
【LLM Compiler】Meta社がコード最適化&コンパイル用LLMを開発

2024年6月28日、Meta社がMeta Code Llamaをベースに、コードの最適化とコンパイラ機能を追加した「LLM Compiler」モデルを発表しました!
このLLM Compilerは、X(旧Twitter)で36万人以上の人々が興味を示しており、非常に注目を集めているモデルです。
LLM Compilerでは、70億と130億パラメータの2種類が用意されており、研究および商用利用のためのライセンスを用意しており、研究者や開発者がコードの最適化とコンパイラの最適化を効率的に進めるためのスケーラブルで費用対効果の高い基盤を提供することを目指しています。
この記事では、LLM Compilerをgoogle colaboratoryで使用する方法を画像を交えて解説し、実際にコーディングを行い、最適化されたコードの評価をします。
本記事を最後まで読むことでgoogle colaboratoryを使ってLLM Compilerを使えるようになるので、ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
LLM Compilerの概要
LLM Compilerは研究者や開発者がコードの最適化とコンパイラの最適化を効率的に進めるためのモデルであり、主な目的は、従来のコード最適化手法に代わり、より高度かつ効率的な最適化を実現することです。
従来の手法は手作業や特定の特徴に依存していたため、最適化の質に限界がありました。LLM Compilerはこれを改善し、より広範で精密な最適化を可能にします。
LLM Compilerには70億と130億パラメータの2種類が用意されており、70億パラメータは軽量で効率的なデプロイメントに適しているためリソースが限られた環境での利用に最適であり、130億パラメータのモデルはより高い性能と精度を提供しており、複雑な最適化タスクに対して優れた結果を出します。
さらにそれぞれのモデルには、LLM CompilerとLLM Compiler FTDがあり、LLM Compilerは一般的なコンパイラシミレーションに対応し、LLM Compiler FTDはフラグチューニングと逆アセンブリに特化しているのが特徴的。さらにLLM Compiler FTDでは、追加コンパイル不要で最適化の可能性を77%実現、14%の確率で正しい逆アセンブリを作成します。
LLM Compilerで実現できることをまとめると、次の3つです。
- コード最適化
- 最適化の自動化
- 完全かつロスレスなプログラムの表現
LLM Compilerのトレーニングパイプライン
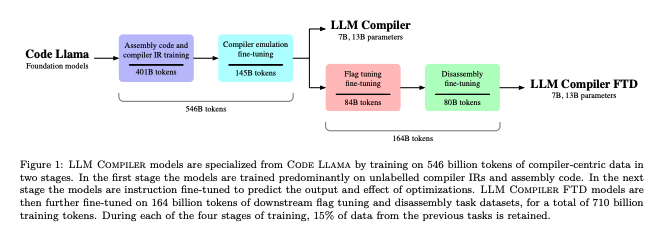
LLM Compilerのトレーニングパイプラインは4段階で行われます。
まずCode Llamaの初期化により基礎となるモデルを設定します。次に4010億トークンを使用して、ラベルなしのコンパイラIRとアセンブリコードのトレーニングです。
3段階目では、1450億トークンを使用して、最適化の出力と効果を予測するための微調整。最終段階では、さらに840億トークンのフラグチューニングと808億トークンの逆アセンブリのタスクに対応するための微調整です。
LLM Compilerのフラグチューニング
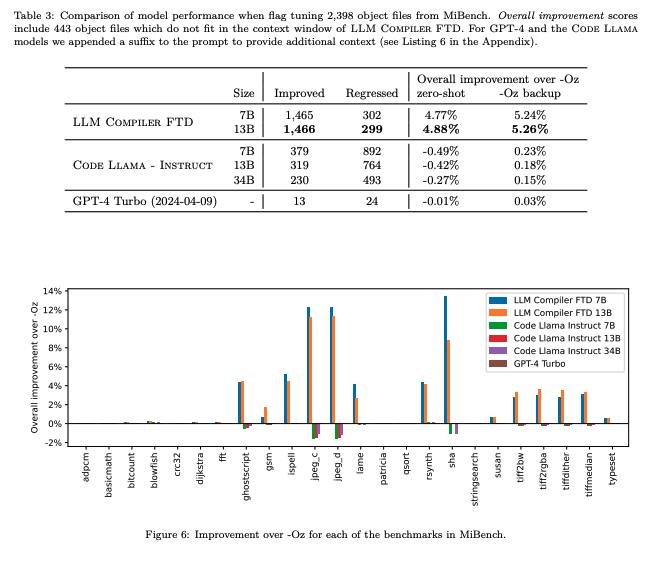
フラグチューニングの結果を、LLM CompilerとGPT4-Turbo、Code Llama – Instructと比較してそれぞれのモデルの性能評価をしてみると、LLM Compilerが最も効果的なモデルであることがわかります。
ImprovedはOz最適化よりも性能が向上したファイルの数であり、RegressedはOz最適化よりも性能が低下したファイルの数です。
