
【Consistency Decoder】OpenAIが開発、DALLE-3に搭載されている高速画像生成AIモデル

皆さん、Consistency Decoderをご存知ですか?Stable Diffusionのデコーダーとして機能し、従来よりも画像生成の精度やスピードを高めてくれるんです!
先日のDavDayアナウンスの中で、OpenAIによって公開されたものです。GitHubでも1.6kスターを獲得しており、あのChatGPTのDALL-E 3にも搭載されているんです。
なんでも、100枚の画像を約7分で生成できるのだとか。
では、Consistency Decoderの使い方や、実際に使ってみた感想、最後には従来のStable Diffusionとの比較をまとめています。
この記事を最後まで読むと、Consistency Decoderを重宝したくなるでしょう!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Consistency Decoderの概要
今回のConsistency Decoderは、あのStable Diffusionを改良するために作られたモデルです。
具体的には、以前のStable DiffusionのVAEデコーダーを、Consistency Decoderに取り換えたというものです。VAEデコーダーの場合だと、画像を生成するのに時間がかかるという問題点がありましたが、Consistency Decoderに換えることで、スピードを格段にアップさせることに成功しました。また、画像の鮮度や顔、直線など、品質も大幅に向上したそうです。
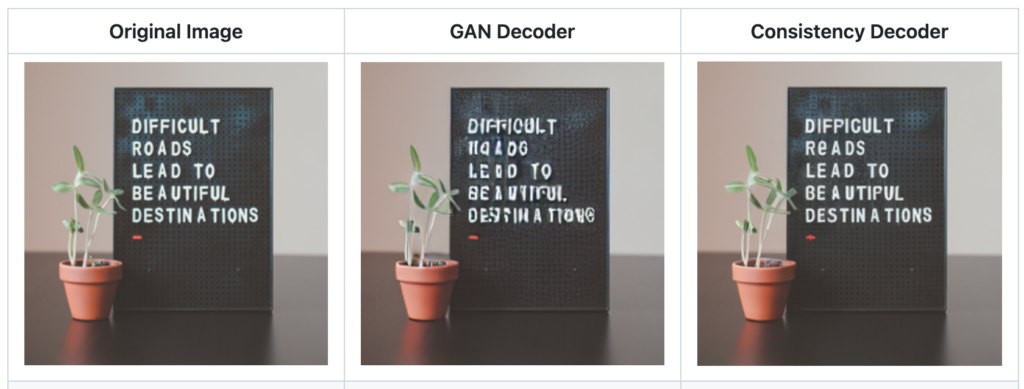
この画像は、左から元画像、GAN Decoderの場合、Consistency Decoderの場合の、生成された画像です。GANと比べてみると、やはりConsistency Decoderの方がクオリティが高いことが分かります。
ちなみに、このConsistency Decoderは、ChatGPTのDALL-E 3にも用いられているそう。
Consistency Decoderは、GitHubでオープンソースとして公開されているので、ぜひ触ってみてください。

Consistency Decoderの料金体系
このモデルはOSSなので、誰でも無料で利用可能です。
なお、Stable Diffusion Web UIを倍速にできるNVIDIA製の神AIツールについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【TensorRT】Stable Diffusion Web UIを倍速にできるNVIDIA製の神AIツール!使い方〜実践まで
Consistency Decoderの使い方
今回は、Google Colabで使ってみます。
ここでは、以下の般若寺の画像を生成させてみようと思います。

