
Qwen2.5-Coderで開発革命!?プログラミング特化LLMの概要から実力まで

2024年11月12日、アリババクラウドが新たな大規模言語モデル「Qwen2.5-Coder」をリリース!
「Qwen2.5」のコードバージョンである「Qwen2.5-Coder」は、オープンソースで公開され、コードアシスタントやコード生成に活用可能。
Qwen2.5-Coderを活用してさまざまな開発が可能で、SNSでも話題になっています。
Qwen2.5-Coderの詳細とGoogle Colaboratoryでの実装方法について解説します!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen2.5-Coderの概要
Qwen2.5-Coderシリーズは、「強力」で「多様」で「実用的」を目標とするモデルで、その中でもQwen2.5-Coder-32B-Instructは、GPT-4oのコーディング能力に匹敵する性能です。
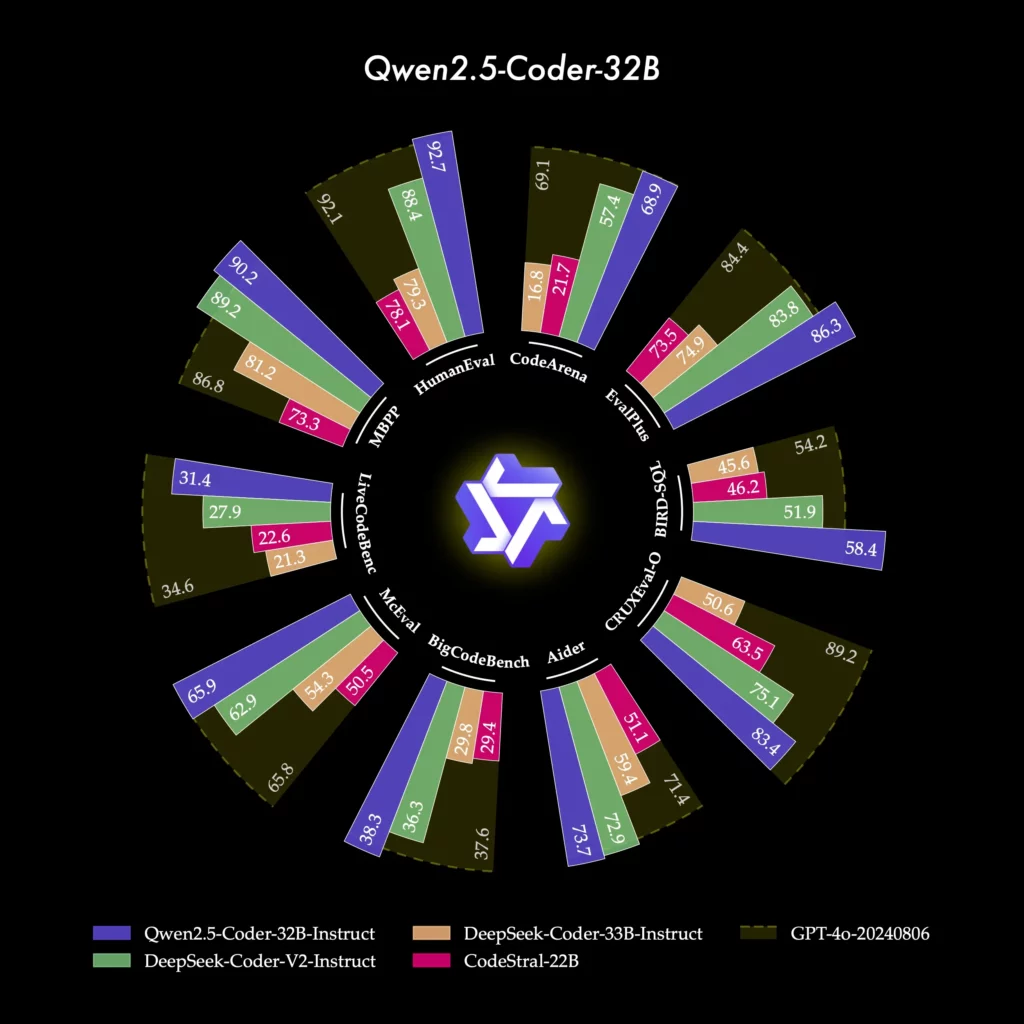
現在リリースされているオープンソースコードモデルとして、高性能なコーディング能力を示しており、また、コーディングだけでなく、一般的な知識と数学的スキルも優れています。
Qwen2.5-Coderは多様性にも優れており、これまでは1.5Bおよび7Bのモデルサイズのみでしたが、今回のリリースでは0.5B、3B、14B、32Bという新たな4つのモデルサイズを追加。これにより、合計で6つのモデルサイズを使うことができ、状況に応じてモデルを使い分けることができます。
このQwen2.5-Coderシリーズは、128Kトークンのコンテキスト長をサポートしており、長いコンテキストに対する理解と生成が可能です。サポートしているプログラミング言語数はなんと92言語!
