
【4M-21】Appleが開発した「画像系タスクの便利屋さん」

WEELメディア事業部LLMリサーチャーの中田です。
6月13日、多様な画像モダリティを扱えるマルチモーダルモデル「4M-21」を、Appleが公開しました。
画像を入力するだけで、入力画像の深度やキャプション、物体検出など様々なタスクを一度に実行できるのです!
この記事では、4M-21の技術や簡単な使い方をご紹介します。「4M-21を使えば具体的にどんなことができるのか」をイメージしたい方は、「4M-21を実際に使ってみた」のセクションまで飛んでもらってもOKです。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
4M-21は全ての画像系タスクに対応したマルチモーダルAI
4M-21は、画像に関する多様なモダリティを統合的に扱うことができる、Apple社の汎用的なAny-to-Anyモデルです。
Any-to-Anyとは、多様なモダリティを入力として受け付け、多様なモダリティで出力できる、マルチモーダルモデルを指します。
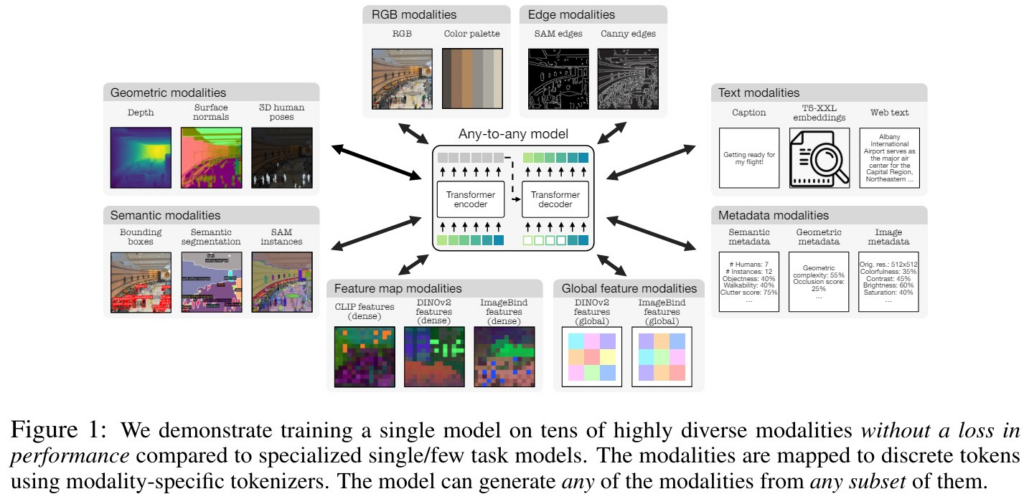
4M-21は、21種類もの画像のモダリティに対応しており、例えば以下のようなモダリティを扱えます。
- RGB画像
- 表面法線
- 深度
- 人物の3Dポーズ
- セマンティックセグメンテーション
- バウンディングボックス
- SAMインスタンス
- エッジ
- DINOv2やImageBindの特徴量
- メタデータ(画像サイズなどの、画像に関する基本情報)
- 入力画像の内容を説明したテキスト(画像に何が映っているのか)
また、4M-21はモダリティ間の変換が可能であり、例えばRGB画像からセグメンテーションマップを生成できます。さらに、任意のモダリティをクエリとして、他のモダリティを検索できるため、例えば、テキストからRGB画像を検索したり、深度マップからRGB画像を検索したりできるのです。

他にも、メタデータやカラーパレットなどを条件として与えることで、画像生成をコントロールできます。例えば、明るさや彩度を指定して、より自分好みの画像を生成できるのです。

