
【PaliGemma 2 mix】複数タスクをハイレベルで実行できるVLM?概要や使い方を徹底解説

- マルチモーダルVLM(Vision-Language Model)
- Gemmaライセンスのもとでオープンソースで公開
- OCRや物体検出、画像セグメンテーションなど、多様なタスクに対応
2025年2月20日、Google社がビジョンと言語の統合モデル(Vision-Language Model, VLM)「PaliGemma 2 mix」を公開しました!
「PaliGemma 2 mix」は、単一のモデルで複数のタスクを高い水準で実行できるのが特徴で、画像キャプション(短文・長文)、OCR(光学文字認識)、画像質問応答(VQA)、物体検出、画像セグメンテーションなどの様々なタスクに対応しているようです。
この記事では「PaliGemma 2 mix」の概要や使い方までご説明します。本記事を熟読することで、「PaliGemma 2 mix」の凄さをご理解いただけると思います。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
PaliGemma 2 mixの概要
「PaliGemma 2 mix」は、2024年12月に公開された「PaliGemma 2」をベースとしており、その学習済みモデルを様々なタスクのデータでファインチューニングしてリリースされました。
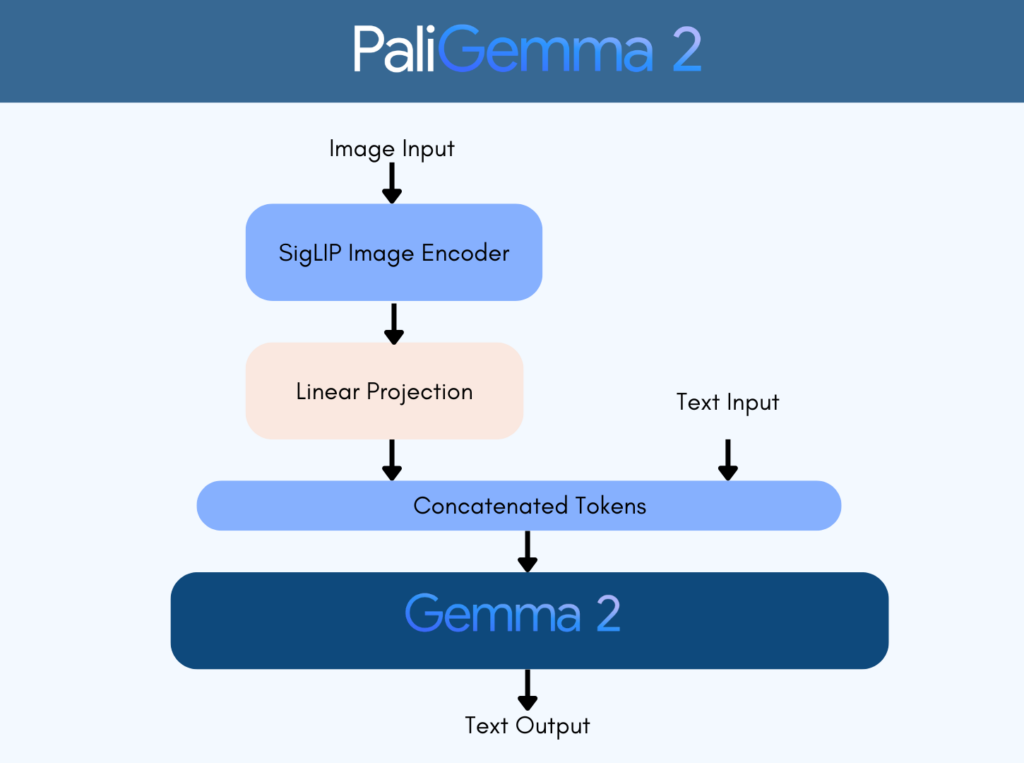
画像エンコーダにはVision Transformer(SigLIPモデル)、テキストデコーダに大規模言語モデルGemma 2を組み合わせた構成になっており、これによって、追加の学習なしで汎用的な画像と言語の処理能力を発揮する実用的なモデルとなっています。
さらに、マルチモーダル入力にも対応しており、画像やテキストの入力から、画像説明文、質問への回答、検出バウンディングボックス座標やセグメンテーションのコードなどのテキストを出力する仕組みになっています。
実例を見てみましょう!
