
【GPT Crawler】URLを入れるだけでどんなサイトもGPTsにできる神AIを使ってみた
- URLを指定するだけでサイト専用のGPTsを自動構築できる
- セットアップは簡単で最短2分でGPTsを作成
- ISCライセンスで公開されており商用利用や改変も可能
2023年11月15日、Builder.ioより「GPT Crawler」がオープンソース化されました。
GPT Crawlを利用すれば、URLを指定するだけで、そのサイト独自のGPTsをたった2分で簡単に作れてしまうんです!
というわけで今回は、GPT Crawlerの概要や使い方について詳しく解説します。ぜひ最後までご覧いただき、お手元のPCでGPTsを作成してみてください!
\生成AIを活用して業務プロセスを自動化/
GPT Crawlerの概要
GPT Crawlerは、【サイトのURLを指定するだけで、独自のGPTsをChatGPT上で作成できるソフトウェア】です。
例として以下は、GPT Crawlerで作成した「Builder.io Assistant」というGPTsを使用した様子です。(GPTsの利用にはChatGPT Plusへの課金が必要)
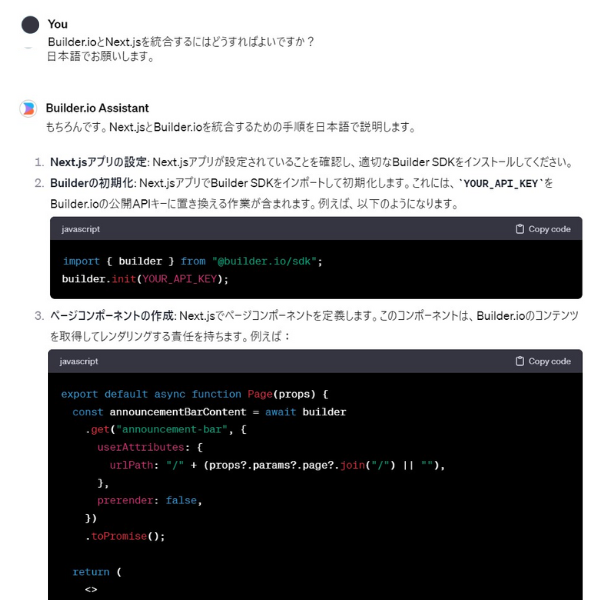
ご覧のとおり、Builder.ioの使い方についてプロンプトで質問するだけで、手順をわかりやすく解説してくれていますね。
ちなみに作成したGPTsは、自社サイトやサービスに設置して、チャットボットとして使うことも可能です。
GPT CrawlerでGPTsを作成するメリットは以下の2点。
- [ユーザー視点]:不明点についてわざわざ調べたり問い合わせたりする必要がなく、GPTsに質問するだけで疑問が解決する。
- [開発者視点]:GPTsが自動でユーザーとやり取りしてくれるため、顧客対応業務の負担が軽減される。
さらに、GPT CrawlerでGPTsを作成する手順は非常にシンプルで、早ければ2分ほどで完了します。
興味のある方は、ぜひ独自のGPTsを作成してみてください!
なお、ノーコードでGPTsを利用する方法については下記の記事を合わせてご確認ください。

GPT CrawlerでPDFを読み込ませられるのか?
チャットボットと言えば、PDFを読み込ませられると非常に楽ですよね。GPT CrawlerがPDFを読み込んでくれればRAGを構築する必要もなく、自社独自のチャットボットを運用できます。
しかしGitHubを確認してみるとPDFを直接解析する機能や、PDF対応に関する記述は一切ありません。
また記載されている内容としては、以下の範囲に限られています。
- クロール対象は「WebサイトのURL(HTMLベース)」
- 設定ファイル(config.ts)でURL・マッチパターン・セレクタなどを指定してテキスト抽出
- 結果を output.json に保存し、それをChatGPTの「Knowledge」にアップロード
つまり、公式には「PDFを直接読み込ませる」ことは想定されておらず、PDFへの対応は無理だと解釈できます。
GPT Crawlerのライセンス
GPT CrawlerはISC licenseでライセンスされています。商用利用や改変などは許可されていますが、特許については明示されていませんので特許に関連した使用を行う場合はご注意ください。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕ |
| 改変 | ⭕ |
| 配布 | ⭕ |
| 特許使用 | 明示されていない |
| 私的利用 | ⭕ |