研究背景と課題
Pix2Seq、OFA、4M、Unified-IOなどの先行研究では、異なるモダリティの入力と出力を共通の表現空間に変換することで、単一のモデルで複数のモダリティやタスクを扱っています。具体的には、異なるモダリティを離散トークンのシーケンスに変換し、標準的なTransformerアーキテクチャを学習させています。
しかし、これらの先行研究では、比較的少数のモダリティで学習されているため、モデルが解くことができるタスクに限りがありました。さらに、モダリティの数を増やすと、モデルの性能が低下するという課題もありました。
本研究では、マルチモーダルマスク事前学習スキームをもとに、21種類のモダリティで学習することでモデルの性能を向上させ、より多様な画像系モダリティ・タスクを扱えるようにしています。
実験結果
表面法線や深度推定、セマンティックセグメンテーションなどを含む様々なタスクで、4M-21の性能を定量的に評価した結果、4M-21はほぼ全てのタスクにおいて、既存モデルよりも高い性能を発揮しています。
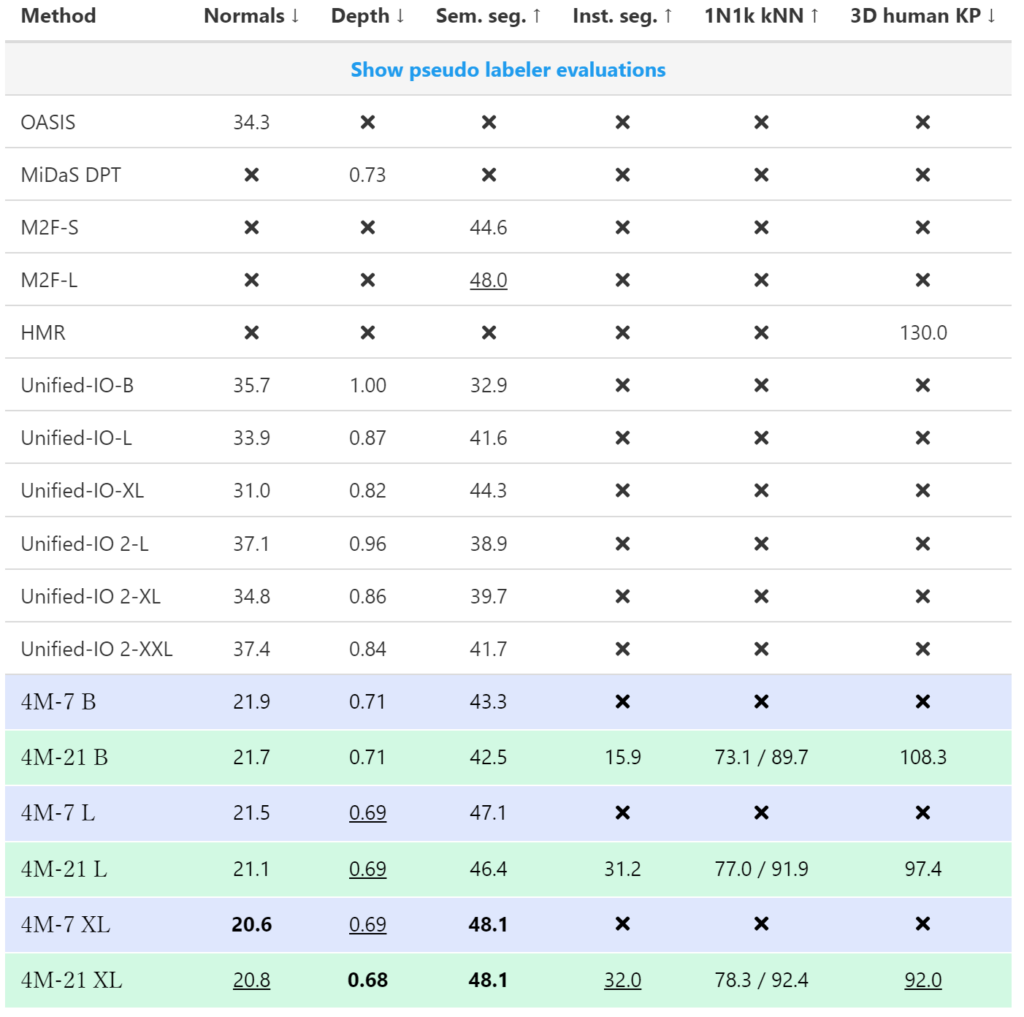
また、以下のセマンティックセグメンテーションのタスクにおける比較では、4M-21がUnified-IOよりも正しくセグメンテーションしているように見えます。
なお、スマホでも操作できるApple小型オープンLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

