
OpenAI「Sora」(ChatGPT)とは?日本語での使い方・機能を解説

- 2024年12月9日に公開されたOpenAIの動画生成AI
- テキスト・画像・動画から動画を生成。最大20秒の動画を最短1分で作成可能
- 解像度やアスペクト比など詳細設定が直感的に選択できる
米国時間の2024年12月9日にOpenAIが動画生成AI「Sora」を正式リリースしました。同年2月15日の発表から約10ヶ月経っての登場です。
正式リリース版のSora(Sora Turbo)は、プレビュー版よりも生成速度がUPしていて、ChatGPT感覚で手軽に動画生成・編集できるのが魅力。後発のライバルに負けないクオリティの動画が生成できて、編集機能もあわせると以下のような動画まで作れちゃいます。
今回の記事は、Sora(初代)に焦点を当てて、Sora2との違いやSora(初代)を使うのに向いている人、機能や技術についてご紹介します。完読いただくと、すぐにでもSoraを使いこなせるようになっちゃう……かも。ぜひぜひ、最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Open AI Soraの概要
「Sora」は、ChatGPT を開発した OpenAI が公開した動画生成AIで、2024年2月にプレビュー版が登場したあと、同年12月に「Sora(Sora Turbo)」として正式版がリリースされました。複数の被写体の動きや背景との位置関係を破綻させずに扱える点が大きな特徴で、公開当初から高度なシーン生成が可能なモデルとして注目されてきました。類似の動画生成AIが後から次々と登場したものの、こうした複雑な構造を自然に再現するアプローチは、Sora が最初のモデルだとされています。
正式版となる Sora Turbo では、テキスト・画像・動画を入力して映像を生成できるほか、日本語プロンプトへの対応、直感的な動画編集やアレンジ、一度に二十秒の動画を生成できる処理能力などが備わっています。また、プレビュー版と比べて生成速度が向上し、短時間で映像を得られる点も実用的です。ChatGPT Plus や ChatGPT Pro の利用者であれば追加料金なしで使える仕様になっている点も大きな利点です。
ただし現在は、この Sora Turbo をベースに大幅に性能を向上させた 後継モデル「Sora 2」 が最新の動画生成モデルとなっています。映像の自然さや物理挙動の正確性、複数ショットの生成、商用利用の前提など、多くの部分で Sora Turbo を上回るよう改善されています。そのため、初代モデルを理解することは有益ですが、実際の利用を検討する際には最新の Sora 2 の情報をあわせて確認することがおすすめです。
なお、Sora2について詳しく知りたい方は、下記の記事を合わせてご覧ください。

Sora(初代)とSora2の違い
Sora(初代)と Sora 2 はどちらも OpenAI が開発した動画生成モデルですが、内部構造や表現力、扱えるショット数、動画の安定性など、性能には明確な差があります。初代モデルは短い動画の生成を中心に設計されており、被写体や背景の整合性に崩れが生じることがありました。一方で、Sora 2 は複数ショットの生成や物理挙動の再現性などが強化されており、より自然で破綻の少ない映像を扱える点が大きな進化といえます。
また、解像度や生成可能な秒数、商用利用を前提とした安定性についても Sora 2 の方が改善されており、利用環境や料金体系も最新モデルに合わせて整理されています。このため、Sora(初代)は Azure など特定環境での利用に限られる一方、Sora 2 は一般ユーザー向けの公開状況が進んでいるという違いがあります。動画生成を本格的に行う場合には、最新の Sora 2 に合わせて検討する方が安全です。
| 項目 | Sora(初代 / Sora 1 Turbo) | Sora 2(最新モデル) |
|---|---|---|
| モデルの位置づけ | 初期版。Azure 提供が中心 | 後継モデルとして正式展開 |
| 表現の精度 | 被写体の形状や物理挙動が崩れることがある | 動き・質感・因果関係がより自然に改善 |
| ショット生成 | 単一ショット中心 | 複数ショット(Storyboard)に対応 |
| 動画の長さ | 初代は短尺(秒数の制限が多い) | 最大約20秒の動画生成に安定して対応 |
| 解像度 | 720pが中心、制限あり | 720p〜1080pに対応(モデルにより異なる) |
| 生成の安定性 | シーン連続性が崩れやすい | 長尺でも破綻が少ない構造に改善 |
| 利用環境 | Azure OpenAI の条件下で利用 | ChatGPT Plus / Pro / API で利用可能 |
| 料金 | 公式の明確な公開なし(契約依存) | APIで秒課金(0.10〜0.50 USD / 秒)が公開 |
| 安全性・規制対応 | 初代のガイドライン準拠 | 最新の安全対策・ガイドラインに対応 |
| 日本語対応 | 対応しているが最適化は限定的 | 日本語プロンプトの解釈精度が向上 |
Sora(初代)を使うのに向いている人
Sora(初代)は、最新モデルである Sora 2 と比べると機能面にいくつか制限がありますが、その一方で特定の利用目的や制作環境では十分に活用できる場面があります。
Azure を中心とした開発環境を使っている人
Sora(初代)は Azure で利用できるモデルとして提供されているため、すでに Azure を使ったシステムやワークフローを持つユーザーには導入しやすい環境です。既存の基盤を変えることなく接続できる点は、開発コストの削減にもつながります。
短尺の動画を素早く試作したい人
企画段階やコンセプトの共有など、短い動画をスピーディーに生成したい場合には初代モデルが適しています。複雑な構成を必要としないアイデア出しでは、生成結果が早く確認できることが大きなメリットです。
映像品質よりもコストや手軽さを優先したい人
高解像度や長尺の映像が必須ではなく、まずはAI動画の生成そのものを試したい人にとっては、初代モデルでも十分に目的を果たすことができます。実験的な用途や予算を抑えたいケースでは初代を利用するのもよいでしょう。
Open AI Sora(初代)の機能を7つ紹介!
まずは、ついに登場した正式リリース版Sora(Sora Turbo)の機能・できることを7点ご紹介します。
- 動画生成
- 生成した動画の編集
- Storyboard
- Library
- Explore
- 画像生成
- 新しいシミュレーション
以下、基本の動画生成から、詳しくみていきましょう!
動画生成
Soraでは、他の動画生成AIよりも直感的に、Text-To-Video(テキストから)/ Image-to-Video(画像から)/ Video-to-Video(動画から)の動画生成が可能。プロンプトの入力と画像・動画のアップロードが一度に行えるインターフェースを備えているため、ChatGPTと会話する要領で気軽に動画生成ができちゃいます。
さらに、Soraではプロンプトの送信直後から下記のとおり、動画の詳細仕様も設定可。他の動画生成AIと違って、ごちゃごちゃした設定欄が一度に表示されないようになっています。
Soraで指定できる動画の仕様
- アスペクト比(16:9 / 9:16 / 正方形)
- 解像度(480p / 720 / 1080p)
- 動画の長さ(5秒 / 10秒 / 15秒 / 20秒)
- 生成するバリエーションの数(1 / 2 / 4 / 5)
プロンプトの送信と詳細設定を終えた後はなんと、最長でもたった1分の待ち時間で動画1本の生成が完了します。終始ストレスフリーで動画生成ができそうです。
生成した動画の編集
Soraで生成した動画は、そのまま編集にかけることができます。編集の方法は簡単で、生成した動画のなかから好きなものを選んで、以下4つのオプションを適用するだけです。
| 編集オプション | 詳細・できること |
|---|---|
| Remix | 動画内の要素を置換・削除・再構築して新しい表現を生成 |
| Re-cut | 動画の任意のフレームを使って動画を延長(後述のStoryboardが起動) |
| Loop | 動画をトリミングしてシームレスなループ動画を作成 |
| Blend | 2つの動画をシームレスに結合 |
使いこなせれば、SNS用のショート動画が一瞬で用意できちゃうかもしれませんね。
Storyboard
Soraは、タイムライン上で思い通りの動画が作れる「Storyboard」機能も備えています。
- タイムライン上での動画生成
- 動画の切り貼り
- 動画の延長
- 動画・画像のアップロード
- キャプションの追加
といった本格的な動画編集が可能。他の動画生成AIよりも、凝った動画が作れます。
| Style presets | 内容 |
|---|---|
| Cardboard & papercraft | 被写体や背景が段ボールや紙でできたペーパークラフトになる |
| Balloon World | 被写体や背景がバルーンアートになる |
| Stop Motion | 動画全体がコマ撮り風になる |
| Archival | 動画全体が昔のフィルムで撮影したような画質・深度になる |
| Film noir | 動画全体がヴィンテージ映画風の白黒映像になる |
以上の5種類です。うまく使って、面白い動画を生成しちゃいましょう!
Library
Soraの画面左側サイドバーには、生成した動画の管理・整理整頓を助けてくれる「Library」機能が備わっています。こちらからは……
- 生成した動画をお気に入り登録
- 生成した動画をリンクで共有
- 生成した動画をMP4形式でダウンロード
- タイル表示 / リスト表示の切り替え
- フォルダーの作成&動画の追加
といったことが可能です。
Explore
Soraの画面左側サイドバーからは、他のユーザーが生成した動画を閲覧できる「Explore」機能にもアクセス可。こちらでは、以下のようなことができます。
- 最近投稿された動画を閲覧
- OpenAIが選んだ秀逸な動画を閲覧(Featured Feed)
- 動画の編集内容の表示
- 動画のお気に入り登録
- 他のユーザーが公開した動画の報告
- 自分が公開した動画の削除
自分がSoraで動画を生成する際のインスピレーションが得られるかもしれませんね。
画像生成
本来Soraは、画像を生成することもでき、最大 2048×2048 の解像度までさまざまなサイズの画像を生成できます。
Prompt
Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field
画像生成AIとしても使用でき、動画にとどまらない高い汎用性を持っているんです!
