
【古本を電子書籍に】DN_SuperBook_PDF_Converterとは?インストールや使い方も紹介!

- DN_SuperBook_PDF_Converterは、自炊PDFを電子書籍レベルまで読みやすくできるツール
- DN_SuperBook_PDF_Converterは、ローカル環境で無料で利用可能
- 変換後のPDFは実際の書籍とページ番号が一致し、PDFビューアの検索機能で探せる
自身で書籍を裁断してスキャン(いわゆる自炊)したところ、「インクにじみや紙の汚れがひどくて、PDFがまともに読めない」といった経験をしたことはありませんか?
そんな時に便利なのが、AI PDF高品質化ツール「DN_SuperBook_PDF_Converter」です。
今回の記事では、DN_SuperBook_PDF_Converterの特徴や基本的な使い方について解説します。最後まで読めば、あなたの手元の自炊PDFを読みやすく整え、探したい情報にすぐアクセスできる状態になります。ぜひご覧ください!
\生成AIを活用して業務プロセスを自動化/
DN_SuperBook_PDF_Converterの概要
DN_SuperBook_PDF_Converterは、登大遊氏がGitHubで公開している、自炊(裁断・スキャン)で作成した書籍PDFを電子書籍並みの品質に整えるAI PDF高品質化ツールです。
電子化されていない専門書を大量に自炊して読む中で発生する、以下の課題を一括で解決する目的で登場しました。
- 紙の書籍のスキャン結果は画質が低い
- 微妙な傾きがあること、かつそれがページごとに異なる
- 各ページのスキャンオフセットがずれる
- 余白自動除去によって各ページの余白部分をトリミングするとガタガタになる
- 書籍のページ番号とPDFビューアにおけるページ番号とがズレる
- 見開き表示する際に、左側ページと右側ページとが自動判別されない
- 縦書きの書籍は見開きの左右表示が逆になるケースがある
- 日本語OCRにおいて誤字・脱字が多く生じるほか、PDFをOCRソフトにかけるとメタデータが全部消える
DN_SuperBook_PDF_Converterは、従来の手作業編集や単純な補正と違い、ページ全体の解析に基づく統一的な補正に加え、AIによる鮮明化やOCRまで組み合わせて読みやすさと検索性を底上げしているのが特徴です。
ツール開発の背景には、絶版などでデジタル化されない日本語書籍こそが「隠された資産」であり、個人が快適に読めて全文検索やAI活用までできる状態に整えることが人材育成や知の継承につながる、という登大遊氏の考えがあります。
なお、PDFを音声化できるOpen NotebookLMについて知りたい方は、以下の記事もご覧ください。

DN_SuperBook_PDF_Converterの仕組み
DN_SuperBook_PDF_Converterの仕組みは、自炊PDFの「読みにくさの原因」を工程ごとに分解し、AI・OCR・ヒューリスティック処理を組み合わせて段階的に解消していく流れです。
この記事では特に、高画質化・鮮明化、ページ位置(オフセット)補正、書籍ページ番号とPDFページ番号の一致という3つの中核処理に分けて説明します。
高画質化・鮮明化の仕組み
DN_SuperBook_PDF_Converterは、自炊PDFを「完全なベクトルPDFへ逆変換する」のではなく、現実的に効果が出る方法としてビットマップ画像をAIで鮮明化する方針を取っています。