Qwen2.5-Coderは「コードアシスタント」と「アーティファクト」という2つの実用的な環境において効果を発揮します。
長いテキスト処理においてはYaRN技術を活用し、ファイルレベルおよびリポジトリレベルでのコード補完もサポートします。また、vLLMを通じて分散サービングが可能であり、スケールアップに対応しています。
Qwen2.5-Coderのコーディング性能
コード生成において、Qwen2.5-Coder-32B-Instructはこのオープンソースリリースモデルとして、EvalPlus、LiveCodeBench、BigCodeBenchなどの複数の人気コード生成ベンチマークで、オープンソースモデル中で最高のパフォーマンスを達成しており、GPT-4oと競合する性能を発揮しています。
プログラミングスキルの一つとして、コード修正能力が挙げられますが、コード修正についても、Qwen2.5-Coder-32B-Instructは、ユーザーがコードのエラーを修正するのをサポートしてくれるそうです。
Aiderはコード修正のための人気ベンチマークで、Qwen2.5-Coder-32B-InstructはAiderで73.7点を獲得し、GPT-4oに匹敵するパフォーマンスを示しました。
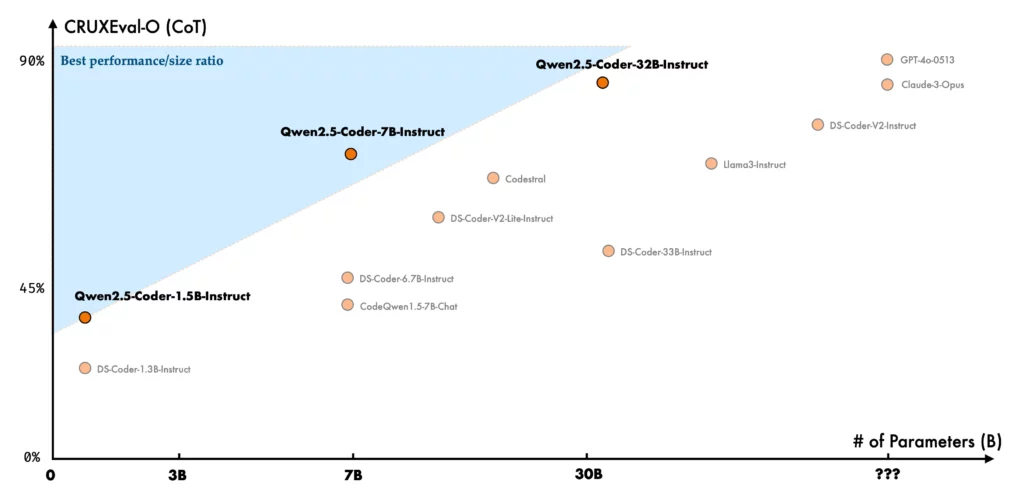
コード推論はモデルがコードの実行プロセスを学び、正確に入力と出力を予測する能力。最近リリースされたQwen2.5-Coder-7B-Instructはすでにコード推論において優れたパフォーマンスを示していますが、この32Bモデルはその性能をさらに向上させています。
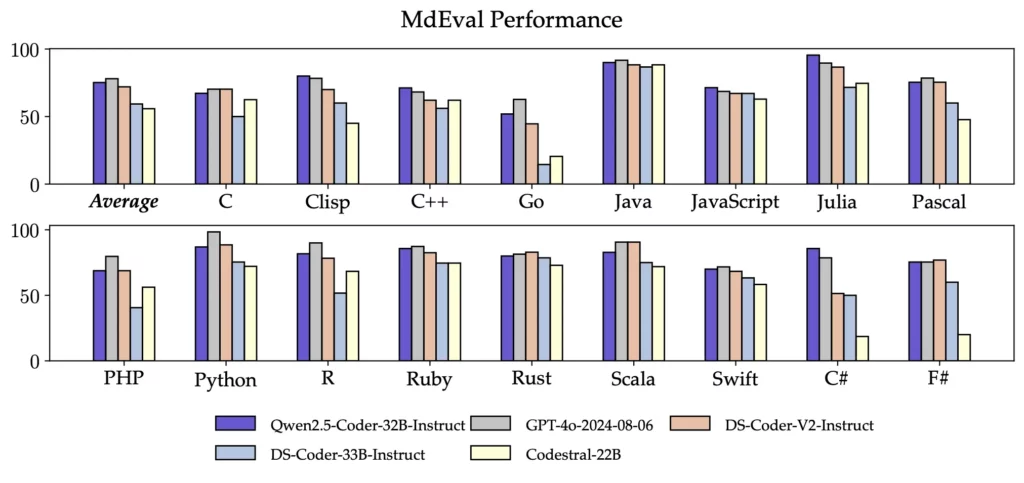
