
Qwen Imageで「日本語は本当に描けるのか?」を検証してみた

- 非アルファベット系文字の画像への描画が高精度
- 意味と見た目の整合性を両立
- 多様な画像生成・編集タスクに対応できる汎用性
2025年8月5日、Alibabaから新たな画像生成AIが登場!
今回リリースされた「Qwen Image」は特に文字描画に長けており、ただ単純に画像に文字が入っているレベルではなく、「人がデザインしたかのように整って見えるテキスト・構成・スタイル」の画像を生成可能。
本記事では、Qwen Imageの概要から使い方、実際に使ってみた結果を余すことなくお伝えします。最後までお読みいただくことでQwen Imageの理解が深まります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Qwen Imageの概要
Alibabaから新たに発表されたQwen Imageは従来の画像生成AIと比べると人がデザインしたかのように整っているテキストを画像に表示させることが可能です。

特にQwen Imageが圧倒的に優れているのは中国語などの非アルファベット系文字の忠実な描画です。また、多言語に対応しているので、上記画像のように、英語や中国語などにも対応。
Qwen Imageの公式ページやテクニカルレポートに日本語対応とは明記されていませんが、非アルファベット系文字に強いことを考えると、日本語の描画も問題なくできそうです。
Qwen Imageの開発背景
Qwen Imageが開発された背景を知ることが、Qwen Imageの特徴を押さえることにも繋がります。Qwen Imageが解決したかった問題は次の2つ。
- 複雑なテキストを正しくレンダリングできない問題
- 画像編集において意味と見た目の整合性が取れない問題
上記2つの問題を解決するためにQwen Imageが開発されているので、Qwen Imageは上記2つをクリアしているAIと解釈できます。※1
複雑なテキストを正しくレンダリングできない
まず複雑なテキストを正しくレンダリングできない問題です。
従来の画像生成AIでは多い文章を描画することや非アルファベット系文字の描画、レイアウトや装飾を伴うスライド・ポスターの生成を苦手としていました。
Qwen Imageでは多段階カリキュラム学習・合成データ生成パイプライン・Multimodal Scalable RoPE・VAEのテキスト最適化という4つの技術を用いて解決しています。
