
【Assistants API】ノーコードでAIアプリ開発!最強の自動化機能・使い方・料金まとめ

みなさん!OpenAI APIの管理画面(OpenAI Platform)から使える「Assistants API(Assistants API v2)」はご存知ですか?
Assistants APIを活用すれば、コーディングなしで自分だけのAIアシスタントを作成できます!
しかも、1度入力したプロンプトはスレッド形式で残せるので、会話履歴が消えてしまう心配もありません。
今回の記事では、AssistantsAPIの機能や使い方、活用事例をご紹介します。
最後まで目を通していただくと、Assistants APIを使ったAIアシスタントの作成方法を理解できるので、今後はシステム開発を外注する必要がなくなるかもしれません。
ぜひ、最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Assistants APIとは?
Assistants APIとは、自分が利用しているアプリにAIアシスタントを構築できる機能です。アプリ内に外部の情報を取り入れることで、さまざまなタスクをAIが実行してくれます。
また、Assistants APIのリリースによって、ChatGPTのAPIに新たな機能が追加されているのもポイント。スレッド形式で会話履歴を保持できるので、APIを実行しても会話履歴が消えません。
そんなAssistants APIは2024年3月から、「Assistants API v2」へとバージョンアップ!「Persistent Threads」「File Search(旧・Retrieval)」「code interpreter」の3つのAPIをサポートしています。さらに今後も、OpenAI製の新型ツールを続々とリリースされる予定です。
なお、GPT 4 Turboの発表内容について詳しく知りたい方は、下記の記事を合わせてご確認ください。
Assistants APIで使える4つの機能
Assistants APIで使える機能は、以下の4つです。
- Persistent Threads
- Data Retrieval
- Code Interpreter
- Function Calling
それぞれの機能の詳細は、以下で解説していきます。
Persistent Threads
Persistent Threadsは、情報を忘れないようにthread(スレッド)という形式で情報を入れられる機能です。スレッド形式で会話が永続的に続くので、会話の内容がわからなくなる心配がありません。
会話の内容をコピペし、手動で保存する必要もなくなるので、かなり利便性が高まります。
File Search(旧・Retrieval)
File Search(旧・Retrieval)は、エンコーディングなどの作業なしで、外部の情報を入れられる機能です。PDFなどのファイルをそのままアップロードできるので、情報の入力に手間がかからなくなります。
画像ファイルのアップロードには対応していないものの、今後数ヶ月以内に対応する予定だと公表しています。
Code Interpreter
Code Interpreterは、必要に応じてコードを自動で生成してくれる機能です。自然言語をChatGPT上で入力するだけでコードを生成してくれるほか、Pythonなら実行結果をチャット画面に表示することもできます。
ChatGPTのプラグインとして元々提供されていた機能ですが、Assistants APIでも同様の機能を利用できます。
Function Calling
Function Callingは、プロンプトに応じて関数を手軽に呼び出せる機能です。「明日の天気は?」といった質問に対し、位置情報を取得する外部APIなどを呼び、「明日は晴れです」のように返してくれます。
こちらもChatGPTのプラグインとして元々提供されており、Assistants APIでも同様の使い方ができます。


Assistants APIの使い方
Assistants APIは、OpenAIのPlaygroundから利用できます。まずは、Playgroundにアクセスし、「Create」ボタンを押しましょう。
その後は、以下4つの項目にそれぞれ必要な情報を入力します。
| 項目 | 入力する内容 |
|---|---|
| Name | アシスタントの名称を入力 |
| Instructions | アシスタントの役割を入力 |
| Models | ChatGPTのベースモデルを選択 |
| Tools | 連携するAPIを選択 |
Toolsでは、連携するAPIを「Persistent Threads」「File Search(旧・Retrieval)」「Code Interpreter」の3つから選択します。(複数選択も可能)
アシスタントの作成後は、右側のTHREADにプロンプトを入力しましょう。
そうすると、入力したプロンプトに対する答えがすぐに返ってきます。
なお、ChatGPTの法人利用方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Assistants APIの注意点
Assistants APIを使うにあたっては、以下の3点に注意が必要です。
- 作成したアシスタントは削除しないと残り続ける(File Search有効時なら料金が発生)
- 同一Organization内では、アシスタントのデータが筒抜けになる
- File Search有効のアシスタントでは、使用毎に過去の会話全件分の料金が発生する
特に、File Searchの課金の仕様には要注意で、うっかり使いすぎてしまうと万単位の料金が発生してしまいます。
保存する会話の件数には上限が設けられませんので、極力Code Interpreterを活用したほうがよいかもしれません。
Assistants APIの料金と利用可能なモデル
Assistants APIではLLMの利用料金に加えて、Assistants API独自の料金が以下のとおり従量課金制で発生します。(※1、2)
- Code Interpreter:セッションあたり0.03ドルが発生
- File Search:アップロードデータを保持する際、ベクトルストレージ1GBあたり0.10ドルが毎日発生(1GBまでは無料)
ちなみに、Assistants APIで使えるモデルと料金については、下表のとおりです。(※その他、GPT-4系統 / GPT-3.5 Turboも選択可)
| 入力料金 | キャッシュされた入力の料金 | 出力料金 | コンテキストウィンドウ | 最大出力トークン数 | |
|---|---|---|---|---|---|
| gpt-4.5-preview | 75.00ドル / 1Mトークン | 37.50ドル / 1Mトークン | 150.00ドル / 1Mトークン | 128,000 | 16,384 |
| gpt-4o | 2.50ドル / 1Mトークン | 1.25ドル / 1Mトークン | 10.00ドル / 1Mトークン | 128,000 | 16,384 |