GPT Crawlerの使い方
早速GPT Crawlerを使うためのセットアップを行いましょう。
手順としてはローカルでGPT Crawlerをセットアップし、サイトをクローリングしてデータを取得したあと、ChatGPTで独自のGPTsを作成するという流れになります。
GPT Crawlerをローカルで動かすのに必要なPCのスペック
今回、GPT Crawlerを動かしたのは下記のマシンになります。
■マシン:MacBook Pro(13-inch 2020)
■CPUの種類:1.4 GHz クアッドコアIntel Core i5
■システムメモリ:16GB
■GPUの種類:Intel Iris Plus Graphics 645 1536 MB
■HDD/SSDの空き容量:50GB
■必要なパッケージ
Node.js >= 16
ローカル環境での準備
まずGitからソースコードを任意のフォルダにダウンロードします。
git clone https://github.com/builderio/gpt-crawler次に、生成された「gpt-crawler」というフォルダに移動し、installコマンドでインストールを開始します。
cd gpt-crawler
npm install※もしPlaywrightがインストールされていなければ、下記コマンドでインストールを行ってください。
npx playwright installGPT Crawlerのインストールが完了したら、「config.ts」という設定ファイルを変更します。
export const config: Config = {
// 下記のURLからクロールを開始する
url: "https://weel.co.jp/media",
// 上記のパターンに一致するURLのみをクロールする
match: "https://weel.co.jp/media/**",
//このセレクタ内のテキストのみを取得する
selector: `.l-mainContent`,
// クロールするページ数
maxPagesToCrawl: 50,
//結果が出力されるファイルの名前
outputFileName: "output.json",
};今回は弊社WEELの公式サイトをクローリングしてみます。詳細はコード内のコメントに書いていますが少し補足です。
「 selector:」という箇所はCSSセレクタとなります。上記の場合、CSSのクラス「l-mainContent」の中のコンテンツのみ、クローリングするという設定になります。
設定ファイルを保存したら準備は完了です。下記コマンドでGPT Crawlerを起動します。
npm startすると、設定ファイルで指定したURLからクローリングを始めます。
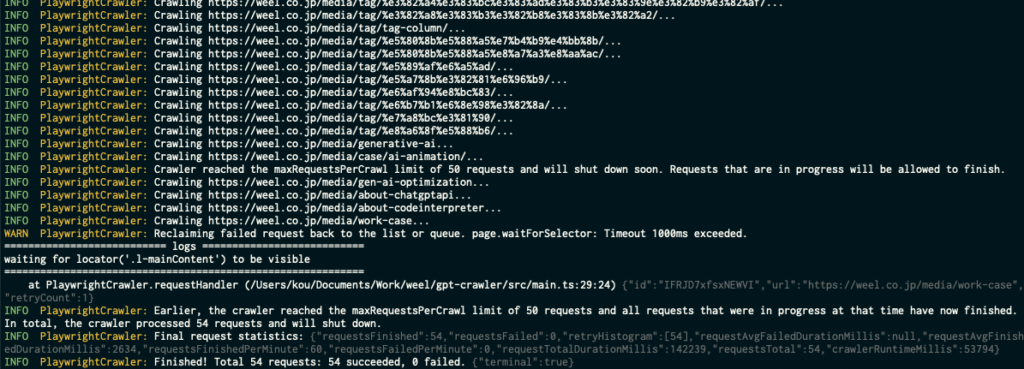
「Finished!」の記述が表示されれば、クローリング完了です。設定ファイルで指定した名前でjsonファイルが吐き出されていると思います。
ChatGPTでの準備
ChatGPTの左下に表示されているアカウント名をクリックしたあと、「My GPTs」をクリックします。
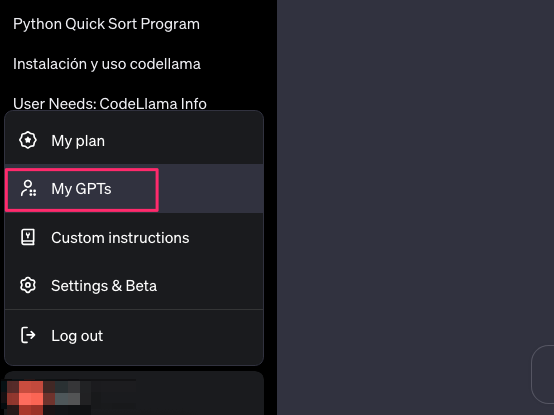
「Create a GPT」をクリックし、次の画面で「Configre」タブを選択します。「Name」にGPTの名前を入力し、「Knowledge」でjsonファイルをアップロードします。最後に右上のSaveボタンをクリックしたら、ChatGPTでの準備は完了です。
とはいえ、GPTsの上手な使い方がいまいちよくわからない・・・という方は下記の記事も合わせてご確認ください。