Overall improvement over -Oz (zero-shot)がOz最適化に対する全体的な性能向上率(ゼロショット設定)で、Overall improvement over -Oz (-Oz backup)がOzバックアップを使用した場合の全体的な性能向上率であり、Regressed以外はそれぞれの数値が高い方が性能がよく、Regressedは数値が低い方が性能が良いことを表します。
従来のコード最適化とLLM Compilerとの比較
従来のコード最適化手法は、プログラムの特定部分を手作業で調整する必要がありました。また、グラフニューラルネットワーク(GNN)などの技術を用いて最適化を行うことが多かったですが、従来の手法ではプログラムの全体像を完全に捉えることが難しく、不完全な情報に依存していました。
LLM Compilerは、ソースプログラムを完全かつロスレスで受け入れることができるため、プログラムの全体を正確に理解し、最適化できます。LLM Compilerは機械学習を用いて自動的に最適化を行うため、従来手法では見逃されていた最適化の機会を逃さずに捉えることができるようになりました。
なお、Meta社が発表しているLlma3以上の性能を持ったLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

LLM Compilerのライセンス
LLM Compilerのライセンスは次の通りです。
研究目的や商用利用も可能ですが、製品やサービスの月間アクティブユーザーが700万人を超える場合、Metaからのライセンスが必要となります。
また、配布や改変も可能ですが、その場合には関連するウェブサイトやユーザーインターフェース、ブログ記事、アバウトページ、または製品ドキュメントに「Built with LLM Compiler」を明示的に表示しなければなりません。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
LLM Compilerの使い方
LLM Compilerを使用するには、Hagging Faceに登録してアクセストークンの取得とMeta社に個人情報を登録する必要があります。
Hagging Faceの登録とアクセストークンの取得
まずはHagging Faceに登録して、アクセストークンを取得します。
LLM Compilerのページにアクセスした際、以下の画像のように表示されている場合にはサインアップもしくはログインをしましょう。
ログインしたらアクセストークンの設定を行いましょう。
画面右上のアカウントボタンをクリックして、「Settings」を選択。
「Access Tokens」をクリック。
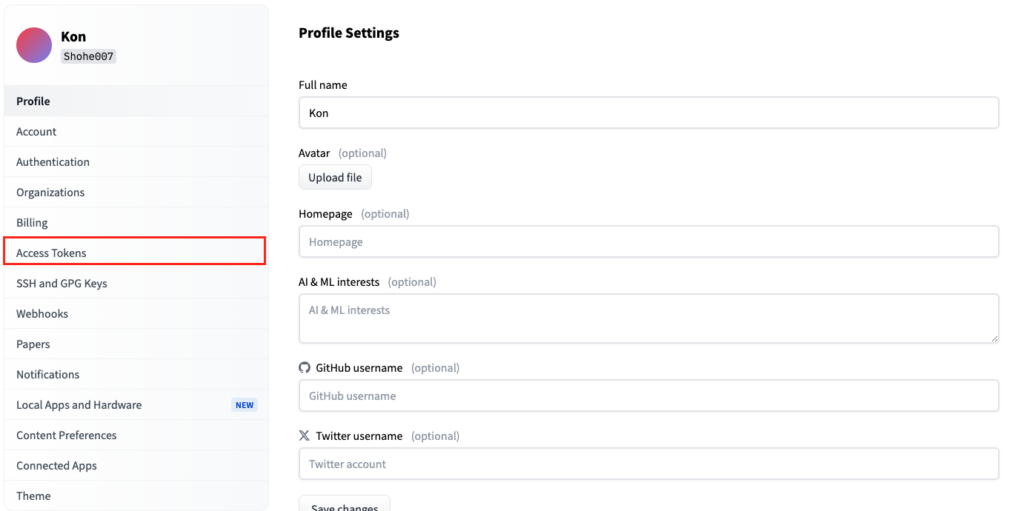
「New token」をクリックして、トークン名を「LLM Compiler」と入力、タイプは「read」を選択して「Generate token」をクリックすると、トークンを設定できます。
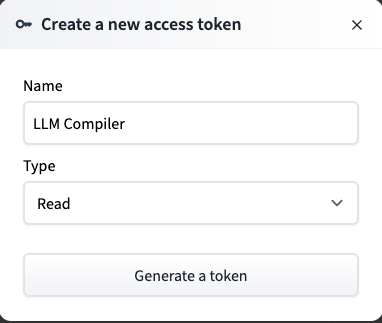
Generate tokenをクリックした後にアクセストークンが表示されますが、作成されたトークンはこの時しかコピペをすることができないため、忘れずにコピペをしておきましょう。万が一コピペし忘れた場合には、新たにトークンを設定する必要があります。
Meta社に個人情報を登録
Hagging Faceにログインもしくはサインアップすると、以下の画面になります。
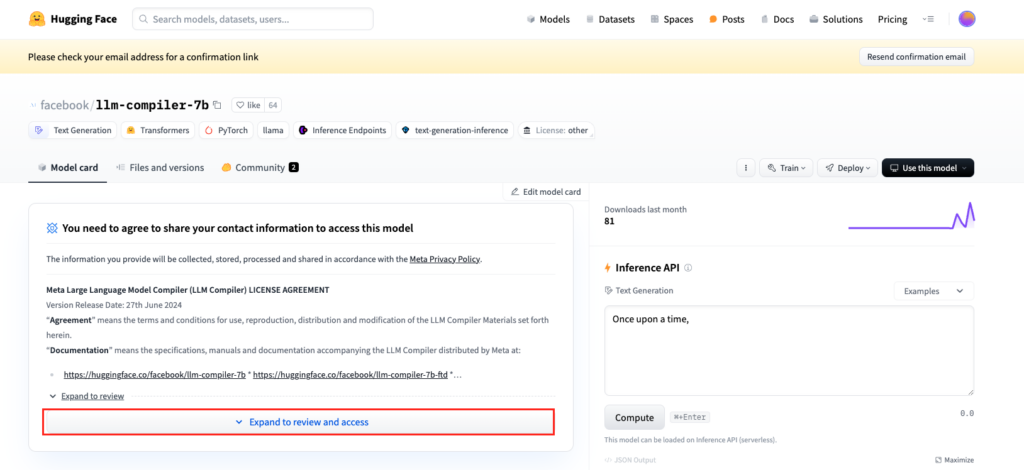
赤枠をクリックすると個人情報を登録するフォームが出てくるので、そちらに必要事項を入力して、「I Accept Meta LLM Compiler License and AUP」をクリック。
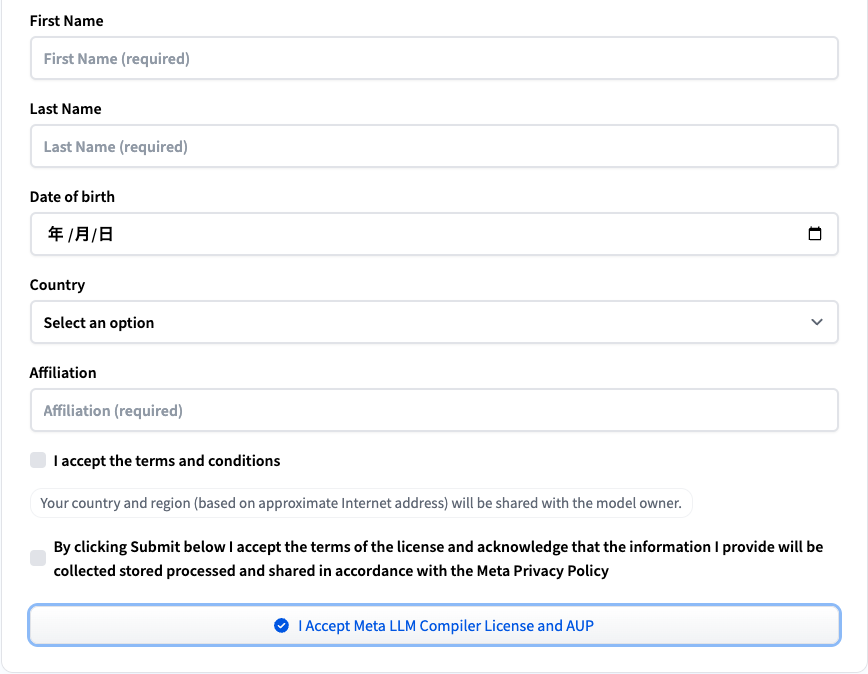
これでLLM Compilerを使用する準備ができましたが、承認されるまでは利用することができません。承認されると登録しているメールアドレスに以下のようなメールが送られてきます。
もしくは「settings」→「Gated Repositories」で承認されているかどうかを確認できます。