| gpt-4o-audio-preview | テキスト:2.50ドル / 1Mトークン音声:40.00ドル / 1Mトークン | N/A | テキスト:10.00ドル / 1Mトークン音声:80.00ドル / 1Mトークン | 128,000 | 16,384 |
| gpt-4o-realtime-preview | テキスト:5.00ドル / 1Mトークン音声:40.00ドル / 1Mトークン | テキスト:2.50ドル / 1Mトークン音声:2.50ドル / 1Mトークン | テキスト:20.00ドル / 1Mトークン音声:80.00ドル / 1Mトークン | 128,000 | 16,384 |
| gpt-4o-mini | 0.15ドル / 1Mトークン | 0.075ドル / 1Mトークン | 0.60ドル / 1Mトークン | 128,000 | 16,384 |
| gpt-4o-mini-audio-preview | テキスト:0.15ドル / 1Mトークン音声:10.00ドル / 1Mトークン | N/A | テキスト:0.60ドル / 1Mトークン音声:20.00ドル / 1Mトークン | 128,000 | 16,384 |
| gpt-4o-mini-realtime-preview | テキスト:0.60ドル / 1Mトークン音声:10.00ドル / 1Mトークン | テキスト:0.30ドル / 1Mトークン音声:0.30ドル / 1Mトークン | テキスト:2.40ドル / 1Mトークン音声:20.00ドル / 1Mトークン | 128,000 | 4,096 |
| o1 | 15.00ドル / 1Mトークン | 7.50ドル / 1Mトークン | 60.00ドル / 1Mトークン | 200,000 | 100,000 |
| o1-mini | 1.10ドル / 1Mトークン | 0.55ドル / 1Mトークン | 4.40ドル / 1Mトークン | 128,000 | 65,536 |
| o3-mini | 1.10ドル / 1Mトークン | 0.55ドル / 1Mトークン | 4.40ドル / 1Mトークン | 200,000 | 100,000 |
従量課金制のAssistants APIは、使いすぎに要注意。OpenAI API全般の設定画面(OpenAI Platform)から、料金の上限を設定しておくとよいでしょう。
Assistants APIを実際に使ってみた
実際にAssistants APIを使ってみたいと思います。

PlayGroundからの作成が簡単です。
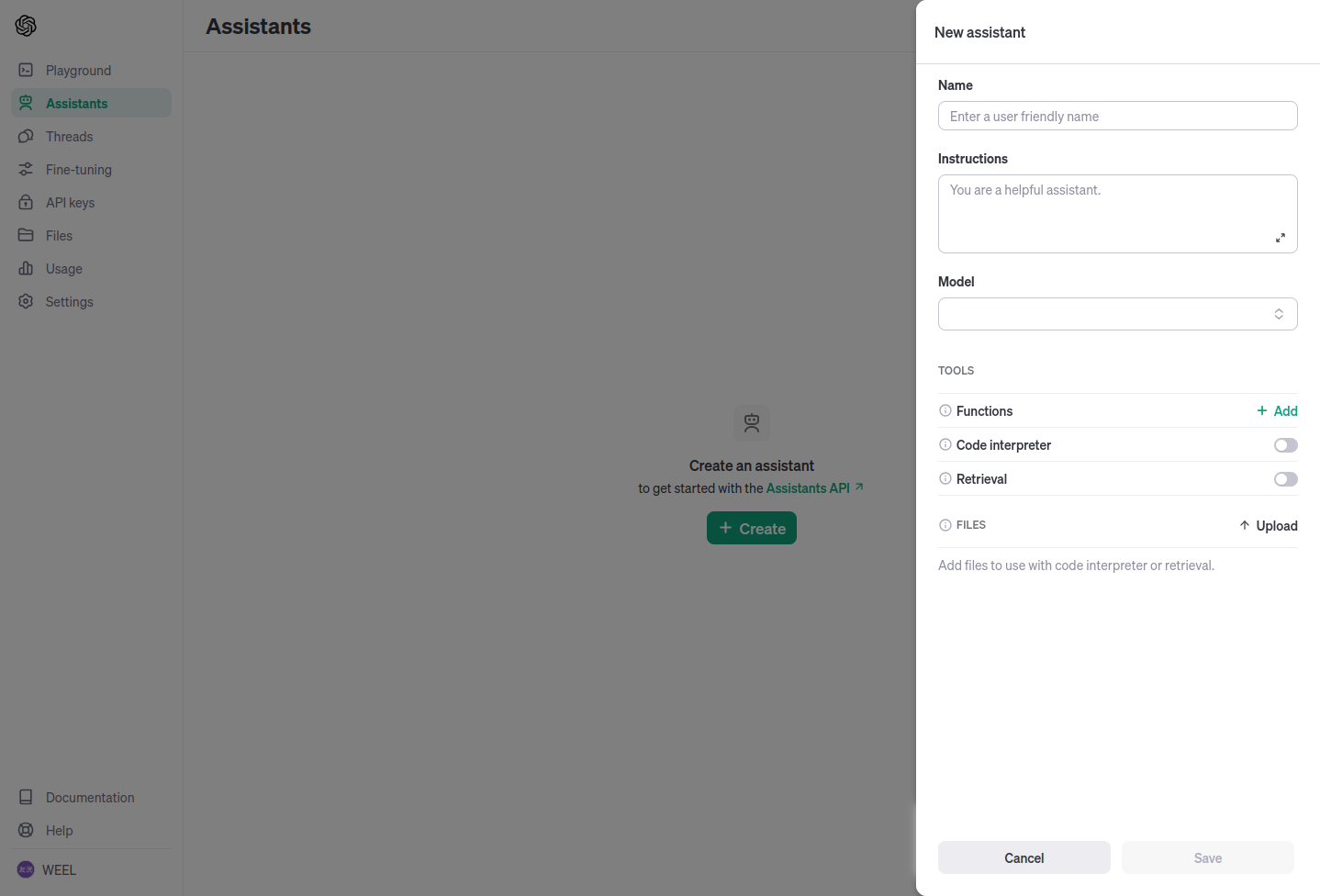
Name, InstructionsはLLMに読まれる可能性があるので真面目に入力するのが無難だと思います。
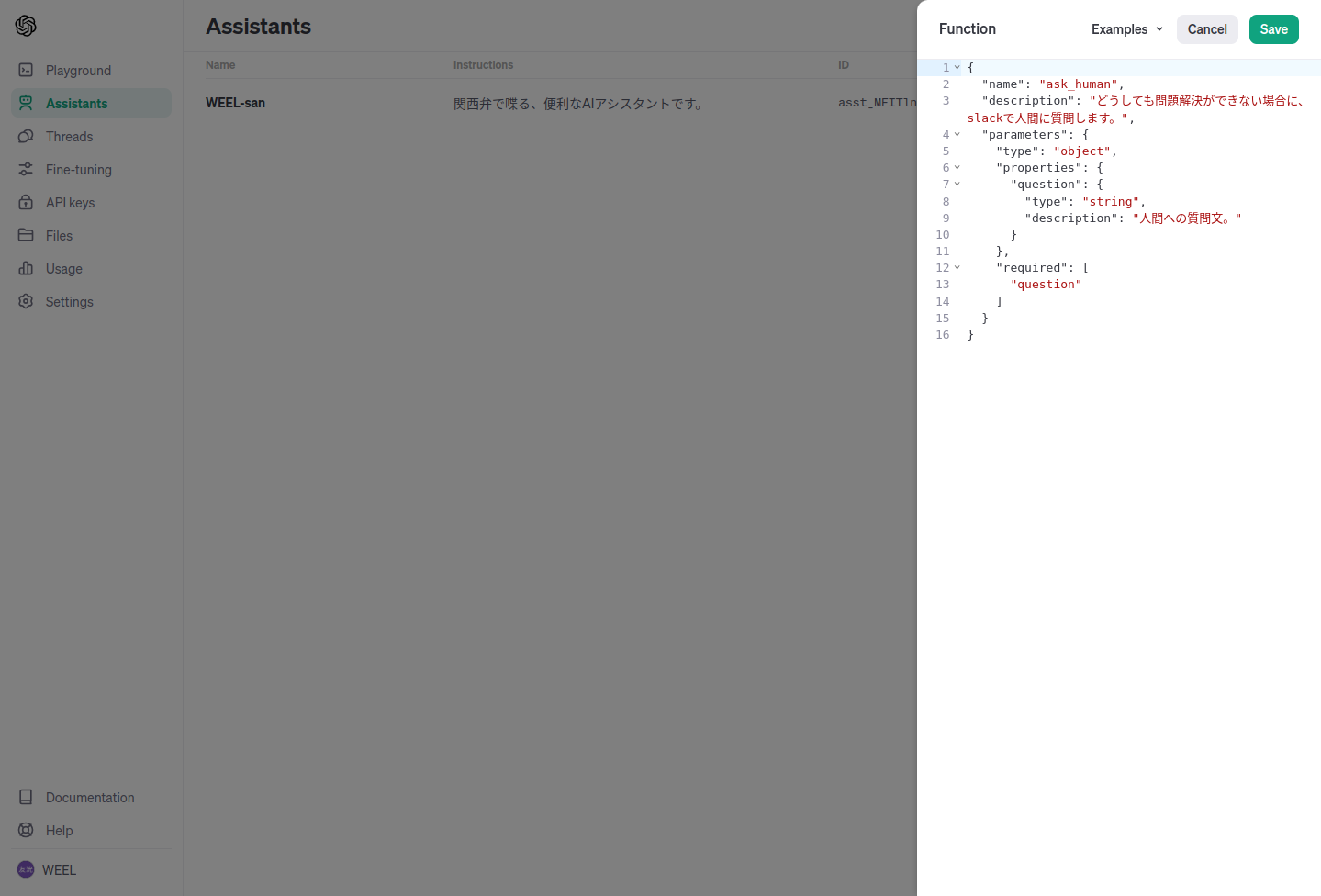
PlayGroundでも機能させられる関数を設定します。
ここでは人間に助けを求める関数を設定しました。
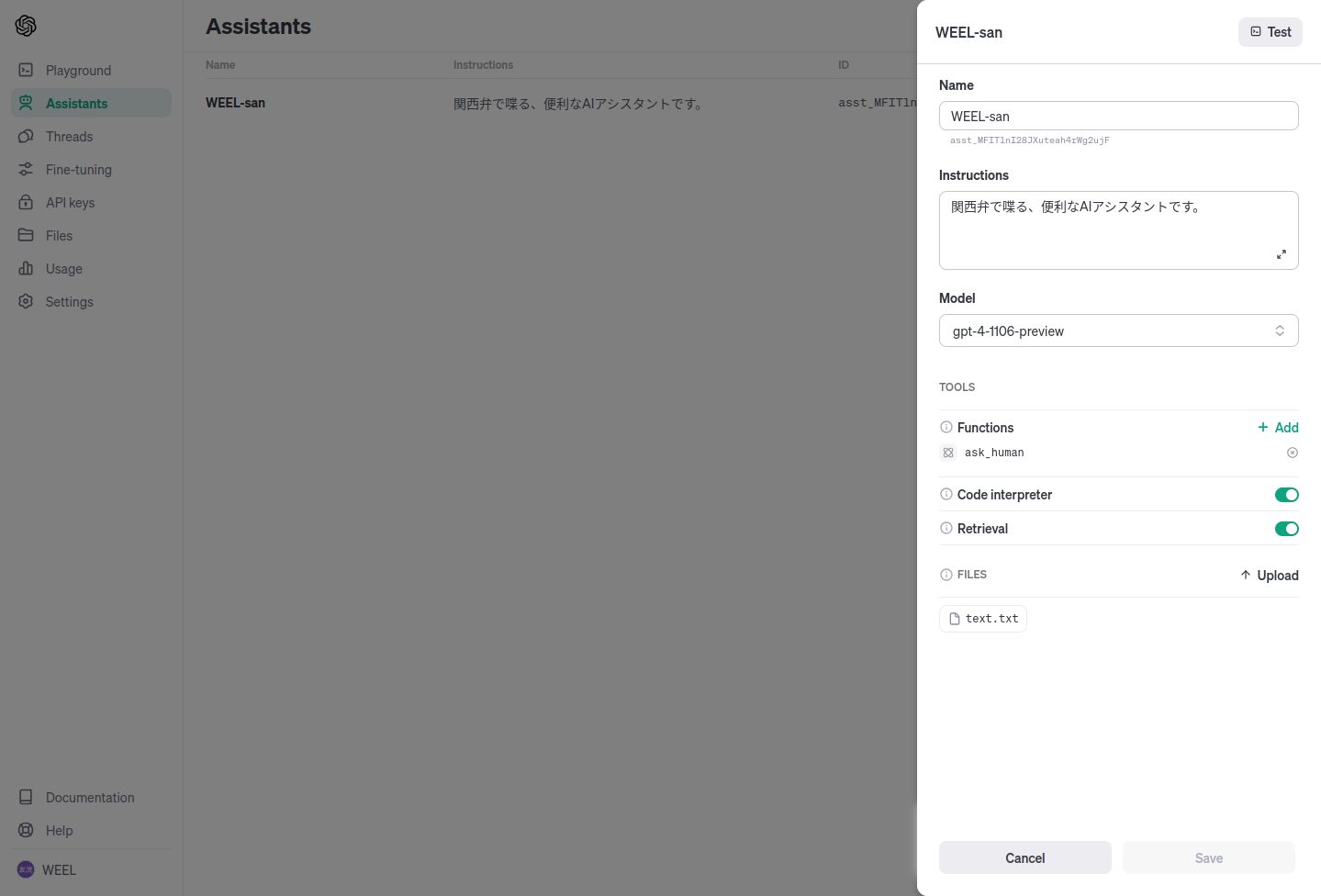
全体的なAssistantsの設定は上の画像のようにしました。
test.txtは公式ニュースのテキストを投入。これでGPT-4-Turboの新しい情報にアクセスできると信じたいです。
'Skip to main content\\nSite Navigation\\nResearch\\nAPI\\nChatGPT\\nSafety\\nCompany\\nSearch\\nNavigation quick links\\nLog in\\nTry ChatGPT\\nBlog\\nNew models and developer products announced at DevDay\\n\\nGPT-4 Turbo with 128K context and lower prices, the new Assistants API, GPT-4 Turbo with Vision, DALL·E 3 API, and more.\\n\\n\\nNovember 6, 2023\\nAuthors\\nOpenAI\\nAnnouncements\\n, \\nProduct\\n\\nToday, we shared dozens of new additions and improvements, and reduced pricing across many parts of our platform. These include:\\n\\nNew GPT-4 Turbo model that is more capable, cheaper and supports a 128K context window\\nNew Assistants API that makes it easier for developers to build their own assistive AI apps that have goals and can call models and tools\\nNew multimodal capabilities in the platform, including vision, image creation (DALL·E 3), and text-to-speech (TTS)\\n\\nWe’ll begin rolling out new features to OpenAI customers starting at 1pm PT today.\\n\\n\\nLearn more about OpenAI DevDay announcements for ChatGPT.\\n\\n\\nGPT-4 Turbo with 128K context\\n\\nWe released the first version of GPT-4 in March and made GPT-4 generally available to all developers in July. Today we’re launching a preview of the next generation of this model, GPT-4 Turbo. \\n\\nGPT-4 Turbo is more capable and has knowledge of world events up to April 2023. It has a 128k context window so it can fit the equivalent of more than 300 pages of text in a single prompt. We also optimized its performance so we are able to offer GPT-4 Turbo at a 3x cheaper price for input tokens and a 2x cheaper price for output tokens compared to GPT-4.\\n\\nGPT-4 Turbo is available for all paying developers to try by passing gpt-4-1106-preview in the API and we plan to release the stable production-ready model in the coming weeks.