
【MAGNeT】Meta開発のテキストから音楽や音声を生成できるAIの使い方~実践まで

WEELメディア事業部LLMリサーチャーの中田です。
1月9日、FacebookのMeta社が、テキストから音楽や音声を生成できるAI「MAGNeT」を公開されました。
このAIを用いることで、自然言語によるプロンプトだけで、誰でも簡単に高品質な音楽・音声を生成できるんです、、、!
MAGNeTに関するXの投稿の閲覧数は、すでに14万を超えており、大注目のAIモデルであることが分かります。
この記事ではMAGNeTの使い方や、有効性の検証まで行います。本記事を熟読することで、MAGNeTの凄さを実感し、その他の自動音楽・音声生成ツールには戻れなくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
MAGNeTの概要
MAGNeT(Masked Audio Generation using a Single Non-Autoregressive Transformer)は、テキストから音楽・音声へ変換するモデルです。
MAGNeTのモデル構造は、以下の通りです。
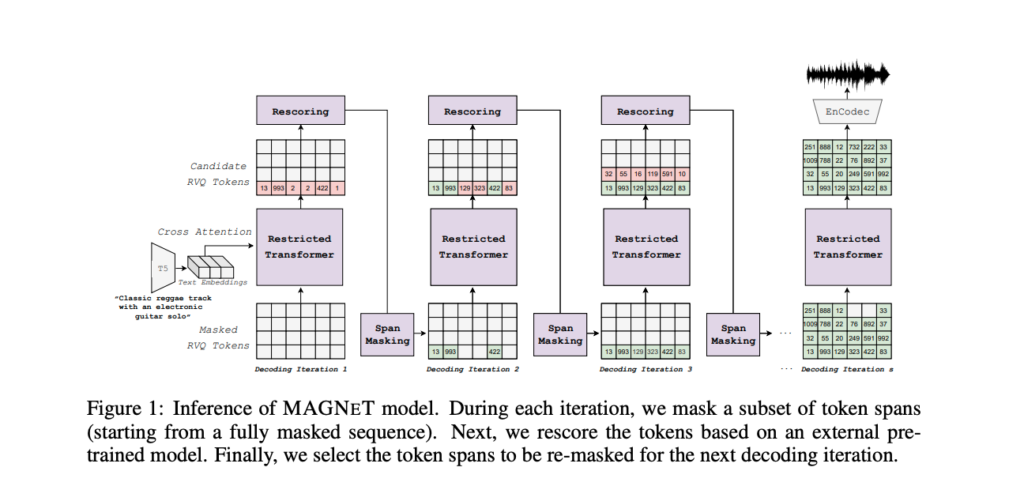
主な構造としては、音を言葉(トークン)として扱い、Transformerなどで処理しています。大まかな生成過程は、以下の通りです。
- 音のトークンを全てマスクする
- マスクされたトークンを、Transformerによって、音のトークンに復元
- これを、すべてのトークンが復元されるまで繰り返す
MAGNeTの学習には、16,000時間の音楽データを使用しています。

