
【Llama 3-V】GPT-4Vの1%サイズの高精度なVLMがまさかの盗作!?

WEELメディア事業部LLMリサーチャーの中田です。
5月29日、MetaのLlama 3 8Bをベースとした、オープンソースの画像認識可能なマルチモーダルLLM「Llama 3-V」が、スタンフォード大学の研究チームによって公開されました。
以前話題となったLlama 3をベースとしており、たった500ドル(約78000円)程度の費用で、SOTAを達成したんです!モデルサイズは、GPT-4Vの100分の1だとか。
ただし、本プロジェクトは、実は「中国のOpenBMBチームが開発した『MiniCPM-Llama3-V 2.5』のコードと学習設定を盗用していた」ことが発覚し、大炎上しています。
XでのLlama3-Vの投稿のいいね数は、すでに1000を超えており、すでに多くの人に注目されていることが分かります。
(後ほど説明しますが、盗作問題のためツイートも削除されています)
この記事ではLlama 3-Vの使い方や、有効性の検証まで行います。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Llama 3-Vの概要
Llama 3-Vは、オープンソースVLMで、MetaのLlama 3をベースとして構築されました。
Llama 3-Vの性能はOpenAIのGPT-4Vに匹敵し、サイズはわずかGPT-4Vの100分の1、学習コストは500ドル程度とのこと。Metaが公開したLlama 3の8Bをベースとすることで、高い性能を実現したそうです。
各種ベンチマークでは、Llama 3-Vは同じVLMのLlavaと比較して10〜20%ほど高い性能を示しています。また、MMMU以外のほとんどすべての指標において、Llama 3-Vの100倍以上のサイズの既存クローズドソースモデル(GPT-4V、Gemini Ultra、Claude Opusなど)に匹敵する性能を発揮。
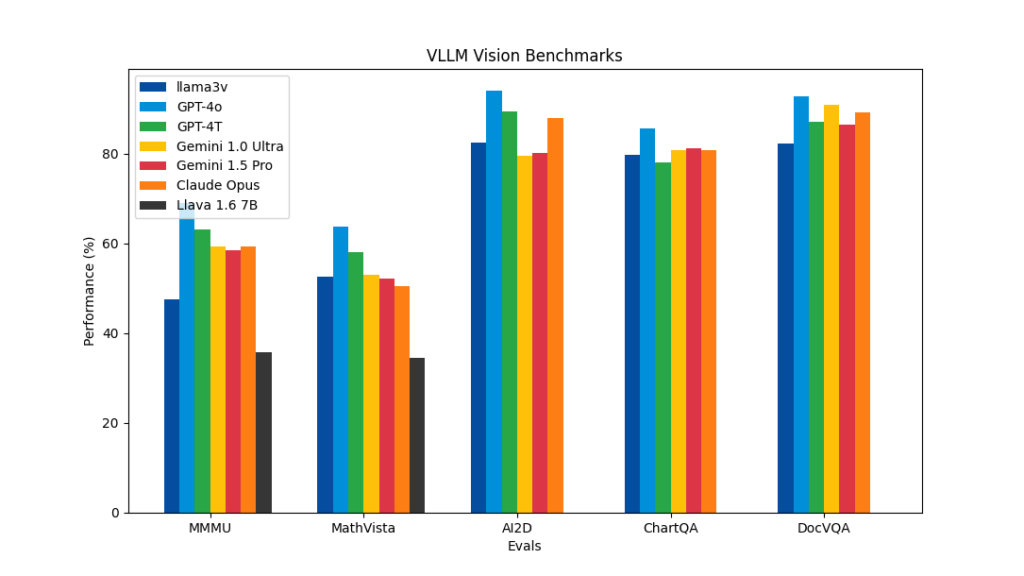
Llama 3-Vは現在、Hugging FaceとGitHubでオープンソースとして公開されており、Hugging Face上では実際に試用することも可能です。
Llama 3-Vのモデル構造