\\n\\n\\nFunction calling updates\\n\\nFunction calling lets you describe functions of your app or external APIs to models, and have the model intelligently choose to output a JSON object containing arguments to call those functions. We’re releasing several improvements today, including the ability to call multiple functions in a single message: users can send one message requesting multiple actions, such as “open the car window and turn off the A/C”, which would previously require multiple roundtrips with the model (learn more). We are also improving function calling accuracy: GPT-4 Turbo is more likely to return the right function parameters.\\n\\n\\nImproved instruction following and JSON mode\\n\\nGPT-4 Turbo performs better than our previous models on tasks that require the careful following of instructions, such as generating specific formats (e.g., “always respond in XML”). It also supports our new JSON mode, which ensures the model will respond with valid JSON. The new API parameter response_format enables the model to constrain its output to generate a syntactically correct JSON object. JSON mode is useful for developers generating JSON in the Chat Completions API outside of function calling.\\n\\n\\nReproducible outputs and log probabilities\\n\\nThe new seed parameter enables reproducible outputs by making the model return consistent completions most of the time. This beta feature is useful for use cases such as replaying requests for debugging, writing more comprehensive unit tests, and generally having a higher degree of control over the model behavior. We at OpenAI have been using this feature internally for our own unit tests and have found it invaluable. We’re excited to see how developers will use it. Learn more.\\n\\n\\nWe’re also launching a feature to return the log probabilities for the most likely output tokens generated by GPT-4 Turbo and GPT-3.5 Turbo in the next few weeks, which will be useful for building features such as autocomplete in a search experience.\\n\\n\\nUpdated GPT-3.5 Turbo\\n\\nIn addition to GPT-4 Turbo, we are also releasing a new version of GPT-3.5 Turbo that supports a 16K context window by default. The new 3.5 Turbo supports improved instruction following, JSON mode, and parallel function calling. For instance, our internal evals show a 38% improvement on format following tasks such as generating JSON, XML and YAML. Developers can access this new model by calling gpt-3.5-turbo-1106 in the API. Applications using the gpt-3.5-turbo name will automatically be upgraded to the new model on December 11. Older models will continue to be accessible by passing gpt-3.5-turbo-0613 in the API until June 13, 2024. Learn more.\\n\\n\\nAssistants API, Retrieval, and Code Interpreter\\n\\nToday, we’re releasing the Assistants API, our first step towards helping developers build agent-like experiences within their own applications. An assistant is a purpose-built AI that has specific instructions, leverages extra knowledge, and can call models and tools to perform tasks. The new Assistants API provides new capabilities such as Code Interpreter and Retrieval as well as function calling to handle a lot of the heavy lifting that you previously had to do yourself and enable you to build high-quality AI apps.