
Mistral AI発「Magistral」とは? 推論特化で進化するLLMの未来
- Magistralは専門領域での推論力と透明性を重視した推論特化型LLMシリーズ
- Smallはオープンソースで扱いやすく、Mediumは産業向けに高精度を発揮
- 2025年9月のアップデートでマルチモーダル対応・性能改善・長文処理強化を実現
Magistralシリーズは、Mistral AIが2025年6月に発表した初の推論特化モデル。
これまでの一般的な大規模言語モデル(LLM)は幅広いタスクに対応する一方で、専門領域での深い推論や透明性、多言語対応に課題がありました。Magistralはそうした課題に応えるべく設計されています。
そして、2025年9月にマイナーアップデートが行われ、マルチモーダル対応・パフォーマンスが従来よりも向上しています。
本記事ではMagistralシリーズについて、概要から性能、使い方まで解説をします。本記事を最後までお読みいただければMagistralシリーズの理解が深まります。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Magistralシリーズの概要
Magistralは、Mistral AIが2025年に発表した推論特化型の大規模言語モデル(LLM)シリーズです。
従来のLLMに不足していた「専門領域における深い推論」「透明性のある思考過程」「多言語対応」を強化し、法務・金融・研究開発など高精度かつ説明責任が求められる分野で活用できるのが大きな特徴です。
Magistralシリーズはオープンソース版のSmallとエンタープライズ向けのMediumの2種類があり、目的や環境に応じて選択可能です。
Magistral Small
Magistral Smallは、24Bパラメータのオープンウェイトモデル。
Magistral Small 1.2ではVision Encoderが追加され、テキストと画像を統合的に処理できるようになりました。また、数学やコーディング系ベンチマーク(AIME24/25、LiveCodeBench v5/v6)で従来モデルから15%以上の性能向上を実現しています。
さらに、特殊トークン[THINK]…[/THINK]によって推論過程を明示でき、ユーザーが回答の裏にある思考を追いやすい点も特徴。ローカル環境でも利用しやすく、RTX 4090や32GB RAMのMacBookでも量子化すれば動作可能です。
Magistral Medium
Magistral Mediumは、より高性能なエンタープライズ版として提供されるモデル。推論能力に優れ、法務・金融・医療・政府といった規制産業向けになっています。
ベンチマークでは特に強力で、AIME24で91.82%、LiveCodeBench v5で75%を記録し、Smallを大きく上回る精度。


|
Magistral 1.2で強化されたポイント
2025年9月に登場したMagistral 1.2は、従来の1.1から多方面で進化を遂げています。
特にマルチモーダル対応や推論性能の改善、応答品質の向上など、実用性を大きく押し上げるマイナーアップデートが行われました。主な変更点は以下の通りです。
- マルチモーダル対応:Vision Encoderを搭載し、テキストと画像を組み合わせた推論が可能
- ベンチマーク性能の向上:AIME24やLiveCodeBenchで15%以上の改善を達成
- ツール利用の改善:Web検索、コードインタープリタ、画像生成の活用がより賢く
- 応答品質の改善:LaTeXやMarkdownの表記強化、自然で簡潔な回答を実現
- 特殊トークンの導入:
[THINK]…[/THINK]で推論過程を明示的に出力可能に - 安定性と制御性の強化:無限生成を防止し、最大128kトークンの長文コンテキストに対応
Magistral 1.2の性能
Magistral 1.2は、数学・科学推論やコーディングなど「論理的な思考が求められる領域」で大幅な性能向上を達成しています。特にAIMEやLiveCodeBenchといった代表的なベンチマークで1.1から大きく改善が確認できます。