RealEsrganとC#実装の自作アルゴリズムにより、紙の汚れ・裏写り・インクにじみ・JPEGモアレを抑えつつ高解像度化し、拡大しても文字が崩れにくい状態に整える仕組みです。
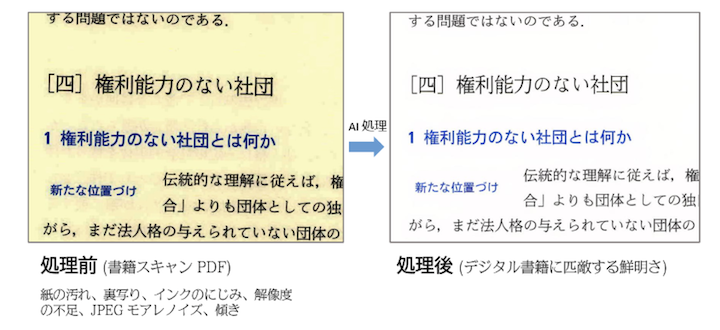

上記は、DN_SuperBook_PDF_Converterの使用前と使用後の画像を比較したものですが、違いは一目瞭然です。
オフセットのズレを補正する仕組み
DN_SuperBook_PDF_Converterは、全ページにあるはずのページ番号領域を基準点としてオフセットずれを補正できます。
ページ番号は装飾や周辺文字の影響で誤認識しやすいため、奇数・偶数ページをまとめて分析し、「同じ位置に現れる数字が物理ページ枚数に応じて増えていく」という規則性からページ番号部分を推定して利用する仕組みです。

余白トリミングもページ単位ではなく本全体で最適化し、奇数・偶数ページ全体から妥当な余白領域を算出して統一トリミング、左右ページでズレて見えないようページ番号の縦位置もできるだけ揃えられます。
書籍のページ番号とPDFのページ番号を一致させる仕組み
DN_SuperBook_PDF_Converterは、補正処理で自動検出した書籍のページ番号を使い、PDFビューア上のページ番号と一致するように内部データを埋め込んでいます。
「227」と検索したら227ページにジャンプするなど、読みたい箇所へ直入力で飛べるようになり、物理ページとの差分を頭の中で換算する手間がなくなります。
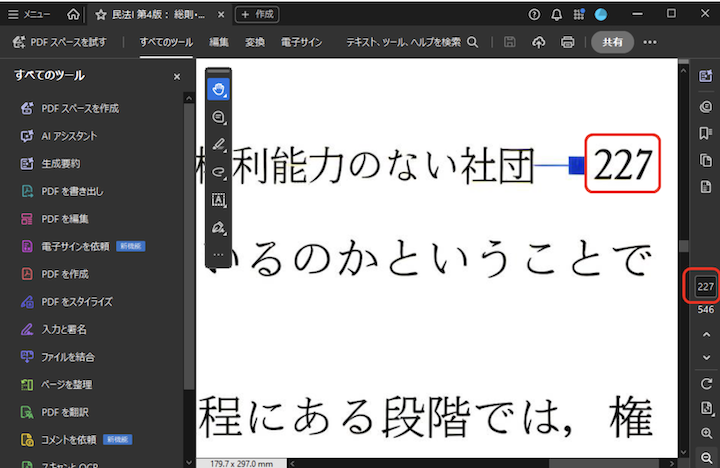
あわせて見開き表示で左右どちらに表示すべきかのフラグも自動設定し、縦書き書籍では右→左のページ順フラグも自動で立てるため、PDFビューア側の設定変更や小細工なしで快適に読める状態になっています。
DN_SuperBook_PDF_Converterの特徴
DN_SuperBook_PDF_Converterは、自炊PDFを「読書しやすい状態」に整えるための機能を幅広く備えた変換ツールです。ここでは、主要な4つの特徴を紹介します。
自炊PDFの高画質化が可能
自炊PDFは、紙の汚れや裏写り、インクにじみ、JPEGのモアレなどが残りやすく、拡大すると文字のギザギザが気になって読書の集中を妨げがちです。
DN_SuperBook_PDF_Converterは、画像鮮明化AIエンジンRealEsrganとC#で実装された自作アルゴリズムを組み合わせ、こうしたノイズを抑えながら高解像度化します。
その結果、タブレットや高精細ディスプレイでも読みやすくなり、後述するOCR精度の向上にもつながります。
傾きを補正できる
スキャン時のわずかな傾きは、単体では気にならなくても、ページをめくるほど「文字が斜めに流れる」感覚が積み重なり、読みにくさの原因になります。
しかし、DN_SuperBook_PDF_Converterは、元の紙の傾きやスキャン工程で混入した傾きを補正し、本文の水平・垂直が安定するように整えられます。
傾きが取れるだけで視線移動が楽になり、長時間読んでも疲れにくいPDFに近づくのがメリットです。
縦書きの書籍のページ順も最適化できる
縦書きの書籍は、正しい読み方向が「右→左」になるため、PDFビューア側の設定次第ではページ送りが逆になり、読書のたびにストレスが発生します。