Llama 3-Vでは、Llama 3の128,000トークンの語彙を活用することで、Llama 2と比べて大幅にエンコーディング効率が向上しています。そのため、モデルサイズを上げることなく、より多様な言語パターンを少ないパラメータで表現できるようになり、パフォーマンスの向上につながっています。
また、Llama 3-Vでは、8,192トークンのシーケンスで学習を行うことで、長いテキスト入力の処理に重点を置いています。
さらに、Llama 3にSigLIPという対照学習モデルの画像エンコーダを用いることで、画像情報をLlama 3に伝えることが可能になっています。テキストエンコーダには、Byte Pair Encoding(BPE)が使用されています。
そして、2 つのSelf-Attentionブロックを使用してProjectionブロックを学習し、テキストトークンと画像トークンを揃えています。
そして、揃えられたトークンをLlama 3 8Bに入力することで、返答の文章が出力されるのです。
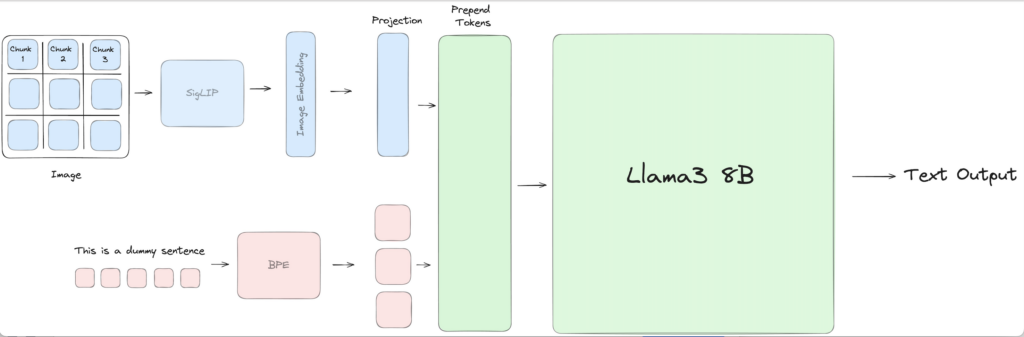
事前学習には、CC3M、LAION-2B、LAION-5Bなどの大規模なデータセットが用いられています。
なお、Llama 3-Vの100倍以上あるクローズドソース「GPT-4V」について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Llama 3-Vのライセンス
Llama 3-Vのライセンス情報については、公開されていなかったので、公開され次第アップデートします。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | 不明 |
| 改変 | 不明 |
| 配布 | 不明 |
| 特許使用 | 不明 |
| 私的使用 | 不明 |

Llama 3-Vの使い方
推論コードについては、GitHubやHuggingFaceに公開されています。
コードはこちら
from transformers import AutoTokenizer, AutoModel
from PIL import Image
model = AutoModel.from_pretrained("mustafaaljadery/llama3v").cuda()
tokenizer = AutoTokenizer.from_pretrained("mustafaaljadery/llama3v")