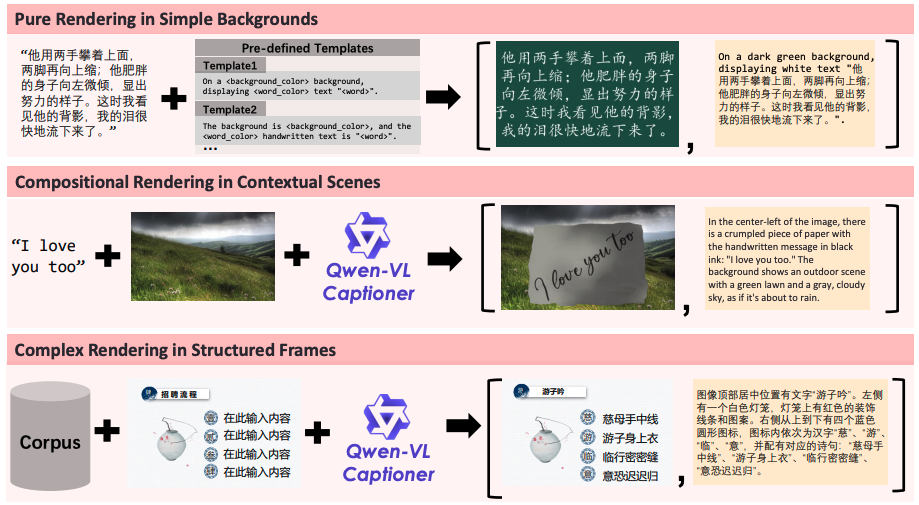
上記画像は、Qwen Imageが複雑なテキストレンダリング能力を向上させるために用いた3種類の合成データ生成手法を示しています。
- Pure Rendering:無地の背景に段落テキストを表示。構文やフォント、字形の学習に活用。
- Compositional Rendering:自然画像に手書き風テキストを合成。現実的な文脈表現に対応。
- Complex Rendering:スライドやUIなど構造化フレーム内にテキストを配置。高度なレイアウト理解を促進。
画像編集において意味と見た目の整合性が取れない問題
次に画像編集において意味と見た目の整合性が取れない問題です。
従来の画像生成AIでは、生成後に人の顔つきが変わってしまう・背景の一部だけを変えたつもりが全体が変わってしまう、など意味と見た目の整合性が取れない問題がありました。
そこでQwen ImageではMultimodal Diffusion Transformerという技術を使って、細かい編集意図に忠実な画像生成を可能としています。
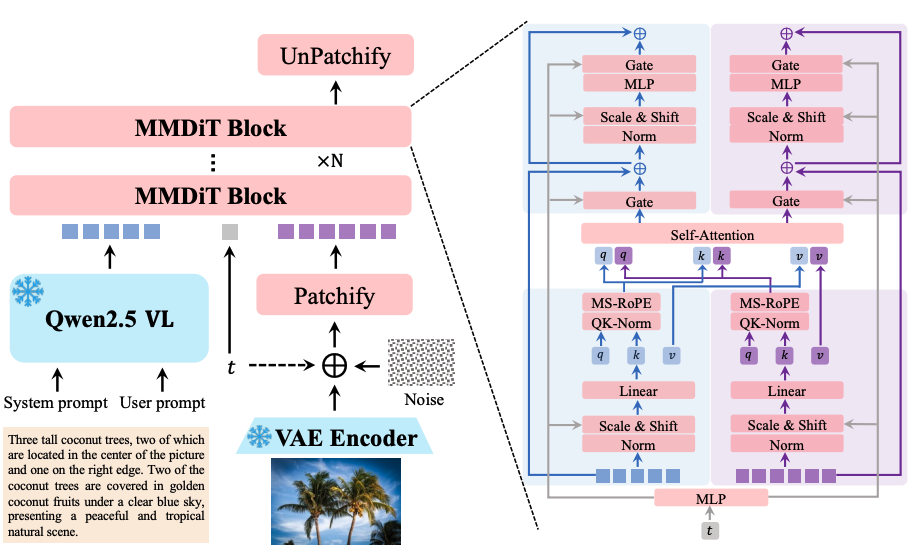
上記画像はQwen Imageがテキストの意味と画像の見た目の整合性を両立させる仕組みを示しています。
上記画像のように、左下のプロンプトは、まずQwen2.5 VLにより意味情報に変換。入力画像は、VAEエンコーダにより視覚的特徴に変換され、それらの情報が、中央のMMDiT(Multimodal Diffusion Transformer)に集約され、画像生成や編集がされます。
このような流れによりQwen Imageは「意味的に正しく、かつ自然な見た目」な画像を生成できます。
なお、最速かつリアルな画像生成を実現するFLUX1.1 [Pro]について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen Imageのライセンス
Qwen ImageのライセンスはApache 2.0です。そのため、商用利用は可能、再配布や改変なども可能ですが、著作権表示とライセンス表記の保持義務はあります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
\画像生成AIを利用する際はライセンスを確認しましょう/