しかし、DN_SuperBook_PDF_Converterは、縦書きであることを自動検出すると、ページ順序が右→左である旨のフラグを自動設定します。
見開き表示でも単ページ表示でも、縦書きとして自然な方向でページをめくれるようになり、設定変更の手間や混乱を減らせるのが魅力です。
AI-OCRによりPDFが検索可能に
DN_SuperBook_PDF_Converterのv2.00以降は、必要に応じてYomiTokuエンジンを内部呼び出しし、高精細な日本語AI-OCRで「文字埋め込み・検索可能PDF」を生成できます。
さらに、OCR結果をMarkdown・HTML・JSONでも出力できるため、全文検索用のインデックス作成やRAG、AI分析など二次活用ができるのもポイントです。
OCR実行後に消えがちな読書用メタデータ(ページ番号一致など)を再適用してくれるので、「検索できるのに読みやすい」状態を維持できます。
DN_SuperBook_PDF_Converterの安全性
DN_SuperBook_PDF_Converter自体はローカルで実行するツールですが、第三者が配布する実行ファイルやデータを自分でダウンロードして配置する必要があるため、絶対に安全とは言い切れません。
参照する外部ソフトが脆弱でマルウェアが混入する可能性もゼロではないため、ウイルス対策ソフトでの検証は必須です。
そのうえで、できるだけリスクを下げるなら 公式GitHubに記載された手順を守り、外部ツールやモデル類も公式サイトや公式リポジトリから入手しましょう。
DN_SuperBook_PDF_Converterの料金
DN_SuperBook_PDF_Converterは無料で公開されているため、基本的にツールの購入料金や月額利用料などはかかりません。
ただし、DN_SuperBook_PDF_Converterの利用にあたり、第三者が配布する複数のファイルやソフトをダウンロードするため、商用利用する場合は一部有料のライセンスを購入する必要があります。
なお、YomiToku は、kotaro.kinoshita 氏が公開・配布されているソフトウェアです。無償でダウンロードでき、「非商用での個人利用・研究目的での利用」は「自由に行っていただけます」と記載されています。しかし、商用利用等にあたっては、ライセンスの購入が必要と記載されています。詳しくは、同ソフトウェアの [README.md] (https://github.com/kotaro-kinoshita/yomitoku/blob/cba0a134e0d2ad3bfdce163231b3cb91de07928e/README.md) をご参照ください。
引用:GitHub
DN_SuperBook_PDF_Converterのライセンス
| 項目 | 利用可否 |
|---|---|
| 商用利用 | ⭕️(一部ソフトは有料ライセンス必須) |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
DN_SuperBook_PDF_Converter自体は、AGPL-3.0ライセンスで公開されており、商用利用・改変・配布・特許使用などが可能です。
しかし、内部で呼び出すライブラリや外部ツールはDN_SuperBook_PDF_Converterに含まれていないため、利用時はそれぞれのライセンス条件に従う必要があります。
特に、AI-OCRで利用できるYomiTokuについては、「非商用の個人利用・研究目的は自由だが、商用利用等ではライセンス購入が必要」と案内されているので注意しましょう。