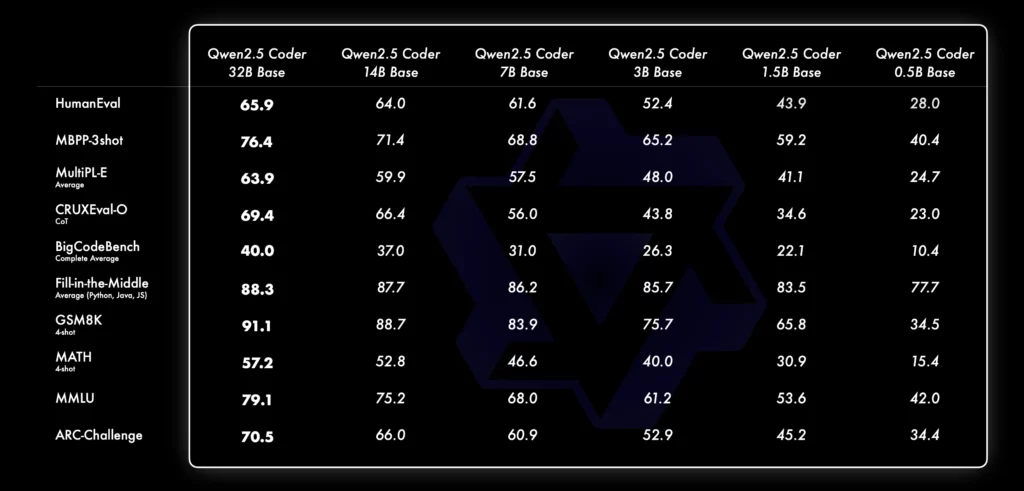
Qwen2.5-Coder-32B-Instructは、40以上のプログラミング言語において優れた性能を発揮し、McEvalで65.9のスコアを達成しました。特にHaskellやRacketなどの言語においても高いパフォーマンスを示しており、これは事前学習段階での独自のデータクリーニングとバランス調整の成果です。
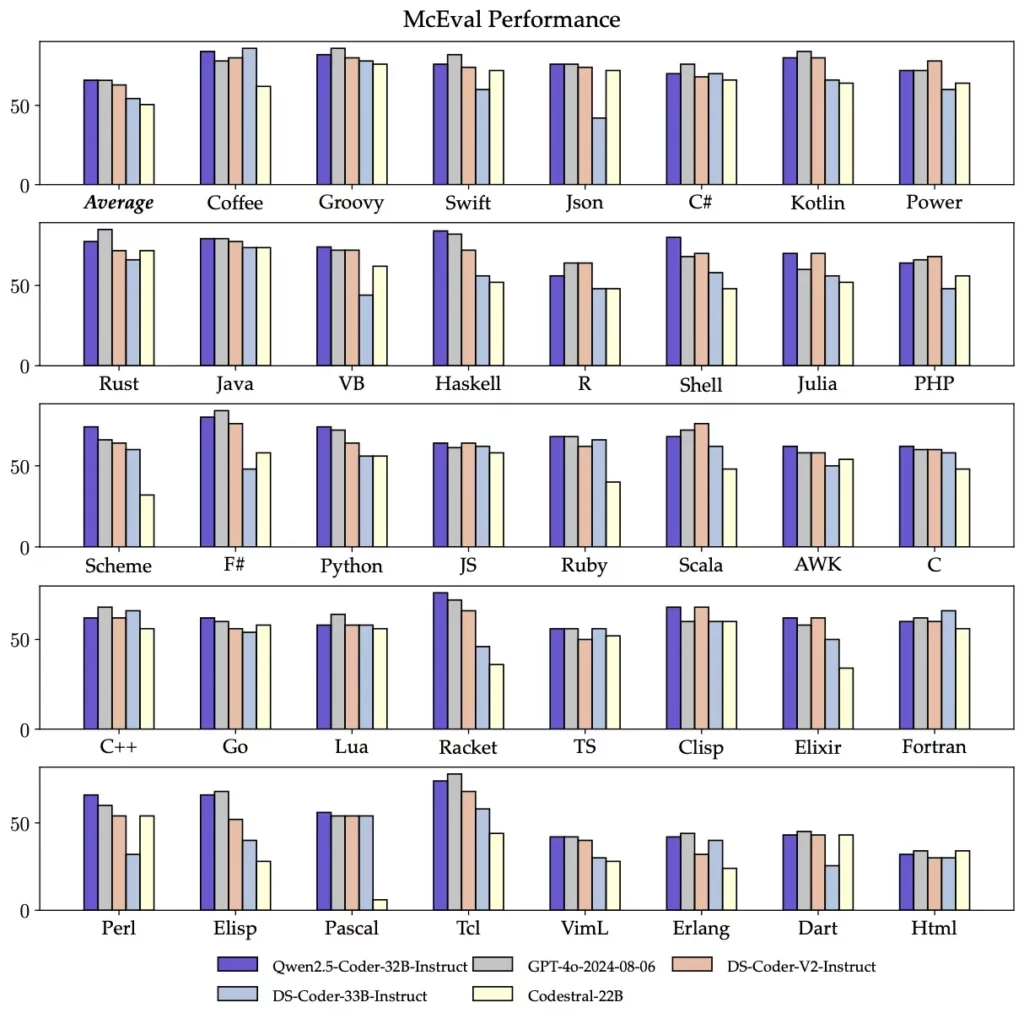
さらに、Qwen2.5-Coder-32B-Instructの多言語コード修正機能も優れており、ユーザーが理解しているプログラミング言語の修正や、未習得の言語の理解と修正をサポートすることで、学習コストを大幅に削減します。
MdEvalはMcEvalと同様に多言語のコード修正を評価するベンチマークであり、Qwen2.5-Coder-32B-Instructはこのテストで75.2のスコアを獲得し、すべてのオープンソースモデルの中で最高の評価を得ています。
なお、Qwen3.7-Plusについて詳しく知りたい方は、こちらの記事もぜひご覧ください。

Qwen2.5-Coderの各種モデル性能
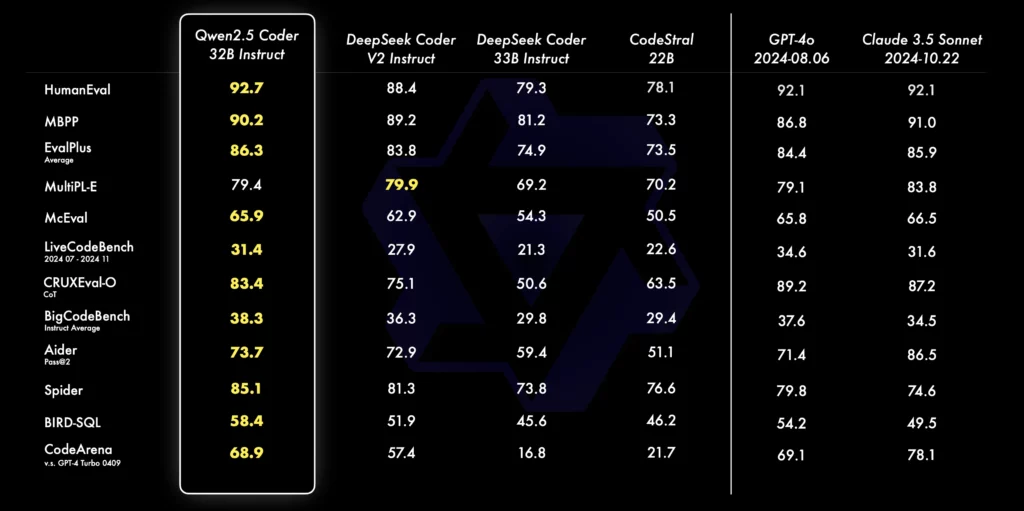
Qwen2.5-Coderの異なるサイズのモデルと他のオープンソースモデルとの比較を、主要なデータセットを使用して行った結果もあります。
まず、ベースモデルの評価指標としてMBPP-3shotを選定。多数の実験の結果、MBPP-3shotはベースモデルの評価に最適であり、実際の性能とよく相関していることが確認できます。
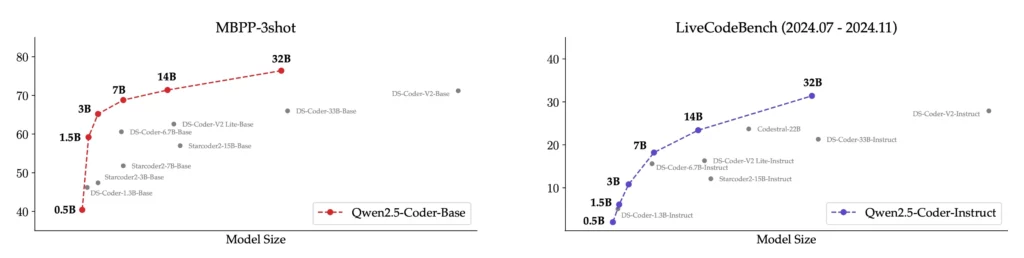
