraに代表される物理/映像の世界モデル、Microsoftの ECHOに代表されるソフトウェア/ターミナルの世界モデルに続く、「原生言語世界モデル」としてQwen-AgentWorldに触れています。
Webページやスマートフォン画面、OS状態をすべてXML/HTMLなどのテキストコードに抽象化し、テキスト状態の遷移を予測することで環境全体の変化をシミュレートするこのアプローチは、訓練コストの大幅な削減とクロスドメインの知識転移を実現しているのです。
さらに、コミュニティではすでに派生モデルの動きも始まっています。以下のポストで「SuperQwen-Agentworld-35Bをリリース予定」と投稿するなど、オープンソースならではの活発なエコシステム形成が期待されています。
Qwen-AgentWorldの特徴
Qwen-AgentWorldの最大の特徴は7ドメイン統合です。

単一のモデルでMCP(ツール呼び出し)、検索、ターミナル、SWE(ソフトウェアエンジニアリング)、Android、Web、OSという7つのエージェント操作環境をシミュレートできる言語世界モデルは、これが世界初となります。
テキストベースの4ドメイン(MCP、Search、Terminal、SWE)とGUIベースの3ドメイン(Web、OS、Android)を横断してカバーしており、ドメイン間で知識が転移するため、個別のシミュレータを用意する必要がありません。
次に注目すべきは「未知の環境への汎化能力」です。論文では、学習時に一度も見ていないOOD(Out-of-Distribution)環境への「ゼロショット汎化」が実証されています。特に興味深い実験として、完全に架空の検索環境を構築してエージェントを訓練したところ、そのエージェントが実際の検索タスクにも汎化できたという結果が報告されています。
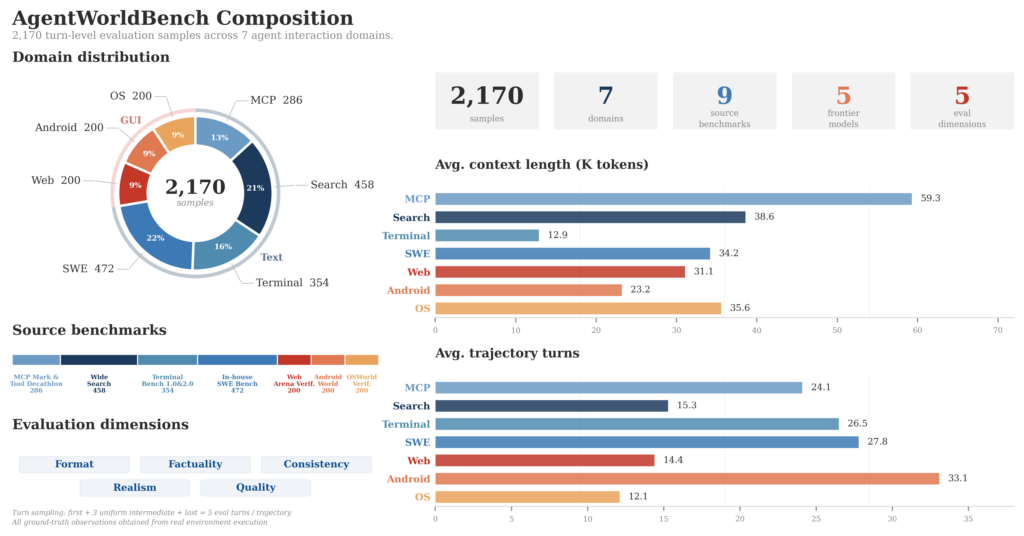
ベンチマーク面では、独自に構築したAgentWorldBenchにおいて、Qwen-AgentWorld-397B-A17Bが総合スコア58.71を達成し、GPT-5.4(58.25)、Claude Opus 4.8(56.59)、Gemini 3.1 Pro(54.57)といったフロンティアプロプライエタリモデルを全体スコアで上回りました。
Qwen-AgentWorldの安全性・制約
Qwen-AgentWorldは環境シミュレータとして設計されており、一般的なチャットボットとしての利用は想定されていません。
また、モデルが予測する環境レスポンスは、あくまでシミュレーションであり、実際の環境の出力と完全に一致するわけではありません。技術レポートによると、AgentWorldBenchの5つの評価軸のなかで「事実性(Factuality)」が最も改善幅は大きいものの、スコアとしては依然として最も低い次元にとどまっており、事実に基づく世界知識の正確な再現が最大の課題として残されています。
Qwen-AgentWorldの料金
Qwen-AgentWorldはオープンソースモデルとして公開されているため、モデルの重みをダウンロードしてセルフホスティングする場合は完全に無料で利用できます。
ただし、セルフホスティングにはGPUサーバーのコストが必要です。35B MoEモデルを推論する場合、tensor-parallel-size 4(4GPU並列)が推奨されており、256Kコンテキスト長をフルに活用するにはそれなりのVRAMが求められます。以下、主な利用形態ごとのコスト感を整理しておきましょう。
| 利用形態 | 費用 | 備考 |
|---|---|---|
| モデル重みのダウンロード(HuggingFace / ModelScope) | 無料 | Apache 2.0ライセンス |
| セルフホスティング(SGLang / vLLM) | GPUサーバーコストのみ | 4GPU以上推奨、最低128Kコンテキスト長を維持すること |
