
【Open-Sora】裏ワザでOpenAIのSoraを使う禁断の方法

WEELメディア事業部LLMリサーチャーの中田です。
3月17日、OpenAIのSoraを再現したプロジェクト「Open-Sora」を、HPC-AI TechのColossal-AIチームが公開しました。
あの話題のSoraを、オープンソースで疑似的に利用できるんだとか!
公式リポジトリのスター数は、すでに6700を超えており、世界中から注目されていることが分かります。
この記事ではOpen-Soraの使い方や、有効性の検証まで行います。本記事を熟読することで、Open-Soraの凄さを理解し、本家のSoraの代わりとして駆使できるようになるでしょう。
ぜひ、最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Open-Soraの概要
少し前、数あるText-to-Videoモデルの中でも、OpenAIのSoraは特に世界的な注目の的となりました。そしてこの度、ColossalAIチームが、Soraのオープンソース版である「Open-Sora 1.0」を公開しました。
公式ブログによると、OpenAIのSoraのアーキテクチャを模倣し、それをオープンソースとしてGitHubに公開したとのこと。
Open-Soraで作った動画の例は、以下の通りです。

上記の動画は、以下のプロンプトを入力して生成されたとのこと。
A bustling city street at night, filled with the glow of car headlights and the ambient light of streetlights. The scene is a blur of motion, with cars speeding by and pedestrians navigating the crosswalks. The cityscape is a mix of towering buildings and illuminated signs, creating a vibrant and dynamic atmosphere. The perspective of the video is from a high angle, providing a bird’s eye view of the street and its surroundings. The overall style of the video is dynamic and energetic, capturing the essence of urban life at night.
和訳:
車のヘッドライトの光と街灯の環境光で満たされた夜のにぎやかな街並み。スピードを上げて行き交う車、横断歩道を行き交う歩行者。街並みは、そびえ立つビルとライトアップされた看板が混在し、活気に満ちたダイナミックな雰囲気を醸し出している。映像の視点はハイアングルで、通りやその周辺を俯瞰している。ビデオの全体的なスタイルは、ダイナミックでエネルギッシュで、夜の都市生活のエッセンスを捉えている。
2 秒の 512×512 ビデオを生成できるそう。
Open-Soraのその他の生成動画を見たい方は、Open-Soraのギャラリーページをご覧ください。
アーキテクチャ
Open-Soraのアーキテクチャは、Soraと同様、「DiT(Diffusion Transformer」をベースとしています。
また、同じくDiTベースのオープンソースのText-to-Imageモデルである「PixArt-α」に対し、temporal attention層を追加することで、画像生成モデルに動画生成の能力を付与しています。
具体的には、事前学習済みのVAE・テキストエンコーダ(T5)・spatial-temporal attentionを利用する「STDiTモデル」で構成されいます。
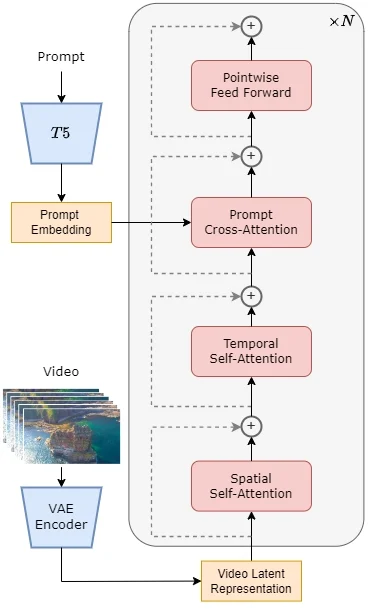
2次元のspatial-temporal attentionは、画像や動画のフレーム内の異なる位置(空間)にある要素間の関係をモデル化します。例えば、画像内のオブジェクトがどのように配置されているか、オブジェクト間の相対的な位置や関係性などを理解し、これを通じて画像の内容をより詳細に解析することができます。
一方、1次元のtemporal attentionは、動画内の異なるフレーム間の時間的な関係をモデル化し、オブジェクトが時間とともにどのように動くか、あるいは変化するかという情報を把握できるのです。
これらのモジュールを順に直列で重ねることで、空間的な情報をベースにして、その上に時間的な情報を加えることを意味します。つまり、まず画像やフレームの空間的な内容を理解し、その上でフレーム間の時間的な変化や動きに注意を払うことで、動画全体のより深い理解を目指す方法です。
temporal attentionの後、Cross-Attentionモジュールによって、テキストプロンプトの情報を処理し、そのプロンプトの内容に沿った動画を生成します。
学習・推論過程は以下の通りです。

まず事前学習されたVAEエンコーダーを使用して動画データを圧縮し、それをプロンプトの埋め込みと共にSTDiTに入力して、拡散モデルによるデノイズされたデータを得ます。そして、最後にそのデータをVAEデコーダーに入力して、圧縮表現から動画に変換します。
学習スキーム
Open-Soraの学習スキームは、以下の3ステップで成り立っています。
- Large-scale image pre-training:Text-to-Imageモデルの学習
- Large-scale video pre-training:ステップ1で学習したモデルの重みを初期値として、Open-Soraのアーキテクチャと動画データで学習
- High-quality video data fine-tuning:ステップ2で学習したモデルを、より高品質な動画データで再学習
各ステージの学習では、前ステージの重みに基づいて多段階的に学習します。