MAGNeTの料金体系
GitHubリポジトリによると、MAGNeTのライセンスは以下の通りです。
- コードはMITライセンスの下でリリース
- モデルの重みは、CC-BY-NC 4.0ライセンスの下でリリース
MAGNeTは無料で利用できます。
ただし、モデルの重みはクリエイティブ・コモンズの非商用利用(BY-NC)ライセンスに基づいてるため、商用目的での使用は制限されています。
なお、日本語の発音が完璧な音声生成AIについて知りたい方はこちらの記事後をご覧ください。
→【Style-Bert-VITS2 JP-Extra】日本語の発音・イントネーションが完璧な次世代AIを使ってみた
MAGNeTの使い方
今回はGoogle ColabのT4 GPUランタイム上で実行しました。
まずは、以下のコードを実行して、リポジトリのクローンから、ライブラリのインストールまで完了させましょう。
!git clone -b magnet https://github.com/camenduru/audiocraft
%cd /content/audiocraft
!pip install -q av julius omegaconf einops num2words flashy torchmetrics sentencepiece
!pip install -q https://github.com/camenduru/wheels/releases/download/colab/xformers-0.0.20+1dc3d7a.d20240115-cp310-cp310-linux_x86_64.whl
!pip install -q .
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/facebook/audio-magnet-medium/resolve/main/state_dict.bin -d /content/audiocraft/audio-magnet-medium -o state_dict.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/facebook/audio-magnet-medium/resolve/main/compression_state_dict.bin -d /content/audiocraft/audio-magnet-medium -o compression_state_dict.bin続いて、以下のコードを実行することで、音楽を生成できます。
%cd /content/audiocraft
from audiocraft.models import MAGNeT
#model = MAGNeT.get_pretrained('/content/audiocraft/audio-magnet-medium')
model = MAGNeT.get_pretrained('facebook/magnet-small-10secs')
model.set_generation_params(
use_sampling=True,
top_k=0,
top_p=0.9,
temperature=3.0,
max_cfg_coef=10.0,
min_cfg_coef=1.0,
decoding_steps=[int(20 * model.lm.cfg.dataset.segment_duration // 10), 10, 10, 10],
span_arrangement='nonoverlap'
)
from audiocraft.utils.notebook import display_audio
###### Text-to-music prompts - examples ######
text = "80s electronic track with melodic synthesizers, catchy beat and groovy bass"
# text = "80s electronic track with melodic synthesizers, catchy beat and groovy bass. 170 bpm"
# text = "Earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves"
# text = "Funky groove with electric piano playing blue chords rhythmically"
# text = "Rock with saturated guitars, a heavy bass line and crazy drum break and fills."
# text = "A grand orchestral arrangement with thunderous percussion, epic brass fanfares, and soaring strings, creating a cinematic atmosphere fit for a heroic battle"
N_VARIATIONS = 3
descriptions = [text for _ in range(N_VARIATIONS)]
print(f"text prompt: {text}\n")
output = model.generate(descriptions=descriptions, progress=True, return_tokens=True)
display_audio(output[0], sample_rate=model.compression_model.sample_rate)ここでは、「80s electronic track with melodic synthesizers, catchy beat and groovy bass」というプロンプトで、音楽を生成しました。
ちなみに、結果はColabの出力画面に、以下のような形で出力されるので、そこから生成された音楽を聴くことができます。
MAGNeTを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.9
また、実行する際に、最低でも16GBのメモリが必要とのこと。
MAGNeTを実際に使ってみた
ここでは、「90s Hip-hop music with melodic guitar, catchy beat and groovy bass」というプロンプトを入力してみようと思います。90年代ヒップホップで、メロディックなギターが鳴り、キャッチーなビートとベースが流れていればOKですが、いかがでしょうか、、、
かなりプロンプトの内容に沿ったヒップホップビートが出来上がりました!
日頃からビート制作する私からしても、かなり品質高いと思います。また、ギターのメロディやベースの部分も、きちんとプロンプト通りなのが、良いポイントですね。
なお、OpenAIのWhisperが高性能になったWhisperSpeechについて知りたい方はこちらの記事をご覧ください。
→【WhisperSpeech】Whisperがさらに高性能になった音声モデルを使ってエミネムにゆっくり喋らせてみた
MAGNeTの推しポイントである最高性能での音楽生成は本当なのか?
MANGeTの公式リポジトリには、State-of-the-artと書かれており、論文でも性能の高さが示唆されています。以下の表は、MAGNeTとその他のText-to-Musicのモデルとの性能比較の表で、一番上の行のFADvggからLATENCY(s)までが、評価指標を表します。ちなみに、矢印の向きが↓であれば、「その評価指標の値が低ければ低い程、性能が高い」ということを表します。

この表より、あらゆる指標において、他モデルよりも性能が良いことを表しています。
そこで、そんなMAGNeTの真の実力を確かめるために、AudioCraftの1つである「MusicGen」と比較してみます。MusicGenは、以下のHuggingFaceのデモページで動かせます。
参考記事:MusicGen
先ほどMAGNeTに入力したプロンプトと同じ内容の文章を、MusicGenに入力した結果、以下のようになりました。
品質は高いと思いますが、ベースの音が無く、ギターのメロディがさほど強調されていないことから、MAGNeTに比べてプロンプトの内容をとらえきれていない印象でした。
まとめ
MAGNeT(Masked Audio Generation using a Single Non-Autoregressive Transformer)は、テキストから音楽・音声へ変換するモデルです。主な構造としては、音を言葉(トークン)として扱い、Transformerなどで処理しています。
実際に生成させてみると、かなりプロンプトの内容に沿った、質の高い音楽が出来上がりました!日頃からビート制作する私からしても、かなり品質高いと思います。
MusicGenに同じことを試したところ、品質は高かったですが、MAGNeTに比べてプロンプトの内容をとらえきれていない印象でした。
数年後には、誰もが即興作曲できるDJになっているのかもしれないですね。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