例えば、画像からの物体検出。

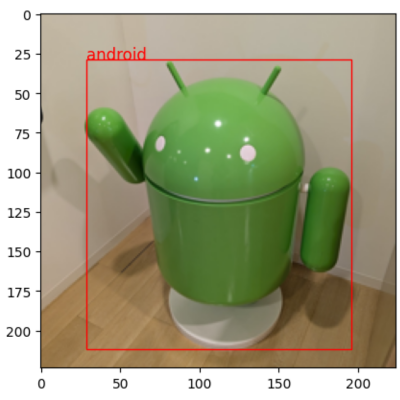
的確にアンドロイドを検出していますね。他の例も見てみましょう。次は複数のオブジェクト検出。


こちらもキレイに識別されていることが分かります。
他にも「キャプション付け」や「OCR」などの実例が紹介されているので、気になる方は以下のリンク先を参考にしてみてください。
参考:https://developers.googleblog.com/ja/introducing-paligemma-2-mix/
さらに「PaliGemma 2 mix」は、「3B(30億規模)」、「10B(100億規模)」、「 28B(280億規模)」と3種類のモデルサイズが提供され、画像入力解像度も「224×224px」と「448×448px(一部最大896pxまで)」とバリエーションが豊富です。
用途や要件に応じてモデルサイズ・解像度を選べるため、開発者にとって扱いやすい柔軟なモデルになっていますね。
PaliGemma 2 mixの料金プラン
「PaliGemma 2 mix」はオープンソースで提供されており、モデルそのものの利用は無料です。
ただし、実行環境にかかるコストには注意しましょう。
モデルサイズが大きいため、ローカルで扱うには高性能なGPUが必要であり、用意できない場合はクラウドGPUサービスを使うことになります。その際のインフラ費用はユーザー負担です。
例えば、Vertex AIでデプロイすればGoogle Cloudの標準料金(GPUマシン稼働費用)が発生しますし、Hugging Faceのデモも無料枠を超える利用は自前のリソースでホストする必要があります。ただし、開発・評価目的であればKaggleやGoogleColabの無料枠で動かすことも可能です。
PaliGemma 2 mixのライセンス
PaliGemma 2 mixは「Gemmaライセンス」で提供されています。このライセンスは、Apache 2.0のようなオープンライセンスに類似していて、モデルの再配布や改変、ファインチューニングなど幅広い利用用途が認められています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
ただし、「倫理的・法的に問題のある用途」は契約上許されないという点に注意が必要です。Google社も、利用者がこうした規約に同意しない限りモデルをダウンロードできないようにしています。
商用利用する場合はもちろん、研究用途であっても、公開API等で他者に流用する場合には、これら制限事項を守るように注意しましょう。


PaliGemma 2 mixの使い方
PaliGemma 2 mixを動かすのに必要な動作環境は以下の通りです。
■Pythonのバージョン
・Python 3.8以上
・Windowsの場合:Python 3.6+、GPUを使うならNVIDIAのCUDAドライバ(CUDA 11以降)が必要
■RAMの使用量
使用するモデルサイズによるが、8〜24GB程度のGPUメモリ推奨
使い方は以下の3種類があります。
1.ローカル環境での利用
ローカル環境では、お好みのフレームワークを選んで「PaliGemma 2 Mixモデル」を導入することができます。
- PyTorch + Transformersでの利用
ライブラリのインストール:PyTorchとHugging Face Transformers、また画像処理に必要なPillowなどのライブラリをインストールします。インターネット接続がある環境で、以下コードを実行します。
pip install torch torchvision transformersインストールが完了したら、モデルへのアクセス許可を取ります。
「PaliGemma 2 Mix」はGoogle提供のモデルで使用許諾への同意が必要です。Hugging Faceにログインし、モデルページで利用規約に同意してアクセス権を取得してください。許諾に同意した後、huggingface-cli loginコマンドでCLIから認証しておくと便利です。
上記まで完了したら、続いてモデルのダウンロードと読み込みフェーズです。Transformersライブラリを使ってモデルとプロセッサをダウンロードします。例えば、3Bモデルを使う場合、以下のようなコードになります。
from transformers import PaliGemmaForConditionalGeneration, PaliGemmaProcessor
model_id = "google/paligemma2-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype="auto", device_map="auto").eval()
processor = PaliGemmaProcessor.from_pretrained(model_id)あとは、推論実行です。例えば、画像の内容説明(caption)を英語で生成するには、以下のように指示しましょう。
Promptはこちら
describe en.