ちなみに、同社が開発した深層学習フレームワークのColossalAIについては、「【Colossal-AI】LLMが自分のPCで安く簡単に、高速で利用できるツール」を合わせてご確認ください。
Open-Soraのライセンス
公式ページによると、Apache License 2.0のもと無料で商用利用することが可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |

Open-Soraの使い方
公式のGitリポジトリを参考に、Google Colab上で実行します。まずは、以下のコマンドを実行してください。
# create a virtual env
conda create -n opensora python=3.10
# install torch
# the command below is for CUDA 12.1, choose install commands from
# https://pytorch.org/get-started/locally/ based on your own CUDA version
pip3 install torch torchvision
# install flash attention (optional)
pip install packaging ninja
pip install flash-attn --no-build-isolation
# install apex (optional)
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" git+https://github.com/NVIDIA/apex.git
# install xformers
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu121
# install this project
git clone https://github.com/hpcaitech/Open-Sora
cd Open-Sora
pip install -v .次に、「pretrained_models/t5_ckpts/t5-v1_1-xxl」にT5の重みをダウウンロードしましょう。また、Open-Soraのモデルファイルから、チェックポイントをダウンロードしましょう。そして、以下のいずれかのコマンドを実行すると、「./samples」に動画が生成されます。
# Sample 16x256x256 (5s/sample)
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x256x256.py --ckpt-path ./path/to/your/ckpt.pth
# Sample 16x512x512 (20s/sample, 100 time steps)
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x512x512.py --ckpt-path ./path/to/your/ckpt.pth
# Sample 64x512x512 (40s/sample, 100 time steps)
torchrun --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/64x512x512.py --ckpt-path ./path/to/your/ckpt.pth
# Sample 64x512x512 with sequence parallelism (30s/sample, 100 time steps)
# sequence parallelism is enabled automatically when nproc_per_node is larger than 1
torchrun --standalone --nproc_per_node 2 scripts/inference.py configs/opensora/inference/64x512x512.py --ckpt-path ./path/to/your/ckpt.pthちなみに、プロンプト情報は「./assets/texts/○○.txt」に格納されています。試しに、以下のプロンプトで実行してみます。
A scene of a man walking with his dog.
和訳:
犬と散歩をしている男性のシーン
結果は以下の通りです。
Open-Soraを動かすのに必要なPCのスペック
■Pythonのバージョン
Python 3.10
■使用ディスク量
1.2GB
■RAMの使用量
8.86GB
OpenAIのSoraの技術的な詳細については、「OpenAI Soraはなんですごい動画を作れる?革新的な点や仕組みをエンジニアが徹底解説」を合わせてご確認ください。
本家のSoraと比較してみた
ここでは、Open-Soraと本家のSoraの性能を比較しようと思います。
使用するプロンプトは以下の通りです。
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
和訳:
暖かく光るネオンとアニメーションの街の看板で埋め尽くされた東京の通りを歩くスタイリッシュな女性。黒いレザージャケットに赤いロングドレス、黒いブーツを履き、黒い財布を持っている。サングラスに赤い口紅。彼女は自信に満ち、さりげなく歩いている。通りは湿っていて反射し、色とりどりの光の鏡のような効果を生み出している。多くの歩行者が歩いている。
ちなみに、このプロンプトは、本家のSoraで以下の動画を生成する際に用いられたもの。
このプロンプトと全く同じ文章を、Open-Soraにも入力した結果、以下の通りになりました。
次は、以下のプロンプトで試してみます。
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
和訳:
数頭の巨大な毛むくじゃらのマンモスが雪の草原を踏みしめながら近づいてくる。長い毛むくじゃらの毛が風になびきながら歩くマンモス、雪に覆われた木々、遠くに見えるドラマチックな雪を頂いた山々。
これを本家Soraに入力した結果は、以下の動画の通りです。
Open-Soraに入力した結果は、以下の通りです。
OpenAIのSoraの活用方法については、「【OpenAI Soraの動画事例】一晩で世界を変えた動画生成AIのヤバい使い方10選」を合わせてご確認ください。
話題のSoraをいち早く体感しよう
本記事では、OpenAIのSoraの再現プロジェクト「Open-Sora」をご紹介しました。簡単にローカルで実行できるので、ぜひ試してみてください。
検証結果としては、個人的には「やはり本家のSoraには、品質面で到底及ばない」という印象でした。これについては、Xでも同意見の投稿が見つかりました。
これに関して、Open-Soraを開発したチームも、「学習データが少ないため、モデルの生成品質などは改善の余地がある」という見解を述べています。また、「Open-Sora 1.0は肖像画や複雑な画像の生成があまり得意ではない」とのこと。
そして、今後もOpen-Soraの品質向上を進めていく予定だそう。
It is worth noting that our current version only uses 400K of training data, and the model’s generation quality and ability of text following could be improved. For example, in the turtle video above, the generated turtle has an extra foot. Open-Sora 1.0 is also not very good at generating portraits and complex images. We have a list of plans on GitHub and will continue to address the existing bugs and improve the quality of the generation.
和訳:
現在のバージョンは400Kの学習データしか使用しておらず、モデルの生成品質とテキスト追跡能力は改善可能であることは注目に値する。例えば、上のカメのビデオでは、生成されたカメには余分な足があります。また、Open-Sora 1.0は肖像画や複雑な画像の生成があまり得意ではありません。私たちはGitHubに計画リストを用意しており、既存のバグに対処し、生成の質を向上させていく予定です。
ちなみに、Open-Soraの公開を発表したXの投稿のリプに、以下のような「Open-Soraを揶揄するかのような」投稿がありました。
最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


