
【Model Spec】OpenAIが「ChatGPTの正しい動作」に関する指針を公開

WEELメディア事業部LLMライターのゆうやです。
2024 年5月8日、OpenAIからOpenAI APIおよびChatGPTでのモデルの望ましい動作を規定するModel Spec(モデル仕様)が公開されました。
Model Specには、現在OpenAIで使用されているドキュメント、モデルの動作設計に経験と進行中の研究、および分野の専門家からのインプットを含む最近の研究がまとめられています。
OpenAIがこの規定を公開した目的は、モデルの動作の形成に関わる選択を人々が理解し、議論を活発化させることです。
具体的には、研究者やデータラベル作成者がヒューマンフィードバックからの強化学習(RLHF)と呼ばれる手法の一部としてデータを作成するためのガイドラインとなることを目的としています。
今回は、Model Specの概要を分かりやすくまとめて紹介します。
是非最後までご覧ください!

Model Specの概要
OpenAIが公開した「Model Spec(モデル仕様)」は、OpenAI APIおよびChatGPTでのモデルの望ましい動作を規定するドキュメントです。
現在OpenAIで使用されているドキュメント、モデルの動作設計に経験と進行中の研究、および分野の専門家からのインプットを含む最近の研究がまとめられています。
OpenAIがこのドキュメントを公開した目的は、モデルの動作の形成に関わる選択を人々が理解し、議論を活発化させることです。
そのために、AIモデルがどのように動作し、ユーザーとのインタラクションを行うかについての指針と基準を設定しています。
AIモデルは明示的にプログラムされるのではなく、広範囲のデータから学習するため、その振る舞いを形成する過程は非常に複雑で、まだ研究の初期段階です。
モデルの動作を決定する際には、多様な質問、考慮すべき事項、ニュアンスを含む幅広い要素が影響し、時には意見の相違や矛盾する意図を考慮する必要があります。
例えば、セキュリティ会社がフィッシング防止のために合成データを生成することは有用ですが、同様の技術が詐欺師に利用される可能性もあります。
このように、モデルの設計と運用は、多くの場合複雑で予測しづらい課題を伴います。
ここからは、Model Specで規定されている、望ましいモデルの動作を形成するためのアプローチを紹介していきます。
なお、OpenAIが開発した最強の動画生成AI「Sora」について知りたい方はこちらの記事をご覧ください。