和訳:
英語で説明して。Pythonコードはこちら
from transformers.image_utils import load_image
image = load_image("image.jpg") # 任意の画像ファイルパス
prompt = "describe en" # 入力プロンプト
inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
with torch.inference_mode():
outputs = model.generate(**inputs, max_new_tokens=100)
result_text = processor.decode(outputs[0], skip_special_tokens=True)<br>print(result_text)上記のコードで、指定した画像に対する説明文が”result_text”に出力されます。プロンプトを変えることでOCRや質問応答など様々なタスクに対応可能です。
TensorFlow/Kerasでの利用
まずライブラリをインストールします。 TensorFlow 2系(>=2.12)かつKeras v3以降が必要です。Kerasチームが提供する「KerasHub」を使うとモデルを簡単に利用できます。以下のコードで最新KerasとKerasHubをインストールします。
pip install keras>=3 keras-hubもし、TensorFlow自体もインストールされていなければ、以下のコードも実行しましょう。
pip install tensorflow続いて、モデルの読み込みです。Kerasから「PaliGemma 2 Mixモデル」を利用するには、KerasHub経由でモデルを取得します。
例えば、3B・解像度224のチェックポイントの場合、「paligemma-3b-224-mix-keras」というプリセット名が用意されています。以下のコードをベースにして試してみてください。
実際のプリセット名やAPIは公式ドキュメントを参照してください。
import keras_nlp
model = keras_nlp.models.PaliGemma.from_preset("paligemma-3b-224-mix-keras")Kerasでモデルがロードできたらいよいよ推論実行です。入力テンソルを用意して推論を行いましょう。
TensorFlowの場合でも基本的な手順はPyTorch時と同様で、画像とテキストの入力を与えて出力を得ます。
例えば、前処理として画像を読み込み、テキストプロンプトとともにモデルに入力し、生成されたシーケンスをデコードするといった流れになります。具体的な使用方法はKerasの公式チュートリアルにも例があるので参考にしてみてください。
クラウド環境での利用
ローカルに十分なリソースがない場合は、クラウド上で「PaliGemma 2 Mix」を試すことができます。
基本的な流れはローカル環境の場合と同じですが、任意のクラウドプロバイダでGPUマシンを用意します。AWS、GCP、Azureなどどのサービスでも構いません。
今回は、手軽な方法としてGoogle Colabでの導入手順をご紹介します。