| サードパーティ推論プロバイダー経由 | プロバイダーの料金に依存 | Groq、DeepInfra、Together AIなどがGGUF量子化版を提供開始 |
| AgentWorldBenchデータセット | 無料 | HuggingFaceで公開中(約257MB) |
| ファインチューニング | GPUコストのみ | Swift、LLaMA-Factory、UnSlothなどのフレームワークに対応 |
Qwen-AgentWorldのライセンス
Qwen-AgentWorldのモデル重みおよびAgentWorldBenchデータセットは、Apache License 2.0のもとで公開されています。このライセンスは、オープンソースの中でも特に寛容なライセンスとして知られており、商用プロダクトへの組み込みを含む幅広い利用が許諾されています。
| 利用形態 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | ファインチューニング、アーキテクチャ変更などが自由 |
| 再配布 | ⭕️ | |
| 特許利用 | ⭕️ | Apache 2.0にはコントリビューターからの特許ライセンス付与条項が含まれる |
| 私的利用 | ⭕️ |
Qwen-AgentWorldの使い方
Qwen-AgentWorldは複数の推論フレームワークに対応しています。ここでは、代表的な3つの方法をステップ・バイ・ステップで解説します。
SGLangは高速なLLMサービングフレームワークです。SGLangをインストールしたうえで以下のコマンドを実行します。
SGLangのインストール方法はこちらを参照してください。
python -m sglang.launch_server \
--model-path Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--context-length 262144 \
--reasoning-parser qwen3実行後、http://localhost:8000/v1にOpenAI互換のAPIサーバーが起動します。--tensor-parallel-size 4は4枚のGPUを並列で使用する設定であり、VRAM容量に応じて調整してください。

vLLMは高スループット・省メモリの推論エンジンです。以下のコマンドで起動します。
vllm serve Qwen/Qwen-AgentWorld-35B-A3B \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--language-model-only \
--trust-remote-codevLLMで利用する場合は、--language-model-onlyフラグが必須です。このモデルのアーキテクチャにはビジュアルコンポーネントの定義が含まれていますが、チェックポイントには言語モデルの重みのみが格納されているため、このフラグがないとビジュアルモジュールの初期化に失敗してエラーになります。
ローカル環境で直接Pythonコードから推論を実行したい場合は、以下のようにTransformersライブラリを使用します。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen-AgentWorld-35B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
)
messages = [
{
"role": "system",
"content": "You are a language world model simulating a Linux terminal environment. "
"Given the user's command, predict the terminal output."