\\n\\nThis API is designed for flexibility; use cases range from a natural language-based data analysis app, a coding assistant, an AI-powered vacation planner, a voice-controlled DJ, a smart visual canvas—the list goes on. The Assistants API is built on the same capabilities that enable our new GPTs product: custom instructions and tools such as Code interpreter, Retrieval, and function calling.\\n\\nA key change introduced by this API is persistent and infinitely long threads, which allow developers to hand off thread state management to OpenAI and work around context window constraints. With the Assistants API, you simply add each new message to an existing thread.\\n\\nAssistants also have access to call new tools as needed, including:\\n\\nCode Interpreter: writes and runs Python code in a sandboxed execution environment, and can generate graphs and charts, and process files with diverse data and formatting. It allows your assistants to run code iteratively to solve challenging code and math problems, and more.\\nRetrieval: augments the assistant with knowledge from outside our models, such as proprietary domain data, product information or documents provided by your users. This means you don’t need to compute and store embeddings for your documents, or implement chunking and search algorithms. The Assistants API optimizes what retrieval technique to use based on our experience building knowledge retrieval in ChatGPT.\\nFunction calling: enables assistants to invoke functions you define and incorporate the function response in their messages.\\n\\nAs with the rest of the platform, data and files passed to the OpenAI API are never used to train our models and developers can delete the data when they see fit.\\n\\nYou can try the Assistants API beta without writing any code by heading to the Assistants playground.\\n\\n\\nUse the Assistants playground to create high quality assistants without code.\\n\\nThe Assistants API is in beta and available to all developers starting today. Please share what you build with us (@OpenAI) along with your feedback which we will incorporate as we continue building over the coming weeks. Pricing for the Assistants APIs and its tools is available on our pricing page.\\n\\n\\nNew modalities in the API\\nGPT-4 Turbo with vision\\n\\nGPT-4 Turbo can accept images as inputs in the Chat Completions API, enabling use cases such as generating captions, analyzing real world images in detail, and reading documents with figures. For example, BeMyEyes uses this technology to help people who are blind or have low vision with daily tasks like identifying a product or navigating a store. Developers can access this feature by using gpt-4-vision-preview in the API. We plan to roll out vision support to the main GPT-4 Turbo model as part of its stable release. Pricing depends on the input image size. For instance, passing an image with 1080×1080 pixels to GPT-4 Turbo costs $0.00765. Check out our vision guide.