Colabノートブックでまず、GPUランタイムを有効にします。(メニューの「ランタイム」→「ランタイムのタイプを変更」からGPUを選択)
その後、以下のコードでGPUが認識されているか確認しながら、必要なライブラリをインストールします。
!nvidia-smi # GPUの状態を表示
!pip install transformers accelerate datasets peft bitsandbytes続いて、Hugging Face Hubから「PaliGemma 2 mixモデル」をロードします。
まず、モデルへのアクセス権を取得する必要があります。
ブラウザでモデルページにアクセスし、ライセンス契約(Usage Policy)に「Accept(同意)」してください。
その後、ブラウザでモデルページを開いて、「Gated model You have been granted access to this model」 と表示されていれば、モデルをダウンロードする権限が付与されている状態になっています。
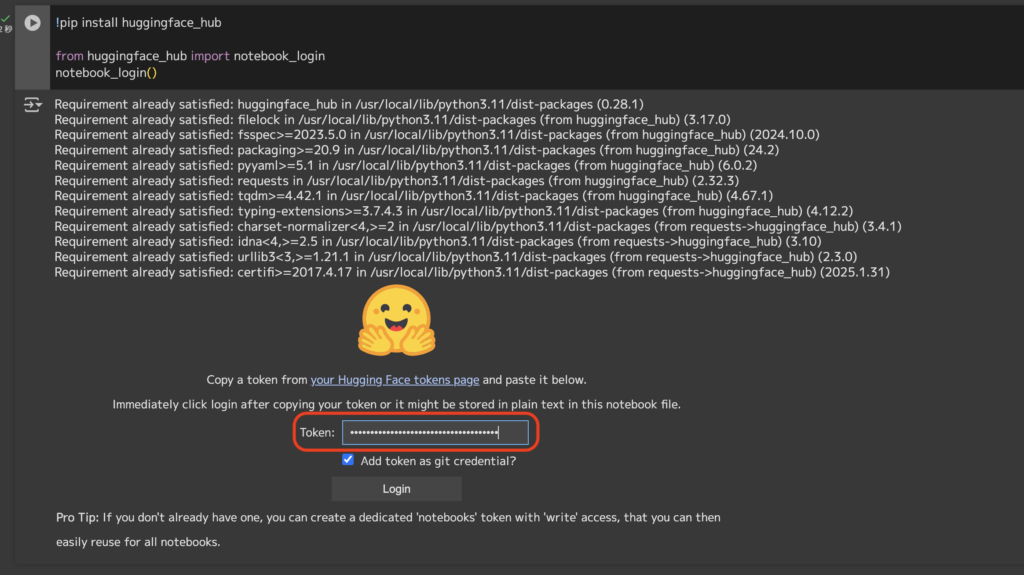
続いて、GoogleColabでの認証(notebook_login)を行います。
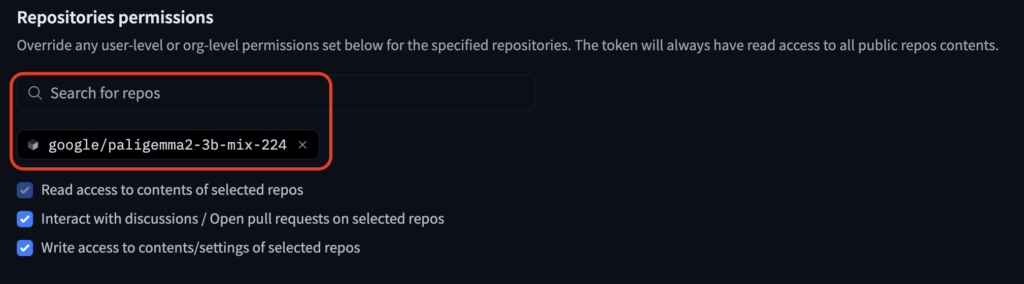
まず以下画像の通り、今回使用したいリポジトリのアクセス許可にチェックを入れてAPIトークンを取得しましょう。
そして、GoogleColab上でHugging Faceにログインします。以下のコードを実行し、表示される入力欄に、上記で取得したトークンを入力してください。
その後、以下のコードを実行してモデルをロードしてください。
from transformers import PaliGemmaProcessor, PaliGemmaForConditionalGeneration
import torch
# モデルの指定: 3B または 10B の mix モデルを選択
model_id = "google/paligemma2-3b-mix-224" # 10Bモデルを使う場合: "google/paligemma2-10b-mix-224"
# プロセッサ(画像前処理+テキストトークナイザ)のロード
processor = PaliGemmaProcessor.from_pretrained(model_id)
# モデル本体のロード
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id, torch_dtype=torch.bfloat16, device_map="auto"
)
model.eval() # 推論モードに設定ここまで完了すれば、いよいよ推論の実行ができます!
今回は、以下のサンプル画像(青い車の画像)を用いて、2つのプロンプトを試してみます。

Prompt①はこちら
describe en.
和訳:
英語で説明して。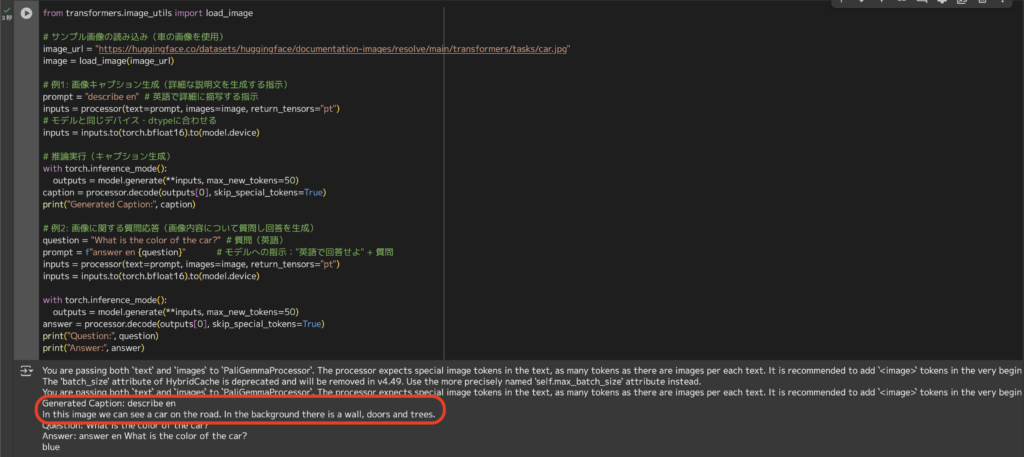
しっかりと画像の細部まで特徴を捉えています!
Prompt②はこちら
What is the color of the car?
