
【Audio2Photoreal】Meta開発の音声入力だけで一瞬でAIアバターを作成できるツールを使ってみた

- 音声入力から顔・体・手の動きを同時生成するAIモデル「Audio2Photoreal」
- 高いリアリズムと多様性を実現し、他手法を上回る生成性能
- 研究・個人利用は自由だが、商用利用にはライセンス交渉が必要
FacebookのMeta社とUCバークレーが、音声入力からアバターを生成できる「Audio2Photoreal」を公開しました。このAIツールを使うことで、音声を入力するだけで、その音声を喋るアバターを生成できるんです…!
GitHubでのスター数は、2,800を超えており注目されていることが分かります。将来のゲーム開発や、メタバースでのアバター生成にも活用できそうです。
この記事ではAudio2Photorealの使い方や、有効性の検証まで行います。本記事を熟読することで、Audio2Photorealの凄さを実感し、普通の画像生成には戻れなくなるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Audio2Photorealの概要
Meta社とUCバークレーが公開した「Audio2Photoreal」は、音声からアバターを生成できるAIモデルです。会話中の音声入力をもとに、顔・体・手の動きを同時に生成するフレームワークとなっていて、内部的には、音声データを入力として、「ベクトル量子化(VQ)」に基づくトランスフォーマーが時間軸を粗く捉えたガイドポーズ(コアな骨格動作)を生成し、次に拡散モデルを用いてその間を補完する細かな動きを生成します。
この粗い動き+微細動きの階層的な仕組みにより、指差しや驚いた表情など多様なジェスチャーが生み出されます。
また、顔の表情生成は音声条件付きの拡散モデルで行われ、音声のイントネーションや感情に即した細かな表情が再現されます。これらの動きは3Dレンダラーによってフォトリアルなビデオ映像に変換され、生成されたアバターは表情豊かな会話相手として機能します。
さらに、Audio2Photorealでは新たに複数視点から会話を撮影した大規模データセットも構築されており、研究発表とともにこのデータセットや学習済みモデル、コードが一般公開されています。


Audio2Photorealの性能
Audio2Photorealの生成性能は高く評価されています。研究チームの実験では、既存の手法と比較して、生成される動きの「多様性」と「リアリズム」の両方で優れた結果を残しています。具体的には、Frechet Gesture Distanceなどの評価指標において最も低いスコアを記録しつつ、ジェスチャーの多様性では最も高い値を達成しています。
これは、ランダムサンプリングや既存の類似手法に比べて、同じ音声に対し多彩かつ自然な動作を生み出していることを意味します。実際のユーザーテストでも、Audio2Photorealの生成結果はベースライン手法を上回っており、他の研究ではメッシュ表示では認識が難しかった細かい表情や動きも忠実に表現できています。
Audio2Photorealのライセンス
Audio2Photorealのコードとデータセットは、Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)で公開されています。この非商用ライセンスにより、研究や個人利用においては自由に使用・改変・共有できますが、商用利用は禁止されています。ライセンス条件を整理すると以下の通りです。
| 利用形態 | 可否 |
|---|---|
| 商用利用 | ❌️ |
| 改変 | ⭕️ |
| 再配布 | ⭕️ |
| 特許利用 | ❌️ |
| 私的利用 | ⭕️ |
このように、商用利用は禁止されている点に注意が必要です。研究や個人利用は問題ありませんが、企業での商用利用には別途ライセンス交渉が必要となる可能性があります。
また、CCライセンスでは特許権の取り扱いについて明記されていないため、実際の展開にあたっては関連特許に留意する必要があります。
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Audio2Photorealの料金体系
Audio2Photorealはオープンソースであるため、誰でも無料で利用可能です。
全ての基本機能が無料で提供されているため、興味がある開発者や研究者は気軽に試すことができます。ただし、前述の通り、商用利用はライセンス上禁止されている点に留意が必要です。企業などで商用展開を検討する場合は、Meta社への問い合わせや別途契約によるライセンス許諾が必要になる可能性があります。
なお、Metaの音声生成AIについて知りたい方はこちらの記事をご覧ください。

Audio2Photorealの使い方
今回は、Google ColabのT4を使用しました。以下のGoogle Colabページに、簡単なチュートリアルが載っています。
まず、以下のコードを実行して、必要なライブラリのインストールを完了させましょう。
# Setup environment and install requirements
!git clone https://github.com/facebookresearch/audio2photoreal.git
%cd audio2photoreal/
!pip install -r scripts/requirements.txtいったんランタイムを再起動しましょう。次に、以下のコードを実行して、モデル等のダウンロードをしてください。
# download models, rendering assets, and prerequisite models respectively
!wget http://audio2photoreal_models.berkeleyvision.org/PXB184_models.tar
!tar xvf PXB184_models.tar
!rm PXB184_models.tar
!mkdir -p checkpoints/ca_body/data/
!wget https://github.com/facebookresearch/ca_body/releases/download/v0.0.1-alpha/PXB184.tar.gz
!tar xvf PXB184.tar.gz --directory checkpoints/ca_body/data/
!rm PXB184.tar.gz
!wget http://audio2photoreal_models.berkeleyvision.org/asset_models.tar
!tar xvf asset_models.tar
!rm asset_models.tar次に、以下のコードを実行して、pytorch3dをインストールしましょう。
# install pytorch3d
import sys
import torch
pyt_version_str=torch.__version__.split("+")[0].replace(".", "")
version_str="".join([
f"py3{sys.version_info.minor}_cu",
torch.version.cuda.replace(".",""),
f"_pyt{pyt_version_str}"
])
!pip install fvcore iopath
!pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/{version_str}/download.html次に、以下のコードを実行して、Trueになることを確認してください
import torch
torch.cuda.is_available()Trueであれば、以下のコードを実行すると、次のようなデモ画面に移ります。
!python -m demo.demo
Audio2Photorealを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.9
■必要なパッケージ
CUDA 11.7
gcc/++ 9.0 for pytorch3d


