
【GPT-4o Transcribe/Mini Transcribe】Whisper超え!?OpenAIの次世代音声認識モデルの性能から使い方まで徹底解説
- 従来のWhisperモデルに比べ、誤認識を大幅に削減
- 100以上の言語に対応
- 高速版(廉価版)モデルを用意
2025年3月21日、OpenAIが、次世代音声認識モデル「GPT-4o Transcribe」「GPT-4o Mini Transcribe」を公開しました!
「GPT-4o Transcribe」は、従来のWhisperモデルを上回る性能を持ち、「Whisper超え」の異名どおり、業界最先端の精度と信頼性を実現しており、人間に近いレベルの聞き取り精度と堅牢性で、テキストベースのAIエージェントを音声対話へと拡張するような仕組みになっているようです。
一方の「GPT-4o Mini Transcribe」は、「GPT-4o Transcribe」の軽量モデル的位置づけとなっています。
本記事では、そんな「GPT-4o Transcribe」と「GPT-4o Mini Transcribe」の概要から使い方までご説明します。
ぜひ、最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
GPT-4o TranscribeとGPT-4o Mini Transcribeの概要
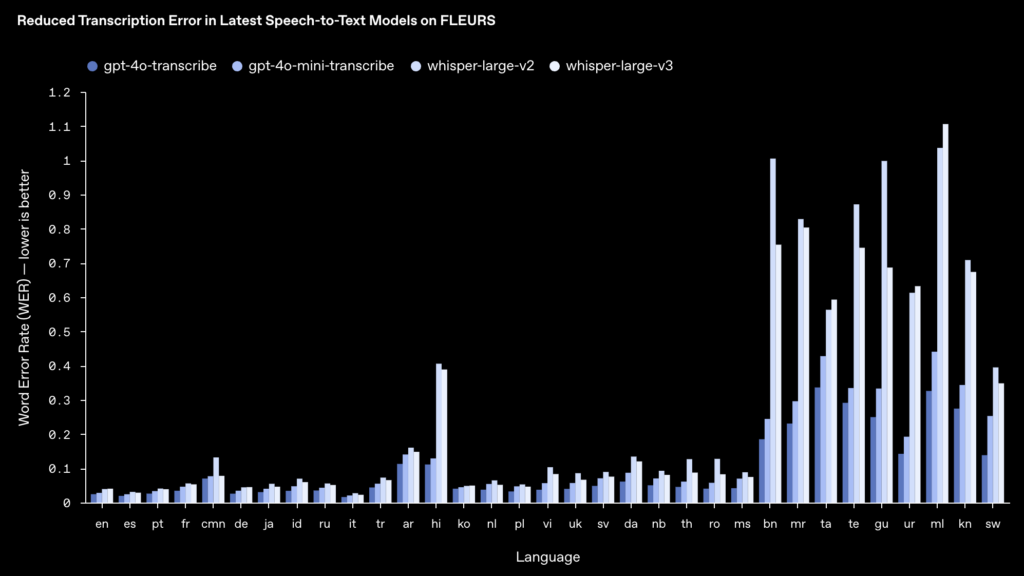
GPT-4o TranscribeとGPT-4o Mini Transcribeは、いずれもWhisperを凌ぐ精度を示す次世代モデルです。
特に、多言語ベンチマーク「FLEURS」において、ほぼ全ての言語でWhisper v2/v3を上回る低いWER(以下画像の棒グラフの青色がGPT-4o系列)を達成しています。
両モデルの概要は以下の通りです。
GPT-4o Transcribe
最新フラッグシップ音声認識モデルで、最高レベルの精度を追求したモデルです。
語彙のニュアンスを捉える能力が高く、難解な専門用語や固有名詞も聞き取りやすくなっています。複数の公式ベンチマークでWhisper大型モデルを上回る性能を示しており、音声データからの文字起こし精度・信頼性の新たな基準を打ち立てています。
また、100言語以上に対応しており、多言語環境下でも高精度な転写ができることが強みです。
GPT-4o Mini Transcribe
GPT-4o Transcribeの軽量高速版であり、モデルサイズを小型化し、推論速度を向上させた代わりに、一部精度がGPT-4o Transcribeより劣る設計となっています。
とはいえ、その性能は依然としてWhisper大型モデル以上であり、特にリアルタイム性が求められる用途で威力を発揮します。
また低コストで利用でき、長時間の音声ストリームや大量データ処理においてコスト面でメリットがあります。精度と速度のバランスに優れることから、サーバー負荷を抑えつつ高品質な文字起こしを行いたい方に適したモデルといえます。
Whisperとの比較
Whisperとの比較では、GPT-4o Transcribeシリーズはいずれも速度・精度の両面で優位に立っています。
Whisper大型モデル(API提供されているwhisper-1相当)は高精度でしたが、GPT-4o Mini Transcribeで既にそれを上回る低エラー率を達成し、GPT-4o Transcribeではさらにエラー率が下がっているようです。
一方で、誰が喋ったかの識別「話者分離」については、現状GPT-4oモデルは対応していない点には注意しておきましょう。
総じて、GPT-4o TranscribeはWhisperの強みであった多言語対応と精度の高さをさらに推し進め、加えて、応答速度の改善やAPI連携の容易さを実現した新世代の音声認識モデルと言えます。


GPT-4o TranscribeとGPT-4oMini Transcribeの仕組み
GPT-4o TranscribeとMini Transcribeの高精度・高性能を支える技術的アプローチについてみていきましょう。
OpenAIはこれら音声モデルの開発にあたり、既存の大規模言語モデル技術をベースに音声データ特化の訓練と強化学習を組み合わせるアプローチを取っているようです。
GPT-4o Transcribe
GPT-4o Transcribeはその名前から分かるとおり「GPT-4o」アーキテクチャを基盤としています。
GPT-4oは音声・画像・テキストをリアルタイムで処理できるマルチモーダル拡張を施したモデル。その音声処理部門としてTranscribeモデルが位置付けられています。
