
【驚異の音声生成AI】Sesame AIのCSM-1Bとは?文脈を理解する次世代音声生成AIを徹底解説

- 文脈を考慮した音声生成が可能
- 話者変更可能
- 生成される音声は限りなく人に近い
2025年2月27日、これまでとは異なる新たな音声生成AIがSesame AIから登場しました!
新たにリリースされたCSM-1BはConversational Speech Modelで、テキストもしくは音声入力からRVQオーディオコードを生成します。
音声合成の弱点として、文脈を考慮した音声生成ができないことや機械的なやり取りになってしまう点がありました。しかし、CSM-1Bでは、文脈を考慮した音声生成が可能であり、特定の声にチューニングされていない分、さまざまな音声を生成することが可能です。
本記事では、CSM-1Bの概要から使い方についてお伝えをします。最後まで読むことでCSM-1Bについて理解が深まりますので、ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
CSM-1Bの概要
CSM-1BはSesame AIが2025年2月に新たにリリースした音声生成AI。モデルサイズは1.55BパラメータでLlamaをベースにしています。
これまでの音声モデルでは文脈に応じた応答ができない・機械的なやり取りになってしまうなどの点から実用性は低かったです。また、一定のトーンで感情の起伏がない話し方では、優れたユーザー体験にもなりません。
そこでSesame AIは声のトーンやピッチ、リズム、間を活用してより人間らしいやり取りを実現させ、ただのリクエスト処理ではなく、会話を通じて関係性をより深められることを目的にCSM-1Bを開発しました。
実際に聞いてみるのが一番わかりやすいと思います。Sesame AIのページに「Samples」というデモ音声があります。どれを聞いてもまるで人間が話しているかのようなやり取りです。
こちらの動画は私がdemoで話している時の様子です。実際には私は無言を貫いていますが、無言でいると「what’s up?」とこちらの反応を確認してきました。ちょっと怖いくらいですね。
CSM-1Bの特徴
CSM-1Bは入力されたテキストや音声からRVQオーディオコードを生成します。
Residual Vector Quantization(RVQ)オーディオコード
Residual Vector Quantizationはデジタル信号処理における高効率なデータ圧縮技術です。特にニューラルオーディオコーデックなどで活用されます。RVQでは段階的にデータを補正することでより少ない計算リソースでより高精度・高品質を実現。
また、CSM-1Bは特定の話者に特化したファインチューニングが行われていないベース生成モデルのため、特定の音声に限定されず、さまざまな話し方を生成できます。さらに、文脈を与えることで最適な音質を発揮し、より自然で相手の意図を理解した音声生成が可能。
一方で、CSM-1Bは音声生成に特化したモデルのため、テキスト生成はできず、テキスト生成を行う場合には別のLLMと組み合わせる必要があります。


CSM-1Bの性能
公式ページに性能評価が記載されています。
性能の記載では3つのモデルサイズを使っていると記載されており、モデルサイズはバックボーンとデコーダーのサイズによって1B、3B、8Bが用意されています。CSM-1BはおそらくTinyに該当すると考えられます。


上記はWord Error Rateで単語の誤り率を示しています。この性能は低い方が良いとされており、生成された音声や認識された音声が元のテキストとどれだけ一致しているかを示す評価です。
通常はGround Truthが実際の人間の発話や正解テキストを指すため、Smallの性能は実際の人間の発話や正解テキストと同等の性能を示すことになります。
次に話者類似度です。話者類似度は生成された音声と元の話者の音声がどれだけ似ているかを数値化したもの。