DN_SuperBook_PDF_Converterの作者も私的利用を前提にツールを開発しており、「本ツールが第三者の特許権等を侵害していないことは保証しない」としているので、基本的には私的利用の範囲にとどめるのがおすすめです。
DN_SuperBook_PDF_Converterの使い方
ここでは公式手順書に沿って、DN_SuperBook_PDF_Converterの動作スペックや導入手順を紹介します。やること自体はシンプルですが、外部ツールの配置とRealEsrganの準備が肝なので、順番どおりに進めるのがコツです。
DN_SuperBook_PDF_Converterの動作スペック
| 必要なもの | 種類・スペック |
|---|---|
| OS | Windows 10or11 64bit版 |
| メモリ | 数GB~数十GBの空きメモリ (元PDFのページ数次第) |
| GPU | NVIDIAのCUDA対応のGeForceシリーズ推奨 VRAMは8GB以上 |
| 開発環境 | Visual Studio 2026もしくはVisual Studio 2022 Python 3系 git |
DN_SuperBook_PDF_Converterは、Windows 10/11(64bit)環境での利用を前提に、PDFの画像化やAI鮮明化、OCR処理を行うためPC負荷が高めです。
特にページ数が多いPDFほどメモリ消費が増えるので、数GB〜数十GBの空きメモリを確保しておく必要があります。
CPU処理のみでは鮮明化に時間がかかるため、CUDA対応のNVIDIA GeForceシリーズのGPUも用意しましょう。
DN_SuperBook_PDF_Converterの導入手順
DN_SuperBook_PDF_Converterの導入から、実際に使用するまでの手順を紹介します。
STEP1.リポジトリをクローンする
まずは開発用のフォルダを用意します。ディレクトリのフルパスにスペースや全角文字が入らない場所に置くとトラブルを避けやすいです。
Cドライブ直下の空欄部分で右クリックしてターミナルを開き、そこに以下のコマンドを入力してリポジトリをクローンします。
git clone --recursive https://github.com/dnobori/DN_SuperBook_PDF_Converter.git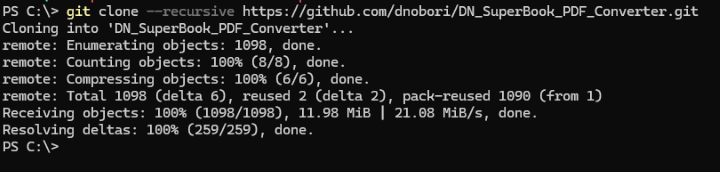
STEP2.外部ツールをダウンロードして所定フォルダへ配置する
本体が子プロセスとして呼び出す「外部ツール類」をそろえます。保存先は「external_tools\external_tools\image_tools\ 」配下で、各ツールごとに指定されたフォルダ構成になっているかが重要です。
| ツール名 ※クリックで直接ダウンロードできます | 保存先 |
|---|---|
| ExifTool(exiftool.exe/exiftool_files\) | external_tools\external_tools\image_tools\exiftool-13.30_64\(直下にexiftool.exe、同階層にexiftool_files\) |