具体的には、大規模なTransformerモデルに音声波形を直接入力しテキストへ変換する設計で、「音声波形→音素表現→テキスト」という従来型の段階的ASR(自動音声認識)とは異なり、end-to-endで音声からテキストへのマッピングを学習しています。
OpenAI公式ドキュメントによると、GPT-4o Transcribeの精度向上つながった大きなポイントが、大量かつ多様な音声データセットでの中間訓練と強化学習(RL)のようです。
GPT-4o Transcribeシリーズは、多彩で高品質な音声データを用いた大規模な事前学習(プリトレーニング)と中間トレーニングを経ており、100以上の言語や様々な話者の話し方に対する深い音声認識能力を獲得し、珍しい訛りや専門用語でも文脈から適切に認識できるようになっています。
また、転写精度を極限まで高めるために、強化学習を組み込んだ訓練プロセスが採用されており、これにより、誤変換の減少や幻覚の抑制が図られています。
GPT-4o Mini Transcribe
軽量版のGPT-4o Mini Transcribeは蒸留技術によって誕生しました。蒸留とは、大きな教師モデルのナレッジを小さなモデルに圧縮して継承させる手法です。
OpenAIは、GPT-4o Transcribeの知見をGPT-4o Miniに効率良く継承させるため、高度な自己対話(self-play)を活用した独自の蒸留データセットを構築しています。
これにより、小型モデルでありながら大モデルに迫る性能を発揮し、会話文脈での自然な応答品質も担保されています。
また、モデルサイズが削減されることで、メモリ消費や計算量が抑えられ、クラウド上での処理速度向上にも繋がっています。
GPT-4o TranscribeとGPT-4o Mini Transcribeのライセンス
GPT-4o TranscribeとGPT-4o Mini TranscribeはOpenAI APIを通じて提供されており、基本的な商用・私的利用は許可されていますが、モデル自体の改変や再配布は許可されていません。詳細は以下の表の通りです。
| 利用用途 | Transcribe | Mini Transcribe |
|---|---|---|
| 商用利用 | ⭕️ | ⭕️ |
| 改変 | ❌️ | ❌️ |
| 配布 | ❌️ | ❌️ |
| 特許使用 | 🔺(OpenAIの許可が必要) | 🔺(OpenAIの許可が必要) |
| 私的使用 | ⭕️ | ⭕️ |
※利用条件は定期的に更新される可能性があるため、最新の情報については公式ページ、公式ドキュメントを確認することをおすすめします。
GPT-4o Transcribeの使い方
ここでは、「GPT-4o Transcribe」の使い方をみていきます。
APIキーの取得
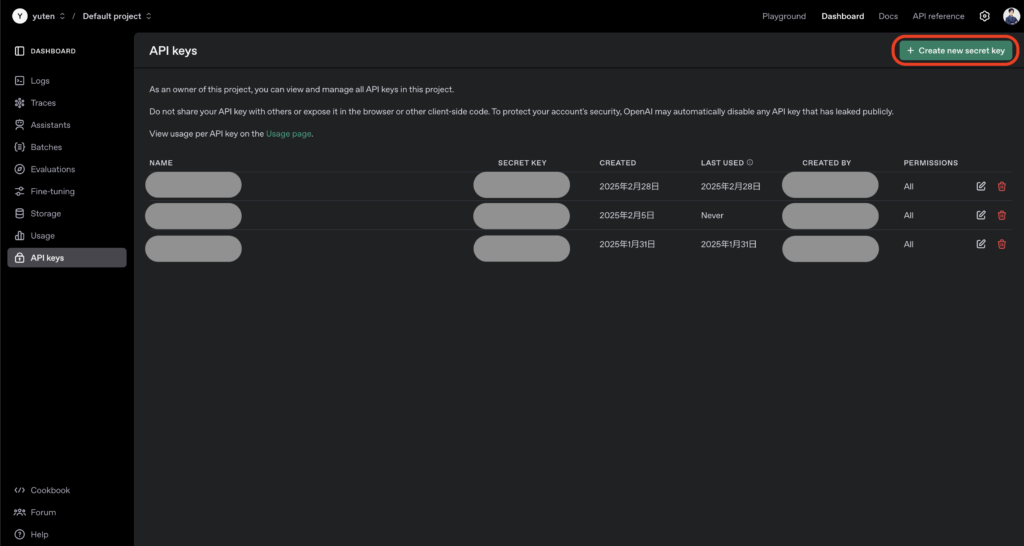
まず、以下の手順でOpenAI APIキーを取得しましょう。
- OpenAIのウェブサイト(https://openai.com/)にアクセス
- アカウントを作成またはログイン
- ダッシュボードから「API keys」セクションに移動
- 「Create new secret key」をクリックしてAPIキーを生成
- 生成されたAPIキーを安全な場所に保存(表示は一度きりなので注意してください)
- APIの使用には課金が発生するため、OpenAIのウェブサイトで支払い情報を設定
開発環境の準備
続いて開発環境の準備をしていきます。
お使いの開発環境にて以下のコードを実行してください。
# OpenAIのライブラリをインストール
pip install openaiJupyter環境で実装される方は以下画像のとおり、先頭に「!」を付けて実行しましょう。(以降のサンプルコードでも同様です。)
環境変数の設定
セキュリティ対策として、APIキーを環境変数として設定しておきましょう。
export OPENAI_API_KEY="your-api-key-here"基本的な文字起こし実装
サンプルコードは以下の通りです。
from openai import OpenAI
import os
# APIキーを設定
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# 音声ファイルのパス
audio_file_path = "path/to/your/audio/file.mp3"
# 音声ファイルを開く
audio_file = open(audio_file_path, "rb")
# GPT-4o Transcribeを使用して文字起こし
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file