「Meta`s LLM Compiler models」に「ACCEPTED」と表示されていればLLM Compilerを使用可能。
LLM Compilerを動かすのに必要な動作環境
LLM Compilerを実装した際のgoogle colaboratoryの動作環境情報です。実装する際にはGPUを使用する必要があるので、google colaboratoryの画面から「ランタイム」→「ランタイムのタイプを変更」→「T4 GPU」を選択しておきましょう。
■Pythonのバージョン:Python 3.8以上
■使用ディスク量:42.8GB
■システムRAMの使用量:2.7GB
■GPU RAMの使用量:13.0GB
LLM Compilerをgoogle colaboratoryで実装
まずは必要なライブラリをインストールします。
必要ライブラリのインストールコードはこちら
# 必要なライブラリのインストール
!pip install transformers
!pip install torch
!pip install sentencepiece
!pip install huggingface_hub
!pip install accelerate
!pip install transformers accelerate次にLLM Compilerを実装します。今回使用するモデルは「facebook/llm-compiler-7b」です。
まずはHagging Faceに掲載されているコードをgoogle colaboratoryで実行します。
Haggin Faceのサンプルコードはこちら
from transformers import AutoTokenizer
import transformers
import torch
import os
from huggingface_hub import login
# Hugging Face APIトークンの設定
token = "your_token"
login(token=token)
os.environ["HUGGING_FACE_HUB_TOKEN"] = token
model = "facebook/llm-compiler-7b"
tokenizer = AutoTokenizer.from_pretrained(model, token=token)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
token=token
)
sequences = pipeline(
'%3 = alloca i32, align 4',
do_sample=True,
top_k=10,
temperature=0.1,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")結果はこちら
Result: %3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
%6 = alloca i32, align 4
%7 = alloca i32, align 4
%8 = alloca i32, align 4
%9 = alloca i32, align 4
%10 = alloca i32, align 4
%11 = alloca i32, align 4
%12 = alloca i32, align 4
%13 = alloca i32, align 4
%14 = alloca i32, align 4
%15 = alloca i32, align 4
%16 = alloca i32, align なお、Googleが発表しているLLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

LLM Compilerはコードの最適化ができるのは本当か
では実際にLLM Compilerはコードの最適化ができるかを検証したいと思います。