| ImageMagick portable(magick.exe/mogrify.exe など一式)+Ghostscript(gsdll64.dll等4点) | external_tools\external_tools\image_tools\ImageMagick-portable-Q16-HDRI-x64\直下にImageMagick一式を配置Ghostscriptの4ファイルはGhostscriptをインストール後 C:\Program Files\gs\gs10.05.1\bin\直下にある4ファイルをImageMagick-portable-Q16-HDRI-x64\フォルダ直下へコピー |
| pdfcpu(pdfcpu.exe) | external_tools\external_tools\image_tools\pdfcpu\(直下にpdfcpu.exe) |
| qpdf(qpdf.exe) | external_tools\external_tools\image_tools\qpdf\(qpdf\bin\が存在し、その中にqpdf.exe等) |
| TesseractOCR_Data(eng.traineddata/jpn.traineddata) | external_tools\external_tools\image_tools\TesseractOCR_Data\(直下にeng.traineddataとjpn.traineddata) |
以下は「external_tools\external_tools\image_tools\ 」フォルダ直下の完成形です。
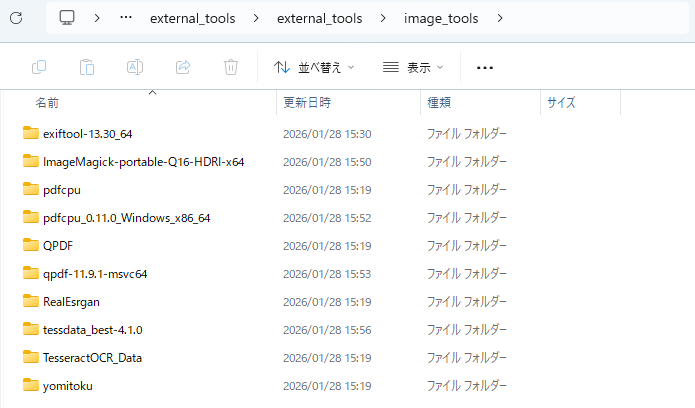
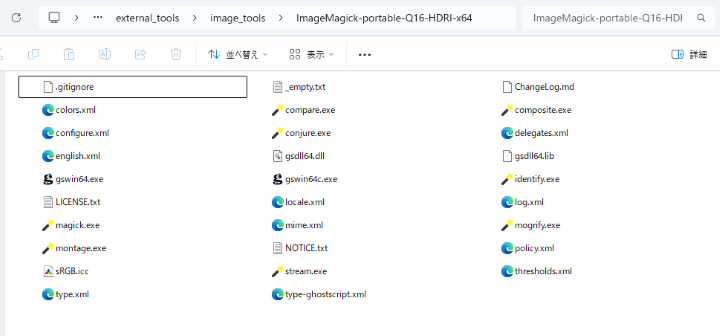
「ImageMagick-portable-Q16-HDRI-x64\」フォルダ直下にも指定ファイルを移動し、最終的に以下の状態になっている必要があります。
STEP3.RealEsrganをセットアップする
鮮明化処理に必須な「.RealEsrgan」をセットアップしていきます。まずはPython 3.11.9 for Windows をインストールし、「%LOCALAPPDATA%\Programs\Python\Python311\」にpython.exeが存在することを確認してください。
次に、「DN_SuperBook_PDF_Converter」のフォルダを右クリックしてターミナル(PowerShell)を開き、以下のコマンドを入力してください。
mkdir <このgitをダウンロードしたディレクトリ>\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\Cドライブ直下に「DN_SuperBook_PDF_Converter」フォルダがある場合は、<このgitをダウンロードしたディレクトリ>の部分を「C:」と入力します。
mkdir C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\続いて以下のコマンドを入力します。(以下Cドライブ直下に「DN_SuperBook_PDF_Converter」フォルダがある前提で進めます。)
cd /d C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\以下のコマンドでvenvをインストール。
%LOCALAPPDATA%\Programs\Python\Python311\python.exe -m venv venvvenvを有効化。