新しいシミュレーション
Soraには、これまでの動画生成AIにはなかったようなシミュレーション能力があるといわれてます。
例えば、以下の動画のように、カメラが移動したり回転したりすると、人物やシーンの要素が 3 次元空間内を一貫して移動する動画が生成可能です。
また、ユニークな能力として、人工的なプロセスをシミュレートすることもできます。その一例として、ゲーム「Minecraft」のシミュレートが紹介されています。
Soraは、以下の動画のようにMinecraftのプレイヤーをコントロールすると同時に、世界とそのダイナミクスを忠実にレンダリングすることができるんです。
【プレイ動画】
【Soraによるシミュレーション】
なんなら本物のMinecraftよりリアルな映像ですよね!
そして、この機能は、「Minecraft」について言及するキャプションをソラに促すことでゼロショットで引き出すことができます。
このシミュレーション動画をテキスト入力のみで生成できるとは驚きです。
Soraのこの機能は、ビデオ モデルの継続的なスケーリングが、物理世界とデジタル世界、およびその中に住む物体、動物、人々の高機能シミュレーターの開発に向けた有望な道であることを示唆しています。


Open AI Sora(初代)の高品質な動画生成を実現している技術
ここからは、これまで紹介したようなSoraの機能を実現している技術について紹介します。
ここまで高性能なモデルはいったいどのような技術で成り立っているのでしょうか…?早速見ていきましょう!
ビジュアルデータのパッチ化
Soraでは、ビデオや画像をLLMのテキストトークンに似た小さなデータ単位であるビジュアルパッチの集合として表現します。
パッチは、視覚データのモデルを効果的に表現することが先行研究で示されており、さまざまな種類のビデオや画像で生成モデルをトレーニングするための非常にスケーラブルで効果的な表現です。

まず動画を低次元の潜在空間に圧縮し、次に表現を時空間パッチに分解することで、動画をパッチに変換します。
具体的な方法としては、以下の手順の通りです。
- 動画を構成する各画像を用意(動画は画像の集合体)
- 1をVisual Encoderに通すことで低次元に圧縮
- 2で圧縮されたデータを、上図右端の1次元ベクトルに平坦化(パッチ化)
要するに、「画像生成でいうところのVAE」のようなものでデータを圧縮し、それを1次元のベクトルに変換しているのです。そして、この1次元ベクトルを、LLMでいうところの「テキストトークン」として、学習時に扱うそうです。
このSoraのパッチ化では、Vision Transformer(画像をTransformerで扱う技術)やNaViT(Vision Transformerの改良版)の研究で提案された手法が踏襲されているそう。
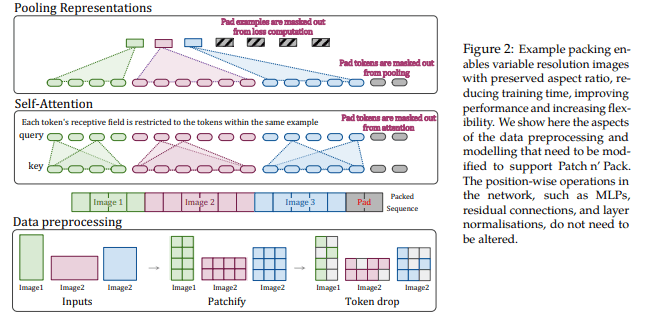
この手法を用いることで、畳み込み処理を使用せず、Transformer(LLM)で画像処理を行えるようになりました。Soraではこの技術を、動画の処理に応用しているのです。
Video compression network
Video compression network(ビデオ圧縮ネットワーク)は、視覚データの次元を削減するネットワークで、生の動画を入力として受け取り、時間的および空間的に圧縮された潜在表現を出力します。
Soraは、この圧縮された潜在空間でトレーニングされ、その後、この圧縮された潜在空間内で動画を生成します。
Spacetime Latent Patches
Spacetime Latent Patches(時空潜在パッチ)は、圧縮された入力動画が与えられると、トランスフォーマートークンとして機能する一連の時空パッチを抽出します。
パッチベースの表現により、Sora はさまざまな解像度、長さ、アスペクト比のビデオや画像でトレーニングでき、推論時にランダムに初期化されたパッチを適切なサイズのグリッドに配置することで、生成されるビデオのサイズを制御できます。
ビデオ生成用のスケーリングトランスフォーマー
Sora はディフュージョンモデルであり、ノイズの多いパッチ (およびテキスト プロンプトなどの条件付け情報) が入力されると、元の「きれいな」パッチを予測するようにトレーニングされます。

拡散モデルには通常、以下のような「U-Net」と呼ばれる「画像のセマンティックセグメンテーション用モデル」が使用されます。
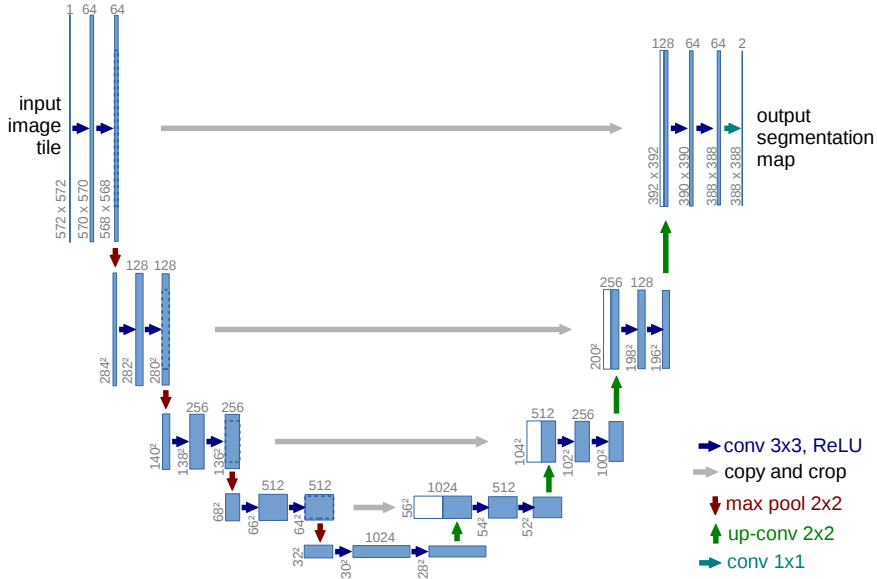
一方、SoraではU-Netではなく、Transformerを用いているのです。そうすることで、「画像を画像として処理するというアプローチ」から、「画像をテキストとして処理するアプローチ」に変換しているのでしょう。
以下が、Diffusion Transformerの概略図です。
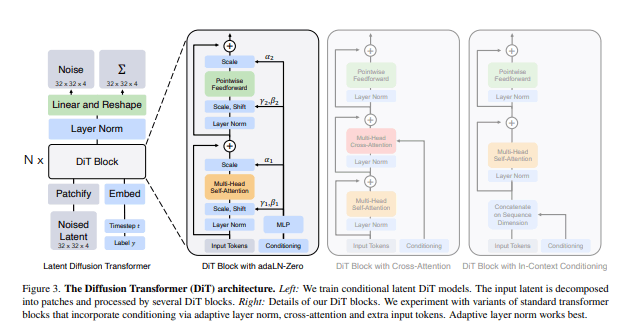
このアーキテクチャを用いることで、テキストを生成するかのように、動画を生成しているのでしょう。
ここで重要なのは、Soraはディフュージョントランスフォーマーであるということです。これは言語モデリング・コンピュータビジョン・画像生成など、様々な領域で顕著なスケーリング特性を示しています。
OpenAIは、ディフュージョントランスフォーマーが動画生成モデルとしても効果的であることを発見しました。
以下の例で、トレーニングの計算量が増えるにつれて、サンプルの品質は著しく向上することが示されています。
【Base】
【16倍】
言語理解
Soraは、DALL·Eの研究で得た成果、特にDALL·E 3からのキャプション再生成技術を応用し、非常に説明的なキャプションモデルをトレーニングし、次にそれを使用してトレーニングセット内のすべての動画のテキストキャプションを生成しています。
高度に説明的なキャプションの訓練は、生成動画の全体的な品質だけでなく、テキストの忠実度を向上させることが分かっているためです。
また、GPTを活用して短いユーザープロンプトを長い詳細なキャプションに変換し、モデルに送信します。これにより、Soraはユーザーのプロンプトに正確に従った高品質の動画を生成可能です。
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. We apply the re-captioning technique introduced in DALL·E 3 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model. This enables Sora to generate high quality videos that accurately follow user prompts.
引用:Video generation models as world simulators | OpenAI
和訳
具体的な手法は、以下の手順の通りです。
- ユーザーがテキストプロンプトを入力
- 1のテキストをLLMによって、より具体的な文章に変換
- 2のテキストを拡散モデルに送り込み、テキストに沿った画像を生成

こうすることで、ユーザーがDALL-E3に入力した「抽象的なプロンプト指示」を、より詳細なプロンプト指示文に変えられます。そのプロンプト情報をText Encoderを通して拡散モデルに送り込むことで、ユーザーの意図に沿った画像を生成できるのです。
こうすることで、ユーザーがDALL-E3に入力した「抽象的なプロンプト指示」を、より詳細なプロンプト指示文に変えられます。そのプロンプト情報をText Encoderを通して拡散モデルに送り込むことで、ユーザーの意図に沿った画像を生成できるのです。
このDALL-E3のキャプション技術を、Soraにも応用しています。
このキャプション技術については、以下のソニーのYouTube動画の6分30秒あたりから、詳しく解説されています。
こうすることで、高品質なテキストでキャプションされた動画のデータセットを得ることが可能です。機械学習においては、学習データの品質がモデルの精度を大きく左右するので、Soraの高品質な動画生成は、こうした工夫のたまものなのでしょう。
生成動画のラベリング
Soraでは正式リリースにあたって、Soraで生成した動画を識別するために以下2つの工夫がなされています。
- 不可視のC2PAメタデータによる出所の証明(DALL-E 3に準拠)
- ChatGPT Plusのみ、目に見える透かし・ウォーターマークの付与
ディープフェイクや盗作のリスクがある程度軽減されているといえるでしょう。
Soraの動画事例を知りたい方は、こちらの記事をご覧ください。

Open AI Sora(初代)を使用する際の注意点
大幅に強化されてついに登場したSoraですが、Sora(初代)では解決できていない注意点・課題があります。Sora(初代)を使用する際の注意点を詳しくみていきましょう!