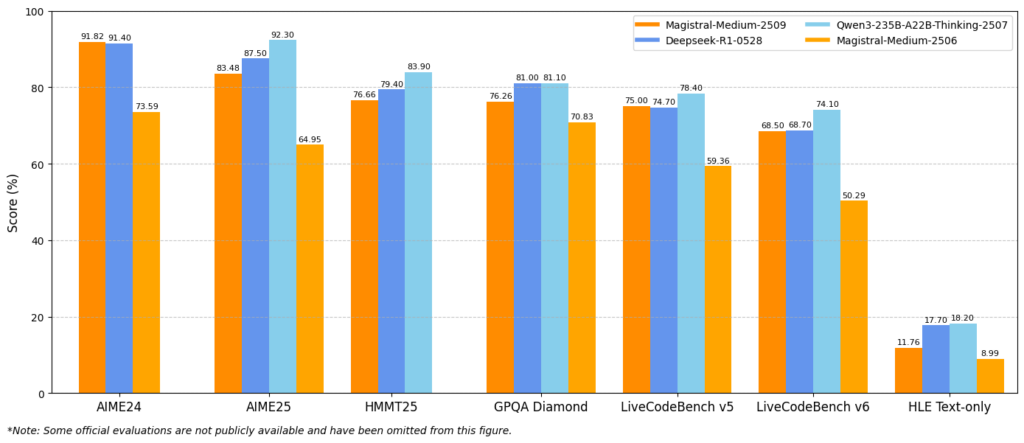
Smallはオープンソース版ながら、大幅な性能向上を果たしています。数学・コーディング分野で安定した精度を出しており、ローカル実行可能なモデルとしては十分に高いレベルです。
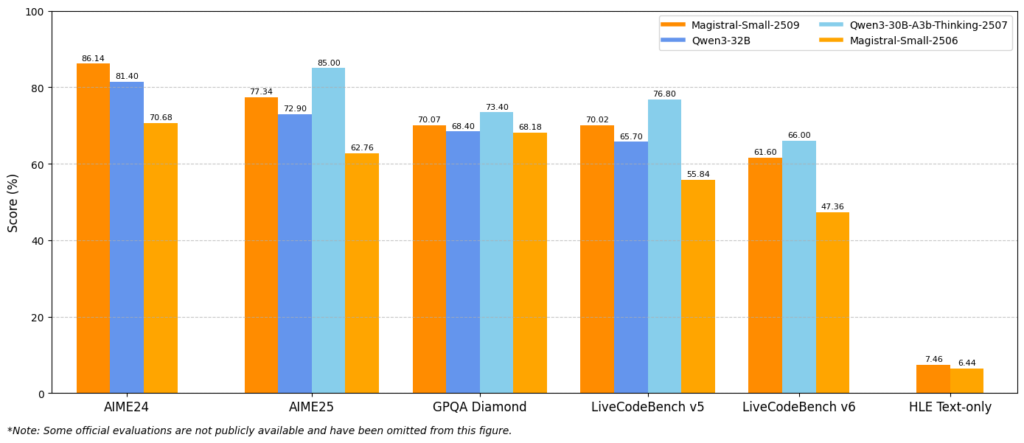
総じて、Mediumは最高水準の研究・産業利用向け、Smallはオープンソースで扱いやすく高性能という位置付けです。
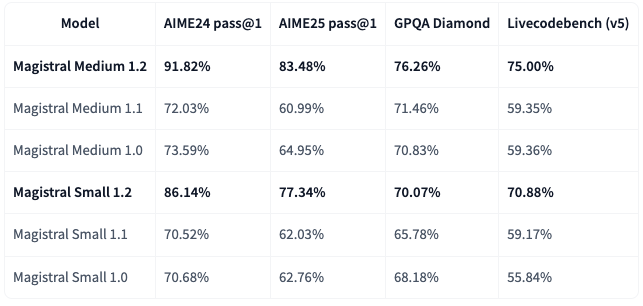
上記はSmallとMediumの比較表ですが、いずれにおいても従来のモデルよりも性能が向上していることがよくわかります。
Magistralシリーズのライセンス
MagistralシリーズのライセンスはApache 2.0ライセンスです。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、ローカル利用可能なオープンウェイト推論モデルであるgpt-oss-120b/gpt-oss-20bについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Magistralシリーズの使い方
MagistralシリーズはChat版が用意されているので、誰でも手軽に利用できます。
一方でMagistral SmallはHugging Faceからダウンロードが可能。24Bパラメーターなので量子化を行えばRTX 4090や32GB RAMのMacBookでも動作可能です。
Mediumはオープンウェイトではなく、クラウドやAPI経由で利用します。今回はChat版とMediumをMistral APIで使っていきます。
Chat版Magistralの使い方
まずはサイトにアクセスします。
実際に使ってみましたが、処理速度はめちゃくちゃ速いですね。もしかしたら単純な質問だからかもしれません。
Mistral APIの使い方
Magistralをgoogle colaboratoryで利用します。利用するにはMistralのAPIキーを発行し、事前に10ドルを課金しておく必要があります。
APIキーの発行と課金が終わったらあとはコードを書いていきます。
!pip install openai次にAPIキーを入力します。
import os
os.environ["MISTRAL_API_KEY"] = ""あとはサンプルコードを実行すればOKです。
サンプルコードはこちら
from openai import OpenAI
client = OpenAI(
api_key=os.environ["MISTRAL_API_KEY"],
base_url="https://api.mistral.ai/v1"
)
response = client.chat.completions.create(
model="mistral-medium-latest", # 利用するモデル名
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "LLMのMagistral Mediumについて簡単に説明してください。"}
],
temperature=0.7,
max_tokens=500
)
print(response.choices[0].message.content)結果はこちら
**Magistral Medium**は、2024年6月に発表された**Mistral AI**による**中規模の高性能言語モデル(LLM)**です。
主な特徴は以下の通りです:
1. **規模と性能**
- パラメータ数は非公開ですが、**Mistral Small(22B)とMistral Large(123B)の中間**に位置付けられています。
- 高い推論能力とコストパフォーマンスを両立し、**企業向けタスク(RAG、ファインチューニング、エージェントシステムなど)**に適しています。
2. **長文処理**