image = Image.open("test_image.png")
answer = model.generate(image=image, message="What is this image?", temperature=0.1, tokenizer=tokenizer)
print(answer)ただ、こちらを実行すると、以下のようなエラーが発生。
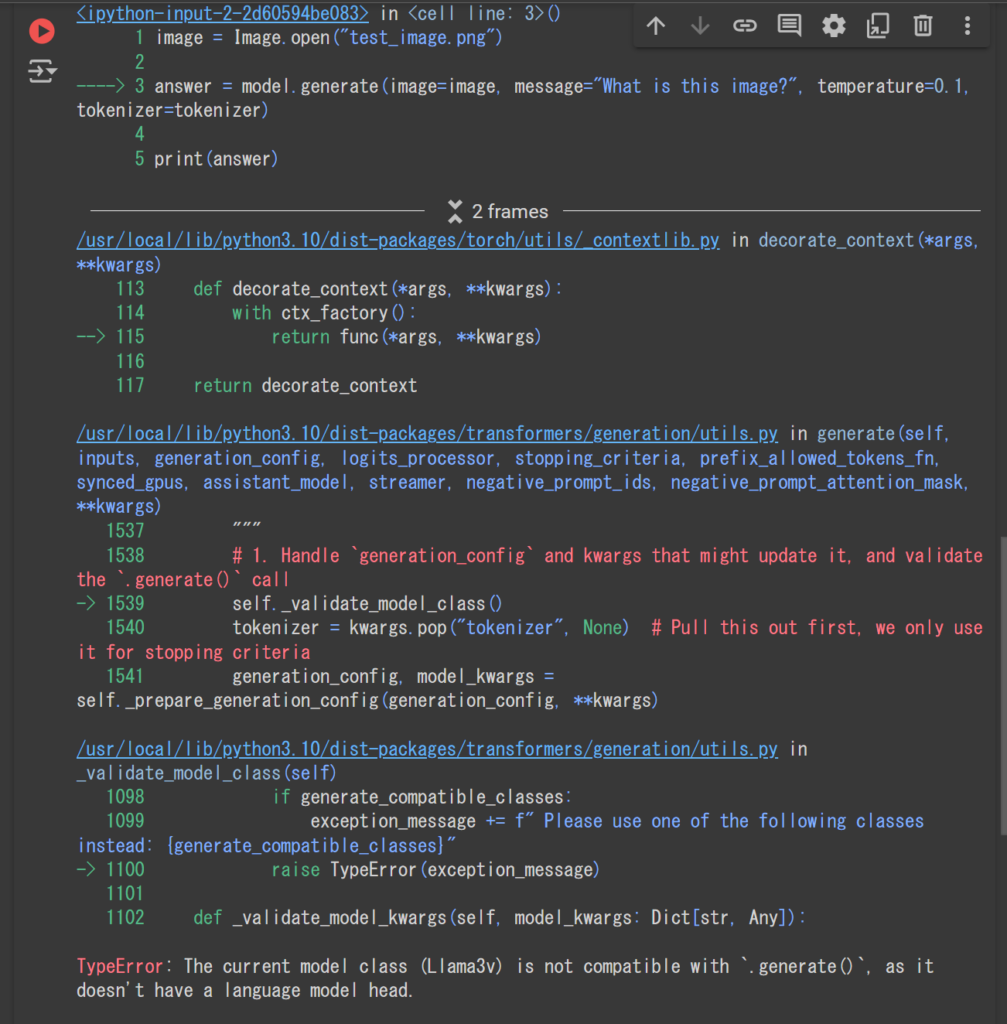
公式HuggingFaceでも、以下のように明記されています。
IMPORTANT: There’s an inference problem in the code, I’m working on cleanup and a fix right now. (28th May – Mustafa Aljadery)
参考:https://huggingface.co/mustafaaljadery/llama3v
和訳:
重要:コードに推論の問題があり、現在クリーンアップと修正に取り組んでいます。(5月28日-ムスタファ・アルジャデリー)
ただ、LlavaをLlama 3でファインチューニングしたものが、Hugging Face Spaceとしてデモが公開されています。
まずは、以下をクリックしてスペースにアクセス。
LLaVA++ (LLaMA-3-V) – a Hugging Face Space
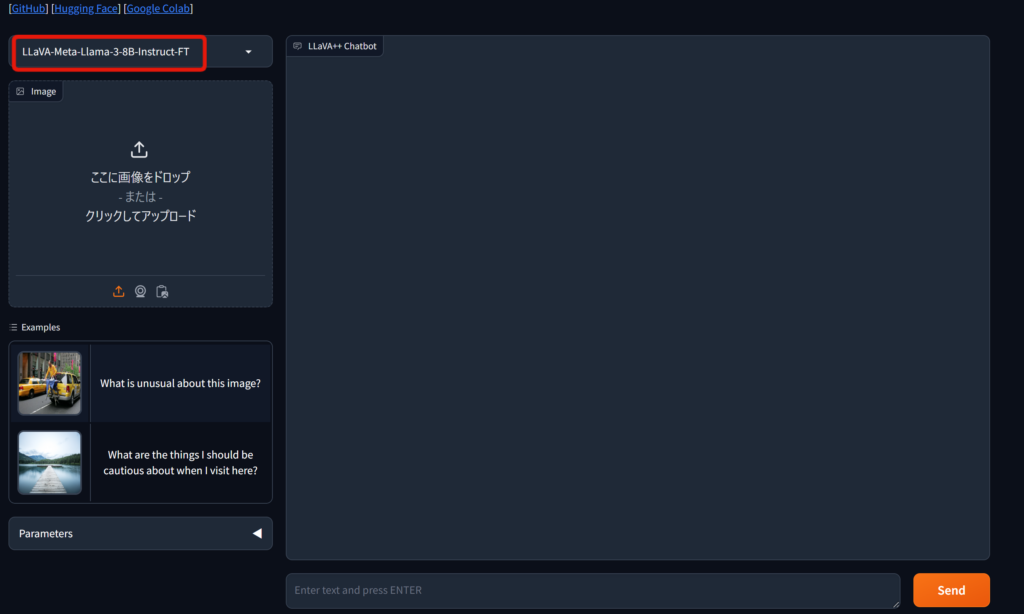
同じLlama 3 8Bをベースとしているので、Llama 3-Vのコードが修正されるまで、こちらを試しても良いでしょう。
Llama 3-Vを動かすのに必要なPCのスペック
以下はGoogle ColabA100で動かした場合に、消費したディスクやGPU RAMです。
■使用ディスク量
約22GB
■GPU RAMの使用量
約30GB
なお、ベースとなるMetaのLlama 3について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Llama 3-Vは実は盗作したプロジェクトだった
Llama 3-Vチームは当初、自分たちのモデルを独自に開発したと主張していましたが、実際にはMiniCPM-Llama3-V 2.5というVLMプロジェクトを盗用したものでした。