GPT Crawler を Docker コンテナとして実行する
Dockerでコンテナ実行をしていきましょう。
まずはリポジトリを取得します。
git clone https://github.com/builderio/gpt-crawler
cd gpt-crawler/containerapp続いて設定の編集。containerapp/config.tsを開きます。
export const defaultConfig = {
url: "https://example.com/docs",
match: "https://example.com/docs/**",
selector: "main", // 抽出したいコンテンツ領域
maxPagesToCrawl: 100,
outputFileName: "output.json", // コンテナ向け既定設定
};最後に実行です。
docker build -t gpt-crawler .
docker run --rm -v "$(pwd)/data:/app/data" gpt-crawler普段からDockerに使い慣れている方はそこまで難しくないかと思います。
Assistants APIの使い方
GPT CrawlerではGPTsの他にAssistants APIとしても使うことができます。
jsonファイルを作るところまでは前述したものと一緒です。作成したjsonファイルを下記のコードで呼び出すことでクロール済みサイトを質問可能なチャットボットに変えることができます。
// test.ts
import "dotenv/config";
import OpenAI from "openai";
import fs from "node:fs";
const FILE_PATH = "/output-1.json";
async function main() {
const apiKey = process.env.OPENAI_API_KEY;
if (!apiKey) throw new Error("OPENAI_API_KEY が未設定です");
if (!fs.existsSync(FILE_PATH)) throw new Error(`ファイルが見つかりません: ${FILE_PATH}`);
const client = new OpenAI({ apiKey });
// 1) ファイルアップロード(purpose=assistants)
const file = await client.files.create({
purpose: "assistants",
file: fs.createReadStream(FILE_PATH),
});
console.log("✅ アップロード:", file.id);
// 2) アシスタント作成(tools は file_search のみ)
const assistant = await client.beta.assistants.create({
name: "Site Knowledge Assistant",
model: "gpt-4o-mini",
instructions:
"付与された知識(メッセージ添付のファイル)から日本語で要点を3つ、根拠を短く添えて答えてください。",
tools: [{ type: "file_search" }],
});
console.log("✅ Assistant:", assistant.id);
// 3) スレッド作成:最初のメッセージにファイルを attachments で渡す(tools=file_search)
const thread = await client.beta.threads.create({
messages: [
{
role: "user",
content: "このサイトの要点を3つ挙げてください。",
attachments: [{ file_id: file.id, tools: [{ type: "file_search" }] }],
},
],
});
console.log("✅ Thread:", thread.id);
// 4) Run を開始し、createAndPoll で完了まで待機(引数ズレの事故を防ぐ)
const run = await client.beta.threads.runs.createAndPoll(thread.id, {
assistant_id: assistant.id,
});
console.log("✅ Run status:", run.status);
// 5) 応答取得
const msgs = await client.beta.threads.messages.list(thread.id);
for (const m of msgs.data.reverse()) {
for (const c of m.content) {
if (c.type === "text") {
console.log("------ RESPONSE ------");
console.log(c.text.value);
}
}
}
}
main().catch((e) => {
console.error("❌ エラー:", e);
process.exit(1);
});上記のコードを使うことで、Crawlerで得た知識をAssistants API経由で活用することが可能です。GPTsはChatGPT内で使うことに限局されますが、Assistants API経由で活用することで、プログラムから呼び出すことができる・ChatGPTを使っていない人でも利用できるといったメリットがあります。
GPT Crawlerを実際に使ってみた
では早速GPT Crawlerを使ってみましょう!ChatGPTの画面の左上に、さっき作ったGPTsが表示されているのでクリックします。ここでは「Test Crawler」という名前になります。
あとは普通のChatGPTと同じ使い方です。
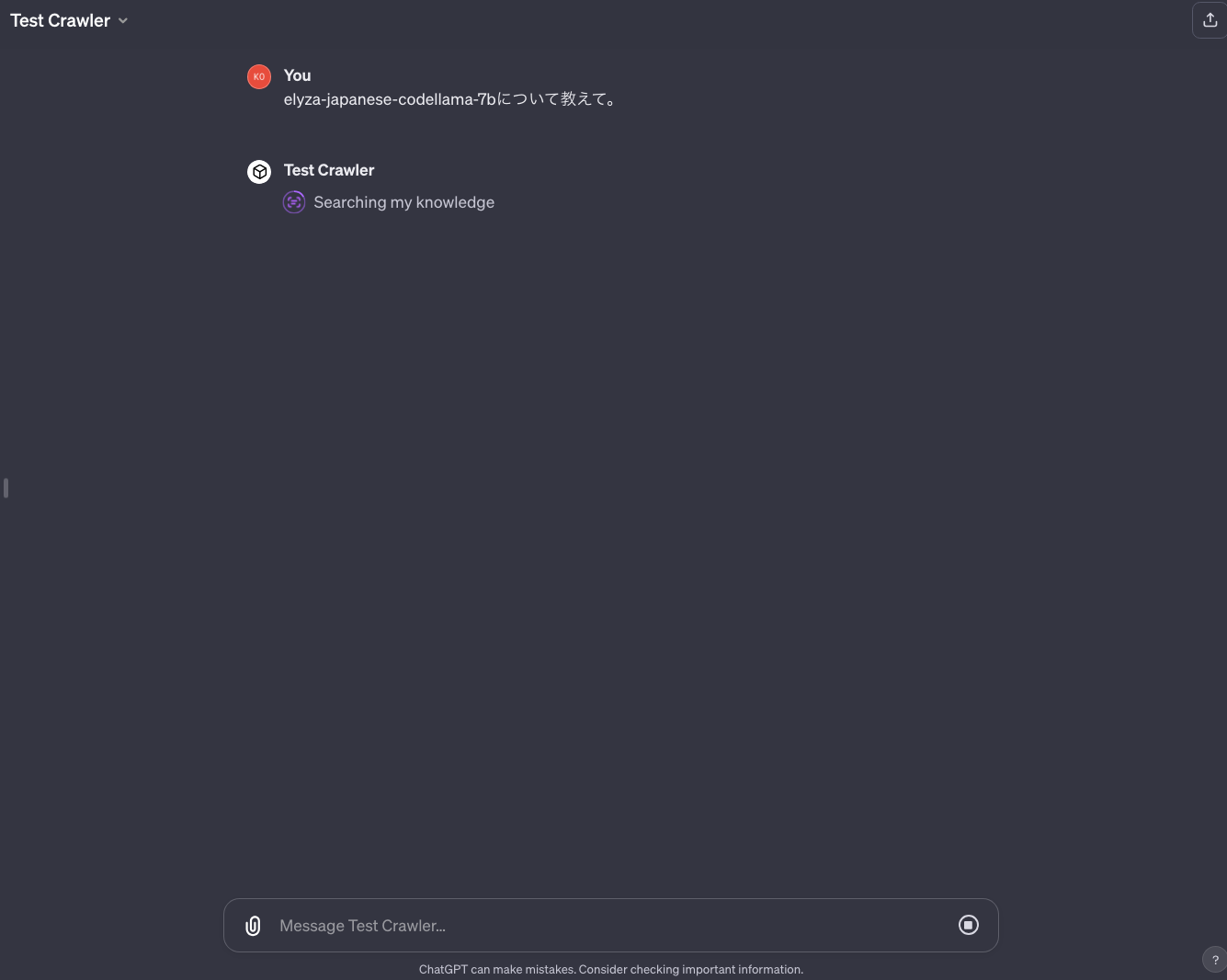
異なるのは、読み込ませたjsonファイルに存在する情報をプロンプトに入力すると、「Searching mu knowlede」と表示されるところです。例えば、「elyza-japanese-codellama-7bについて教えて」と入力すると。。。
ChatGPTがウェブサイトから情報をクローリングし、回答してくれます。すごい!