まずはLLM Compilerを使って使ってコード最適化を行い、その後最適化前後のコード実行時間を算出して、比較します。
コード最適化のサンプルコードはこちら
from transformers import AutoTokenizer, pipeline
import torch
from huggingface_hub import login
import os
import re
import time
import random
# Hugging Face APIトークンの設定
token = "Your_token"
login(token=token)
os.environ["HUGGING_FACE_HUB_TOKEN"] = token
# モデルの指定
model = "facebook/llm-compiler-7b"
# トークナイザーとパイプラインの設定
tokenizer = AutoTokenizer.from_pretrained(model, token=token)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
# 最適化前コード
inefficient_code = """
def very_inefficient_sort(arr):
sorted_arr = []
while len(arr) > 0:
min_val = min(arr)
sorted_arr.append(min_val)
arr.remove(min_val)
return sorted_arr
"""
# より明確な最適化の指示を含むプロンプト
input_text = f"""Optimize the following inefficient Python function for sorting an array:
{inefficient_code}
Please provide a more efficient implementation of this sorting function. Your optimized function should:
1. Use either Python's built-in sorted() function or list.sort() method for efficient sorting.
2. Avoid creating unnecessary new lists if possible.
3. Aim for a time complexity of O(n log n) instead of the current O(n^2).
Provide your optimized implementation below:
"""
sequences = pipeline(
input_text,
do_sample=True,
top_k=10,
temperature=0.7,
top_p=0.95,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=1000,
truncation=True
)
# 生成されたテキストから関数を抽出
generated_text = sequences[0]['generated_text']
print(f"Generated Text:\n{generated_text}")
# 関数定義を抽出
function_match = re.search(r'def\s+sort_by_mergesort\s*\(.*?\):\s*([\s\S]*?)(?=\ndef|$)', generated_text)
if function_match:
optimized_code = function_match.group(0)
print(f"Optimized Code:\n{optimized_code}")
# 最適化されたコードを評価
try:
exec(optimized_code, globals())
print("Optimized function successfully defined.")