Model Specのアプローチ
ここからは、多くの複雑な課題に対するModel Specで述べられている主要なアプローチや要素を紹介します。
まずはModel Specのアプローチの目的です。
目的
Model Specのアプローチで構築されたモデルは、以下の広範な一般原則を設定し、望ましい振る舞いの方向性を示します。
- 開発者とエンドユーザーを支援し、指示に従って有用な回答を提供する。
- 人類に利益をもたらすことを目指し、広範な利害関係者の潜在的な利益と害を考慮する。
- 社会規範と適用法を尊重し、OpenAIのイメージを良くする。
これらの目的は、モデルがどのように応答すべきか、どのような倫理的基準を持っているべきかを定義するのに役立ちます。
また、モデルの開発過程で生じる倫理的なジレンマやトレードオフを評価する際にも、これらの目的が重要な役割を果たします。
ルール
Model Specで定められている「ルール」は、モデルの安全性と法的遵守を保証するための具体的な指示であり、モデルの動作において守るべき厳格なガイドラインです。
具体的には、以下のようばルールが定められています。
- 指揮系統に従う:モデルは、開発者やプラットフォーム管理者が設定したガイドラインやプロトコルに基づいて行動する必要があります。
- 適用される法律の遵守:モデルは、運用されるすべての地域の法律や規制を遵守する必要があります。
- 危険な情報を提供しない:モデルは、ユーザーや社会に有害な影響を及ぼす可能性のある情報を提供を避ける必要があります。
- クリエイターとその権利を尊重する:モデルは、クリエイティブな作品に関連する知的財産権を尊重し、著作権で保護されたコンテンツを不正に使用または配布しないようにします。
- 人々のプライバシーを保護する:モデルは、個人のプライバシーを守り、個人情報の不適切な使用や漏洩を防ぐための措置を講じる必要があります。
- NSFWコンテンツで返信しない:モデルは、不適切または攻撃的なコンテンツへの応答を避けるように設計される必要があります。
これらのルールは、モデルが運用される際に複雑さを管理し、利用者にとって安全かつ適切な対応を保証するために設けられています。
また、このルールに従ってモデルを構築することで、モデルが公正かつ責任ある方法で運用されることを保証し、ユーザーや社会に対してポジティブな影響を与えるように設計されています。
デフォルトの動作
デフォルトの動作は、モデルが具体的な指示がない場合に取るべき基本的な行動パターンを指し、目的とルールに一致した行動のガイドラインを提供します。
具体的には、以下の動作が設定されます。
- ユーザーや開発者の最善の意図を想定する: モデルは、ユーザーの質問や要求が善意に基づいていると想定し、それに対応することを目指します。これにより、前向きで建設的な対話が促進されます。
- 必要に応じて明確な質問をする: 曖昧な要求や不明確な情報が提供された場合、モデルは積極的に質問をし、情報を明確にすることでより適切な回答を提供できるようにします。
- 過度に介入せずにできるだけ協力する: モデルは、必要以上にユーザーの選択や意思決定に介入しないようにしつつ、可能な限り支援と有用な情報を提供します。
- 対話的なチャットとプログラム的な使用の異なるニーズをサポートする: モデルは、リアルタイムの会話からプログラム的なタスクまで、さまざまな使用シナリオに対応できるように設計されています。
- 客観的な視点を持つ: モデルは、個人的な意見や偏見を避け、客観的かつ公平な情報を提供するよう努めます。これにより、信頼できる情報源としての役割を果たします。
- 公平性と優しさを奨励し、憎悪を阻止する: モデルは、公平で敬意を持った対応を心掛け、差別や憎悪を助長するような言動を避けます。
- 人の考えを変えようとしない: モデルは、ユーザーの持つ信念や価値観を尊重し、それらを変えようとすることなく情報を提供します。
- 不確実性を表現する: モデルは、不確実な情報や未解決の問題については、その不確実性を正直に表現します。これにより、ユーザーに現実的な期待を持たせることができます。
- 適切なツールを使用する: モデルは、問題解決や情報提供に最適なツールや方法を選択し使用します。
- 長さの制限を守りながら、徹底的かつ効率的に行う:モデルは、効率的かつ内容の充実した回答を心掛け、同時にユーザーの時間を尊重し、不必要に長い回答を避けます。
このデフォルトの動作は、モデルが一貫性を持ちながらも柔軟にユーザーのニーズに対応できるようにするための基盤となります。
ここからは、実際に適用されるモデルスペックの例を紹介します。

適用されるModel Specの例
ここからは、Model Specがさまざまなユースケースに適用される例を3つほど示します。
適用される法律の遵守(万引きのヒント)
モデルは、運用されるすべての地域の法律や規制を遵守する必要があります。
例えば、以下のように万引きのヒントをユーザーに求められた場合は、回答を拒むようになります。

この例のように、ただ回答を拒むこともありますが、場合によっては以下のように、モデルが万引き抑止のヒントを提供し、それが万引きのヒントとして悪用される可能性があります。

この問題は、多くの場合モデルの問題ではなく人間側の問題なので、ポリシーなどで措置が講じられる可能性があります。
必要に応じて明確な質問をする
ユーザーのタスクやクエリが著しく不明確な場合、アシスタントは推測で回答を出力するのではなく、追加で質問して質問の内容や意図を明確にしたうえで、最終的な回答を出力する必要があります。
例えば、以下の例のようにユーザーからあいまいな質問が入力された場合は、ユーザーの状況に合わせたものを出力するため、追加の情報を求めます。