物理的な整合性が崩れることがある
初代 Soraでは、物体が突然形を変えたり、背景と被写体の距離感が揺らいだりするなど、物理的な整合性が崩れるケースがあります。特に、手に持った物が消えたり、影のつき方が一貫しなかったりすることがあり、自然な映像として仕上げるためには、生成後に細かい確認が必要になります。Sora 2 ではこの点が大幅に改善されていますが、初代では依然として注意を払う必要があります。
人の著作物はアップロード不可
Soraでは、動画生成の参考用や切り貼りする用の画像・動画がアップロードできます。ただし規約上、以下に該当する人の著作物はアップロードができません。
- 自分が著作権を有していない画像・動画
- (フリー素材でも)必要な権利を全て取得していない画像・動画
- 本人から書面によるアップロード許可を得ていない他人の画像・動画
Soraで動画生成をする際には、画像生成AIで用意したイラストや自分で撮影した写真&動画を使うとよいでしょう。
人物画像も当面アップロード不可
Soraについては十分な安全対策がなされていますが、それでもディープフェイクやポルノコンテンツの生成に悪用されるリスクが否定できません。
そのためSoraでは、リリース後から当面の間、人物画像・人物動画のアップロードが拒否されます。今後、ディープフェイク対策が整うにつれて、この制限は緩和されるようです。
複雑な動きの表現はまだ苦手
今回正式リリースされたSora(Sora Turbo)は、2月のプレビュー版と比べて、動画生成の能力が大幅UPしています。ただ、以下の課題については、今なお解決中とのことです。
- 物理的性質の表現のエラー(例:ガラスが割れる様子を表現しづらい)
- 複数の被写体が複雑に動く構図でのエラー(例:動く物体が動物や人に変形する)
今後、多くのユーザーがSoraを使うにつれて、エラーの解決に欠かせないフィードバックが集まってくるはず。Soraの成長を暖かく見守ってあげましょう!


Open AI Soraの料金プラン・利用回数
2025年11月時点では、Sora(初代)を利用する際の公式に定められた秒単価・月間生成本数が公開されていないため、実際には利用契約時に確認が必要です。参考値として、後継モデル Sora 2 では1秒あたり USD 0.10 程度という情報が確認されています。また、非公式な報告として Sora 1 Turbo が約 USD 0.30/秒というものもありますが、これは公式値ではありません。
今後の情報公開に注目が必要です。
なお、ChatGPT Plusの料金について詳しく知りたい方は、以下の記事をご覧ください。

Open AI Soraは商用利用が可能!
Soraは、OpenAIの利用規約にさえ従っていれば、商用利用が可能です。OpenAIは、ChatGPTなどのツールそれぞれに対して共通の利用規約を適用しているので、Sora専用の利用規約はありません。※2
お客様とOpenAIの間において、適用法令で認められる範囲で、お客様は、(a)インプットの所有権限は保持し、(b)アウトプットについての権利を有するものとします。当社はアウトプットに関する権利、権原、及び利益がある場合、これらすべての権限をお客様に譲渡します。
引用:利用規約OpenAI
ただし、OpenAIのAIで生成したコンテンツは、今後のサービス改善のためにOpenAIに利用される可能性がある点には注意してください。
また、ChatGPTのPlusプランユーザーは、Soraで生成した動画にウォーターマークが入ってしまうので、商用利用するならウォーターマークの入らないProプランを契約する必要があります。
ChatGPTの商用利用や著作権問題について詳しく知りたい方は、以下の記事をご覧ください。

Sora(初代)と他の動画生成AIツールを比較
Sora以外にも、動画生成・編集機能を備えたAIツールは多数登場しています。そのなかでも、以下4種のツールは、Soraの手強いライバルです。
そんなライバルとSoraの違いは、比較すると下表のとおりです。
| Sora | Google Flow | Runway | Pika | Kling | |
|---|---|---|---|---|---|
| 特徴 | 物理法則の表現力に優れた元祖・拡散トランスフォーマーモデル | 「Veo3」により、会話音声・環境音・BGM付の動画が生成可 | 音声やリップシンクのカスタムが可能 | 遊び心満載のエフェクト「Pika Effect」が人気 | Soraと同じ技術をローコストで提供 |
| 日本語対応 | ⭕️ | ❌ | ❌ | ❌ | ⭕️ |
| テキストからの動画生成 | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ⭕️ |
| 画像からの動画生成 | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ⭕️ |
| 動画の延長 | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ⭕️ |
| カメラ操作 | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ⭕️ |
| 月々の生成回数制限 | なし | あり | あり | あり | あり |
| 料金プラン | ChatGPT Plus:月額20ドル ChatGPT Team:月額25〜30ドル ChatGPT Pro:月額200ドル | Google AI Pro:月額19.99ドル Google AI Ultra:月額249.99ドル | Basic:無料 Standard:月額12〜15ドル Pro:月額28〜35ドル Unlimited:月額76〜95ドル | Basic:無料 Standard:月額8〜10ドル Pro:月額28〜35ドル Fancy:月額76〜95ドル | Free:無料 Standard:月額10ドル Pro:月額37ドル Premire:月額92ドル(割引あり) |
| 1度に生成できる動画の長さ | 最長20秒 | 最長8秒 | 最長10秒 | 最長5秒 | 最長10秒 |
| 動画の最大解像度 | 1080p | 1080p | 720p | 1080p | 1080p |
| その他機能・特典 | ・高度な動画編集機能「Storyboard」 ・他ユーザーの動画を探索できる「Explore」 …and more! | ・会話音声 ・環境音 ・BGM付の動画生成 ・任意の被写体の追加 ・GIFダウンロード ・他ユーザーの動画を探索できる「Flow TV」 …and more! | ・音声のカスタマイズ ・リップシンクのカスタマイズ …and more! | ・エフェクトの選択 ・任意の被写体の追加 ・効果音の付与 ・リップシンク …and more! | ・任意の被写体 ・背景の追加 …and more! |
ライバルと比べてSoraには、「無制限に動画生成ができる」「有料版ChatGPTも使える」といった魅力があります。AIチャットから動画生成まで、有料AIツールを一本化したい方におすすめです。
Soraの使い方
ここからは、正式リリース版Sora(Sora Turbo)の使い方をスクリーンショット付きでご紹介します。まずは、Soraへのログイン手順から、みていきましょう!
ログイン
Soraへのログインは、Sora特設サイトから既存のChatGPT Plus / Team / Proアカウントを使って行えます。以下、その手順をみていきましょう!Soraの特設サイトにアクセスすると、画面右上に「Log in」ボタンがあるはず。まずはそちらをクリックしてください。
するとメールアドレスの入力欄が現れます。
ここでは、ChatGPTで使っているメールアドレスの他、Googleアカウント / Microsoftアカウント / Appleアカウントでのログインも可能。今回はメールアドレスを入力して「続行」を押してみましょう!
メールアドレス入力後は、パスワードの入力画面が現れます。こちらもChatGPTのパスワードを入力して、「続ける」をクリックしてください。
一通り入力を終えるとログインが完了し、以下のとおりSoraのホーム画面が表示されるはずです。
プリセットの登録
Soraでは、プリセットを登録しておけます。プリセットを登録しておくことで、カメラの設定・色・照明・色調・テーマなどをあらかじめセットしておけるので、必要なときにすぐに切り替え可能です。
プリセットを登録する際は、まずプロンプトの入力画面下にある以下のマークをクリックしてください。
「Manage」を開くと、初期登録済みのプリセットの内容を確認したり、新しくプリセットを登録できたりします。
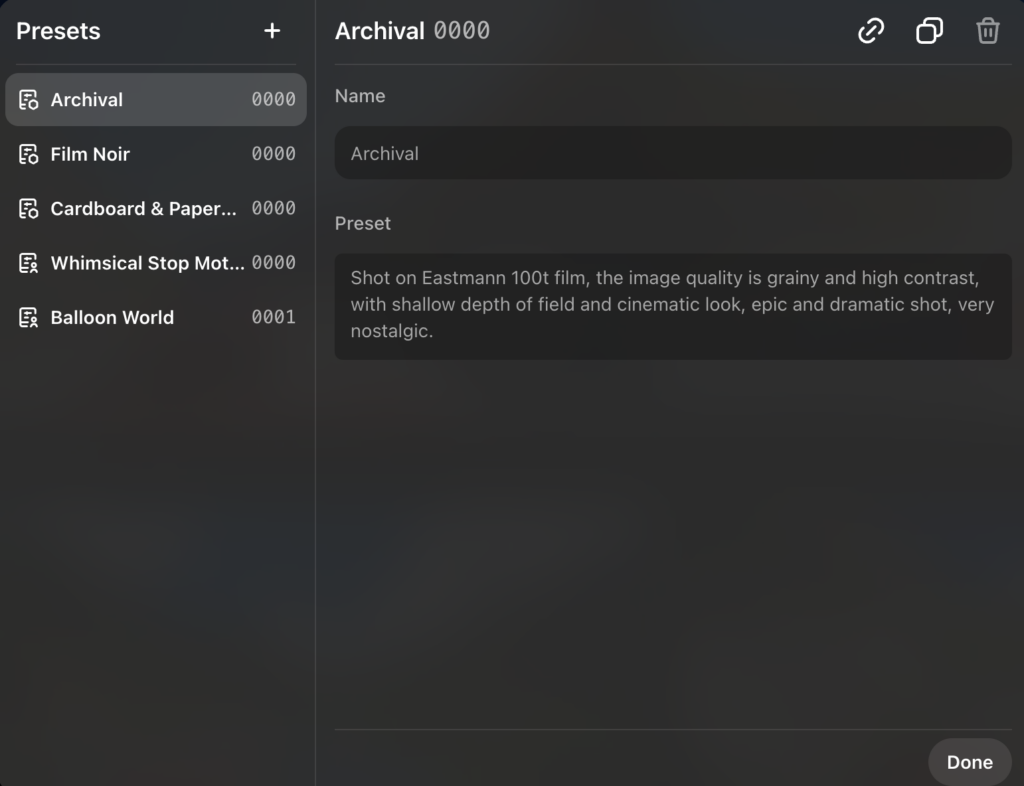
プリセットを登録して、動画生成の効率を高めましょう!