4M-21の手法
4M-21は、モダリティを離散トークンのシーケンスにトークン化することで、テキスト、画像などを含む多様なモダリティに対して、単一のTransformerエンコーダ・デコーダアーキテクチャを学習しています。その際、トークンのランダムなサブセットを、別のサブセットにマッピングしています。4Mの学習スキームの概要については、以下のアニメーションが分かりやすいです。
また、各モダリティは以下の4つのtokenizerのどれかをによって処理されます。
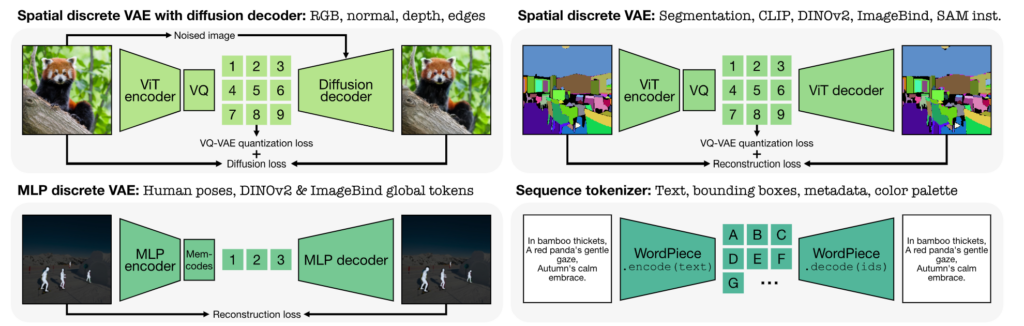
- VQVAE + Diffusion:解像度が高い画像用のエンコーダ(RGB画像, normal, depthなどをエンコード)
- VQVAE:解像度の低い画像のモデルの出力画像に適用するエンコーダ(Segmentationなどをエンコード)
- VQVAE MLP:MLPを適用したVQVAE
- Sequence Tokenizer:WordPieceという手法で順序付きデータを離散値に変換する方法

4M-21の使い方
GitHubのリポジトリを参考に、簡単な4M-21の使い方を解説します。
まずは、以下のコマンドを実行して、リポジトリをクローンし、condaの仮想環境の構築とライブラリのインストールをしましょう。
コマンドはこちら
git clone https://github.com/apple/ml-4m
cd ml-4m
conda create -n fourm python=3.9 -y
conda activate fourm
pip install -e .次に、以下のコードを実行することで、画像タスクを実行できるとのことです。
実行コードはこちら
from fourm.demo_4M_sampler import Demo4MSampler, img_from_url
sampler = Demo4MSampler(fm='EPFL-VILAB/4M-21_XL').cuda()
img = img_from_url('https://storage.googleapis.com/four_m_site/images/demo_rgb.png') # 1x3x224x224 ImageNet-standardized PyTorch Tensor
preds = sampler({'rgb@224': img.cuda()}, seed=None)
sampler.plot_modalities(preds, save_path=None)また、HuggingFaceのデモも用意されています。
なお、Appleのスマホ専用のマルチモーダルAIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

4M-21を実際に使ってみた
HuggingFaceのデモを用いて、入力のRGB画像から、ほぼ全ての画像モダリティを予測させてみたいと思います。
ここで用いる入力のRGB画像は、以下の通りです。

春の大阪城の写真ですね。
この画像を用いて、様々な画像タスクを解かせてみようと思います。結果は以下のように出力されます。
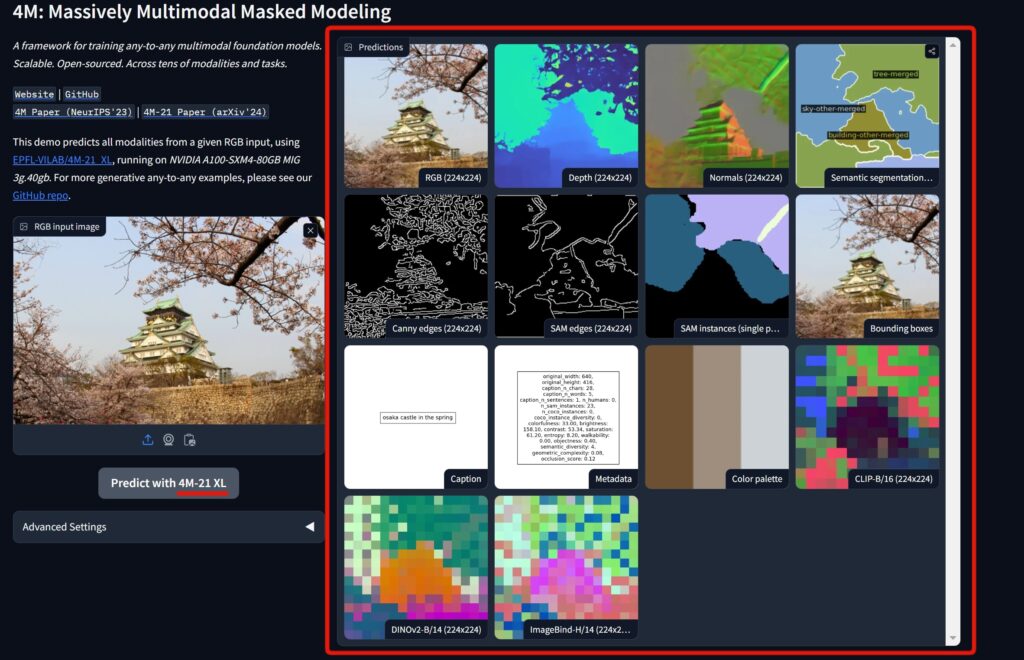
13個のモダリティの予測が出力されたので、その中から「Depth」「Semantic segmentation」「Caption」をピックアップして、1つずつ詳細を見ていきましょう。
Depth結果