では読み込ませたjsonファイルに全く関係のない質問の場合はどうなるのか、試してみました。

ちゃんと回答されましたね。関係のない質問は、普通のChatGPTが答えてくれるようです。次に、今回は50ページしかクロールさせていないので、その範囲外の情報を聞いてみます。

すると、「手元の資料(読み込んだjsonファイル)には詳しく記載されていないが、他の記事にありそう」ということを教えてくれました!
ちなみに、普通のChatGPTで同じ質問をすると・・・

そんなもんは知らん、と言われてしまいました。。。
ChatGPTは万能ではありませんが、GPT Crawlerを使えば自分好みのGPTsを簡単に作成することができるため、作業効率がグッとあがることでしょう!
本記事を読んでGPTsは設定できたけどプロンプトの作り方に迷っている方は下記記事を合わせてご確認ください。

GPT Crawlerで独自のGPTsを作成してみよう!
GPT Crawlerは、【サイトのURLを指定するだけで、独自のGPTsを作成できるソフトウェア】です。作成したGPTsは、自社サイトやサービスに設置して、チャットボットとしても利用できます。
GPT CrawlerでGPTsを作成するメリットは以下の2点。
- [ユーザー視点]:GPTsに質問するだけで疑問が解決するため、リサーチの手間が省ける。
- [開発者視点]:GPTsが自動でユーザーとやり取りしてくれるため、顧客対応業務の負担が軽減される。
GPT Crawlerを使えば最短2分でGPTsが作れるので、興味のある方はぜひお試しください!

最後に
いかがだったでしょうか?
自社サイトに合わせたGPTsを短時間で構築し、顧客対応や業務効率化を強化する具体的な導入方法を紹介します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