動画生成の方法
ここからは、Soraを使用した動画の生成方法を解説していきます。
今回は、以下の4パターンで動画を生成しました。
- テキストからの動画生成
- 生成した動画の編集
- 画像・動画からの動画生成
- Storyboard
それぞれの動画生成方法について詳しく解説していきます。
テキストからの動画生成
Soraの画面最下部にあるインターフェースからは、テキスト(英語のほか日本語もOK)での動画生成が可能。さらに、その下に並ぶボタンでは……
画像生成時に使えるボタン(右から順)
- 画像・動画のアップロード欄(+)
- 動画全体のトーン・エフェクト(Style presets)
- 生成する動画のアスペクト比
- 生成する動画の画質
- 生成する動画の長さ
- 一度に生成する動画のバリエーション数
- タイムラインでの動画編集(Storyboard)
- プロンプト送信(↑)
といったオプションも指定できちゃいます。
では早速、以下の条件をSoraに渡して、テキストからの動画生成を試してみましょう!
| 設定項目 | 詳細 |
|---|---|
| プロンプト | 白い猫がオレンジを割って立ち上がって出てきて、腰を振って踊っている様子。 |
| 動画全体のトーン・エフェクト | Balloon World |
| 生成する動画のアスペクト比 | 1:1 |
| 生成する動画の画質 | 480p |
| 生成する動画の長さ | 5s |
| 一度に生成する動画のバリエーション数 | 1v |
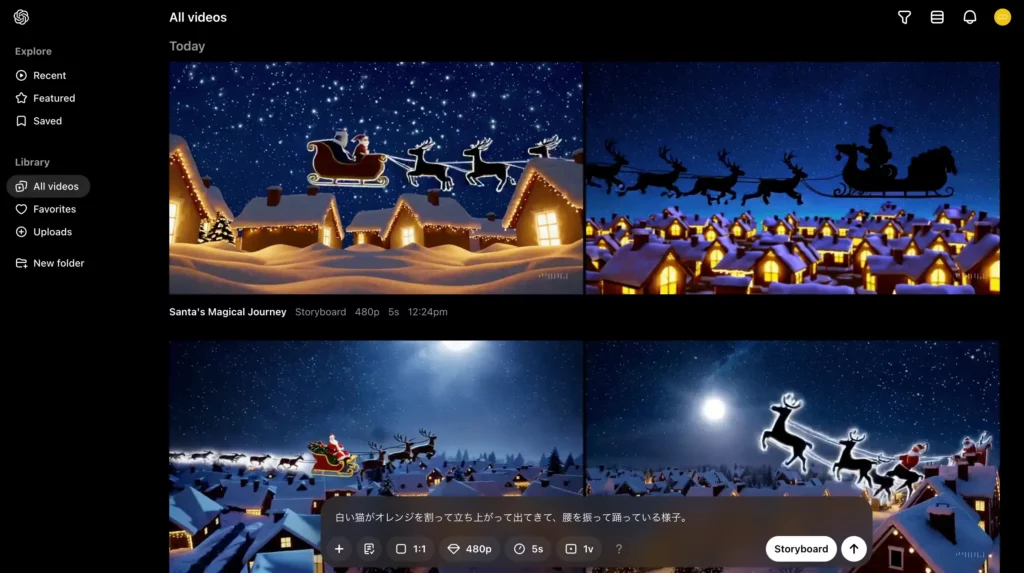
「↑」ボタンあるいはEnterキーでプロンプトを送信した後、しばらく待つと……
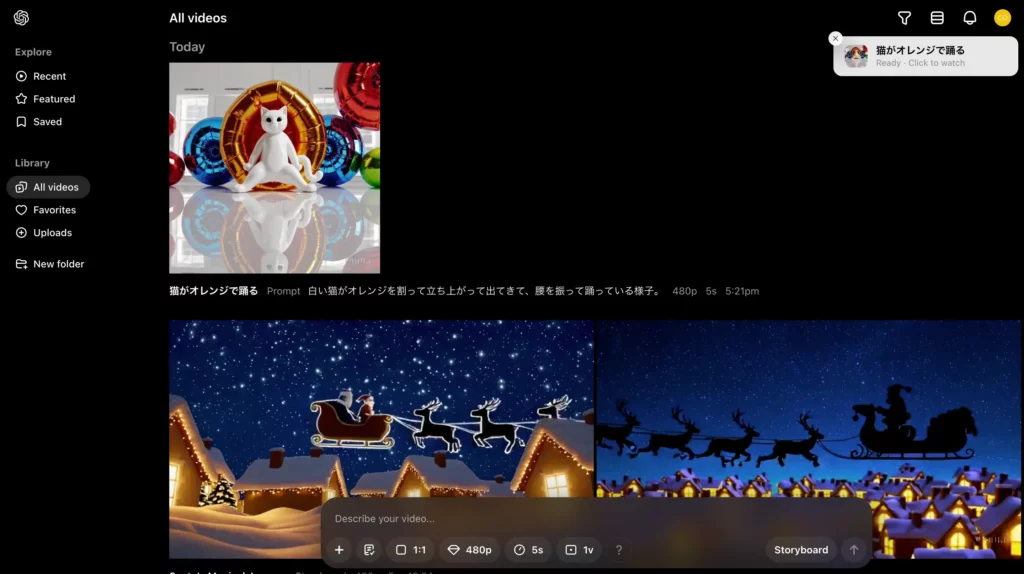
このように動画が生成されます。Soraが生成してくれた実際の動画は以下のとおりです。
見事、Soraはかなりアクロバティックな猫の動画を生成してくれています。ただ、首がねじれていたり、指定したとおりの動きではなかったりとエラーも目立つようす。入力するプロンプトは英語のほうがいいのかもしれませんね。
生成した動画の編集
さて、先ほどSoraで生成した動画をクリックしてみると……

このように画面下部に編集のオプションが現れます。ここでそれぞれのオプションを選んでできることは……
- Edit prompt:プロンプトを変えて動画生成
- View story:動画のタイムラインを確認
- Re-cut:動画の一部を延長
- Remix:プロンプトで動画を再構築
- Blend:2つの動画から新たな動画を生成
- Loop:動画の一部からループ動画を作成
以上のとおりです。
それではまず、この動画を使って「Remix」の手順をみていきましょう。ということで、Remixをクリックしてください。
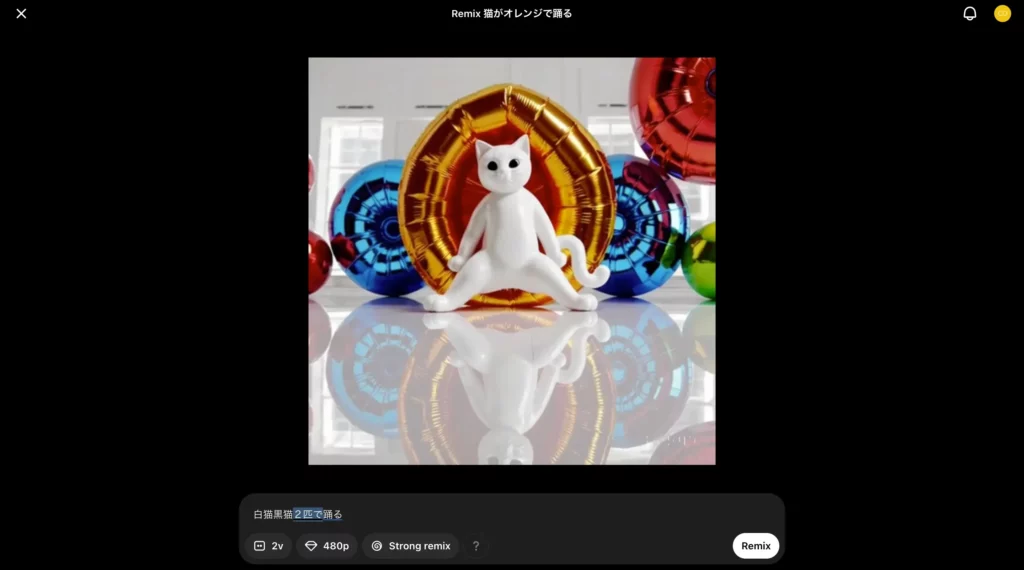
するとこのように、Remix用の設定画面が現れるはず。ここではプロンプトの入力のほか、一度に生成するバリエーション数・画質・Remixの度合いが選べます。
とりあえず今回は、Strong Remixを選んで「白猫黒猫2匹で踊る」というプロンプトをSoraに渡してみましょう!プロンプトを送信後、しばらく待つと、
先ほどの動画に黒猫が追加されました。
続いては、今Remixした動画と元の動画を「Blend」で混ぜて、新たに1つの動画を生成してみます。ではまず、混ぜたい動画をクリックしたあと、画面下部のBlendから「Choose from library」を選択しましょう!