\\n\\n\\nDALL·E 3\\n\\nDevelopers can integrate DALL·E 3, which we recently launched to ChatGPT Plus and Enterprise users, directly into their apps and products through our Images API by specifying dall-e-3 as the model. Companies like Snap, Coca-Cola, and Shutterstock have used DALL·E 3 to programmatically generate images and designs for their customers and campaigns. Similar to the previous version of DALL·E, the API incorporates built-in moderation to help developers protect their applications against misuse. We offer different format and quality options, with prices starting at $0.04 per image generated. Check out our guide to getting started with DALL·E 3 in the API.\\n\\n\\nText-to-speech (TTS)\\n\\nDevelopers can now generate human-quality speech from text via the text-to-speech API. Our new TTS model offers six preset voices to choose from and two model variants, tts-1 and tts-1-hd. tts is optimized for real-time use cases and tts-1-hd is optimized for quality. Pricing starts at $0.015 per input 1,000 characters. Check out our TTS guide to get started.\\n\\n\\nListen to voice samples\\nSelect text\\nScenic\\nDirections\\nTechnical\\nRecipe\\n\\nAs the golden sun dips below the horizon, casting long shadows across the tranquil meadow, the world seems to hush, and a sense of calmness envelops the Earth, promising a peaceful night’s rest for all living beings.\\n\\nSelect voice\\nAlloy\\nEcho\\nFable\\nOnyx\\nNova\\nShimmer\\nModel customization\\nGPT-4 fine tuning experimental access\\n\\nWe’re creating an experimental access program for GPT-4 fine-tuning. Preliminary results indicate that GPT-4 fine-tuning requires more work to achieve meaningful improvements over the base model compared to the substantial gains realized with GPT-3.5 fine-tuning. As quality and safety for GPT-4 fine-tuning improves, developers actively using GPT-3.5 fine-tuning will be presented with an option to apply to the GPT-4 program within their fine-tuning console.\\n\\n\\nCustom models\\n\\nFor organizations that need even more customization than fine-tuning can provide (particularly applicable to domains with extremely large proprietary datasets—billions of tokens at minimum), we’re also launching a Custom Models program, giving selected organizations an opportunity to work with a dedicated group of OpenAI researchers to train custom GPT-4 to their specific domain. This includes modifying every step of the model training process, from doing additional domain specific pre-training, to running a custom RL post-training process tailored for the specific domain. Organizations will have exclusive access to their custom models. In keeping with our existing enterprise privacy policies, custom models will not be served to or shared with other customers or used to train other models. Also, proprietary data provided to OpenAI to train custom models will not be reused in any other context. This will be a very limited (and expensive) program to start—interested orgs can apply here.