こちらの進度推定の結果は、ある程度上手くいっていると言えるでしょう。
画像中の空の部分は視点から遠いため淡く、手前の木は近いため濃く映っているのが分かります。
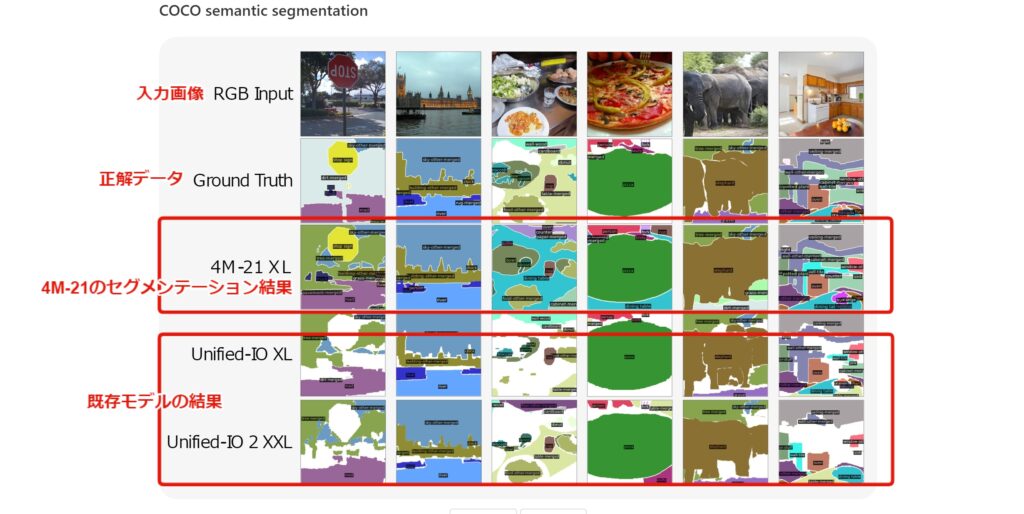
Semantic segmentation結果
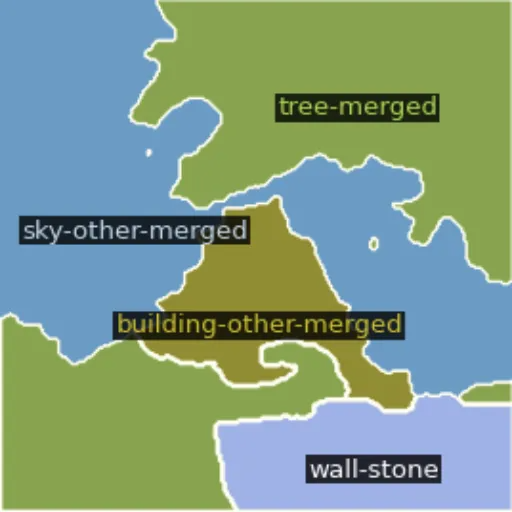
「城壁」「木」「空」「城」のラベルとその領域を、上手く分割できています。
Caption結果

「osaka castle in the spring(春の大阪城)」と出力されているので、正しく予測できていると言えるでしょう。
なお、Appleのマルチモーダル大規模言語モデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

4M-21は画像タスクにおける何でも屋さん
本記事では、Appleが開発した画像系のマルチモーダルモデル「4M-21」について解説しました。
今後の画像生成や画像認識など、様々な画像系タスクにおいて、大いに活用が期待されるでしょう。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