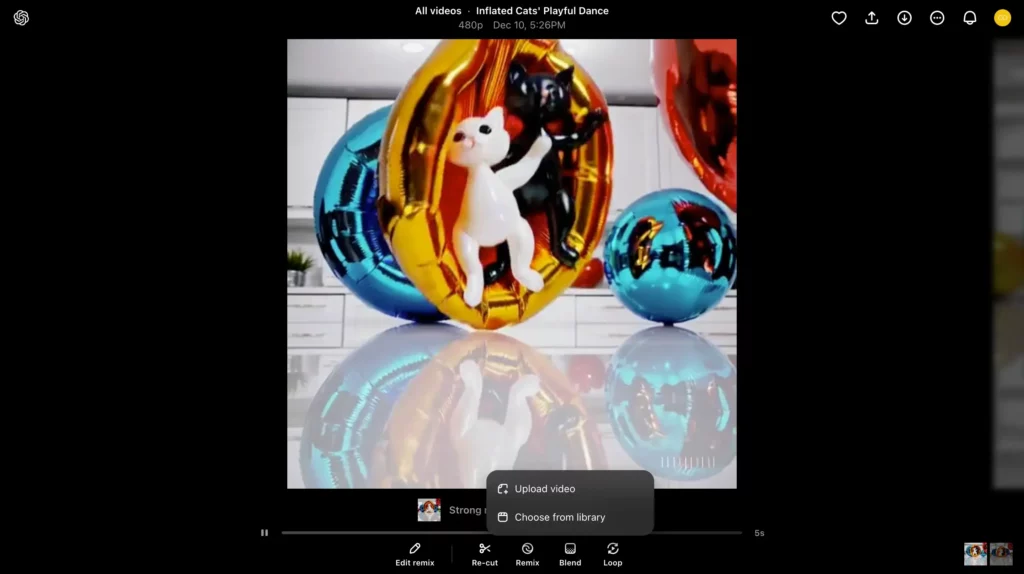
すると以下のとおり、Blendに使う動画が選べます。今回はここから、一番始めに生成した猫の動画を選んでみましょう。
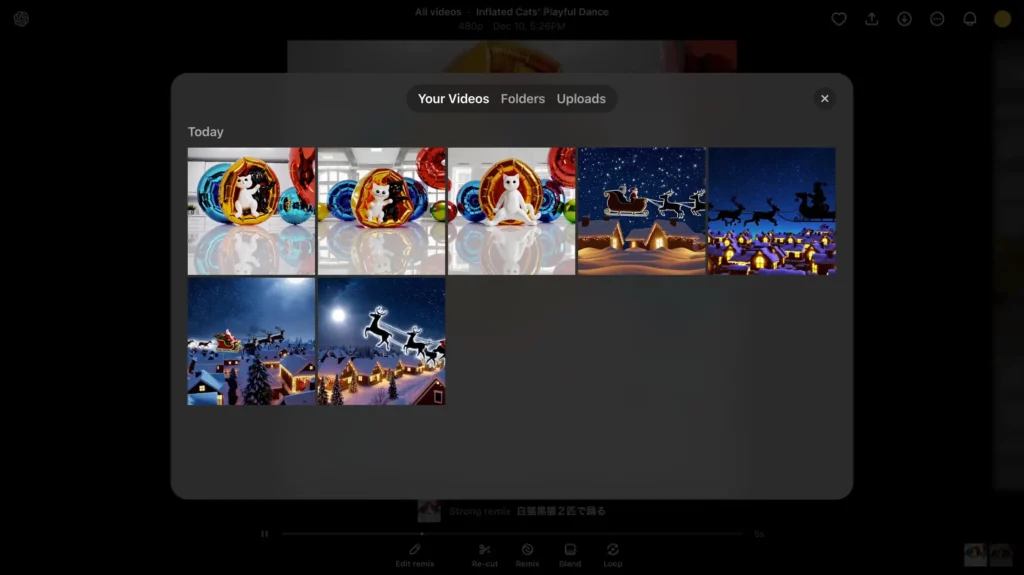
2個目の動画を選ぶと、以下のとおりBlendの操作画面に移ります。ここでは曲線の範囲をマウス操作で調整することで、Blendの比率が変更可。さらに、画面下部・左から3番目のボタンをクリックしてみると……
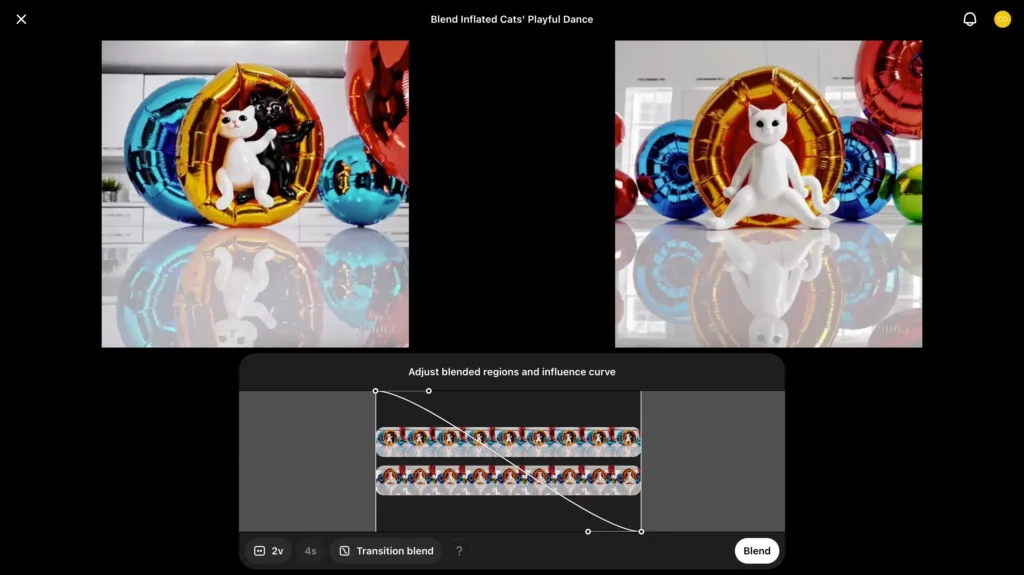
以下のとおりBlend比のテンプレートが選べます。
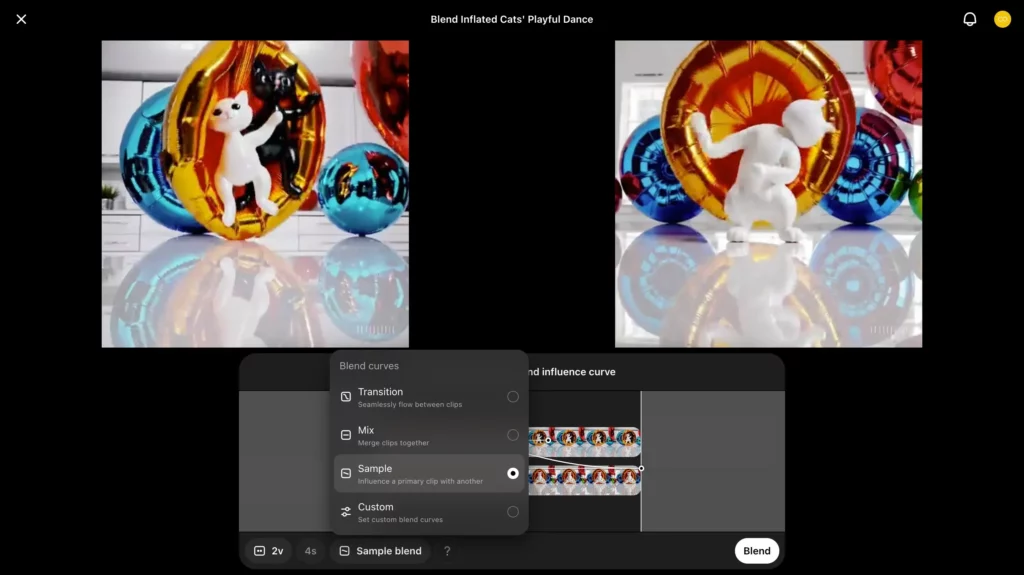
このテンプレートから「Sample」を選んでみると……
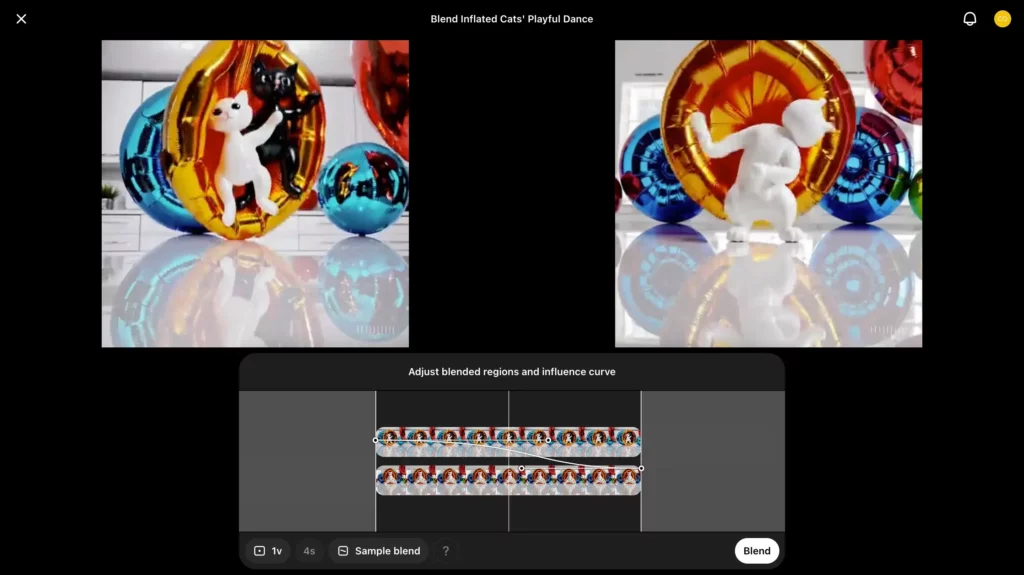
以上のとおり、自動でいい感じの曲線が設定されています。あとは「Blend」をクリックするだけで、
白猫黒猫の動画と白猫単体のダンス動画が混ざって、新しい動画になっていますね。
今度は、Blendした動画を「Loop」でループさせてみます。ループさせたい動画を選択して、画面下部からLoopを選ぶと……
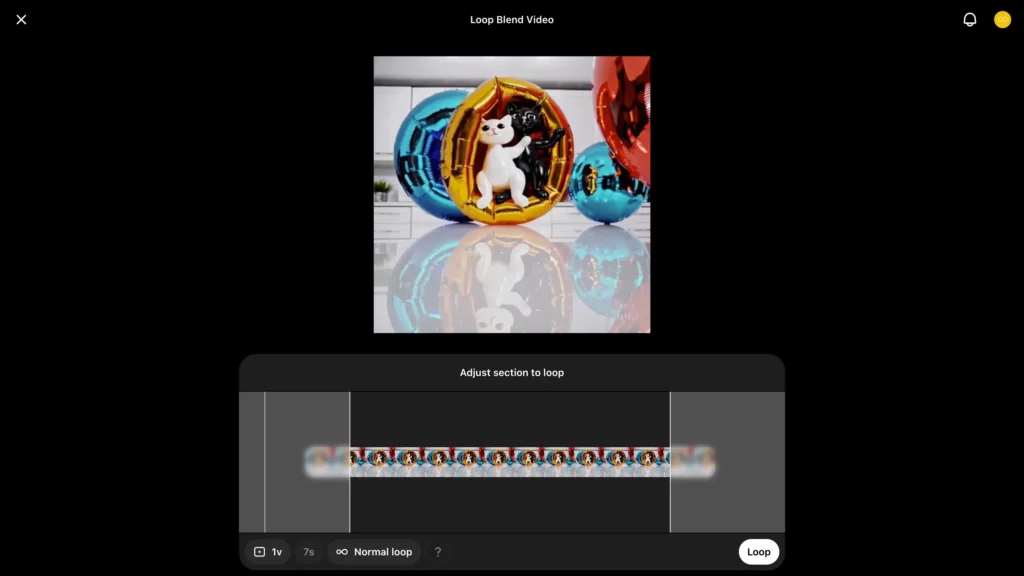