# テストデータ
test_data = [random.randint(1, 1000) for _ in range(1000)]
# 元の関数と最適化された関数を実行して比較
exec(inefficient_code, globals())
start_time = time.time()
inefficient_result = very_inefficient_sort(test_data.copy())
inefficient_time = time.time() - start_time
print(f"Inefficient Sort Time: {inefficient_time:.6f} seconds")
start_time = time.time()
optimized_result = sort_by_mergesort(test_data.copy())
optimized_time = time.time() - start_time
print(f"Optimized Sort Time: {optimized_time:.6f} seconds")
# 結果の正確性を確認
print(f"Results match: {inefficient_result == optimized_result}")
# 速度向上の計算
speedup = inefficient_time / optimized_time
print(f"Speedup: {speedup:.2f}x")
# より大きなテストデータでの実行
large_test_data = [random.randint(1, 100000) for _ in range(10000)]
start_time = time.time()
very_inefficient_sort(large_test_data.copy())
large_inefficient_time = time.time() - start_time
print(f"Inefficient Sort Time (large data): {large_inefficient_time:.6f} seconds")
start_time = time.time()
sort_by_mergesort(large_test_data.copy())
large_optimized_time = time.time() - start_time
print(f"Optimized Sort Time (large data): {large_optimized_time:.6f} seconds")
large_speedup = large_inefficient_time / large_optimized_time
print(f"Speedup (large data): {large_speedup:.2f}x")
except Exception as e:
print(f"Error in optimized code: {e}")
else:
print("No valid function found in the generated text. Using the original inefficient code.")最適化前のコードはこちら
# 最適化前コード
def very_inefficient_sort(arr):
sorted_arr = []
while len(arr) > 0:
min_val = min(arr)
sorted_arr.append(min_val)
arr.remove(min_val)
return sorted_arr最適化後のコードはこちら
def better_sort(arr):
arr.sort()
return arr最適化前後のコード量を見てみても、明らかにコード数が違うことがわかります。
最適化前後のコードは、sorted_arrという空のリストを作成し、元の配列arrが空になるまで次の作業を繰り返します。
- arrの中から最小値を見つけてmin_valに格納
- min_valをsorted_arrに追加
- min_valをarrから削除
最後にソートされたリストからsorted_arrを返します。
では実際に最適化前後のコード実行時間を測定してみましょう。
最適化前後のコード実行時間を測定するコードはこちら
import time
import random
# 元の非効率なコード
def very_inefficient_sort(arr):
sorted_arr = []
while len(arr) > 0:
min_val = min(arr)
sorted_arr.append(min_val)
arr.remove(min_val)
return sorted_arr
# 最適化されたコード
def better_sort(arr):
arr.sort()
return arr
# テストデータの生成
test_data = [random.randint(1, 1000) for _ in range(1000)]
# 非効率なソートの実行時間を計測
start_time = time.time()
very_inefficient_sort(test_data.copy())
inefficient_time = time.time() - start_time
print(f"Very Inefficient Sort Time: {inefficient_time:.6f} seconds")
# 最適化されたソートの実行時間を計測
start_time = time.time()
better_sort(test_data.copy())
optimized_time = time.time() - start_time
print(f"Better Sort Time: {optimized_time:.6f} seconds")
# 速度向上の計算
speedup = inefficient_time / optimized_time
print(f"Speedup: {speedup:.2f}x")
結果はこちら
Very Inefficient Sort Time: 0.042483 seconds
Better Sort Time: 0.000247 seconds
Speedup: 171.66xBetter Sort Timeが最適化を行った時のコード実行時間です。
どちらのコードも実行時間は1秒にも満たないですが、最適化前後で比較すると速度改善は明らかでしょう。
今回は非常にシンプルなタスクで実験的にLLM Compilerの実力を測りましたが、より複雑なコードを最適化する際などに本領を発揮することでしょう。
まとめ
本記事では、LLM Compilerをgoogle colaboratoryで使用する方法についてお伝えをしました。google colaboratoryを使用することで、自身のパソコンにGPUが搭載されていなくても、手軽に生成AIツールを活用できます。
これまでにもコードを最適化するためのLLMはリリースされていましたが、LLM Compilerの強みは、完全かつロスレスなプログラムの表現であり、従来手法では見落としていた最適化のポイントを見逃さずにコードの最適化を行える点です。
また、LLM Compilerには2種類のモデルが用意されているため、使用ケースや必要な精度に応じてモデルを選択することも可能。LLM Compilerはまだリリースされたばかりなので、今後の成長が楽しみですね。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


