
【V-JEPA】Meta開発、動画内の物理世界を機械に理解させるフレームワークを徹底解説

WEELメディア事業部LLMリサーチャーの中田です。
2月16日、動画内でマスクされた部分を予測する汎用モデル「V-JEPA」を、Metaが公開しました。
このモデルを用いることで、様々な画像・動画の下流タスクに応用できるんです、、、!
公式のXでのいいね数は、公開から1日足らずで2000を超えており、世界中で注目されていることが分かります。
この記事ではV-JEPAの使い方や、有効性の検証まで行います。本記事を熟読することで、V-JEPAの凄さを実感し、様々なタスクに応用したくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
V-JEPAの概要
Metaによって開発されたV-JEPAは、動画内の物体間の細かい相互作用や時間の経過に伴う細かい動きを認識し、予測できるモデルです。例えば、ペンを置く、拾う、置くふりをするといった動作を映像から推測できます。
V-JEPAの学習では、動画内の映像の大部分をマスキングして隠し、そのマスク部分をV-JEPAに推測させます。
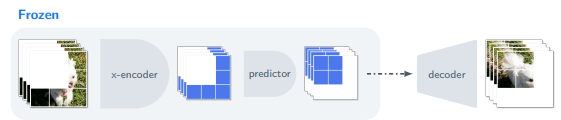
例えば、下図の1行目のように、一部分を白色でマスクした映像を、J-JEPAに入力します。

そして、アウトプットとして、マスクされた部分を補完した完全な動画を出力します。
V-JEPAの最大の特徴は、予測不可能な情報を捨てることで、学習と推論の効率が1.5倍から6倍に改善されている点です。また、特定のタスクに特化せず、汎用性のある動画モデルとしても有用です。
例えば、以下の画像では、V-JEPAによって予測した動画のマスクを、「Image classification(画像分類)」や「Action classification(行動分類)」など、様々な動画・画像タスクに応用している様子を表しています。
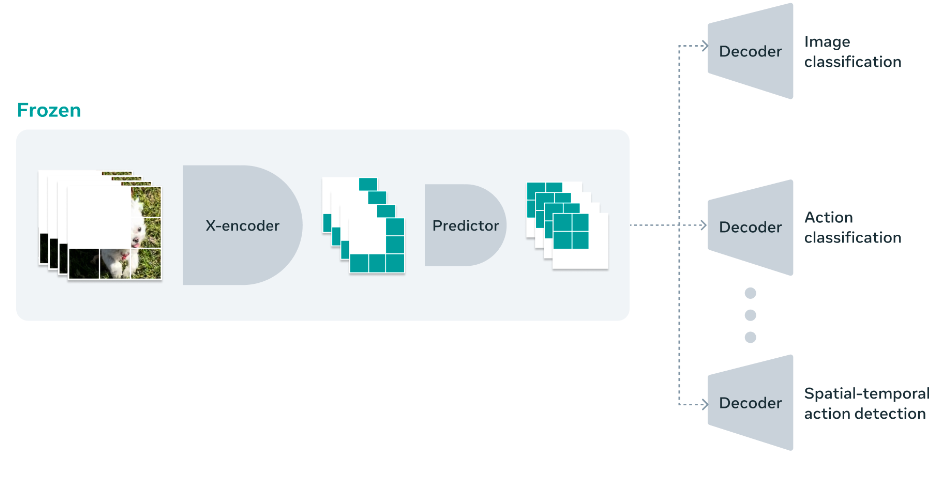
まとめると、V-JEPAは動画の理解能力が高く、様々な下流タスクに応用可能な汎用モデルと言えるのです。
なお、Metaの音楽・音声生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【MAGNeT】Meta開発のテキストから音楽や音声を生成できるAIの使い方~実践まで
V-JEPAのライセンス
V-JEPAのモデルは、CC BY-NC ライセンスの下で一般公開されています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️(非商用目的に限り) |
| 配布 | ⭕️(非商用目的に限り) |
| 特許使用 | ❌ |
| 私的使用 | ⭕️(非商用目的に限り) |
V-JEPAの使い方
ここでは、公式のGitHubページに載っている方法をご紹介します。
まずは、以下のコードを実行して、リポジトリのクローンとライブラリをインストールをしてください。
git clone https://github.com/facebookresearch/jepa.git
cd jepa
pip install -r requirements.txt次に、事前学習済みモデルを評価する場合、もしくは学習に使用する場合は、READMEファイル内のリンクから必要なモデルのチェックポイントとConfigをダウンロードしてください。
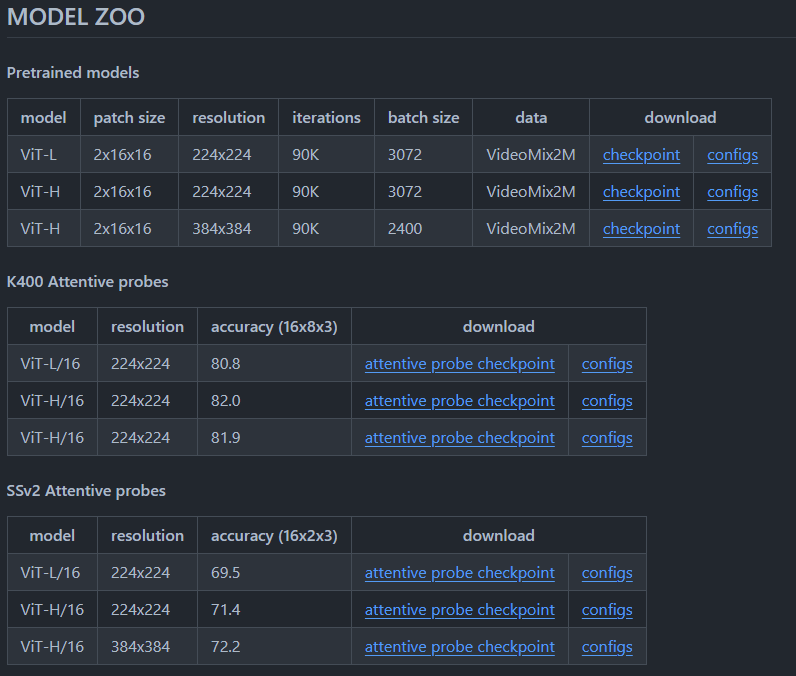
モデルを学習させる場合は、以下のコマンドを実行しましょう。
python -m app.main --fname configs/pretrain/vitl16_finetune.yaml --devices cuda:0 cuda:1モデルの評価をする場合は、以下のコードを実行してください。
python -m eval.main --fname configs/eval/vitl16_in1k.yaml --devices cuda:0 cuda:1 cuda:2このコマンドは「GPU cuda:0」を使用して、ImageNetデータセット上でViT-Lモデルを評価します。
V-JEPAを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.9以上
■使用ディスク量
約4.0GB以上
■RAMの使用量
約10GB以上(推測)
なお、Metaのアバター生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Audio2Photoreal】Meta開発の音声入力だけで一瞬でAIアバターを作成できるツールを使ってみた
V-JEPAをどのように応用できるのか?
本モデルを具体的なサービスに落とし込むのは、ハードルが高いかもしれません。というのも、V-JEPAは画像・動画タスクのための、いわば基盤的なモデルです。そのため、具体的なサービスに利用する場合は、ある程度の開発期間と費用を設けて、活用することになるでしょう。
今後は、具体的な応用について模索する必要があるのかもしれません。ちなみに、Meta社も公式ブログで、以下の様に記述しています。
V-JEPA is a research model, and we’re exploring a number of future applications.
参考:https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/?utm_source=twitter&utm_medium=organic_social&utm_campaign=vjepa&utm_content=video
和訳:
V-JEPAは研究モデルであり、私たちMetaは、将来的な応用を数多く模索している。
また、以下の様に、V-JEPAの応用についても言及しています。
For example, we expect that the context V-JEPA provides could be useful for our embodied AI work as well as our work to build a contextual AI assistant for future AR glasses. We firmly believe in the value of responsible open science, and that’s why we’re releasing the V-JEPA model under the CC BY-NC license so other researchers can extend this work.
参考:https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/?utm_source=twitter&utm_medium=organic_social&utm_campaign=vjepa&utm_content=video
和訳:
例えば、我々は、V-JEPAが提供するコンテキストが、我々の具現化AIの研究や、将来のARグラスのためのコンテキストAIアシスタントを構築する我々の研究に役立つと期待している。私たちは、責任あるオープンサイエンスの価値を固く信じており、だからこそ、他の研究者がこの研究を拡張できるように、V-JEPAモデルをCC BY-NCライセンスの下で公開しているのです。
やはり、V-JEPAの強みは、やはり動画の内容の理解力の高さなので、それを活用したARグラスなどのサービス展開が期待されます。