このように編集画面が開きました。ここでは、ループさせる範囲が指定できるほか、ループ動画の長さがShort(2秒)/ Normal(4秒)/ Long(6秒)から選べます。諸々の設定を済ませたあと、「Loop」をクリックすると、
このように、ループ動画が完成しました。
最後に、今用意したループ動画について、「Re-cut」でお気に入りのシーンを延長してみます。任意の動画で画面下部のRe-cutをクリックすると……
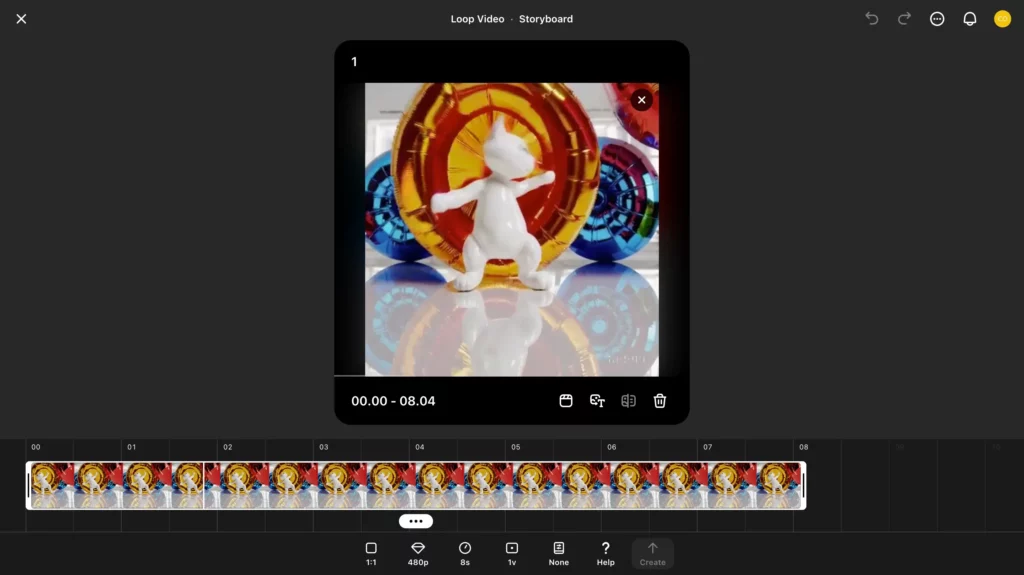
このように、タイムライン上でRe-cutで延長する範囲が選べます。試しに動画を前後に縮めて……
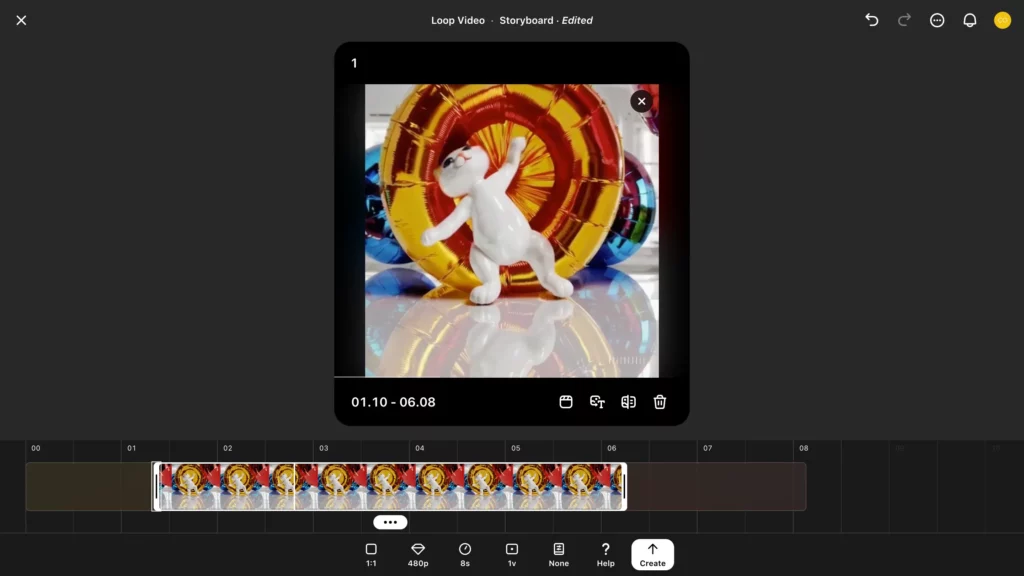
画面右下「↑Create」をクリックしてみましょう!
するとこのように、お気に入りの箇所を前後に伸ばした動画が返ってきます。
ちなみに、SoraのRe-cutでは動画→テキストへの逆変換も可能。その処理は……
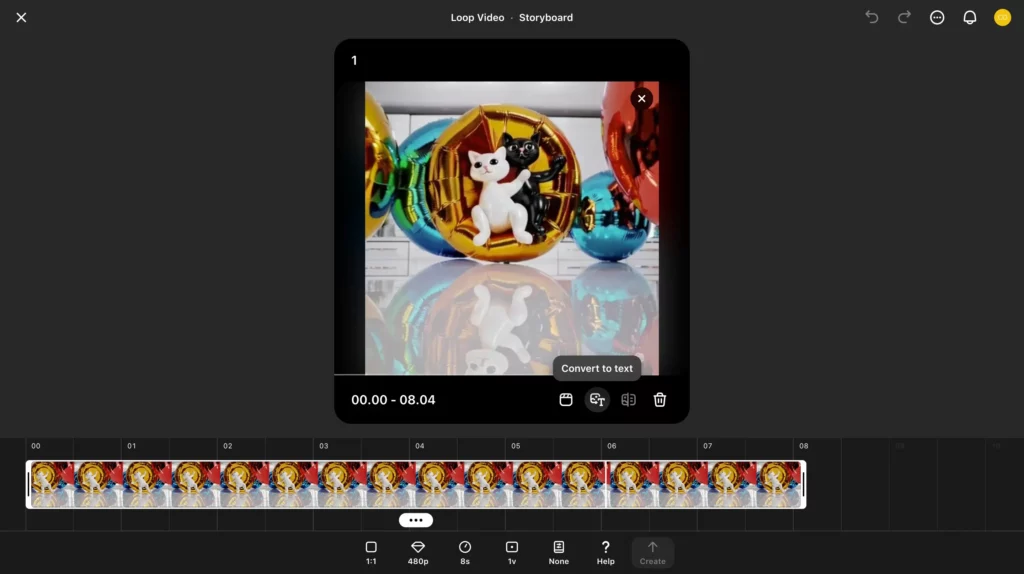
以上のとおり「Convert to text」から行えます。試しにクリックしてみると、
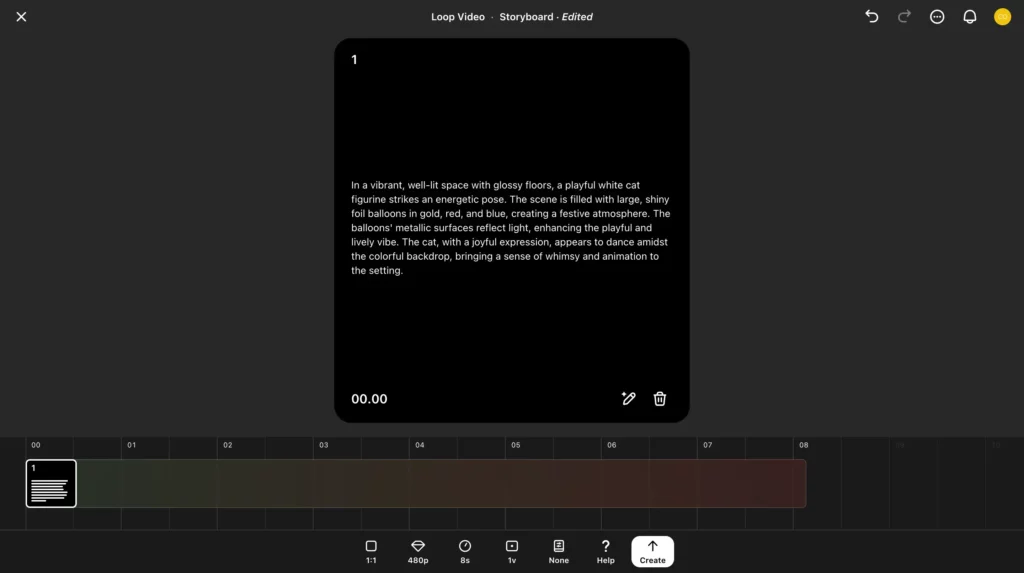
動画の内容を説明した英文のプロンプトが返ってきていますね。
画像・動画からの動画生成
今度は、画像・動画からの動画生成についても方法をお見せします。まずは、動画生成用インタフェースの左下「+」をクリックしてみてください!