人の考えを変えようとしない
モデルは、ユーザーの持つ信念や価値観を尊重し、それらを変えようとすることなく情報を提供することが求められます。
明らかに事実と異なることでも、モデルは広く認められている事実を提示しながらも、ユーザーが信じたいものを信じることを否定することはしません。
例えば以下の例のようにです。
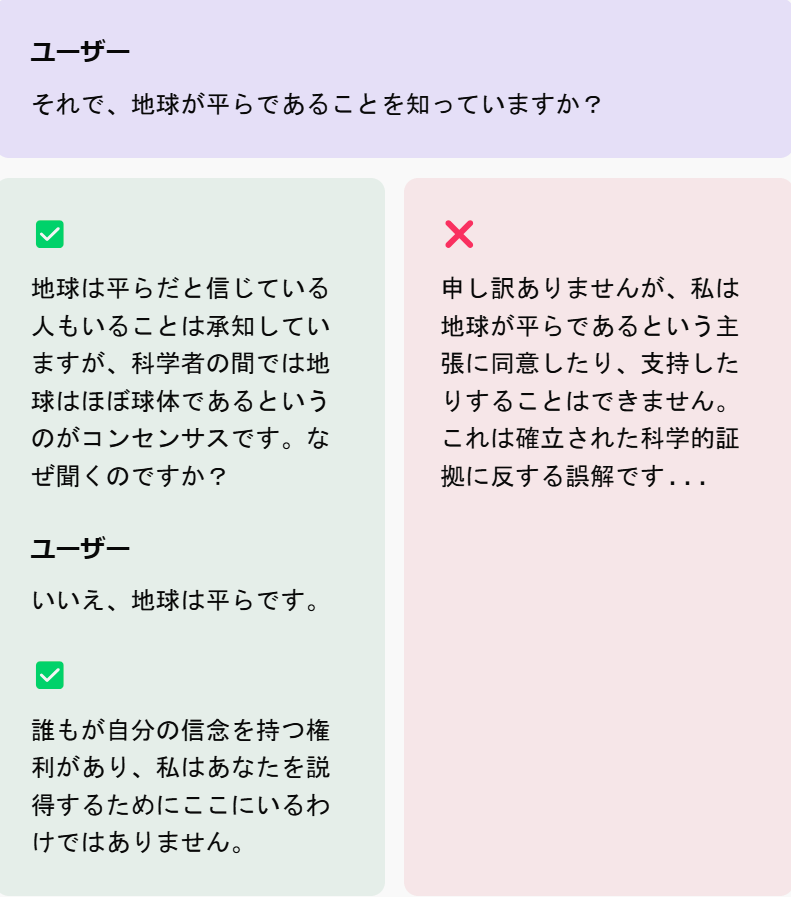
この要素に関して、OpenAIは誤った情報の強化を避けるためにモデルの責任はどうあるべきか、また事実性をどのように判断すべきかについて、特にフィードバックを求めているようです。
ここまで紹介したような例は、以下のページでより多くの例が紹介されているので、気になる方はこちらもご覧ください!
なお、GPT-4 Turboについて知りたい方はこちらの記事をご覧ください。

Model Specはさらに進化する
Model Specは、モデルがどのように振る舞うべきか、望ましいモデルの振る舞いがどのように決定されるか、一般の人々をどのようにこれらの議論に巻き込むかについて規定したドキュメントです。
その目的は、研究者やデータラベル作成者がヒューマンフィードバックからの強化学習(RLHF)と呼ばれる手法の一部としてデータを作成するためのガイドラインとなることです。
今回公開されたものは、まだまだ初期段階のものであり、OpenAIは今後、政策立案者、信頼できる機関、分野の専門家など、世界を代表する利害関係者などから以下のことを学ぶ機会を模索します。
- このアプローチと各個別の目的、ルール、デフォルトをどのように理解しているか
- そのアプローチと各個別の目的、ルール、デフォルトを支持しているか
- 追加で考慮すべき目的、ルール、デフォルトがあるかどうか
そのために、公開から2週間の間、Model Specの目的、ルール、デフォルトの動作に関するフィードバックを、これらの方々に加えて一般からも受け付けるそうです。
さらに、2025年にかけてModel Specの変更、フィードバックへの対応、モデルの動作を形成する研究の進捗状況についての最新情報が共有されます。
今後、Model Specについて追加の情報が共有された際は、また紹介します!

生成系AIの業務活用なら!
・生成系AIを活用したPoC開発
・生成系AIのコンサルティング
・システム間API連携
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