Audio2Photorealを実際に使ってみた
先ほどのデモページで、以下の音声ファイルを入力に使ってみようと思います。
すると、以下のような結果に、、、
おっと、これは本物の人間さながらのアバターが生成されました!
ただ、これを利用すれば、今よりも精巧なフェイク動画が作れてしまうんじゃないでしょうか、、、
なお、日本語の発音が完璧な音声生成AIについて知りたい方はこちらの記事をご覧ください。

Audio2Photorealの推しポイントであるアバター生成能力は本当なのか?
なぜAudio2Photorealが、リアルなアバターを生成できるのかについては、以下の論文に詳しく書かれています。
この研究では、まず人間の話す音声を入力として使用し、この音声情報からアバターの動きを決定します。

特に、口の動きは事前に訓練されたリップレグレッサーを用いて予測し、顔の表情を拡散モデルを使用して生成します。そうして生成されたアバターの「体の動き」と「顔の表情」を組み合わせることでアバターが動くのです。

提案モデルは、既存のメソッドよりも高い「リアリズム」と「多様性」を実現しています。以下の表は本研究における精度比較を表すもので、一番上の行が「精度指標」、一番左の列が「各モデル」を表します。精度指標の矢印に関してですが、「↓」は「数字が低ければ、精度が高いこと」を表し、「↑」は「数字が高ければ、精度が高いこと」を表します。
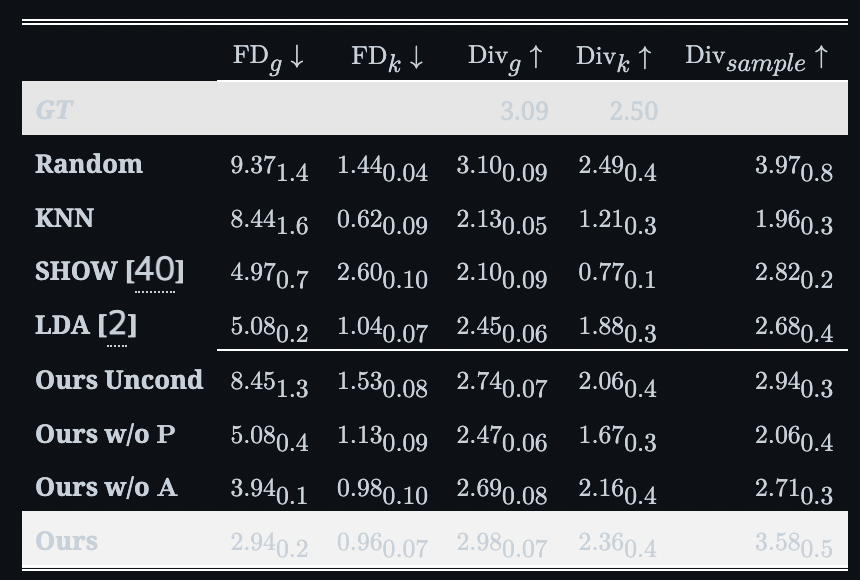
この表の一番下の「Ours(本研究のモデル、つまりAudio2Photoreal)」を見ても、ほぼすべての指標において、他のモデルよりも高いことが分かります。
特に、顔の表情と体の動きが音声に同期しており、会話の流れに沿った自然な動きが生成可能なのです。
まとめ
Meta社とUCバークレーが公開した「Audio2Photoreal」は、音声からアバターを生成できるAIモデルです。例えば、音声入力から全身アバターを生成したり、そのアバターの表情を表現したりできます。Audio2Photorealを応用すれば、ゲーム開発やメタバースなど、仮想空間でイノベーションが起こるでしょう!
研究結果からも、既存のモデルよりも高い「リアリズム」と「多様性」を実現しています。
実際に試してみたところ、本物の人間さながらのアバターが生成されました!ただ、この技術を悪用したフェイク動画には、さらなる注意が必要になるでしょう。
数年後には、グラセフのようなリアルなアバターを、誰でも作れるようになっているのかもしれないですね。

最後に
いかがだったでしょうか?
Audio2Photorealのような音声×アバター生成AIは、顧客体験や業務効率を大きく変革します。御社の事業領域にどう活用できるか、具体的に検討してみませんか。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