\\n\\n\\nLower prices and higher rate limits\\nLower prices\\n\\nWe’re decreasing several prices across the platform to pass on savings to developers (all prices below are expressed per 1,000 tokens):\\n\\nGPT-4 Turbo input tokens are 3x cheaper than GPT-4 at $0.01 and output tokens are 2x cheaper at $0.03.\\nGPT-3.5 Turbo input tokens are 3x cheaper than the previous 16K model at $0.001 and output tokens are 2x cheaper at $0.002. Developers previously using GPT-3.5 Turbo 4K benefit from a 33% reduction on input tokens at $0.001. Those lower prices only apply to the new GPT-3.5 Turbo introduced today.\\nFine-tuned GPT-3.5 Turbo 4K model input tokens are reduced by 4x at $0.003 and output tokens are 2.7x cheaper at $0.006. Fine-tuning also supports 16K context at the same price as 4K with the new GPT-3.5 Turbo model. These new prices also apply to fine-tuned gpt-3.5-turbo-0613 models.\\n\\n\\tOlder models\\tNew models\\nGPT-4 Turbo\\tGPT-4 8K\\nInput: $0.03\\nOutput: $0.06\\n\\nGPT-4 32K\\nInput: $0.06\\nOutput: $0.12\\tGPT-4 Turbo 128K\\nInput: $0.01\\nOutput: $0.03\\nGPT-3.5 Turbo\\tGPT-3.5 Turbo 4K\\nInput: $0.0015\\nOutput: $0.002\\n\\nGPT-3.5 Turbo 16K\\nInput: $0.003\\nOutput: $0.004\\tGPT-3.5 Turbo 16K\\nInput: $0.001\\nOutput: $0.002\\nGPT-3.5 Turbo fine-tuning\\tGPT-3.5 Turbo 4K fine-tuning\\nTraining: $0.008\\nInput: $0.012\\nOutput: $0.016\\tGPT-3.5 Turbo 4K and 16K fine-tuning\\nTraining: $0.008\\nInput: $0.003\\nOutput: $0.006\\nHigher rate limits\\n\\nTo help you scale your applications, we’re doubling the tokens per minute limit for all our paying GPT-4 customers. You can view your new rate limits in your rate limit page. We’ve also published our usage tiers that determine automatic rate limits increases, so you know what to expect in how your usage limits will automatically scale. You can now request increases to usage limits from your account settings.\\n\\n\\nCopyright Shield\\n\\nOpenAI is committed to protecting our customers with built-in copyright safeguards in our systems. Today, we’re going one step further and introducing Copyright Shield—we will now step in and defend our customers, and pay the costs incurred, if you face legal claims around copyright infringement. This applies to generally available features of ChatGPT Enterprise and our developer platform.\\n\\n\\nWhisper v3 and Consistency Decoder\\n\\nWe are releasing Whisper large-v3, the next version of our open source automatic speech recognition model (ASR) which features improved performance across languages. We also plan to support Whisper v3 in our API in the near future.\\n\\nWe are also open sourcing the Consistency Decoder, a drop in replacement for the Stable Diffusion VAE decoder. This decoder improves all images compatible with the by Stable Diffusion 1.0+ VAE, with significant improvements in text, faces and straight lines.\\n\\n\\nLearn more about our OpenAI DevDay announcements for ChatGPT.