和訳:
車の色は?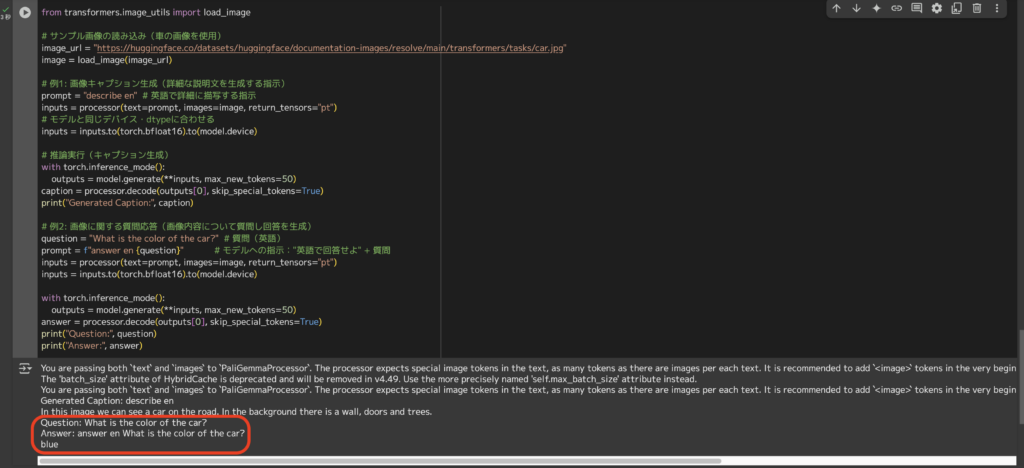
正確に「Blue」とアンサーしてくれていますね!
WebUIでの利用
面倒な環境構築なしで「PaliGemma 2 Mix」を試したい場合は、Hugging Faceのデモページを利用するのが最も簡単です。
Googleが提供する公式デモでは、ブラウザ上のインターフェースから画像とテキストプロンプトを与えてモデルの出力を確認することができます。
例えば、画像をアップロードし「describe the image」などのプロンプトを入力するだけで、画像キャプションやOCR結果が得られます。
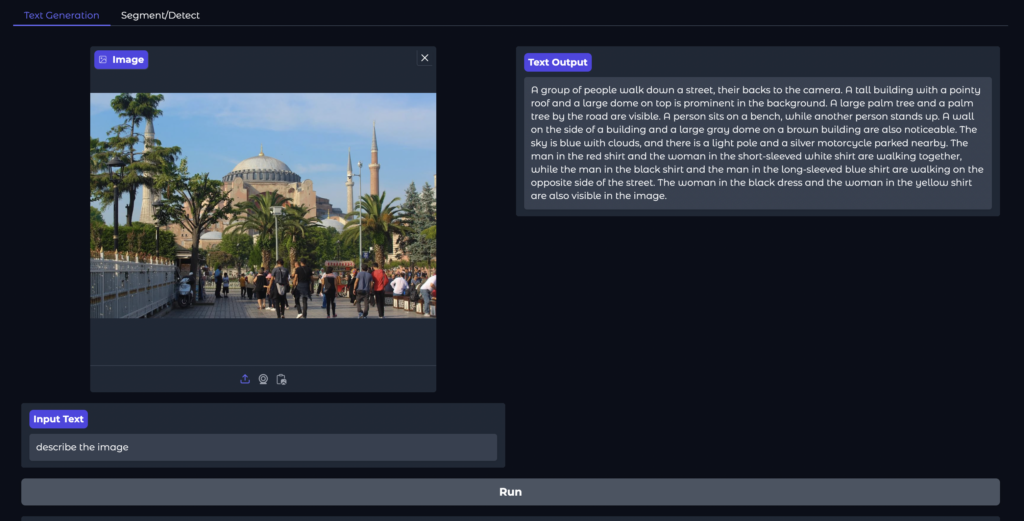
所要時間は20秒ほど。画像の特徴を長文テキストで出力してくれました。
以上、3つの利用方法のご紹介でした!
個人的に、手軽に試したい方は「WebUI」、ファインチューニングも試したい方は「GoogleColab」での利用がオススメです。
PaliGemma 2 mixの活用事例
「PaliGemma 2 mix」の活用事例を厳選して3つご紹介します!