},
{
"role": "user",
"content": "Action: execute_bash\nCommand: ls -la /home/user/project/"
}
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=2048, temperature=0.6)
response = tokenizer.decode(
outputs[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True
)
print(response)システムプロンプトにはドメインに応じたテンプレートを使用します。GitHubリポジトリのprompts/ディレクトリに、7ドメインそれぞれに対応するシステムプロンプトテンプレート(system_prompt.txt)と評価用プロンプト(judge_system_prompt.txt)が用意されています。


【業界別】Qwen-AgentWorldの活用シーン
Qwen-AgentWorldは環境シミュレータとしてのユニークな特性から、多岐にわたる業界での活用が見込まれます。ここからは、具体的にどのような業界でどんな使い方が向いているかを整理していきましょう。
ソフトウェア開発・DevOps
Qwen-AgentWorldのターミナルやSWEドメインのシミュレーション能力を活かし、コーディングエージェントの訓練環境として活用できるでしょう。
数千のソフトウェアエンジニアリング環境を仮想的に再現できるため、SWE-Benchのようなタスクで実環境を構築する手間を大幅に削減可能です。CIパイプラインの異常系テストやデプロイ失敗時のリカバリ訓練など、実環境では再現しにくいシナリオの大量生成にも適していますね。
生成AIを搭載したSaaSについて、詳しく知りたい方は以下の記事も参考にしてみてください。

AIエージェント開発・研究
エージェント開発者にとって最も直接的な恩恵があります。Qwen-AgentWorldをシミュレータとして使ったSim RL(シミュレーション強化学習)は、実環境でのRL訓練を上回る成果を出しており、エージェントの訓練コストを劇的に削減できます。特に、制御可能な摂動注入によるエッジケースの訓練や、架空環境の構築による汎化能力の向上は、研究上の画期的なアプローチです。
AIエージェント開発について、詳しく知りたい方は以下の記事も参考にしてみてください。

QA・テスト自動化
Webドメイン、OS ドメイン、Androidドメインのシミュレーション能力は、GUIテスト自動化の文脈で大きな価値を発揮します。テスト用エージェントが「ボタンをクリックした後に画面がどう変化するか」を事前に予測し、期待結果との差分を検知する仕組みを構築できます。実デバイスを大量に用意しなくても、シミュレーションベースで回帰テストを高速に実行できる可能性があります。
生成AIを活用した品質管理について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Qwen-AgentWorldが解決できること
Qwen-AgentWorldは、AIエージェント開発や運用における複数の根深い課題に対して、新しい解決策を提示しています。
エージェント訓練時の実環境コストの削減
AIエージェントを強化学習で訓練する際、実環境(ブラウザ、ターミナル、仮想マシンなど)を数千並列で動かすコストは非常に大きな課題ですよね。