venv\Scripts\activatepipを更新。
python -m pip install --upgrade pipPyTorch(CUDA版)をインストール。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128Real-ESRGAN をクローンして指定コミットに固定。
cd C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo
& "C:\Program Files\Git\bin\git.exe" clone https://github.com/xinntao/Real-ESRGAN.git
cd C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\Real-ESRGAN
& "C:\Program Files\Git\bin\git.exe" checkout a4abfb2979a7bbff3f69f58f58ae324608821e27
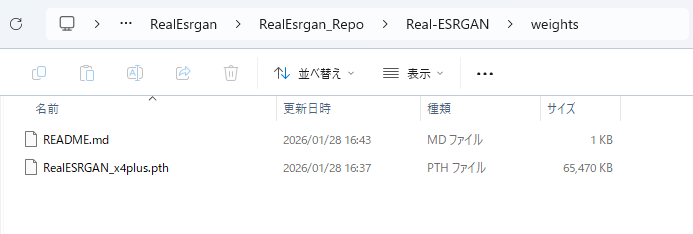
「RealESRGAN_x4plus.pth」をダウンロードして、「C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\Real-ESRGAN\weights\」直下に手動で配置します。
RealEsrgan_Repo に移動(念のため)
cd C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repovenv を有効化
.\venv\Scripts\Activate.ps1requirements をインストール
pip install -r .\Real-ESRGAN\requirements.txt「degradations.py」を1行だけ書き換えます。場所は「C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\venv\Lib\site-packages\basicsr\data\」の直下です。
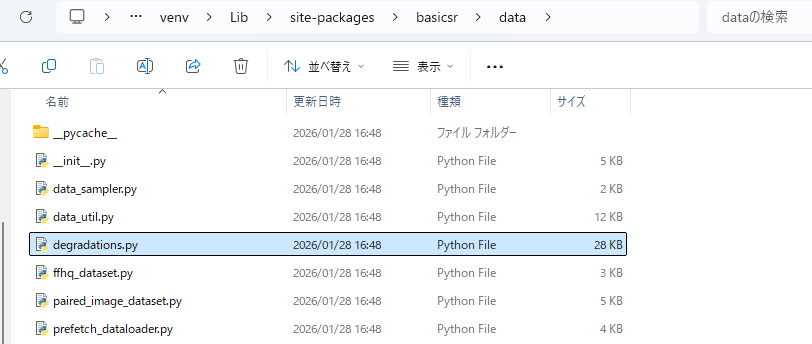
デフォルトで以下の記載がある行を編集します。
from torchvision.transforms.functional_tensor import rgb_to_grayscale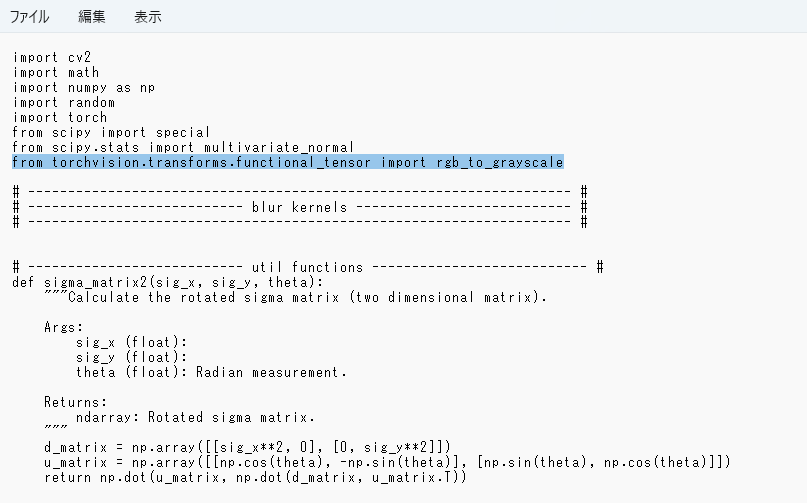
上記部分を以下に書き換えてください。
from torchvision.transforms.functional import rgb_to_grayscale最後に、「\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\RealEsrgan\RealEsrgan_Repo\Real-ESRGAN\realesrgan\」直下に「version.py」の名前で内容が空のファイルを作っておきます。
STEP4.YomiTokuをセットアップする(AI-OCRを使う人だけ)
AI-OCRを使いたい場合は、YomiTokuをセットアップします。
ターミナルに以下のコマンドを順番にコピペして実行してください。