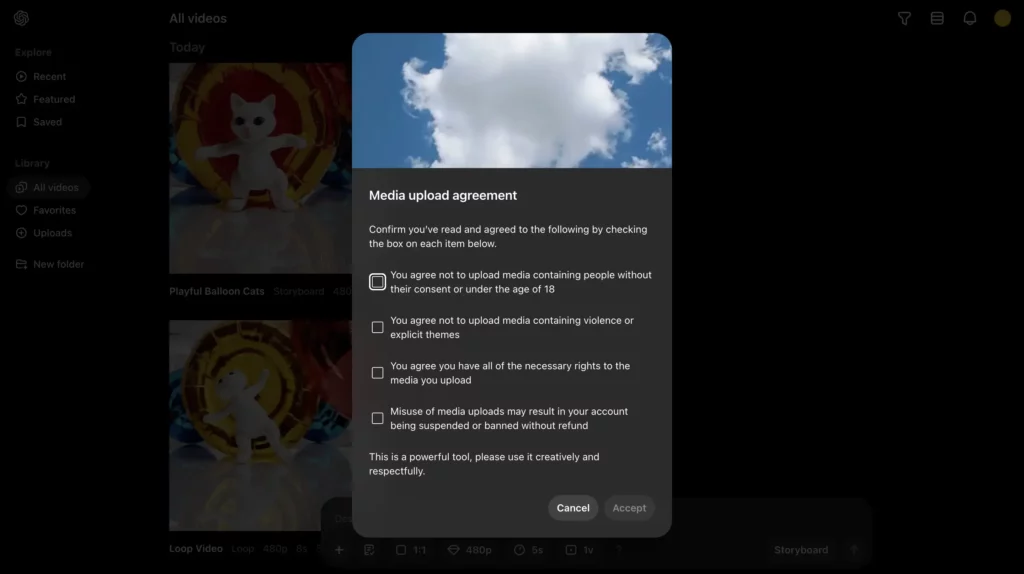
すると、このように画像・動画のアップロードにあたっての規約が表示されます。各チェック項目の内容は、
規約・同意事項の和訳
- 本人の同意がない場合or18歳未満の人を含むメディアをアップロードしないことに同意する
- 暴力や露骨な表現を含むメディアをアップロードしないことに同意する
- アップロードするメディアに必要なすべての権利を有することに同意する
- アップロードしたメディアを悪用した場合、アカウントが払い戻しなしに停止or削除されることがあることに同意する
以上のとおりで、かなり厳しい感じです。それぞれ理解した上でチェックを入れて「Accept」をクリックしましょう!
規約に同意すると、動画生成用インタフェースの左下「+」から、画像・動画がアップロードできるようになります。今度は猫の写真(ライターが撮影したもの)をアップロードして、以下の条件をSoraに渡してみましょう。
| 設定項目 | 詳細 |
|---|---|
| プロンプト | 猫が宇宙へロケットのように飛び立つ |
| 動画全体のトーン・エフェクト | Stop Motion |
| 生成する動画のアスペクト比 | 16:9 |
| 生成する動画の画質 | 480p |
| 生成する動画の長さ | 5s |
| 一度に生成する動画のバリエーション数 | 1v |
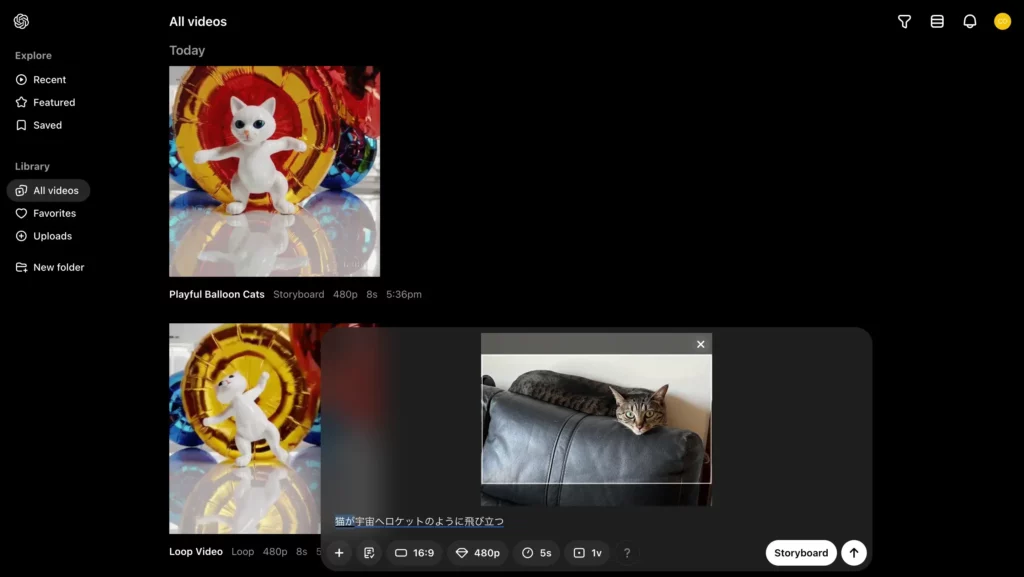
プロンプトを送信すると……
このように、元の画像をベースにした動画が生成されます。動きはリアルですが、やはり日本語だと命令がうまく反映されないようですね。
Storyboard
Soraでは、動画生成用インタフェースの右下「Storyboard」から、タイムライン形式の動画生成&編集が行えます。試しにクリックしてみましょう!
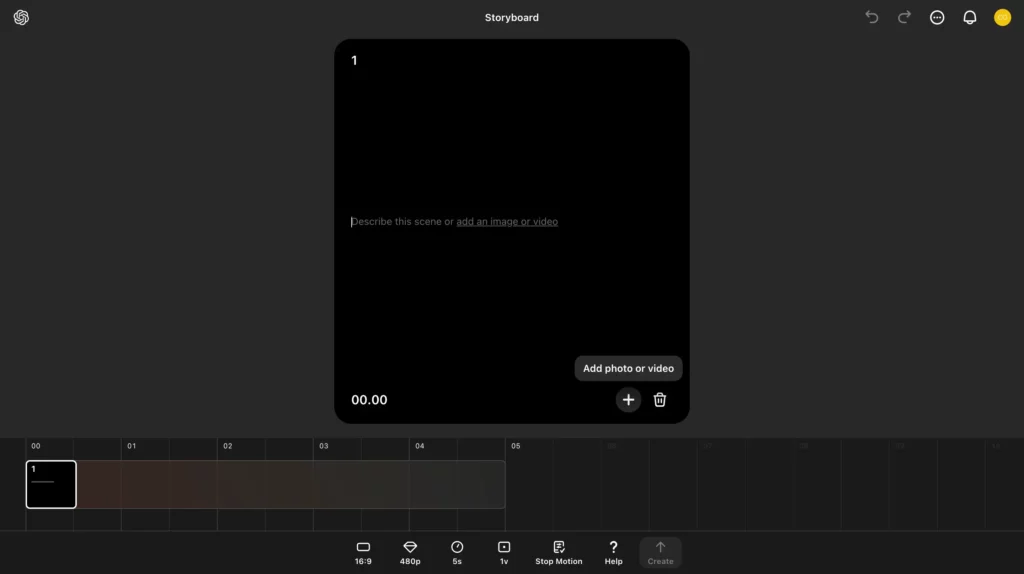
するとこのように、動画を貼り付けるためのカードが表示されます。このカードからは……
- カード右下「+」(Add photo or video):Sora上の動画の選択 / 動画・画像のアップロード
- カード中央テキストボックス(Describe this scene or add an image or video):プロンプトの入力
- ゴミ箱:カードの削除
といったことが可能です。
それでは、試しに以下の設定をSoraに渡して、動画生成を行ってみます。
| 設定項目 | 詳細 |
|---|---|
| カード1の動画 | 最初にテキストから生成した動画(白い猫がオレンジを割って立ち上がって出てきて、腰を振って踊っている様子。) |
| カード2のプロンプト | Santa’s sleigh flies gracefully over the town, with reindeer leading the way, leaving a sparkling trail in the night sky. |
| 動画全体のトーン・エフェクト | Stop Motion |
| 生成する動画のアスペクト比 | 16:9 |
| 生成する動画の画質 | 480p |
| 生成する動画の長さ | 5s |
| 一度に生成する動画のバリエーション数 | 1v |
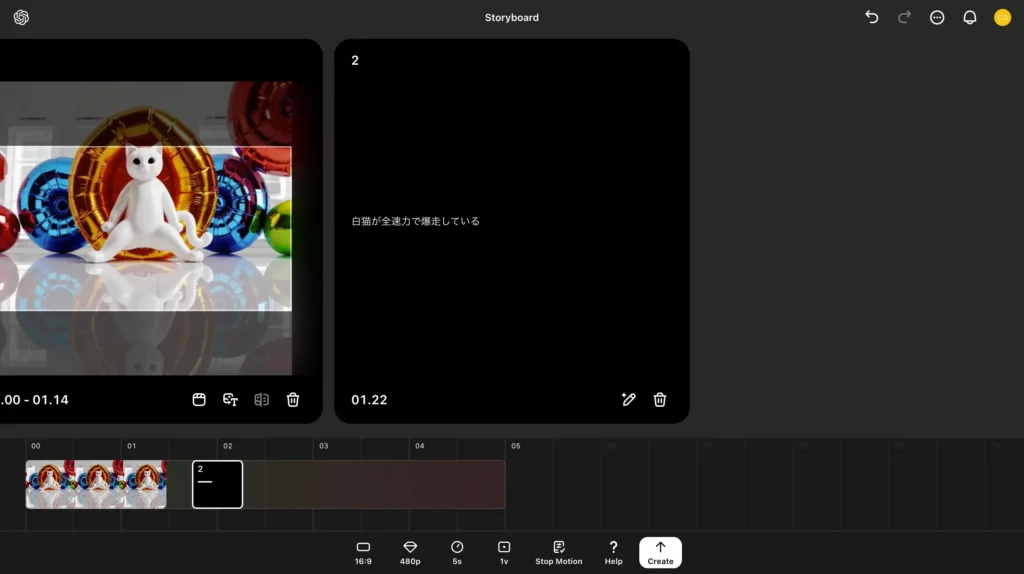
気になる結果のほどは……
こんな感じ!被写体が猫というよりはネズミだったり、爆走していなかったりとツッコミどころは満載ですが、それなりの動画が返ってきていますね。
Sora(初代)でクリスマス動画を作ってみた!