- **128Kトークン**のコンテキストウィンドウをサポートし、長文の理解や複雑なドキュメント処理が可能です。
3. **マルチモーダル対応(予定)**
- テキストだけでなく、**画像や音声などのマルチモーダル入力**にも対応する予定(2024年後半にリリース予定)。
4. **効率性**
- **Mistralの高速推論エンジン**と組み合わせることで、低遅延・低コストで運用できます。
5. **利用方法**
- **MistralのAPI**または**La Plateforme**(Mistralのモデルホスティングサービス)経由で利用可能。
- ファインチューニングやカスタマイズもサポートされています。
---
**比較例(Mistralシリーズ)**
| モデル | 規模 | コンテキストウィンドウ | 主な用途 |
|----------------|-----------|----------------------|------------------------|
| **Mistral Small** | 22B | 32Kトークン | 軽量タスク、低コスト |
| **Magistral Medium** | 中規模 | **128Kトークン** | **企業用途、複雑タスク** |
| Mistral Large | 123B ||
|
マルチモーダル機能の検証
マイナーアップデートでマルチモーダル対応になったので、ここではマルチモーダル機能の検証をしたいと思います。
まずは下記の画像を解説してもらいます。
サンプルコードはこちら
import os
import base64
import mimetypes
from openai import OpenAI
client = OpenAI(
api_key=os.environ["MISTRAL_API_KEY"],
base_url="https://api.mistral.ai/v1"
)
# 画像をdata URLに変換(Magistral 1.2のvision入力用)
def encode_image_to_data_url(path: str) -> str:
mime = mimetypes.guess_type(path)[0] or "image/png"
with open(path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
return f"data:{mime};base64,{b64}"
image_path = "/content/G1IfPW3XIAAKlWs.png"
image_data_url = encode_image_to_data_url(image_path)
# テキストのみ→画像つきマルチモーダル入力に変更
response = client.chat.completions.create(
model="mistral-medium-latest",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "text", "text": "この画像を踏まえて、LLMのMagistral Mediumについて簡潔に説明し、図の要点も述べてください。"},
{"type": "image_url", "image_url": image_data_url}
]
}
],
temperature=0.7,
max_tokens=500
)
print(response.choices[0].message.content)結果はこちら
このバーチャートは、様々な評価基準における複数の言語モデルの性能を比較したものです。
**Magistral Mediumモデルについて**
- Magistral モデルは、簡単に言えば、自然言語処理タスクに使用される大規模言語モデル(LLM)の一つです。この図の中ではMagistral-Smallという名前で2種類(2509と2506)のバージョンが比較されています。
**図の要点**
1. **比較モデル**
- Magistral-Small-2509