一方、指示モデルの評価には、LiveCodeBenchの最新4か月分(2024年7月から2024年11月)の質問を用いられています。
これらの質問は新たに公開されたもので、トレーニングセットに含まれている可能性はなく、モデルのOOD(Out-of-Distribution)能力を反映しています。
実験の結果、モデルのサイズと性能には正の相関があり、Qwen2.5-Coderはすべてのサイズにおいて最先端(SOTA)の性能を達成。
Qwen2.5-Coderのライセンス
0.5B、1.5B、7B、14B、32BモデルはApache 2.0ライセンス、3BモデルはQwen-Researchライセンスです。
Apache 2.0ライセンスは特許ライセンスを含んでいるため、商用利用を含む幅広い使用が可能。再配布や改変時に、元のライセンス条項と表示が求められます。以下の表は0.5B、1.5B、7B、14B、32Bモデルのライセンスです。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
こちらは3Bモデルの表です。3Bモデルは商用利用が不可であり、基本的には研究目的の用途で使われます。
特許使用も可能ですが、非商用目的で利用する場合のみ可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌(商用利用の場合には別途許可が必要) |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 🔺(制限付き) |
| 私的使用 | ⭕️ |
なお、Qwen2.5について詳しく知りたい方は、下記の記事を合わせてご確認ください。
Qwen2.5-Coderの使い方
では実際にQwen2.5-Coderを使っていきましょう!