本物の音声が0.940でありSmallが0.938であるため、非常に高いスコアを達成しており、話者の音声と一致していることがわかります。TinyではなくSmallサイズのモデルではありますが、話者の声質を非常に正確に再現できていることを示しています。
次が同形異義語の精度と発音の一貫性です。
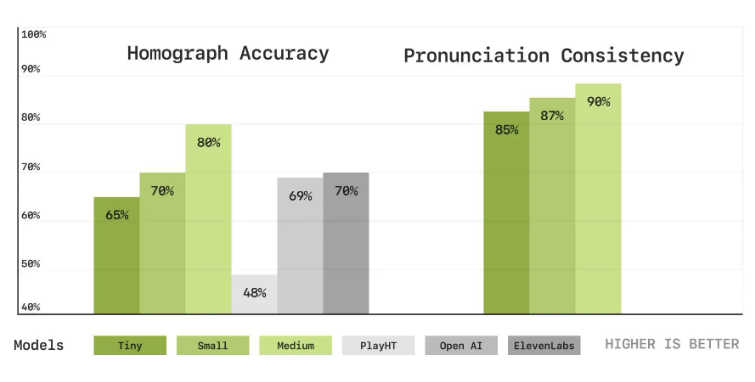
Homograph Accuracyは同じスペルだが、異なる発音を持つ単語を正しく発音できるかを評価します。こちらは高いほど性能が良いことを示します。
Mediumモデルが最も性能が高いですが、TinyでもOpenAIやElevenLabsの性能と近しいところまで来ています。
次のPronunciation Consistencyは発音の一貫性です。同じ単語が異なる文脈で使われた時、一貫した発音が維持されるかを評価します。こちらも高いほど性能が良いことを示します。
外部モデルの評価はなく、3モデルの評価のみですがいずれも80%後半の性能を持っており、非常に高いスコアを達成していると言えるでしょう。
最後に人の声との勝率です。
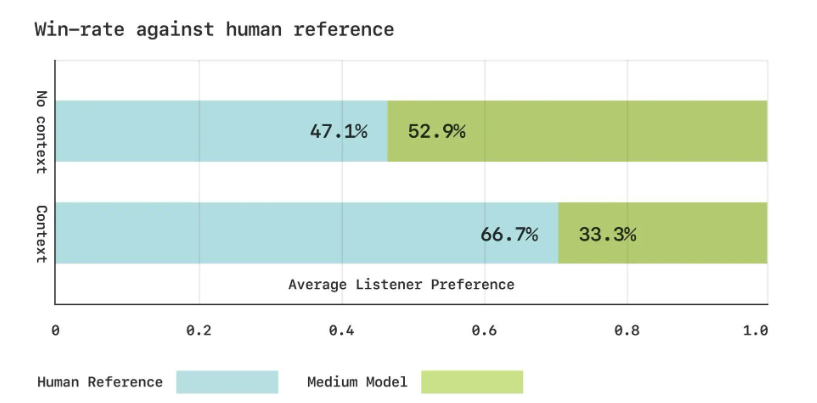
リスナーがモデルの声と人の声、どちらを好んだかを表しています。
文脈がない場合には、多くの人がモデルの声を選択しており、これは文脈がない場合にはモデルの声が人間の声を超える評価を得ていることを表します。
一方で文脈がある場合には、7割近くの人が人の声を選んでおり、文脈に応じた声を生成できるとはいえ、まだまだ人の声には及ばないことを示唆しています。
CSM-1Bのライセンス
CSM-1BのライセンスはApacheライセンス2.0です。
そのため、基本的には改変や再配布、商用利用が可能です。ただし、再配布時には元の著作権表示やライセンスの通知を行う必要があります。
また、Apache2.0ですが、いくつかの注意点がGitHubに記載されています。
- なりすましまたは詐欺
- 誤った情報または欺瞞
- 違法または有害な活動
上記3点は行わないように注意喚起されています。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、テキストや人間の声から音声をクローンするZyphraAI Zonos-v0.1について詳しく知りたい方は、下記の記事を合わせてご確認ください。
CSM-1Bの使い方
CSM-1BはHugging Faceに公開されているので、google colaboratoryで使うことができます。
■Pythonのバージョン
Python 3.10以上
■使用ディスク量
51.0GB
■GPU RAMの使用量
4.5GB
■システムRAMの使用量
4.2GB
■使用GPU:A100
■プラン:有料
まずはGitHubからクローンします。
!git clone https://github.com/SesameAILabs/csm.git
%cd csm
次に必要ライブラリのインストール。
!pip install -r requirements.txt
Hugging Faceの認証も必要です。APIキーまだ持っていない場合には、APIキーを取得しておきましょう。
from huggingface_hub import notebook_login
notebook_login()
次にモデルのロードと音声の生成です。
サンプルコードはこちら
import sys
sys.path.append("/content/csm")
from generator import load_csm_1b
import torchaudio
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
generator = load_csm_1b(device=device)
text = "Hello from Sesame AI. This is a test of the CSM-1B model."