- Magistral-Small-2506
- Qwen3-30B-A3b-Thinking-2507
- Qwen3-32B
2. **評価基準**
- AIME24
- AIME25
- GPQA Diamond
- LiveCodeBench v5
- LiveCodeBench v6
- HLE Text-only
3. **スコア比較**
- AIME24ではMagistral-Small-2509が86.14%と最も高いスコアを示しています。
- AIME25ではQwen3-30B-A3b-Thinking-2507が85.00%と最も高いスコアです。
- GPQA DiamondではQwen3-30B-A3b-Thinking-2507が73.40%と最も高いスコアです。
- LiveCodeBench v5ではQwen3-30B-A3b-Thinking-2507が76.80%と最も高いスコアです。
- LiveCodeBench v6ではQwen3-30B-A3b-Thinking-2507が66.00%と最も高いスコアです。
- HLE Text-onlyではMagistral-Small-2509が7.46%と最も高いスコアです。
4. **全体的な傾向**
- Qwen3-30Bしっかりとグラフを読み取れているように見えます。
そうしたら、次に今のグラフを再作成するためのPythonのコードを書いてもらいます。
サンプルコードはこちら
import os
import base64
import mimetypes
from openai import OpenAI
client = OpenAI(
api_key=os.environ["MISTRAL_API_KEY"],
base_url="https://api.mistral.ai/v1"
)
# 画像をdata URLに変換(Magistral 1.2のvision入力用)
def encode_image_to_data_url(path: str) -> str:
mime = mimetypes.guess_type(path)[0] or "image/png"
with open(path, "rb") as f:
b64 = base64.b64encode(f.read()).decode("utf-8")
return f"data:{mime};base64,{b64}"
image_path = "/content/G1IfPW3XIAAKlWs.png"
image_data_url = encode_image_to_data_url(image_path)
# テキストのみ→画像つきマルチモーダル入力に変更
response = client.chat.completions.create(
model="mistral-medium-latest",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "text", "text": "この画像を踏まえて、私がPythonで同じグラフを作成するためのコードを出力してください。"},
{"type": "image_url", "image_url": image_data_url}
]
}
],
temperature=0.7,
max_tokens=4000
)
print(response.choices[0].message.content)結果はこちら
このグラフはMatplotlibやSeabornを使用して作成できます。以下に、このグラフを再現するためのPythonコードを示します。
```python
import matplotlib.pyplot as plt
import numpy as np
# データの準備
labels = ['AIME24', 'AIME25', 'GPQA Diamond', 'LiveCodeBench v5', 'LiveCodeBench v6', 'HLE Text-only']
magistral_small_2509 = [86.14, 77.34, 70.07, 70.02, 61.60, 7.46]