使い方はHugging Face、GitHubどちらにも掲載されています。
また、ChatでのDemoも用意されているので、Qwen2.5-Coderを手軽に体感したい方は、Demoを使ってみてください
■Pythonのバージョン
Python 3.8以上
■システム RAM
33.4 / 83.5 GB
■GPU RAM
35.6 / 40.0 GB
■ディスク
93.4 / 112.6 GB
実行完了までには時間がかかりますが、google colaboratoryのA100であれば32Bモデルでもギリギリ動かすことができます。
では実際にgoogle colaboratoryでサンプルコードを動かしてみましょう。
まず、必要なライブラリのインストールをします。
!pip install transformers続いてモデルのダウンロードとコードの実行です。
ちなみに今回のタスクは「Write a quick sort algorithm in Python.(Pythonでクイックソートアルゴリズムを書いてみよう。)」です。
サンプルコードはこちら
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Model initialization
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load model with efficient settings for Colab
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, # Use float16 for memory efficiency
device_map="auto",
low_cpu_mem_usage=True
)
# Function to generate code
def generate_code(prompt, max_new_tokens=126):
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud."},
{"role": "user", "content": prompt}
]
# Apply chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# Prepare inputs
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate response
generated_ids = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens,
temperature=0.7,
do_sample=True,
)
# Process output
generated_ids = [
output_ids[len(input_ids):]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
# Example usage
prompt = "Write a quick sort algorithm in Python."
response = generate_code(prompt)
print(response)結果はこちら
python
def quick_sort(arr):
# Base case: if the array is empty or has one element, it's already sorted
if len(arr) <= 1:
return arr
else:
# Choose a pivot element from the array
pivot = arr[len(arr) // 2]
# Partition the array into three parts:
# - elements less than the pivot
# - elements equal to実行時の動画↓


AlibabaのQwen-AgentWorldについて詳しく知りたい方は、以下の記事をご覧ください。

Qwen2.5-Coderでコーディングをしてみた
Qwen2.5-Coderは従来のオープンソースモデルに比べて、コーディング能力が優れていると報告されています。
そこで、実際にコーディング性能を検証するために、動きのあるUIを実装させてみたいと思います!
さらに、Artifacts機能も用意されているのでClaudeのArtifacts機能と比較し、インベーダーゲームを作成してみます。
惑星の動きを表示するUIを作成してみた
まずは動きのあるUIを作成してもらいます。今回は画面上に地球と土星・火星のイメージを作ってもらい、それをドラッグで動かせる、クリックしたらその物体が分裂する、というやや複雑な内容にします。
コーディング能力を見るため、プログラミング言語も指定して実装してもらいます。今回はPythonで実装できるか試してみましょう。
プロンプトはこちらです↓
Please create a dynamic UI application or website using Python. On the UI, please create images of the Earth, Mars, and Saturn, and implement a function that allows the user to move these images by dragging them, and also a function that duplicates the image clicked on by the user.
和訳:Pythonを使って動的UIのアプリもしくはWebサイトを作ってください。UI上には地球・火星・土星をイメージとして作成し、ユーザーがドラッグするとそのイメージを動かせる、またイメージをクリックすることでクリックしたイメージと同じ内容のイメージを複製する、という機能を実装してください。
完成イメージとしては公式Xのポストです。
実際に動的なUIの作成をDemoに頼んでみた結果が以下の動画です。
また、実際に出力されたコードを実装して実行した動画は以下です。
Qwen2.5-Coderでコーディングを頼むとディレクトリ構造も表示されるので、Webアプリなどを作りやすいなという印象を受けます。また、エラーも出ずに一発で実装できたのも、個人的には高評価です。
Artifactsで惑星の動きを表示するUI作成に再挑戦
ちょっとイメージしていたものと異なっていたので、もう一つ作ってもらいます。こちらはArtifacts機能を使って作成してもらいます。
イメージは以下のポストです。
プロンプトとしては、次のように入力しました。
Create an app with a dynamic UI. Something like emoji that appear each time you click. Please add movement to the emoji, such as having multiple emoji appear randomly or popping up like they’re bouncing. Please create multiple patterns of movement and have them perform various movements at random.