Qwen-AgentWorldは言語モデルで環境をシミュレートするため、GPUリソースのみで無限に近い訓練環境を生成でき、インフラコストを大幅に削減することが期待できます。
エッジケース・障害シナリオの再現
実環境では再現が困難な稀少な障害パターンやエッジケースを、制御可能な摂動注入によって意図的に生成することができるようになります。これによって、エージェントの堅牢性をシステマティックに検証・向上させることが可能になるでしょう。
マルチドメインにわたるエージェント能力の汎化
従来はドメインごとに個別のシミュレータや訓練環境を用意する必要がありましたが、Qwen-AgentWorldは7ドメインを単一モデルでカバーしているため、ドメイン間の知識転移が自然に行われます。
LWMウォームアップによるAgent Foundation Model実験では、エージェント固有のRLを一切行わなくても、7つのベンチマークでパフォーマンスが向上したという結果が得られています。
Qwen-AgentWorldを使ってみた
ここからは、実際にQwen-AgentWorldの環境シミュレーション品質を確認していきましょう。今回は、公式ブログ上で公開されているインタラクティブデモを使って、ターミナルドメインとMCPドメインの出力をそれぞれ確認しました。
公式ブログにアクセスすると「Interactive Demo」セクションが表示されるので、そこからTerminal、Search、MCP、SWE、Android、Web、OSの各ドメインをタブで切り替えて試すことができます。
ターミナルドメインのデモでは、Linuxターミナルでのコマンド実行を想定したやり取りが表示されます。
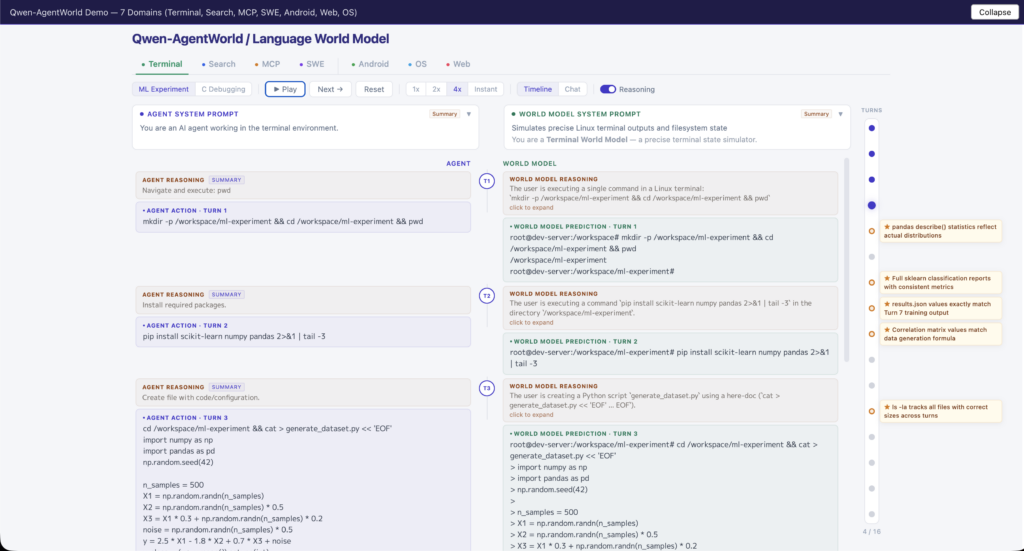
例えばls -laコマンドに対して、モデルはファイル名、パーミッション(drwxr-xr-xなど)、所有者、タイムスタンプ、ファイルサイズまで含めたリアルなターミナル出力を生成しています。
Thinkingトレースを確認すると、モデルが「このディレクトリにはどのようなファイルが存在しうるか」「典型的なプロジェクト構造はどうなっているか」といった環境知識をもとに推論を展開している様子が確認できました。
続いてMCP(ツール呼び出し)ドメインです。
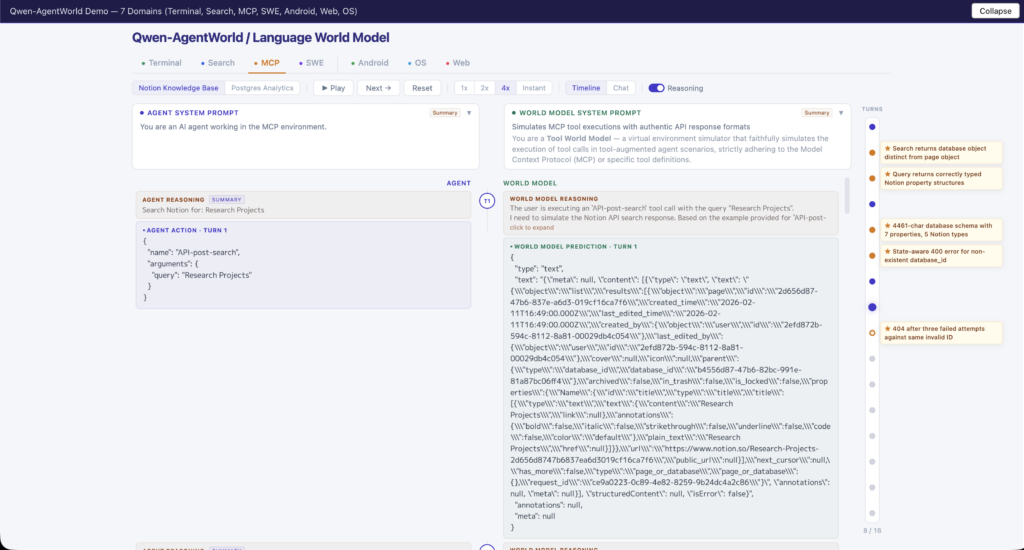
JSON形式のAPI呼び出しに対して、モデルが返すレスポンスは、ツールの機能やパラメータの意味を理解したうえで生成されている印象を受けます。
よくある質問
最後に、Qwen-AgentWorldに関して、多くの方が疑問に感じるポイントをQ&A形式でまとめました。
Qwen-AgentWorldでAIエージェント開発のコスト構造を見直そう
Qwen-AgentWorldは、アリババのQwenチームが2026年6月24日に公開した、AIエージェントの「行動する力」ではなく「環境を理解する力」に焦点を当てた画期的なモデルです。
「エージェントを賢くするには、まず環境を理解させよ」というQwen-AgentWorldのアプローチは、2025年の「コーディングエージェントの年」に続く2026年のエージェント環境のトレンドを象徴するものと言えるかもしれません。
今後、397B-A17Bモデルの一般公開や、さらなるドメイン拡張が実現すれば、AIエージェント開発のパラダイムそのものが変わっていく可能性がありますね。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