qwen3_30b_a3b_thinking_2507 = [85.00, 81.40, 73.40, 76.80, 66.00, 6.44]
qwen3_32b = [81.40, 72.90, 68.40, 55.84, 47.36, None]
magistral_small_2506 = [70.68, 62.76, 68.18, 65.70, None, None]
x = np.arange(len(labels)) # ラベルの位置
width = 0.2 # バーの幅
fig, ax = plt.subplots(figsize=(14, 8))
# バーのプロット
rects1 = ax.bar(x - width*1.5, magistral_small_2509, width, label='Magistral-Small-2509', color='orange')
rects2 = ax.bar(x - width/2, qwen3_30b_a3b_thinking_2507, width, label='Qwen3-30B-A3b-Thinking-2507', color='cyan')
rects3 = ax.bar(x + width/2, qwen3_32b, width, label='Qwen3-32B', color='blue')
rects4 = ax.bar(x + width*1.5, magistral_small_2506, width, label='Magistral-Small-2506', color='gold')
# グラフの装飾
ax.set_ylabel('Score (%)')
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.legend()
# 値をバーの上に表示
def autolabel(rects):
for rect in rects:
height = rect.get_height()
if height is not None:
ax.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0, 3),
textcoords="offset points",
ha='center', va='bottom')
autolabel(rects1)
autolabel(rects2)
autolabel(rects3)
autolabel(rects4)
fig.tight_layout()
plt.show()
```
このコードでは、Matplotlibを使って棒グラフを作成しています。データは問題文のグラフに従って設定されています。`None` の部分はグラフに表示されないようになっています。そうしたら出力されたコードを実行してみます。出力された画像がこちら
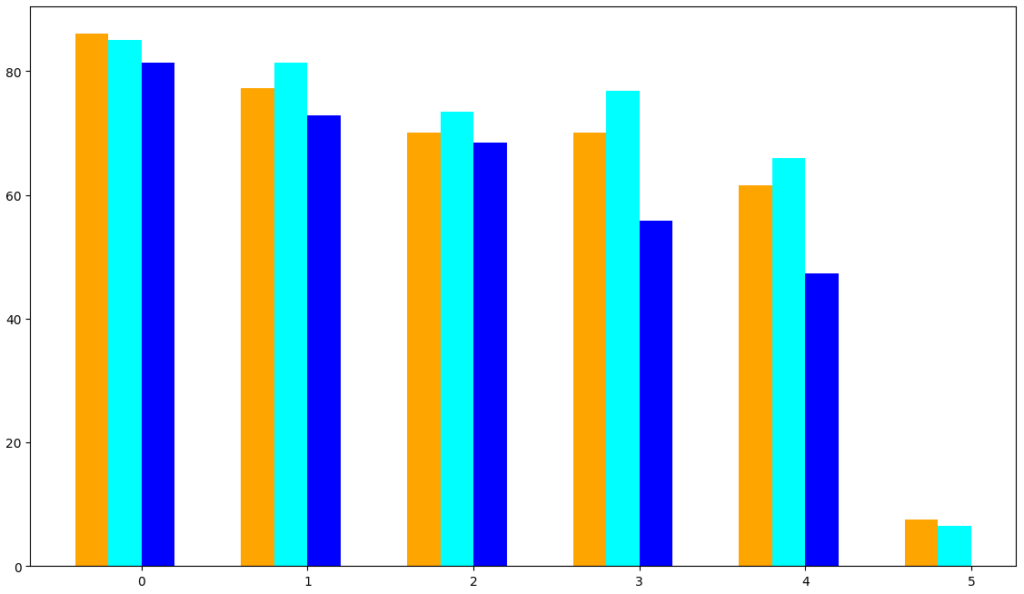
おおむね再現できている印象でしたが、TypeErrorが発生したため、その影響で完全には再現出来ませんでした。とはいえ、およそ7割程度は再現できていると考えられます。
なお、GPT-4に次ぐ世界第二位のLLMであるMistral Largeについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
まとめ
本記事ではMagistralシリーズとしてSmallとMediumについて解説をしました。
SmallはChat版で使い勝手が良く、もう一歩踏み込んだ使い方をしたいユーザーはMediumを使うのが良いでしょう。APIが用意されているので、そこまで手間でもありません。
皆さんも本記事を参考にぜひMagistralを使ってみてください!

最後に
いかがだったでしょうか?
Magistralシリーズを実際に試して、その推論力とマルチモーダル対応を体感してみましょう。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