- Llama 3-VのコードがMiniCPM-Llama3-V 2.5のコードと酷似している(変数名まで一致している部分が多数ある)。
- Llama 3-Vの学習設定パラメータがMiniCPM-Llama3-V 2.5とほぼ同一。
- 学習データセットも同じものを使用した形跡がある。
- Llama 3-Vの論文にはMiniCPM-Llama3-V 2.5への言及がなく、OpenBMBの成果を適切に引用していない。
OpenBMBチームはGitHubでこの問題を指摘し、Llama 3-Vチームに説明と是正を求めました。これを受けてLlama 3-Vチームはツイッターで盗用を認め、謝罪しました。コードと論文からMiniCPM-Llama3-V 2.5の痕跡を消し、クレジットを追記すると述べています。
参考記事:https://news.yahoo.co.jp/articles/f7951847aeb6f3e41597fa5257065a818d4e2dfa
この一連の出来事は、学術研究におけるオープンソースの成果物の扱いの難しさを浮き彫りにしました。たとえ無料で公開されているコードでも、適切なクレジット表示と引用は必須です。Llama 3-Vの行為は研究倫理に反しており、波紋を呼んでいます。
後日、MiniCPM-Llama3-V 2.5の記事を執筆し、公開する予定です。
なお、Llama2をベースとしたVLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Llama 3-VはMiniCPM-Llama3-V 2.5の盗作プロジェクト
本記事では、Llama 3をベースとしたVLMのLlama 3-Vについて解説しました。
Llama 3-Vは非常に小さなモデルサイズであり、大規模なマルチモーダルモデルに匹敵する高い性能を実現した画期的なオープンソースモデルだと言えます。今後、画像認識と言語理解を組み合わせた幅広い用途への応用が見込めるでしょう。
今回のLlama 3-Vの学習にかかるコストは、日本円でおよそ8万円ということもあり、最近トレンドの「LLM開発の低価格化」についても、さらに注目が集まっていくでしょう。
ただ、まさかの盗作プロジェクトだったということで、大きな波紋を呼んでいます。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