和訳:動的UIのアプリを作って。クリックするたびに絵文字が出てくるような感じ。絵文字はランダムに複数出てきたり、弾けるように飛び出てきたり、動きをつけてください。まだ動きは複数のパターンを作っておき、ランダムでさまざまな動きをするようにしてください
Artifacts機能でインベーダーゲームを作ってみた
またArtifacts機能はClaudeにもあるので、ClaudeとQwen2.5-CoderのArtifacts機能でインベーダーゲームを作ってもらいます。
作られたインベーダーゲームはClaudeでは実際に遊ぶことはできましたが、Qwen2.5-Coderでは遊ぶことができませんでした。Qwen2.5-CoderのArtifacts機能では、実際に動かせるものと動かせないものが出てくるのかもしれません。
深層学習モデルの学習コードを作成させてみた
コード生成機能も試してみます。今回は「Qwen 2.5-Coderに画像認識モデルの学習および推論のスクリプトを作成させ、それを使用して画像認識ベンチマークでモデルの性能を評価し、高得点を狙う」ってこともやってみたいと思います!
まずはコードの作成です。
コードの作成はこちら
# Qwen2.5-Coderのセットアップ
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# モデル生成の依頼
messages = [
{
"role": "system",
"content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant specialized in deep learning and computer vision tasks."
},
{
"role": "user",
"content": """
Create a complete, efficient PyTorch implementation for CIFAR-10 image classification that:
1. Uses ResNet architecture
2. Can run in Google Colab GPU
3. Completes training within 1-2 hours
4. Includes all necessary code for:
- Data loading
- Model definition
- Training loop
- Evaluation
- Results visualization
Make the code as efficient as possible while maintaining good accuracy.
"""
}
]
# コードの生成
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=2048,
temperature=0.7,
top_p=0.95
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)結果はこちら
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
# Define BasicBlock class
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# Check if CUDA is available and set device accordingly
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# Data preprocessing
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Load CIFAR-10 dataset
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)
# Define classes
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# Define ResNet model
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
# Instantiate the ResNet model with ResidualBlock and number of blocks per layer
model = ResNet(BasicBlock, [2, 2, 2, 2]).to(device)
# Loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9, weight_decay=5e-4)
# Training parameters
num_epochs = 100
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# Training loop
def train(num_epochs, model, trainloader, criterion, optimizer, scheduler):
for epoch in range(num_epochs):
running_loss = 0.0
correct = 0
total = 0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
scheduler.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(trainloader)}, Accuracy: {100*correct/total}%')
# Evaluate the model
def evaluate(model, testloader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100*correct/total}%')
# Train and evaluate
train(num_epochs, model, trainloader, criterion, optimizer, scheduler)
evaluate(model, testloader)
# Visualize some predictions
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(testloader)
images, labels = next(dataiter)
# print images
imshow(torchvision.utils.make_grid(images))
# predict classes for images
outputs = model(images.to(device))
_, predicted = torch.max(outputs, 1)
# Print predictions
for i in range(4):
print('Predicted: ', ' '.join(f'{classes[predicted[j]]:5s}'
for j in range(i*4, i*4+4)))作成されたコードの結果がこちら
Using device: cuda:0
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
100%|██████████| 170M/170M [00:13<00:00, 13.0MB/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Epoch [1/100], Loss: 2.017900244811612, Accuracy: 29.416%
Epoch [2/100], Loss: 1.524604049789936, Accuracy: 43.864%