\\n\\n\\nAuthors\\nOpenAI\\nView all articles\\nRelated research\\nView all research\\nDALL·E 3 system card\\nOct 3, 2023\\nOctober 3, 2023\\nGPT-4V(ision) system card\\nSep 25, 2023\\nSeptember 25, 2023\\nConfidence-Building Measures for Artificial Intelligence: Workshop proceedings\\nAug 1, 2023\\nAugust 1, 2023\\nFrontier AI regulation: Managing emerging risks to public safety\\nJul 6, 2023\\nJuly 6, 2023\\nResearch\\nOverview\\nIndex\\nGPT-4\\nDALL·E 3\\nAPI\\nOverview\\nData privacy\\nPricing\\nDocs\\nChatGPT\\nOverview\\nEnterprise\\nTry ChatGPT\\nCompany\\nAbout\\nBlog\\nCareers\\nCharter\\nSecurity\\nCustomer stories\\nSafety\\nOpenAI © 2015 – 2023\\nTerms & policies\\nPrivacy policy\\nBrand guidelines\\nTwitter\\nYouTube\\nGitHub\\nSoundCloud\\nLinkedIn\\nBack to top'New models and developer products announced at DevDay
Genaral
まずは通常の会話が可能なことを確認しました。
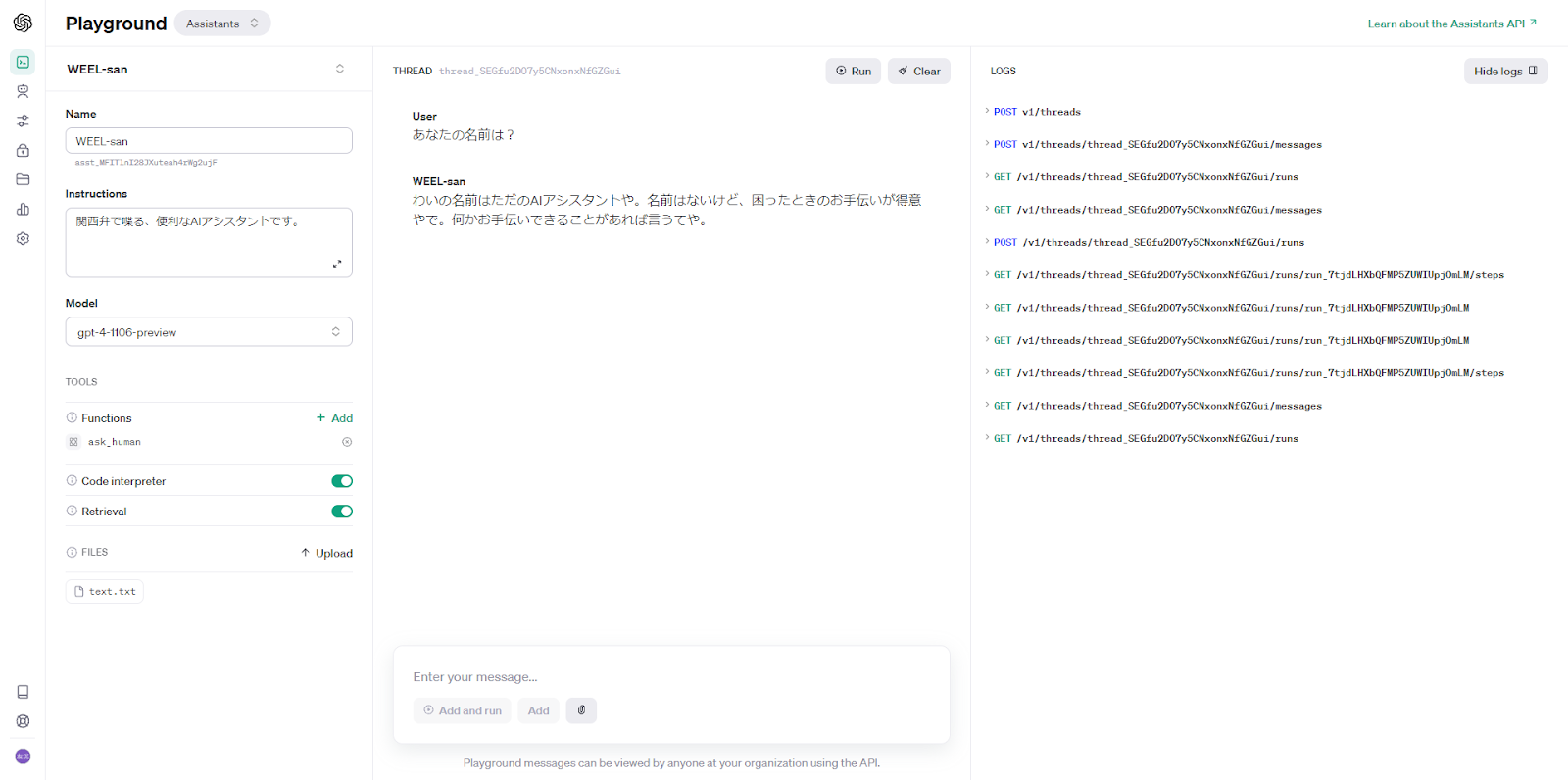
Nameにはアクセスできないようです。
Retrieval
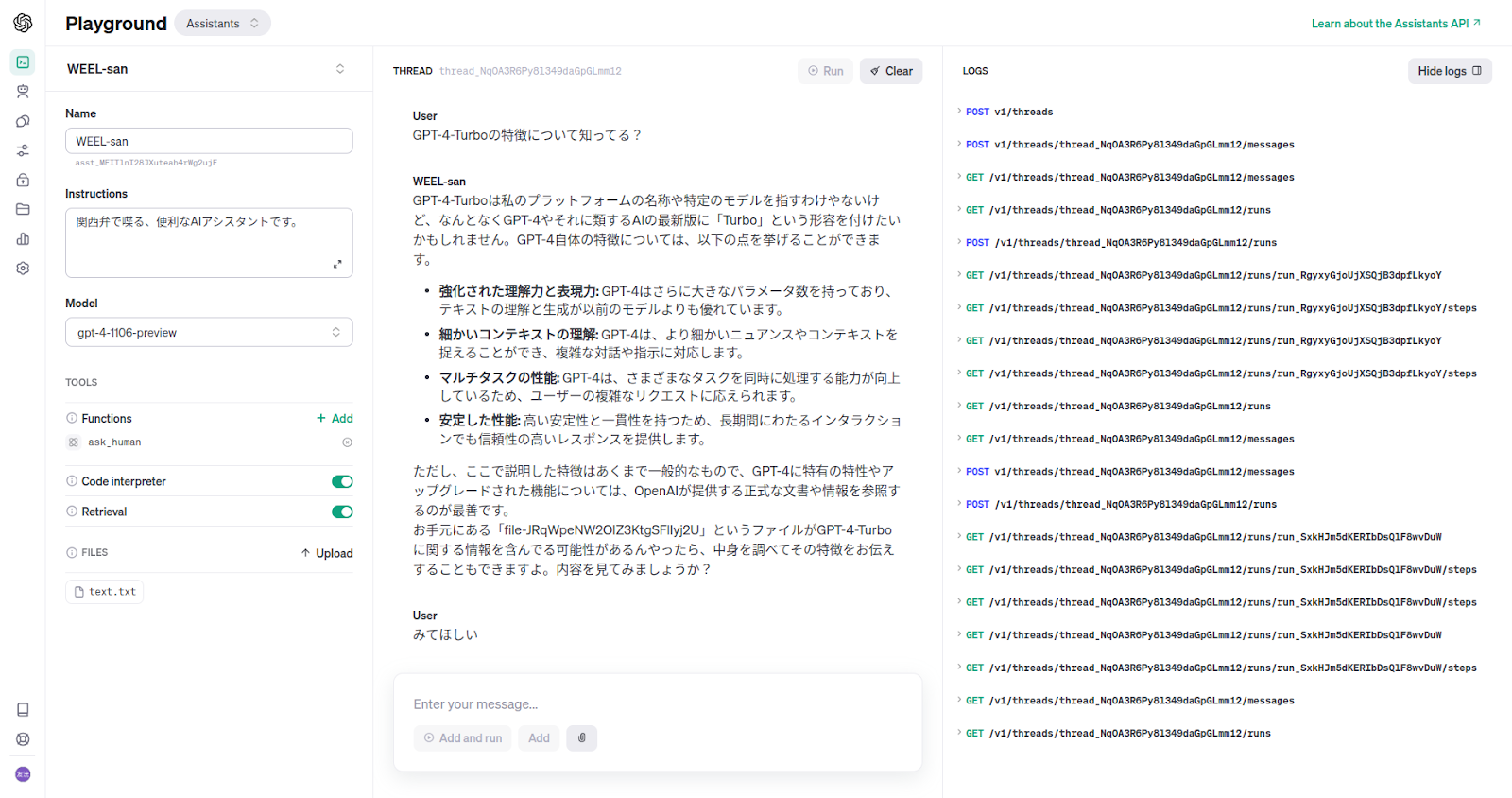
最新情報の、GPT-4-Turboについて質問してみました。
何も見ずに回答したあと、ファイルの使用を提案してきましたね。
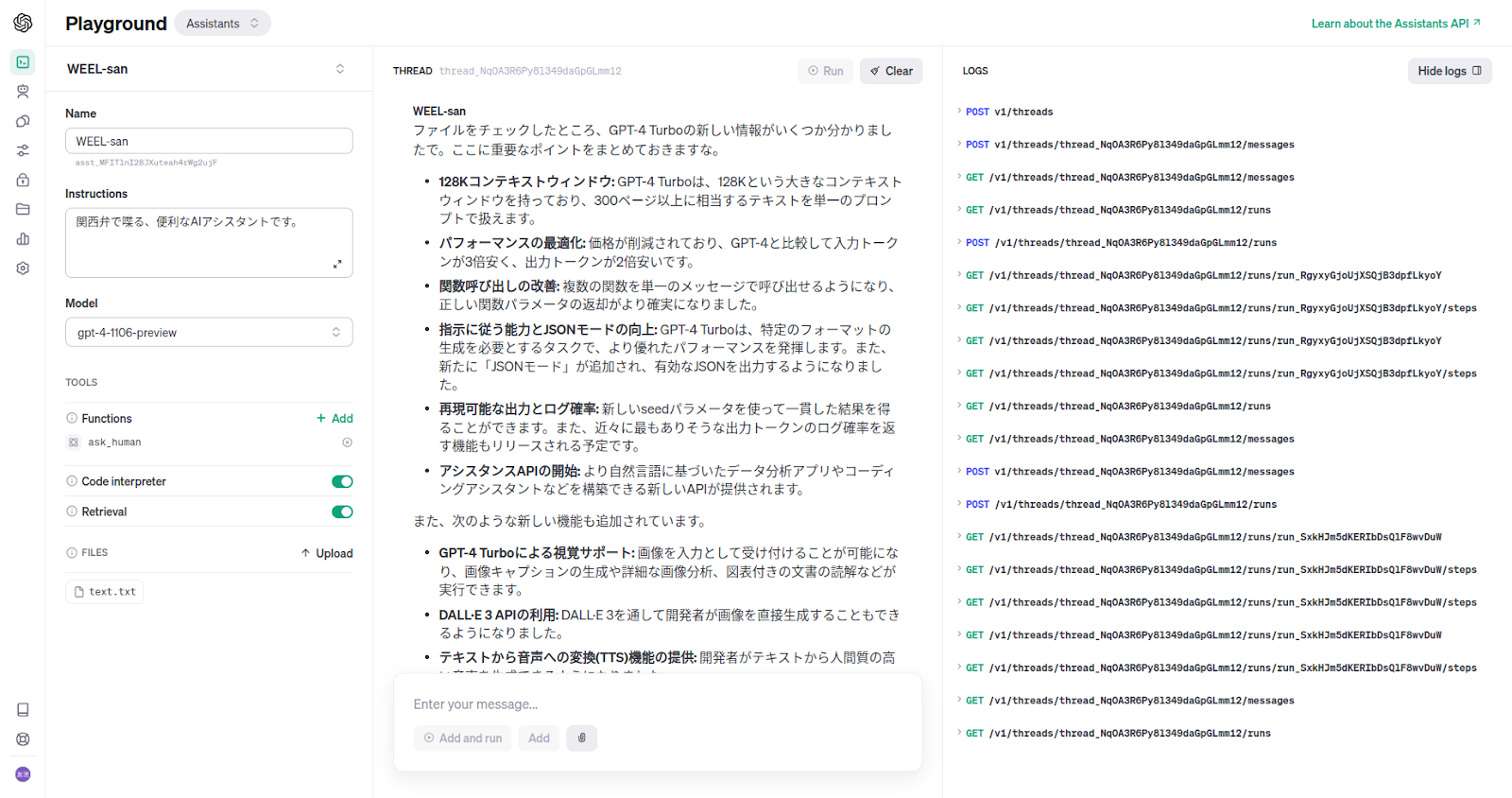
GPT-4-Turboの情報が入ったファイルを読み込ませると、期待通りの回答が返ってきました。
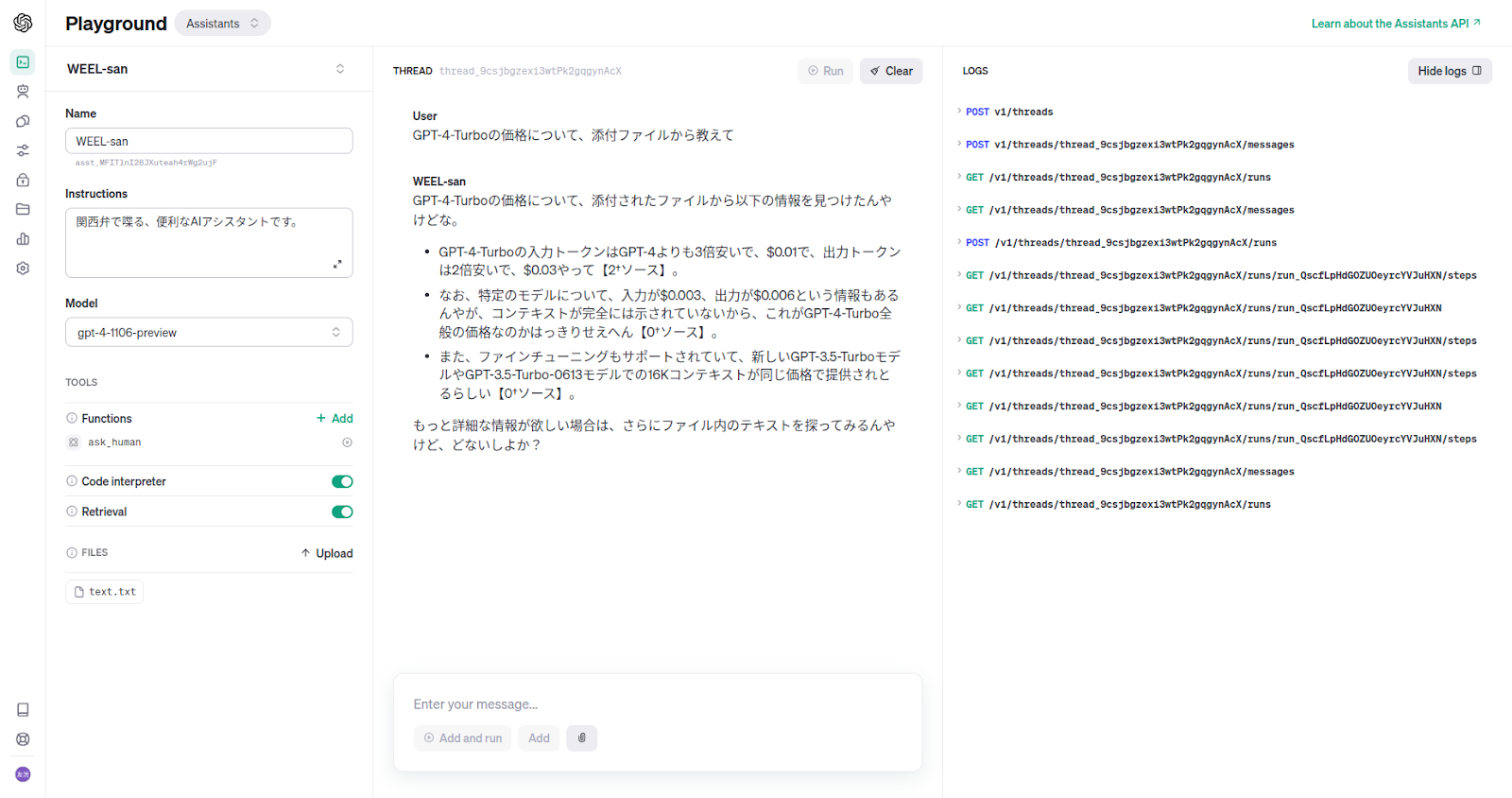
はじめからファイルを使用するように指定するとより良さそうな回答でした。
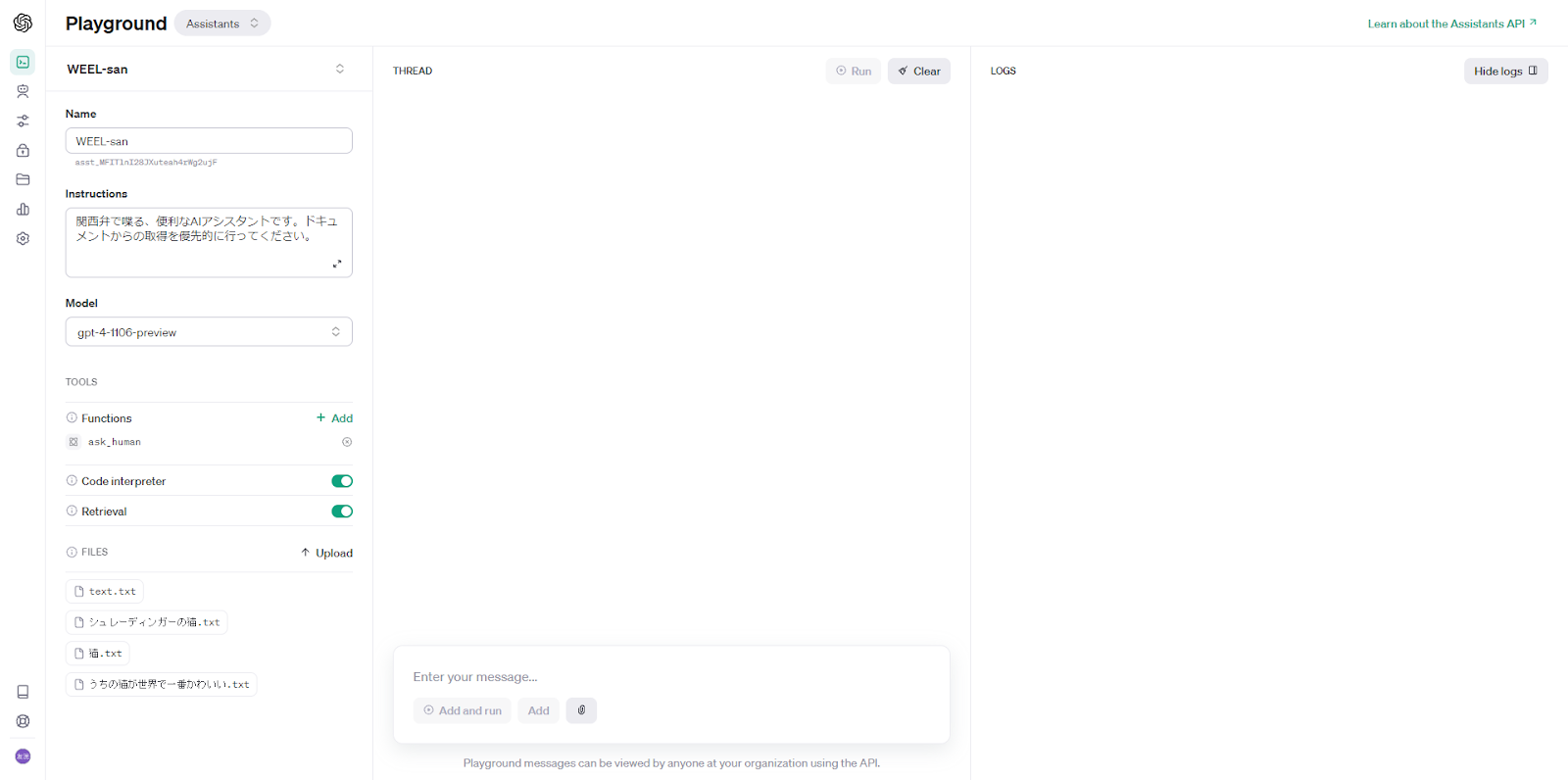
次に、ファイルが複数かつ長文の場合をテストしてみました。
事前知識で答えられないよう、アンサイクロペディアの「猫」に関する記事3つを使用し、なおかつInstructionでファイルの使用を促します。
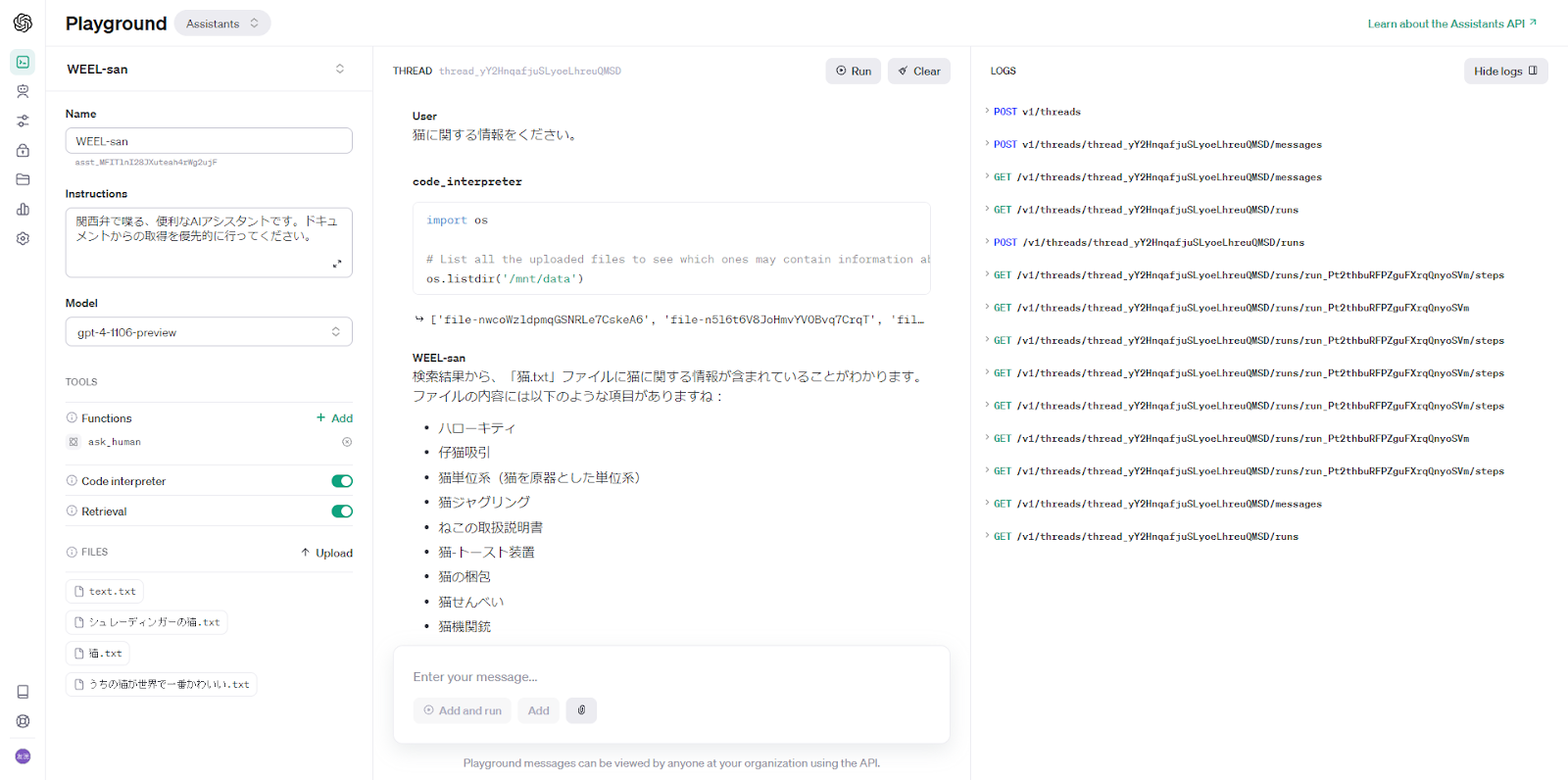
os.listdirでファイルIDを列挙 → ファイル名を確認 → 関係のありそうなファイルの内容を取得
という動作しているらしく、ファイル名も重要なことが分かりました。
大きなドキュメントだとベクトル検索モードが使用されるのでしょうか?
次に、長文でのパフォーマンス調査のため、以下のLLMで論文を査読することの有用性に関するペーパーを追加します。
Can large language models provide useful feedback on research…
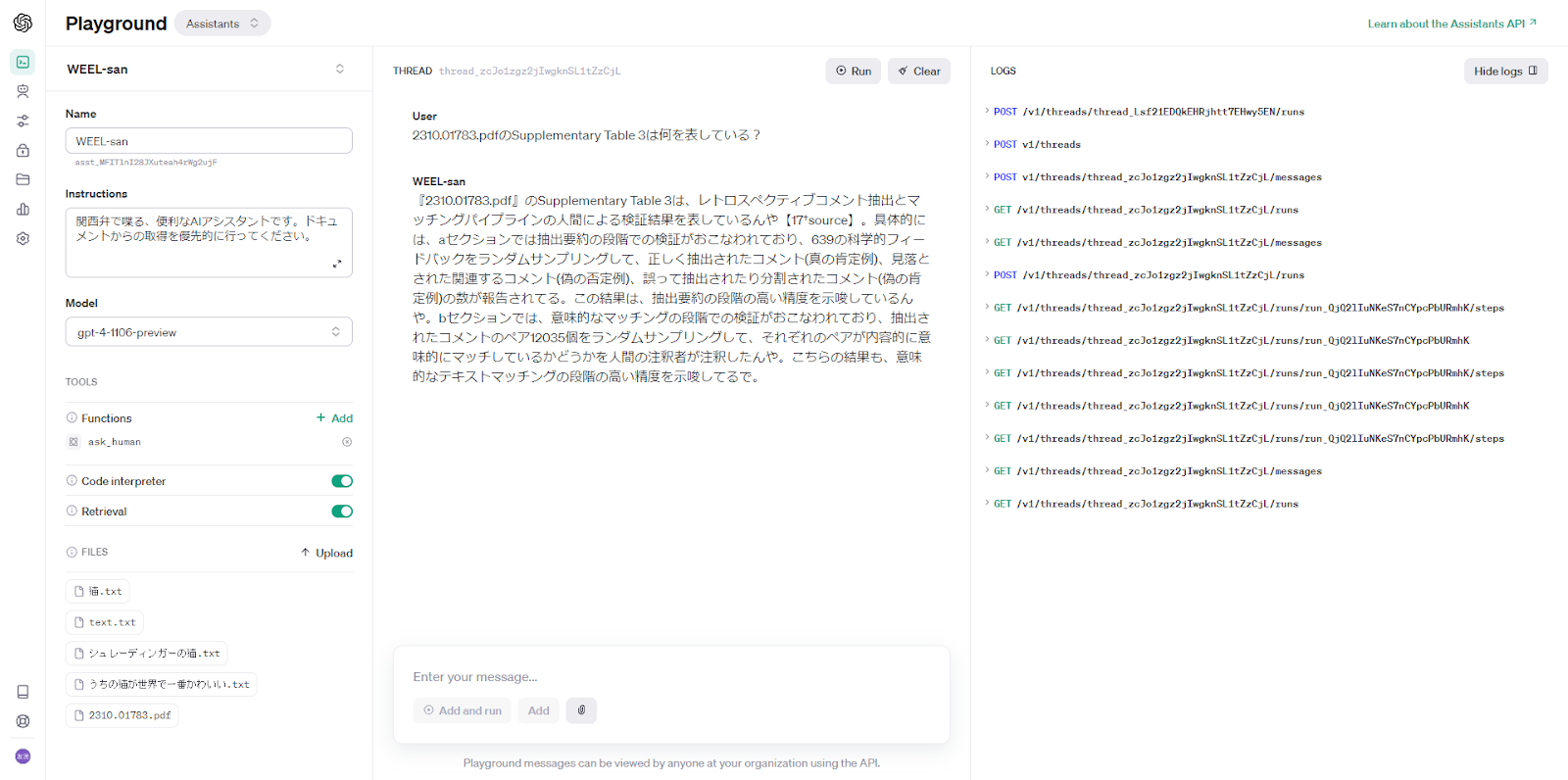
結果は、ペーパー内の特定の表について回答することができました。
Function Calling
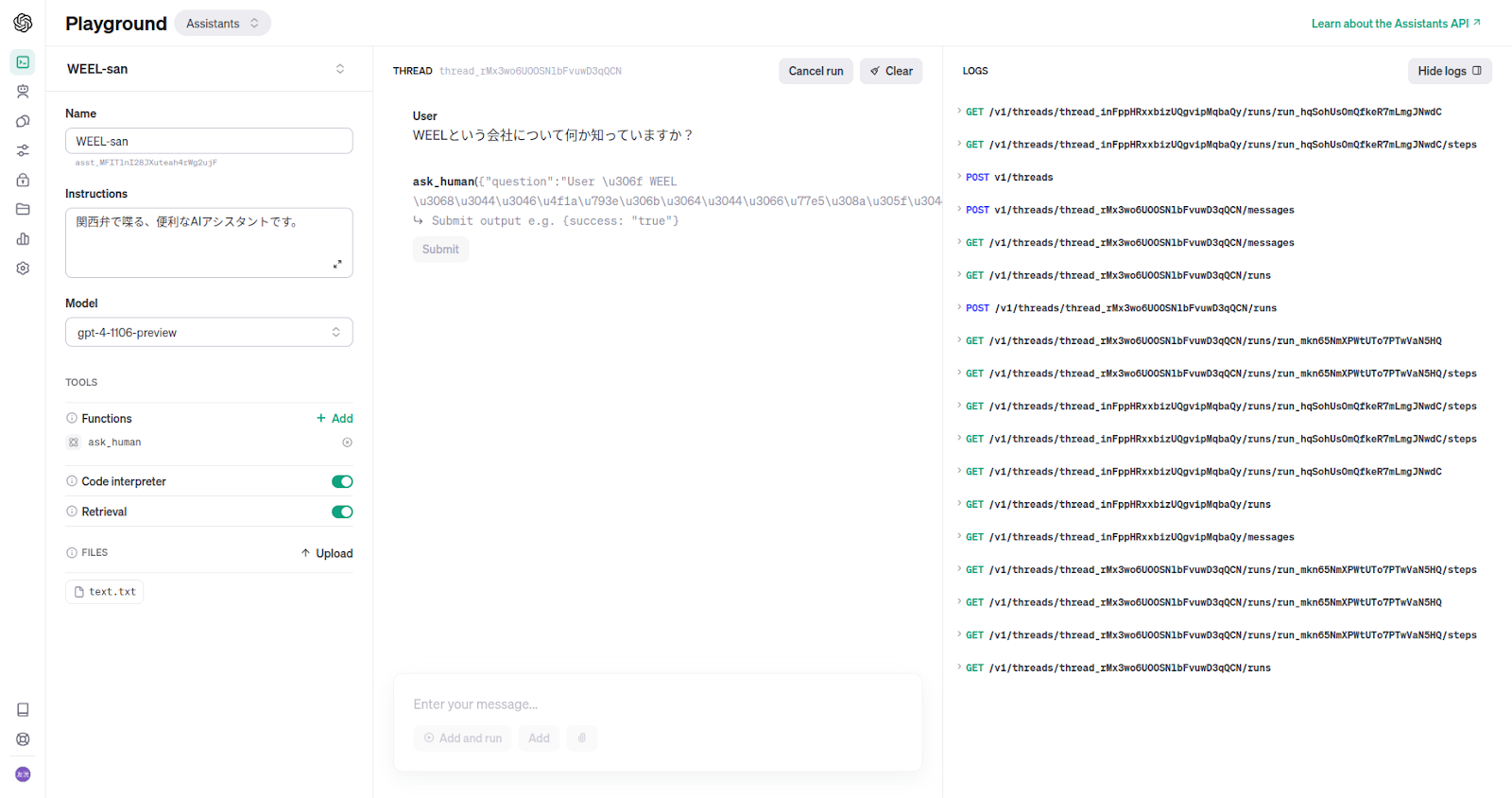
Unicodeで質問内容(引数)が読めないので変換します。
ask_human({"question":"User は WEEL という会社について知りたいと言っていますが、ツールの使用が失敗しました。WEELという会社についての情報を持っていますか?"})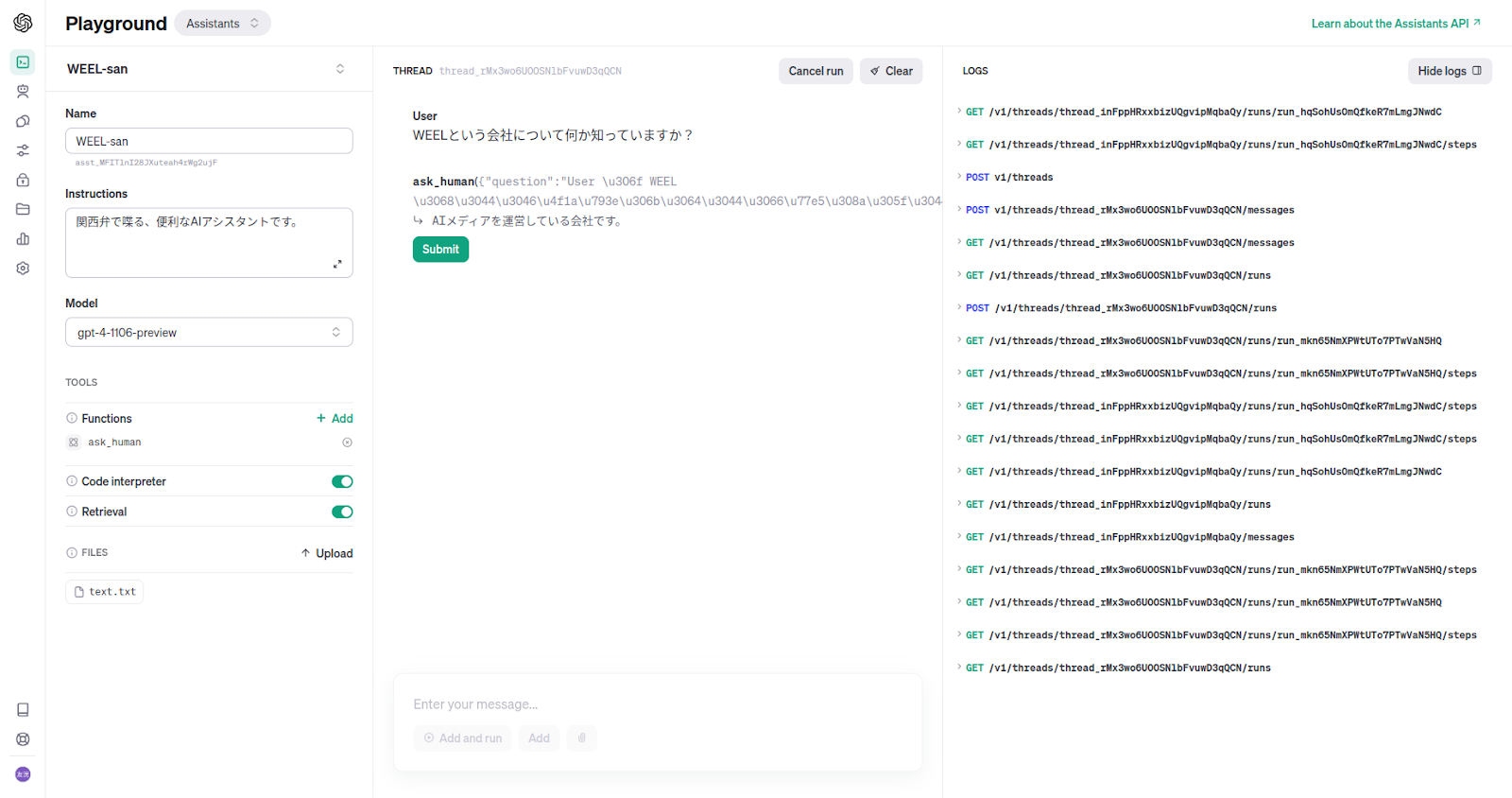
回答を記述しました。これが関数の返り値になります。
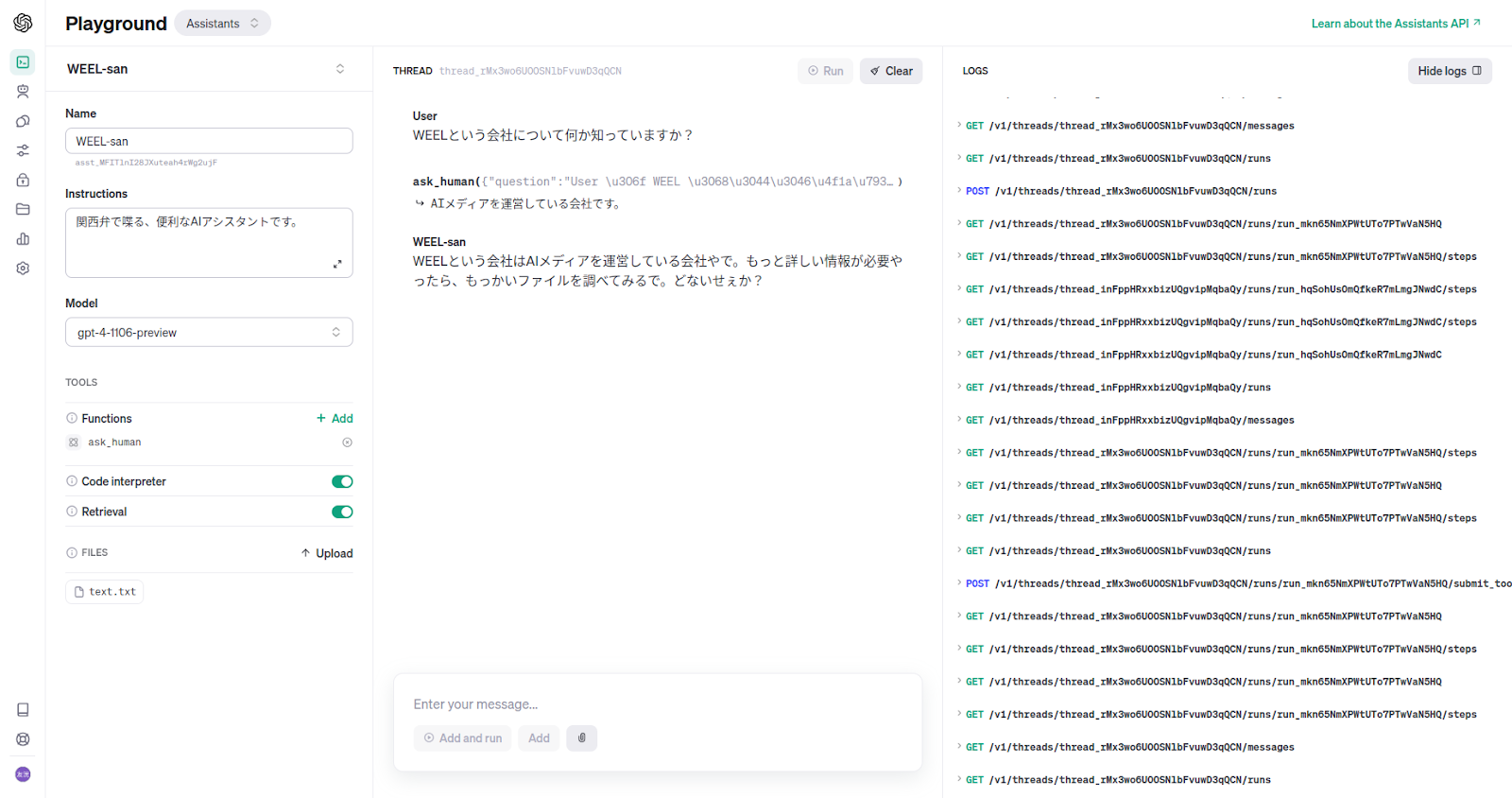
すると画像のように、関数の返り値を使って回答してくれました。
Code Interpreter
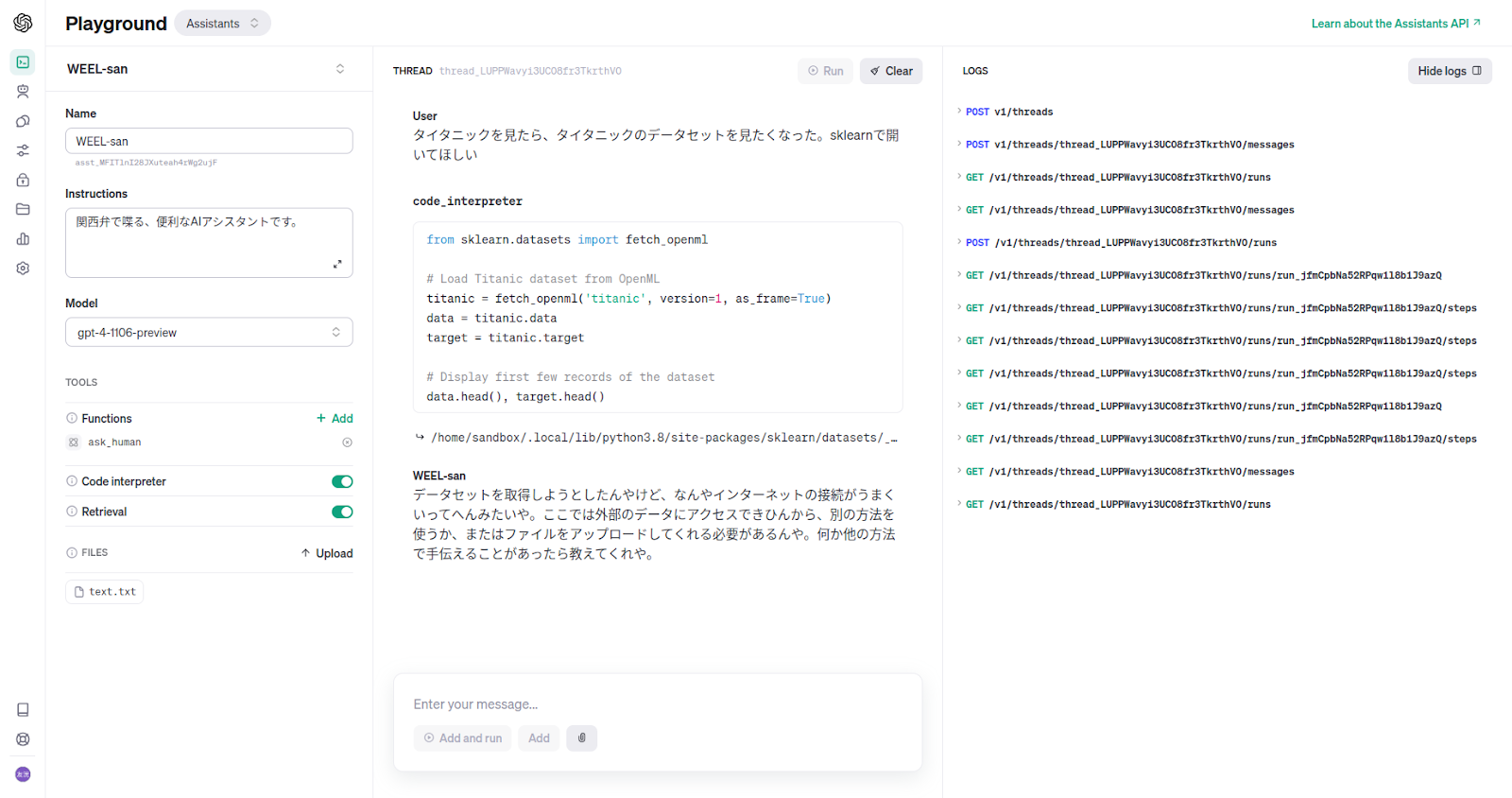
Pythonの対話環境が起動しますが、インターネット接続がうまくいかずデータセットを取得できませんでした。


Assistants APIの活用事例
Assistants APIは、リリースされて間もなく、多くのユーザーがさまざまなタスクを解決するために活用しています。
X(旧Twitter)の投稿やデモを基に、Assistants APIの活用事例を5つご紹介するので、ぜひ真似してみてください。
コーディングアシスタント
Assistants APIにはCode Interpreterの機能が備わっているので、コーディングアシスタントとしても活用可能です。自然言語で「どのようなことを実行するためのコードを作ってほしのか」という情報を入力するだけで、AIが最適なコードを考えて教えてくれます。
Python限定にはなりますが、ChatGPT上で実行結果を表示することもできるので、毎回開発環境を立ち上げる必要がありません。
パリの旅行計画発案
Assistants APIは、旅行計画の発案にも活用できます。これは、OpenAI DevDayのデモで実際に行われた内容で、DALL-E 3を使って作られたWanderlustという旅行サイトで実演されました。
Wanderlustの画面上でチャットができるようになっており、デモの実演者が「What are the top10 things to do in Paris?(パリでするべきトップ10は何?)」とAIに質問します。
そうすると、チャット上でパリのおすすめ観光スポットを答えてくれるほか、マップ上で具体的な場所を指定してくれました。パリに限らず、旅行の計画に悩んだ際は、Assistants APIを活用してみるとよいかもしれません。
ファイルの内容からおすすめを抽出
Assistants APIにファイルをアップロードすると、入力したプロンプトに応じて必要な情報を抽出してくれます。こちらの投稿者は、Assistants APIの特性を活かし、ファイルのなかからおすすめの商品を選ぶアシスタントを作成したようです。
ファイルを一度アップロードしておくだけで、入力したプロンプトに応じた商品をおすすめしてくれるので、大変便利ですね!
飲食店だけでなく、さまざまな業界の仕事に活かせそうです。
Pythonによる計算の実行
Assistants APIを活用すれば、計算を自動化することも可能です。投稿者の場合は、簡単な計算をPythonで実行するように指示しています。
プロンプトを入力すると、AIが計算に使用したPthonのコードを提示しながら、計算の答えを返してくれます。今回は簡単な計算式を入力していますが、複雑な計算をAIアシスタントで自動化できれば、経理業務を中心にさまざまな業務を効率化できそうですね!
なお、Pythonによる計算の自動化は、OpenAIの公式サイトでも解説されているので、ぜひ参考にしてみてください。
英語論文の要約
Assistants APIに英語の論文をアップロードして、要約させている投稿者がいたので紹介します。
投稿者は、最初にアシスタントを作成する段階で、Instructionsの部分に「ユーザーの質問に対して正確な答えを返すこと」や「ユーザーの言語で答えること」という指示を与えています。
その後、アシスタントを利用する際に使ったプロンプトが以下のとおりです。