まずは、以下のコードを実行して、ライブラリをインストールしましょう。途中で、ランタイムを再起動する必要があります。
!pip install git+https://github.com/openai/consistencydecoder.git
!pip install diffusers transformers次に、上記の画像を「hannyaji.jpg」として、アップロードしてください。その後、以下のコードを実行してください。
# https://zenn.dev/timoneko/articles/16f9ee7113f3cd
import time
import torch
from diffusers import StableDiffusionPipeline
from consistencydecoder import ConsistencyDecoder, save_image, load_image
def execution_speed(func):
"""
実行速度計測用のデコレータ
"""
def wrapper(*args, **kwargs):
start_time = time.perf_counter()
func(*args, **kwargs)
end_time = time.perf_counter()
run_time = end_time - start_time
print("実行時間" + str(run_time) + "秒")
return wrapper
# encode with stable diffusion vae
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, device="cuda:0"
)
pipe.vae.cuda()
decoder_consistency = ConsistencyDecoder(device="cuda:0") # Model size: 2.49 GB
image = load_image("hannyaji.jpg", size=(256, 256), center_crop=True)
latent = pipe.vae.encode(image.half().cuda()).latent_dist.mean
# decode with vae
@execution_speed
def CON():
sample_consistency = decoder_consistency(latent)
save_image(sample_consistency, "con-hannyaji.png")
CON()
#decode with gan
@execution_speed
def GAN():
sample_gan = pipe.vae.decode(latent).sample.detach()
save_image(sample_gan, "gan-hannyaji.png")
GAN()すると、GAN DecoderとConsistency Decoderそれぞれで、以下のような画像を生成してくれました。


Consistency Decoderの方が若干キレイですね。GANの方は、寺の一部が少し歪んでる?
ちなみに、実行時間は、以下の通りです。
- Consistency Decoder: 実行時間6.941886241999953秒
- GAN: 実行時間0.09443198999997549秒
しかし、GANの方が生成スピード速いですね。まあ、GANの方が速いのは納得できます。ただし、これでノーマル型のStable Diffusionの方が速いのであれば、「速さが推しポイントって噓じゃねえか」ってなりますね。
Consistency Decoderを実際に使ってみた
ここでは、以下の本物画像と同じものを、Consistency Decoderに生成させてみます。

人の顔とか作るの難しそうですよね。これと同じ画像をConsistency Decoderに作らせてみた結果が、以下の通りです。

かなり精度は高いですが、顔がすこし歪んでしまっているのが残念です。
生成速度は19.5秒でした
この結果を、次の「Stable Diffusionとの比較」で利用します!
Consistency Decoderの推しポイントである高速な画像生成は本当なのか?
ここでは、先ほどと同じタスクを、従来のStable Diffusionで試してみようと思います!
その際に、以下の2点に着目して、比較してみましょう。
- 画像の品質
- 生成速度
Stable DiffusionのImage-to-Imageで画像を生成するためのプロンプトとその結果は、以下の通りです。
Generate an image that closely resembles the input image, maintaining all its details, colors, and composition. Ensure the new image is as similar as possible to the original.
さすがStable Diffusion!ポージングや衣装、背景は完璧です。ただ、顔立ちは完全に別人ですね。
生成速度は14秒でした。これより、Consistency Decoderと通常のStable Diffusionの比較表は、以下の通りになるかと思います。
| Consistency Decoder | Stable Diffusion | |
|---|---|---|
| 画像品質 | 結構「人の顔」が歪んでいる | かなり精度が高いが、少しぼやけている |
| 生成速度 | 6.8秒 | 14.0秒 |
ちなみに、品質に関しては完全個人的な意見です。
やはり生成速度に関しては、Consistency Decoderの方が素晴らしいです!ただ、品質に関しては改善の余地ありといった感じでしょうか。
とはいえ、このあたりに関しては、実際に「Text2Image」で使う際に、ファインチューニングをあらかじめ行うことで、精度の向上が見込めそうです!
なお、生成AIの開発方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【生成AI×開発】AI担当者が気になる生成AIツール開発の情報まとめ
まとめ
Consistency Decoderは、あのStable Diffusionを改良するために作られたモデルです。
具体的には、以前のStable DiffusionのVAEデコーダーを、Consistency Decoderに取り換えたというもので、スピードを格段にアップし、品質も大幅に向上したそうです。ちなみに、このConsistency Decoderは、ChatGPTのDALL-E 3にも用いられているらしい。
GitHubでオープンソースとして公開されているので、ぜひ触ってみてください。
生成速度に関しては、Consistency Decoderの方が素晴らしいです!ただ、品質に関しては改善の余地ありといった感じでした。実際に「Text2Image」などで使う際には、あらかじめファインチューニングをした方が良さそうです!
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