Epoch [3/100], Loss: 1.3510525727363498, Accuracy: 51.308%
Epoch [4/100], Loss: 1.212064925743186, Accuracy: 57.416%
Epoch [5/100], Loss: 1.1276802913002346, Accuracy: 60.638%
Epoch [6/100], Loss: 1.0702080279969803, Accuracy: 62.71%
Epoch [7/100], Loss: 1.0388420465047403, Accuracy: 64.254%
Epoch [8/100], Loss: 1.0064927332693963, Accuracy: 65.528%
Epoch [9/100], Loss: 0.9879102718342295, Accuracy: 65.856%
Epoch [10/100], Loss: 0.965128690918998, Accuracy: 66.968%
Epoch [11/100], Loss: 0.9500944154036929, Accuracy: 67.378%
Epoch [12/100], Loss: 0.9339566117204974, Accuracy: 68.122%
Epoch [13/100], Loss: 0.9334243627460411, Accuracy: 68.176%
Epoch [14/100], Loss: 0.9202621887102151, Accuracy: 68.738%
Epoch [15/100], Loss: 0.9149780412159307, Accuracy: 68.642%
Epoch [16/100], Loss: 0.9108395404980311, Accuracy: 68.92%
Epoch [17/100], Loss: 0.8958525558566803, Accuracy: 69.378%
Epoch [18/100], Loss: 0.9001198803524837, Accuracy: 69.156%
Epoch [19/100], Loss: 0.8901896867758173, Accuracy: 69.742%
Epoch [20/100], Loss: 0.8905173825562153, Accuracy: 69.878%
Epoch [21/100], Loss: 0.8844653989576623, Accuracy: 69.758%
Epoch [22/100], Loss: 0.8841260716585857, Accuracy: 69.822%
Epoch [23/100], Loss: 0.885251448053838, Accuracy: 69.868%
Epoch [24/100], Loss: 0.881751984662717, Accuracy: 69.926%
Epoch [25/100], Loss: 0.8753453788854887, Accuracy: 70.206%
Epoch [26/100], Loss: 0.8698140630865341, Accuracy: 70.324%
Epoch [27/100], Loss: 0.8769668530853812, Accuracy: 70.016%
Epoch [28/100], Loss: 0.8714507713799586, Accuracy: 70.304%
Epoch [29/100], Loss: 0.8749360920828017, Accuracy: 70.5%
Epoch [30/100], Loss: 0.8640674073677843, Accuracy: 70.69%
Epoch [31/100], Loss: 0.6120725371267485, Accuracy: 79.004%
Epoch [32/100], Loss: 0.5403349277613413, Accuracy: 81.502%
Epoch [33/100], Loss: 0.5119456429120219, Accuracy: 82.36%
Epoch [34/100], Loss: 0.4911070683270769, Accuracy: 83.126%
Epoch [35/100], Loss: 0.47593911862967875, Accuracy: 83.652%
Epoch [36/100], Loss: 0.4647358420407376, Accuracy: 84.068%
Epoch [37/100], Loss: 0.4503367023013742, Accuracy: 84.592%
Epoch [38/100], Loss: 0.44684560360658504, Accuracy: 84.66%
Epoch [39/100], Loss: 0.43907811035356864, Accuracy: 84.796%
Epoch [40/100], Loss: 0.4340236116476986, Accuracy: 85.036%
Epoch [41/100], Loss: 0.4350870517284974, Accuracy: 85.072%
Epoch [42/100], Loss: 0.4299119021124242, Accuracy: 85.136%
Epoch [43/100], Loss: 0.4191155178505746, Accuracy: 85.534%
Epoch [44/100], Loss: 0.4225593926885244, Accuracy: 85.366%
Epoch [45/100], Loss: 0.4216346669932613, Accuracy: 85.534%
Epoch [46/100], Loss: 0.41891488695845885, Accuracy: 85.608%
Epoch [47/100], Loss: 0.41789528578900925, Accuracy: 85.43%
Epoch [48/100], Loss: 0.4097350081690894, Accuracy: 85.746%
Epoch [49/100], Loss: 0.4129747009414541, Accuracy: 85.664%
Epoch [50/100], Loss: 0.4133060688100508, Accuracy: 85.714%
Epoch [51/100], Loss: 0.40188368613762626, Accuracy: 86.118%
Epoch [52/100], Loss: 0.4046934463102799, Accuracy: 85.926%
Epoch [53/100], Loss: 0.4038145473546079, Accuracy: 86.232%
Epoch [54/100], Loss: 0.3991208066758902, Accuracy: 86.144%
Epoch [55/100], Loss: 0.39824950919889124, Accuracy: 86.118%
Epoch [56/100], Loss: 0.3946946076191295, Accuracy: 86.29%
Epoch [57/100], Loss: 0.39266179457230643, Accuracy: 86.374%
Epoch [58/100], Loss: 0.3932194915955024, Accuracy: 86.326%
Epoch [59/100], Loss: 0.3915362291018981, Accuracy: 86.498%
Epoch [60/100], Loss: 0.39024223892203985, Accuracy: 86.508%
Epoch [61/100], Loss: 0.29354873759781613, Accuracy: 90.038%