audio = generator.generate(
text=text,
speaker=0,
context=[],
max_audio_length_ms=10_000
)
output_wav = "output.wav"
torchaudio.save(output_wav, audio.unsqueeze(0).cpu(), 16000)音声出力はこちら
from IPython.display import Audio
Audio("output.wav")実際に生成された音声はこちらです。適切にテキストを読み上げてくれていることがわかりますね。
CSM-1Bで話者の声やテンポを変更できるか検証
CSM-1Bでは文脈に応じた音声の生成が可能とのことなので、話者の声やテンポを変えられるか色々検証してみたいと思います。
speakerパラメータの変更
speakerのパラメータを変更すれば話者も変わるはずなので、for文で20話者まで生成してみました。
サンプルコードはこちら
import sys
sys.path.append("/content/csm")
from generator import load_csm_1b
import torchaudio
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
generator = load_csm_1b(device=device)
text = "Hello from Sesame AI. This is a test of the CSM-1B model."
for i in range(20):
print(f"Generating audio for speaker {i}")
audio = generator.generate(
text="Hello from Sesame AI. This is a speaker test.",
speaker=i,
context=[],
max_audio_length_ms=10_000
)
output_wav = f"output_speaker_{i}.wav"
torchaudio.save(output_wav, audio.unsqueeze(0).cpu(), generator.sample_rate)話者の限界がいくつまでなのかGitHubにも記載されていなかったので、どこまで話者を変えられるかぜひ試してみてください。
speaker4と19のサンプルはこちらです。だいぶ変わりますね。
こちらはspeaker4です。
こちらはspeaker19です。
文脈を与える
次に文脈を与えてみます。下記コードの「context」に過去の音声もしくはテキスト情報を渡し、文脈を考慮して音声を生成してもらいます。
サンプルコードはこちら
from generator import Segment
speakers = [0, 1, 0, 0]
transcripts = [
"Hey, how are you doing?",
"Pretty good, pretty good.",
"I'm great.",
"So happy to be speaking to you."
]
audio_paths = [
"output_speaker_1.wav",
"output_speaker_19.wav",
"output_speaker_2.wav",
"output_speaker_4.wav",
]
def load_audio(audio_path):
audio_tensor, sample_rate = torchaudio.load(audio_path)
audio_tensor = torchaudio.functional.resample(
audio_tensor.squeeze(0), orig_freq=sample_rate, new_freq=generator.sample_rate
)
return audio_tensor
segments = [
Segment(text=transcript, speaker=speaker, audio=load_audio(audio_path))
for transcript, speaker, audio_path in zip(transcripts, speakers, audio_paths)
]
audio = generator.generate(
text="Hello from Sesame AI. This is a test of the CSM-1B model.",
speaker=1,
context=segments,
max_audio_length_ms=10_000
)
torchaudio.save("audio.wav", audio.unsqueeze(0).cpu(), generator.sample_rate)文脈を与えて生成した音声は下記です。ちょっと違いが僕には理解できませんでした。生成している音声は一つ前の検証で生成したものと同じにしています。
日本語で音声を生成する
ここまでで話者変更と文脈の有無を英語でやってきましたが、最後に日本語の音声を合成できるか検証してみます。
サンプルコードはこちら
import sys
sys.path.append("/content/csm")
from generator import load_csm_1b
import torchaudio
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
generator = load_csm_1b(device=device)
text = "こんにちは。私はAIモデルです。何かお手伝いすることはありますか?"
audio = generator.generate(
text=text,
speaker=0,
context=[],
max_audio_length_ms=10_000
)
output_wav = "output.wav"
torchaudio.save(output_wav, audio.unsqueeze(0).cpu(), 16000)音声の生成自体はできますが、言葉として通じる内容のものではありませんでした。
CSM-1Bの対応言語については、明言されていませんがGitHubには以下のように記載されています。
Does it support other languages?
The model has some capacity for non-English languages due to data contamination in the training data, but it likely won’t do well.
日本語訳:そのほかの言語も対応していますか?
非英語に対するある程度の適応能力はあるが、うまくいかない可能性が高いです。
上記のことから、おそらく英語のみが実用レベルと考えられます。
英語だけになってしまいますが、流暢な発音でテキストを読み上げてくれるのでリスニングの勉強として活用することができるかもしれませんね。
なお、自然な音声と多言語対応の音声生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではCSM-1Bの概要から使い方について解説をしました。実用的なのはおそらく英語だけですが、生成された音声は人が喋っていると勘違いしてしまうくらいレベルの高い音声が生成されました。
英語に限って言えば、eラーニングの教材として使ってみたり、アクセシビリティとして音声読み上げとして活用ができるかもしれませんね。
ぜひ本記事を参考にCSM-1Bを使ってみてください!
最後に
いかがだったでしょうか
音声生成AIを活用すれば、カスタマーサポートの自動応答や社内研修動画のナレーション作成が短時間で可能になり、業務効率が大幅に向上します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