レシートスキャン&カテゴライズ&家計簿作成
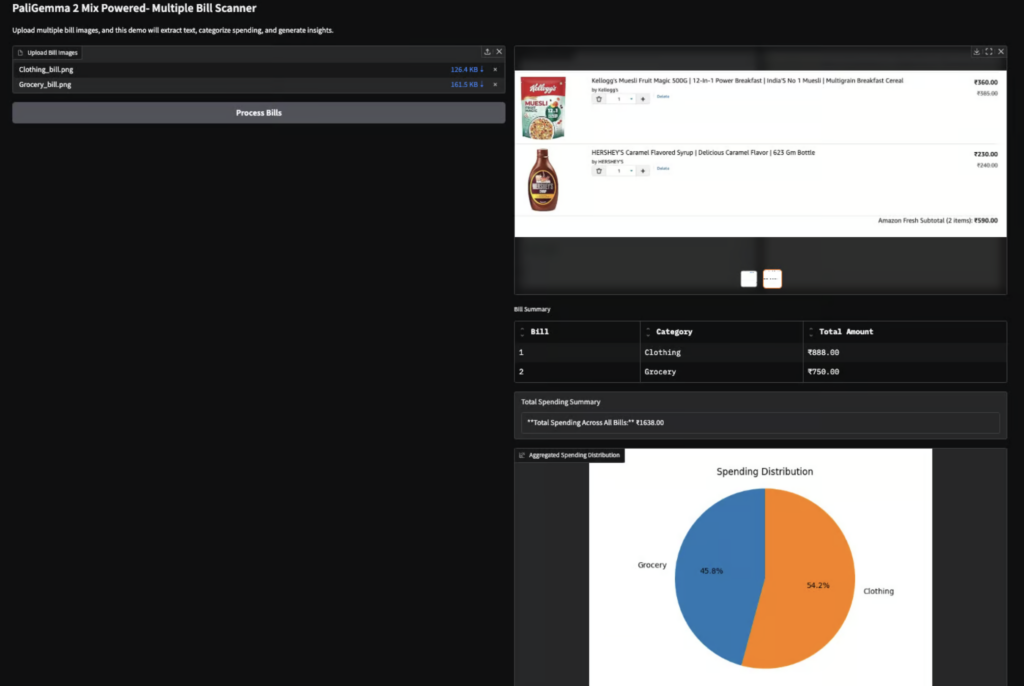
上記では、レシート画像から商品名や価格をOCRで抽出し、自動でカテゴリ分けして家計簿データを生成する実験がなされています。「PaliGemma 2 mix」のテキスト読み取り能力と画像キャプション生成能力を組み合わせることで、画像内のテキスト情報を正確に抜き出し家計管理に活用する実用的な例ですね!経理タスクが楽になりそうです。
画像認識
上記ポストでは、ユーザーが画像をアップロードし、「この猫は何をしているか?」と質問を投げると、モデルがテキストで回答を出力しています。投稿内容によると、「DeepSeek R1でも答えられない質問に答えた」と述べられており、「PaliGemma 2 mix」の強力な画像理解能力が示唆されていますね。
画像認識AIをOCR業務に活用したい方は、以下の記事もご覧ください。

画像セグメンテーション
上記ポストでは、2パターンのテストがなされています。
1つ目は、「When is this ticket dated and how much did it cost?(このチケットの日付と値段は?)」という画像付き質問に対して、「26-05-2023 17:00(2023年5月26日17時)」と正確にアンサーできています。
2つ目は、「segment cat behind(後ろの猫をセグメントして)」というプロンプトに対して、2匹いるうちの後ろの猫が赤色にセグメンテーションされています。(上記ポストの33秒〜)
まとめ
最後に「PaliGemma 2 mix」の特徴をおさらいします。
- 単一のモデルで複数のタスクを高い水準で実行できる
- 追加学習なしで汎用的な画像と言語の処理能力を持つ
- モデルそのものの利用は無料
- Gemmaライセンスでリリースされており、商用利用など可能
- ローカル、クラウド、WebUIの3つの利用方法がある
ユースケースとして、個人やビジネスの財務管理やカスタマーサポート、医療分野での画像解析など様々なシーンで応用できそうですね!
最後に
いかがだったでしょうか?
PaliGemma 2 mixなどのVLMを活用することで、画像解析やOCRの精度向上、業務の自動化が可能になり、データ入力や顧客対応の効率が大幅に改善されます。生成AIの導入で、コスト削減や生産性向上を実現しませんか?
「生成AIで新しいプロダクトを作りたい」「もっと本格的に生成AIを業務に組み込みたい」とお考えの方は、ぜひ株式会社WEELにご相談ください。
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
アイデア段階でも構いません。まずは無料相談でお気軽にご相談ください。
➡︎生成AIを活用したプロダクト開発・業務効率化について相談する

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