cd /d C:\DN_SuperBook_PDF_Converter\external_tools\external_tools\image_tools\yomitoku\%LOCALAPPDATA%\Programs\Python\Python311\python.exe -m venv venvvenv\Scripts\activatepython -m pip install --upgrade pippip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128pip install "yomitoku==0.10.3"うまくいっているか確認したい場合は、以下のコマンドを実行します。
python -c "import yomitoku; print('yomitoku OK', yomitoku.__version__)"
上記のようなコマンドが返ってくれば、YomiTokuのインストールは成功しています。
STEP5.Visual Studioでビルドする
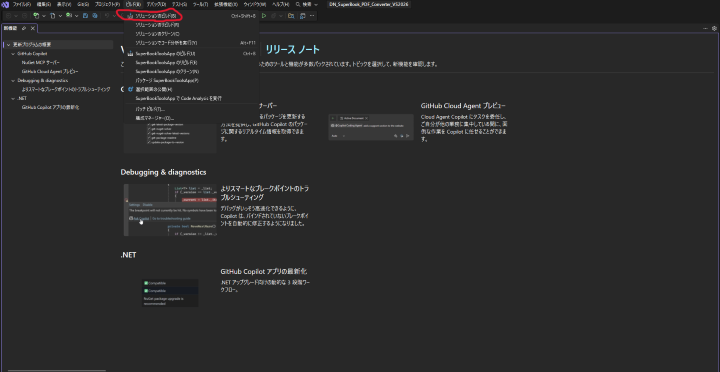
Visual Studioを開き、「プロジェクトやソリューションを開く」を選択して、「DN_SuperBook_PDF_Converter_VS2026.sln」を開きます。
以下の画面が立ち上がるので、上部にある「ビルド」から「ソリューションのビルド」を選択してください。
STEP6.起動してConvertPdfで変換する
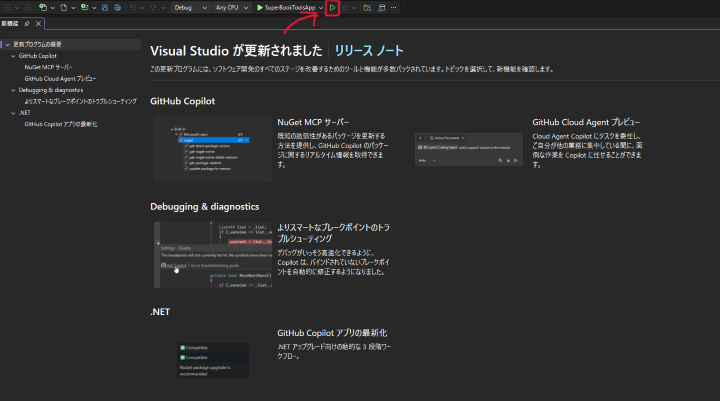
ビルドしたソリューションを「デバッグなしで実行」します。「デバッグありで実行」すると、処理に時間がかかるためです。
「Ctrl+F5」を押すか、上部にある再生マークを押すと「デバッグなしで実行」できます。
筆者の場合、ここで「.NET 6.0」の実行環境がPCに入っていないがためにエラーが起きました。そのため、Microsoft公式サイトから「.NET 6.0」をインストールしています。
「.NET 6.0」をインストール後、改めて「デバッグなしで実行」をクリックしてください。成功すると、以下画面のようにコマンドプロンプトのようなものが表示されます。
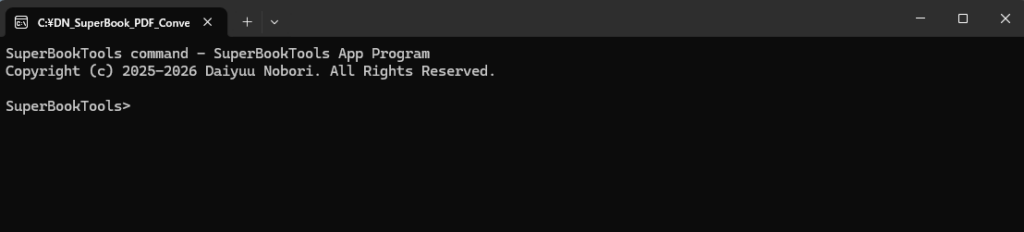
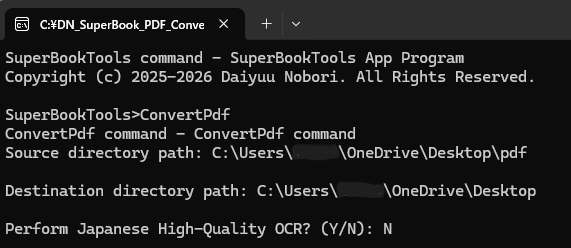
PDFの変換を実行する際は、以下のコマンドを入力します。
ConvertPdfソースディレクトリと宛先ディレクトリを質問されるので、それぞれパスを指定しましょう。ソースディレクトリは変換元のPDF、宛先ディレクトリには変換後のPDFを保存する場所を指定します。
例えば、デスクトップにPDFというフォルダを新しく作り、そこに変換元のPDFがある場合は以下のようにコマンドを入力します。
C:\Users\ユーザー名\OneDrive\Desktop\pdf宛先ディレクトリも任意で構いませんが、ソースディレクトリと同じ場所にはできません。例として、デスクトップに保存する場合は、以下のように指定します。
C:\Users\ユーザー名\OneDrive\Desktop最後にAI-OCRを実行するか問われるので、必要ならY、不要な場合はNを入力してください。
ログ全体は以下のようになります。
実行の結果、うまくいかない場合は前の手順でそれぞれのファイルやソフトを指定通りの場所に配置できていない、もしくは名称が異なる可能性があります。