Qwen Imageの使い方
一番手軽にQwen Imageを使うにはデモサイトがおすすめ。
Examplesに記載されていた「A capybara〜」というものを選択して生成した画像がこちら。

確かに正確に文字を描画してくれていますが、アルファベット系文字だからかもしれません。
もう一枚中国語で生成してもらおうと思ったら、アップグレードしろとアラートが出ました。
デモ版ではあるものの、利用に制限があるようです。
google colaboratoryでの実装
デモサイトが制限かかってしまうので、google colaboratoryで実装してみたいと思いますが、実際に実装するとA100でもGPUメモリエラーが発生してしまいます。
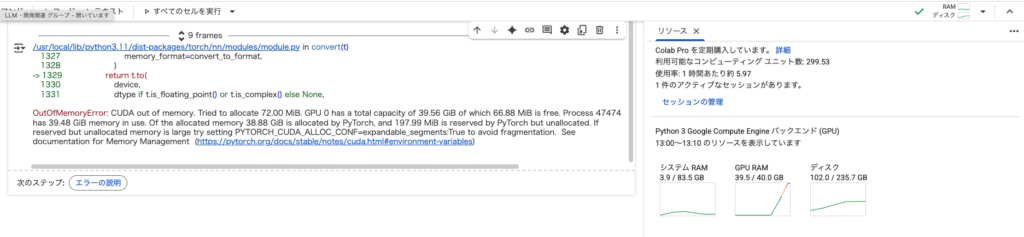
なのでgoogle colaboratoryではなくVast.aiでGPUをレンタルして実装します。今回は2x H200をレンタルしました。
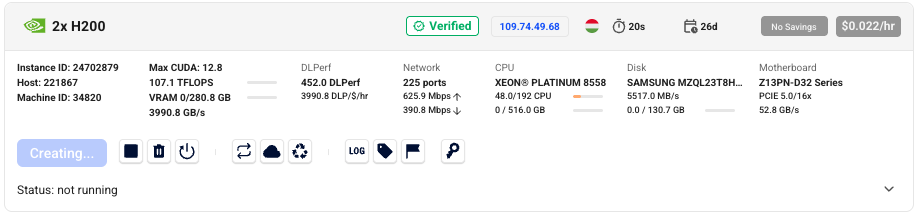
準備が終わると「Creating」と書かれている部分が「Open」になるので、そこからJupyterを起動することができます。
Githubのクローンはこちら
!pip install git+https://github.com/huggingface/diffusers transformers torch必要ライブラリのインストールからモデルの読み込みはこちら
import subprocess
import sys
def install_packages():
packages = [
"git+https://github.com/huggingface/diffusers",
"transformers>=4.51.3",
"torch",
"torchvision"
]
for package in packages:
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
install_packages()
from diffusers import DiffusionPipeline
import torch
from IPython.display import display, Image as IPImage
device = "cuda" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
print(f"Device: {device}")
print(f"GPU: {torch.cuda.get_device_name() if torch.cuda.is_available() else 'None'}")
print("Loading Qwen-Image model...")
pipe = DiffusionPipeline.from_pretrained("Qwen/Qwen-Image", torch_dtype=torch_dtype)
pipe = pipe.to(device)
print("Model loaded!")画像生成はこちら
def generate(prompt, save_name="output.png"):
width, height = 1664, 928 # 16:9
enhanced_prompt = prompt + " Ultra HD, 4K, cinematic composition."
image = pipe(
prompt=enhanced_prompt,
width=width,
height=height,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device=device).manual_seed(42)
).images[0]
image.save(save_name)
display(IPImage(save_name))
print(f"Saved: {save_name}")
return image
generate("A coffee shop with a sign reading 'AI Cafe'")
print("Ready! Use: generate('your prompt here')")実際に生成された画像はこちら。


英語の出力は問題なく行えています。画像自体のクオリティも高いと思います。


日本語の出力が適切にできるのかを検証
Qwen Imageの特徴として、「非アルファベット系文字の画像への描画が高精度」というものがあります。
中国語は適切に出力されているようですが、日本語の出力に関しては言及がありませんでした。そこで、日本語の出力・描画が適切に行えるのかを検証したいと思います。
検証する際に使用するコードは上述したコードでプロンプトだけ以下に変更します。
generate(“A magazine cover with headline ‘人工知能の未来’ in modern font design”)
generate(“A Japanese restaurant menu board with text ‘本日のおすすめ'”)
実際に生成された画像がこちら。


前述の英語の描画は非常に適切にされていましたが、日本語の描画はもう一歩という印象です。
ただデザイン性などは割とクオリティ高いと思います。
なお、GPUメモリを消費せず1秒で深度推定できるオープンソース「Depth Pro」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではQwen Imageの概要から使い方、実際に使ってみた結果をお伝えしました。非アルファベット系文字の画像への描画が高精度ではあるものの、日本語の描画はもう一息って感じでした。
公式ページにも日本語についての言及はないので、将来的に日本語にも適切に対応されるようアップデート待ちですね。※2
ぜひ本記事を参考にQwen Imageを使ってみてください!
最後に
いかがだったでしょうか?
Qwen Imageの業務活用や導入検討について、無料でご相談いただけます。お気軽にお問い合わせください。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