Epoch [62/100], Loss: 0.25097356100216545, Accuracy: 91.468%
Epoch [63/100], Loss: 0.23885520625754694, Accuracy: 91.68%
Epoch [64/100], Loss: 0.22805594758647482, Accuracy: 92.084%
Epoch [65/100], Loss: 0.21918420005789804, Accuracy: 92.566%
Epoch [66/100], Loss: 0.21396534178701357, Accuracy: 92.646%
Epoch [67/100], Loss: 0.21101452361153977, Accuracy: 92.626%
Epoch [68/100], Loss: 0.2006454277459694, Accuracy: 93.108%
Epoch [69/100], Loss: 0.19757415420468658, Accuracy: 93.162%
Epoch [70/100], Loss: 0.19174628786723633, Accuracy: 93.4%
Epoch [71/100], Loss: 0.18734423235973433, Accuracy: 93.594%
Epoch [72/100], Loss: 0.18335523926521963, Accuracy: 93.726%
Epoch [73/100], Loss: 0.18100209219757554, Accuracy: 93.87%
Epoch [74/100], Loss: 0.17190769008930076, Accuracy: 94.05%
Epoch [75/100], Loss: 0.1728737753770693, Accuracy: 94.16%
Epoch [76/100], Loss: 0.16861459704549492, Accuracy: 94.276%
Epoch [77/100], Loss: 0.16395103553181414, Accuracy: 94.38%
Epoch [78/100], Loss: 0.157751568895586, Accuracy: 94.648%
Epoch [79/100], Loss: 0.16118268783220932, Accuracy: 94.392%
Epoch [80/100], Loss: 0.15414197781287572, Accuracy: 94.692%
Epoch [81/100], Loss: 0.15558167078944346, Accuracy: 94.616%
Epoch [82/100], Loss: 0.15197004643661896, Accuracy: 94.732%
Epoch [83/100], Loss: 0.1475323293062732, Accuracy: 94.916%
Epoch [84/100], Loss: 0.14452448352704497, Accuracy: 95.002%
Epoch [85/100], Loss: 0.14415063136888434, Accuracy: 95.078%
Epoch [86/100], Loss: 0.1391058854253777, Accuracy: 95.156%
Epoch [87/100], Loss: 0.1404050268266169, Accuracy: 95.15%
Epoch [88/100], Loss: 0.1356296993391898, Accuracy: 95.356%
Epoch [89/100], Loss: 0.13188377735169265, Accuracy: 95.478%
Epoch [90/100], Loss: 0.13321534729064882, Accuracy: 95.376%
Epoch [91/100], Loss: 0.11846363863281315, Accuracy: 95.86%
Epoch [92/100], Loss: 0.11710257604098914, Accuracy: 96.08%
Epoch [93/100], Loss: 0.11459200452570148, Accuracy: 95.922%
Epoch [94/100], Loss: 0.11062612892140436, Accuracy: 96.196%
Epoch [95/100], Loss: 0.11010768444722761, Accuracy: 96.168%
Epoch [96/100], Loss: 0.10639238096606891, Accuracy: 96.438%
Epoch [97/100], Loss: 0.10709195781518202, Accuracy: 96.408%
Epoch [98/100], Loss: 0.10563893514135114, Accuracy: 96.428%
Epoch [99/100], Loss: 0.10364305780357336, Accuracy: 96.532%
Epoch [100/100], Loss: 0.10464808976282473, Accuracy: 96.424%
Accuracy of the network on the 10000 test images: 86.56%
Predicted: cat ship ship plane
Predicted: frog frog car frog
Predicted: cat car plane truck
Predicted: dog horse truck ship 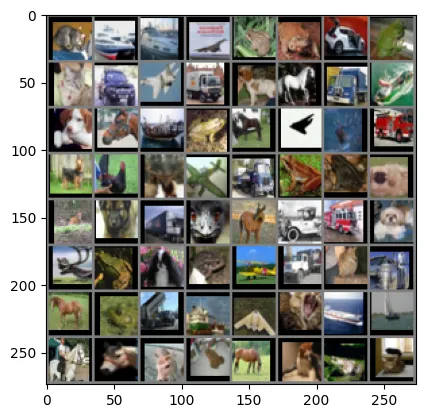
学習結果としては、次の結果です
- トレーニングセットの精度:96.42%
- テストセットの精度:86.56%
- 約10%のオーバーフィッティング
他のと比較してみると、
- AlexNet:CIFAR-10に対して約89%の精度
- VGGNet:CIFAR-10で94%を超える精度
- ResNet:CIFAR-10で95%を超える精度
なので、既存のモデルに比べると精度は若干落ちてはいるものの、プロンプトで指示しただけで86%の精度を出せるのは、すごいなと感じます。ここからパラメーターなどの調整を行えば90%越えも可能だと思います。
なお、ClaudeのAI Artifactsを無料で使う方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事では、Qwen2.5-Coderについて紹介しつつ、google colaboratoryでの実装方法、Demoの使い方、Artifacts機能の使い方それぞれを解説しました。
Qwen2.5-Coder 32Bモデルはgoogle colaboratoryでは実行完了するまでに30分以上かかってしまい、手軽に使えるとは言い難い部分もありますが、高度なコーディング能力を備えたモデルです。
DemoやArtifacts機能だけでも十分にこちらの作りたいものを実現してくれるため、まずはDemoやArtifacts機能を試してみて、もっと複雑なものを作ってみたい!という場合にモデルを使って開発を進めるのも一つかなと思います。
ぜひ本記事をQwen2.5-Coderを活用してみてください!
最後に
いかがだったでしょうか?
コード生成AIを活用すると、複雑なコード修正や新規アルゴリズムの構築が自動化され、プロジェクトのスピードが格段に向上。さらに、生成AIの導入が社内の人的リソースを最適化し、技術者が付加価値の高い業務へシフト可能になります。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