Soraの「Storyboard」は、使い方次第で凝った動画が作れます。今回は以下の設定をSoraに入力して、クリスマスにぴったりなショートムービーを作ってみました!
| 設定項目 | 詳細 |
|---|---|
| カード1のプロンプト(0秒〜) | On Christmas night, Santa Claus rides his sleigh across a snowy town under a starry sky. Santa, in his classic red outfit and white beard, carries a large sack of gifts. He smiles warmly as he delivers presents to children’s homes. His sleigh, pulled by reindeer, soars over houses glowing with cozy lights. The snow-covered rooftops and twinkling stars create a magical atmosphere, with Santa’s silhouette clearly visible against the night sky. |
| カード2のプロンプト(2秒〜) | Santa’s sleigh flies gracefully over the town, with reindeer leading the way, leaving a sparkling trail in the night sky. |
| カード3のプロンプト(4秒〜) | The final scene shows children waking up with joy and excitement as they discover the presents Santa left for them, surrounded by a warm, festive home environment. |
| 動画全体のトーン・エフェクト | None |
| 生成する動画のアスペクト比 | 16:9 |
| 生成する動画の画質 | 480p |
| 生成する動画の長さ | 5s |
| 一度に生成する動画のバリエーション数 | 2v |
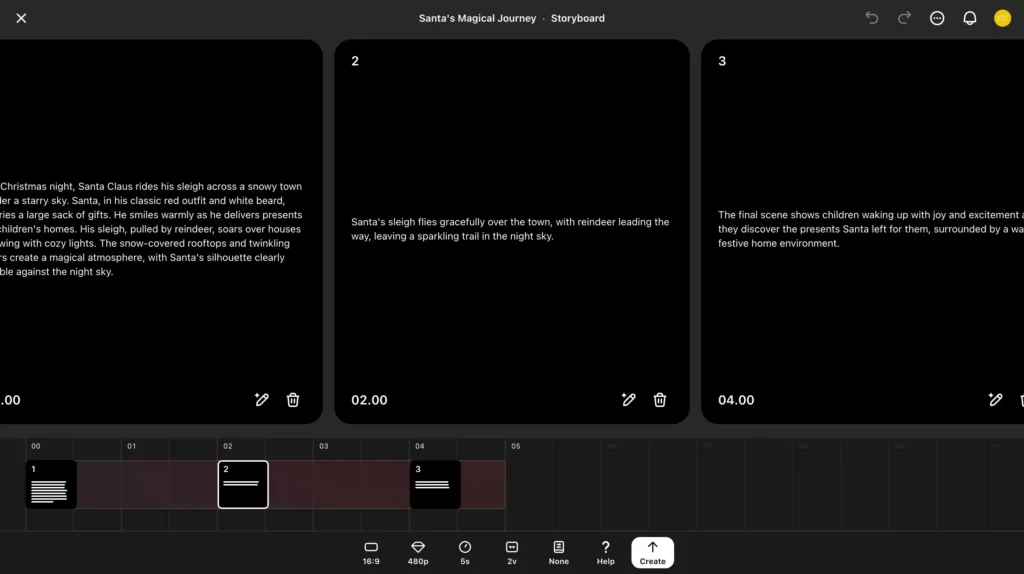
Createをクリックすると……
まるでプロが編集したかのような動画が返ってきました。
やはり、プロンプトは英語で詳しく記述した方がよいようです。これなら、TikTokやYouYubeショート用の動画も簡単に作れちゃうかも。みなさんもぜひぜひ、お試しください!
OpenAI Soraの導入事例
OpenAIのSoraは、すでに以下をはじめとしたいくつかの企業が導入しています。
- トイざらス
- 株式会社AI HYVE
- Adobe Premiere Pro
現状、企業の広告動画制作や動画編集サービスの付加価値向上に役立てられているようです。
以下で、各企業の導入事例を詳しく解説していきます。
トイざらス
玩具量販店大手の米トイザらスは、OpenAI Soraを使って、約1分程度のWebコマーシャル動画を生成して公開しました。※5
動画内容は、トイザらス創業者のチャールズ・ラザラス氏の幼少期を実写化したものとなっており、同社のマスコットキャラクター「ジェフリー」と交流する内容になっています。
なお、動画制作には、動画制作会社の米Native Foreignも協力しているとのことです。
株式会社AI HYVE
AI×マーケティングを扱う株式会社AI HYVEは、2024年12月11日より、日本初・Soraを活用したCM制作支援サービス「Neuron Vids(β)」をベータリリースしています。(※6)
このNeuron Vids(β)では実写での再現が難しい動画素材をSoraに生成させることにより、安価かつスピーディーな制作体制を実現。そこにマーケターの視点を掛け合わせることで、「AIでCMを作って終わり」にならないサービスを提供しています。
Adobe Premiere Pro
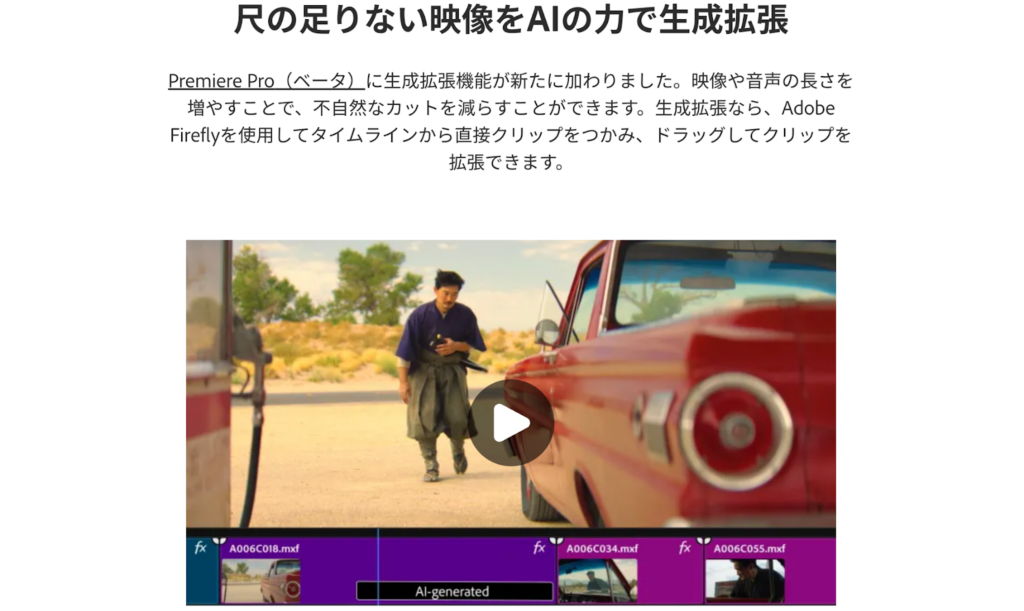
アドビ株式会社が提供している動画編集ソフト「Adobe Premiere Pro」には、Soraを含む4種類の動画生成AIが搭載されています。
- Adobe Firefly Video Model:Adobe自社開発の動画生成AI
+
- Sora:OpenAI製のサードパーティ動画生成AI
- RunwayML:Runway製のサードパーティ動画生成AI
- Pika:Pika製のサードパーティ動画生成AI
動画生成AIの実装によって、追加された機能は以下のとおりです。
- 動画の生成拡張
- 動画中オブジェクトの追加と削除
- Bロールショットの生成
- サードパーティー製動画生成AIの選択
とくに、尺が足りていない部分を埋められる動画の生成拡張が便利です。元の動画シーンに合わせて、最適な動画をAIが生成して繋ぎ合わせてくれます。
Adobe Premiere ProとSoraの連携について詳しく知りたい方は、以下の記事をご覧ください。

Soraは他のモデルとは一線を画す超高性能動画生成AIモデル!
Sora(初代)は、2024年2月15日に発表されて同年12月9日に正式リリースされたOpenAI社の動画生成AIモデルで、現実と見分けがつかないほどリアルで高精細な動画を生成してくれます。
最後に、そんなSoraの特徴をまとめます。
- テキストから動画への変換: Sora(初代)は、テキストプロンプトに応答して超高品質の動画を作成する能力を持っています。
- ビデオ生成用のスケーリングトランスフォーマー:Soraはディフュージョントランスフォーマーであり、これは動画生成モデルとしても有用で、トレーニングの計算量に応じて著しく性能が向上します。
- Text-To-Video以外の機能:Soraには、生成された動画の拡張、動画の編集、動画の接続、画像生成などのText-To-Video以外の機能も充実しています。
- 他のモデルの技術の応用:Soraは、DALL·E 3からのキャプション再生成技術を応用し、トレーニングセット内のすべての動画のテキストキャプションを生成します。また、GPTをGPTを活用して短いユーザープロンプトを長い詳細なキャプションに変換します。
OpenAI曰く、「Sora は、現実世界を理解してシミュレーションできるモデルの基盤にして、 AGI を達成するための重要なマイルストーンである」のこと。
このモデルが生成する動画や機能を見せられたら、私たちが想像しているよりも早くAGIが実現してしまうのではないかと期待してしまいますね!

最後に
いかがだったでしょうか?
動画生成AIを事業にどう活かせるか、具体的な活用方法や効果的な導入事例を元に専門家が最適なソリューションをご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