エラーログをそのままChatGPTなどにコピペして質問すれば、おおよその原因がわかるので、自分だけで解決できない場合は試してみてください。
DN_SuperBook_PDF_Converterの活用シーン
DN_SuperBook_PDF_Converterは、読書や調べものをより快適にするツールとして利用できます。ここでは、具体的な活用シーンを2つ見ていきましょう。
古書・絶版書籍を快適に読む
紙の古書をスキャンしたPDFは、汚れ・裏写り・インクにじみなどが残りやすく、タブレットで読むと目が疲れがちです。
DN_SuperBook_PDF_Converterなら、Real-ESRGANを使った鮮明化で文字の輪郭を整えつつ、傾き補正や余白トリミングを本全体で統一してページ送りのガタつきも抑えられます。
古書特有の読みにくさをデジタルで軽減し、手元の蔵書を読みやすい電子書籍に近づけたいときに有効です。
専門書・資料を検索できる資産にする
必要な条文やキーワードを探すたびにページをめくるのは非効率的です。YomiTokuによる高精細OCRを有効にすれば、文字を埋め込んだ検索可能PDFを生成でき、PDFビューアの検索で目的箇所へすぐに到達できます。
さらに、OCR後に読書用メタデータを再適用して快適さを維持できるのもポイント。長い専門書・判例集・講義資料などを探せる状態に整えたい場合に、時間の節約効果が大きいです。
なお、生成AIの活用事例が知りたい方は、以下の記事もご覧ください。

DN_SuperBook_PDF_Converterを実際に使ってみた
今回はデモ用に、DN_SuperBook_PDF_Converterの公式ドキュメントで紹介されている、以下の画像をPDF化して使ってみます。

早速、公式ドキュメントの手順通りにPDFの変換を試みたところ、以下のような画像になりました。(AI-OCRも使用)

Visual Studio上の処理は問題なく完了したのですが、かえって読みにくい見た目になってしまいました。今回は著作権上の理由で紙の書籍をスキャンしていないので、それが原因かもしれません。
本来の用途であれば、紙の書籍を1枚ずつ読み込むので、もう少し綺麗に変換される可能性もあります。
DN_SuperBook_PDF_Converterで理想の電子書籍を作ろう!
DN_SuperBook_PDF_Converterは、そのままだと読みにくい自炊PDFを読みやすい見た目に変換できる便利なツールです。読書や調べ物がより快適になるほか、PDF内をページなどで検索できるようになります。
ローカル環境にクローンして実行するため、環境構築の難易度は高いですが、本記事の通りに進めれば問題ありません。
古書や絶版書の読書に苦労している方や、電子書籍化して情報検索の利便性を向上させたい方はぜひ活用してみてください。

最後に
いかがだったでしょうか?
DN_SuperBook_PDF_Converterを活用すれば、自炊PDFの画質改善からページ補正、AI-OCRによる検索性向上までを一括で進められ、読みやすさと再利用性を大きく高められます。とはいえ、OCR結果をRAGや社内ナレッジ化に繋げる設計まで含めて自社だけで進めるのは難しいことも多いため、実装経験のあるパートナーと一緒に最短ルートで仕組み化するのも有効です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