例えば、V-JEPAの「動画内の人がどんな行動をとったのか」を分類する「行動認識能力」を、ARグラスに活用できるかもしれません。具体的には、グラスをはめた人が運転中に居眠りをしてしまっても、グラスがそれを認識してアラートをかけてくれるかもしれません。
また、そのような認識技術を自動車のフロントに取り付けることで、自動運転システムをサポートするようなシステムに組み込むことも可能でしょう。

他にも、YouTubeやTikTokなどの動画コンテンツの内容をV-JEPAによって解析し、それをSSNSマーケティングに活用することも可能でしょう。さらに、AGIの「目」の役割を担うシステムに、もしかしたらV-JEPAの技術が組み込まれるかもしれません。
やはり、自社の強みを活かして、MetaがSNSなどで何かしらの新機能を打ち出してくる可能性があるでしょう。今後の動向に、目が離せません。
なお、Metaの多言語翻訳AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【SeamlessM4t】Metaの多言語翻訳AI、使い方から実践まで徹底解説
V-JEPAを様々な画像・動画タスクに応用しよう
Metaが開発したV-JEPAは、動画内の物体間の細かい相互作用や動きを理解し予測するモデルです。この技術は、動画の一部を隠し、その隠された部分を推測させることで学習します。
また、予測不可能な情報を捨てることにより、学習と推論の効率を大幅に向上させています。
さらに、V-JEPAは汎用性が高く、様々な応用が可能であり、動画の深い理解力を生かしたサービス、例えばARグラスでの行動認識や自動運転支援、SNSマーケティングへの応用が期待されまるでしょう。ただし、具体的なサービスへの適用には、開発期間と費用が必要になる可能性があります。今後の新機能開発において、この技術がどのように活用されるか注目されます。
ちなみに、あるXユーザーも、「機械が見ることによって、世界の仕組みを理解するための一歩」と語っています。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