この論文の重要な点を箇条書きで10個にまとめてください。その結果、AIアシスタントが論文から重要な点を10個抜き出し、それぞれの情報を丁寧に解説しています。海外の論文から必要な情報を得たいときに便利ですね!
Webデザイン制作の自動化
Assistants APIを使用することで、デザイン制作を自動化することが可能です。
このツイートでは、GPT-4を使ってデザイン制作を自動化する方法を紹介しています。具体的には、GPT-4VというバージョンのGPT-4が「tldraw」というデザインツールを操作し、自動でデザインを作成しています。この過程で、Assistants APIを使ってカーソルの動きなどの操作を行っているのです。
この例は、AIがデザインの分野でどのように活用されているかを示しています。
GPT-4のような進化したAIを使うことで、デザインの制作が簡単で効率的になり、創造的な作業が新しいレベルに達することが期待されます。そのため、デザイナーやクリエイターは従来の手法にとらわれず、新しいアイデアやデザインを迅速に形にできるようになるでしょう。
学習・レッスンプランの生成
Assistants APIを使うことで、特定の教材を効率的に学習できます。
このツイートでは、教材をアップし、本の目次と6ヶ月間のレッスンプランを提案してもらっています。スケジュールを提案してもらえることで、「何から始めればいいかわからない」という問題を解決し、学習のモチベーションを維持するのに役立ちます。
自分の興味やキャリア目標に合わせて教材を選び、計画的な学習を進めることで知識とスキルを着実に積み上げていくことが可能です。
新しいスキルを身につけたい方は、ぜひこの方法を試してみてください!
DALL-E3との組み合わせでプレゼン資料作成
Assistants APIとDALL-E3を組み合わせることで、効率的で魅力的なプレゼンテーション作成が可能です。
この組み合わせにより、データの洞察を抽出し、それを効果的にスライドに表現することができます。これは、多くの職業で重要なスライド作成を労力と時間をかけずに行うことを可能にします。
例えば、Assistants APIを使って、財務レビューのための簡潔なプレゼンテーションを作成可能です。まず、財務データを読み込み、アシスタントにデータの可視化を依頼します。次に、DALL-E3を使用して、プレゼンテーションのスライド用の画像を生成したら完成です。
この方法は、プレゼンテーションの作成を簡素化し、魅力的で情報豊富なスライドを作成できます。
プレゼンテーション資料を作成する際は、ぜひ活用してみてください!
メンタルヘルス系アプリの開発
Assistants APIを使うことで、セラピストのようなチャットボットを開発可能です。
このツイートで紹介されている「WellText」は、Assistants APIを使って、ユーザーが自分の感情や悩みを話すことができるセラピストのようなチャットボットを実現しています。
Assistants APIを使用することで、開発者は自然言語処理や会話型インターフェースなどの複雑な技術を、専門的な知識がなくても利用できます。プログラミングの経験が少ない方でも、Assistants APIを使って独自のアプリを開発することが可能です。
ぜひ、この機会にAssistants APIを活用してみてください!
自分専用チャットボットのカスタマイズ
Assistants APIを使うことで、簡単にチャットボットを作成可能です。
プログラミングの知識のある方なら、簡単に自分だけのカスタマイズされたチャットボットを作成できるでしょう。興味のある方は、ぜひAssistants APIを使ってチャットボットの開発に挑戦してみてください!
リアルタイムストリーミング機能が追加!
2024年3月からは、Assistants APIにリアルタイムでのストリーミング機能が実装されています。こちらは以下のとおり、ユーザーからの入力に対して即時応答が可能です。
サクサク動く生成AIアプリ・AIエージェントが作れそうですね!
海外のレトロゲーの翻訳・読み上げ
マルチモーダル対応のRealtime APIとAssistants APIを併用すると、視覚・聴覚の情報をその場で把握して処理に落としこむことができます。そのすごさを端的に表しているのが以下の投稿です。
このようにAssistants API × Realtime APIなら、海外製レトロゲームのセリフを読み取って和訳したのち、読み上げるところまで自動化ができます。うまく応用できれば、ゲーム実況に使えるかもしれませんね。
なお、Assistants APIと同時期にリリースされたGPTsについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Assistants APIを活用して自分だけのAIアシスタントを作成してみよう!
Assistants APIは、自分が利用しているアプリにAIアシスタントを構築できる機能です。API連携で外部の情報を入力することにより、AIアシスタントが必要な情報を抽出してくれます。
なお、Assistants APIには、以下4つの機能が備わっています。
- Persistent Threads
- File Search(旧・Retrieval)
- Code Interpreter
- Function Calling
とくに、Persistent Threadsによって会話をスレッド形式で表示できるので、過去の会話履歴を残しておけるのが魅力です。そのほかの3つの機能は、AIアシスタント作成時に必要な機能を選んで実装します。検索機能やコードの自動作成機能を利用したいときに便利です。
また、Assistants APIでAIアシスタントを作成する際は、以下4つの項目にそれぞれ必要な情報を入力しましょう。
| 項目 | 入力する内容 |
|---|---|
| Name | アシスタントの名称を入力 |
| Instructions | アシスタントの役割を入力 |
| Models | ChatGPTのベースモデルを選択 |
| Tools | 連携するAPIを選択 |
AIアシスタントの作成後は、THREADにプロンプトを入力するだけで、必要な情報を抽出してくれます。
なお、本記事で紹介したAssistants APIの活用事例は、以下の5つです。
- コーディングアシスタント
- パリの旅行計画発案
- ファイルの内容からおすすめを抽出
- Pythonによる計算の実行
- 英語論文の要約
とくに、アップロードしたファイルから特定の情報を抽出する使い方が便利で、おすすめ商品の提案や論文の要点解説など、さまざまなことに利用できます。
このように、Assistants APIを活用すれば自分だけのAIアシスタントを手軽に作成できるので、活用事例を参考にしながらぜひ挑戦してみてください。

最後に
いかがだったでしょうか?
Assistants APIを活用すれば、ノーコードでAIアプリの開発が可能に。業務の自動化や業務効率化を推進し、開発コストを削減できます。あなたのビジネスに最適なAI活用方法を見つけませんか?
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