)
# 結果を表示
print(transcription.text)※GPT-4o Mini Transcribeを使用する場合は、model=”gpt-4o-mini-transcribe”と指定するだけでOKです。
高度な設定オプション
以下のようなパラメータを追加することで、文字起こしをカスタマイズすることもできます。お好みで試してみてください。
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file,
language="ja", # 言語を指定(日本語の場合)
prompt="会議の議事録", # コンテキストのヒント
temperature=0.3, # 低い値で正確性を高める
timestamp_granularities=["segment"] # タイムスタンプを追加
)ストリーミング(リアルタイム)処理
以下のコードを参考にしてみてください。
import pyaudio
import wave
import threading
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# 音声録音の設定
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
RECORD_SECONDS = 5
# 音声を録音して一時ファイルに保存
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
print("録音開始...")
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("録音終了")
stream.stop_stream()
stream.close()
p.terminate()
# 一時ファイルに保存
temp_file = "temp_audio.wav"
wf = wave.open(temp_file, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
# 文字起こし処理
with open(temp_file, "rb") as audio_file:
transcription = client.audio.transcriptions.create(
model="gpt-4o-transcribe",
file=audio_file
)
print(transcription.text)以上!
上記フローで次世代音声認識モデルを活用できるようになりますので、用途や予算に応じて、GPT-4o TranscribeとGPT-4o Mini Transcribeを使い分けて試してみてください。
活用事例
高度な音声認識モデルGPT-4o TranscribeおよびGPT-4o Mini Transcribeは、さまざまな分野での活用が期待されています。ここでは代表的なユースケースを3つご紹介します。
会議・インタビューの自動文字起こし
活用事例の1つとして、社内会議やインタビュー取材を、GPT-4o Transcribeによって自動で録音→テキスト化するというケースが考えられます。
これまで、会議の議事録起こしは人手で録音を聞き返しながら行うか、Whisperなどのモデルを使っても誤認識部分の修正が手間でしたが、GPT-4o Transcribeなら長時間の会議音声でも高精度に転写できるため、議事録作成の大幅な省力化が見込めます。
例えば、1時間の会議音声をアップロードすれば、発言内容がほぼそのままテキストになって出力されるため、担当者は体裁を整えたり足りない箇所を確認するだけで議事メモが完成します。
また、将来的には、リアルタイムで会議進行中に字幕を出したり、音声アシスタントが議論内容を理解して議事録をまとめてくれる、といった高度な活用も視野に入ってきそうですね。
映像コンテンツの字幕生成
次に、YouTube動画やオンライン講座、ウェビナーなどの映像コンテンツに対して、自動で字幕ファイルを生成するケースも考えられます。ナレーションや会話音声をGPT-4o Transcribeに通すことで、高精度なテキスト字幕を起こすことができます。
例えば、動画制作者が撮影・編集したコンテンツに後から字幕を付けたい場合、音声トラックを抽出してモデルにかければ、短時間で字幕用のテキストデータを得ることができます。
認識精度が高いので、話し言葉特有の言い淀みや繰り返しも適切に扱われ、読みやすい字幕になることが想定できます。
ライブキャプション(リアルタイム翻訳)
最後に、国際会議やオンラインセミナーの場で、話者の発言をリアルタイムに文字起こしし、同時に他言語へ翻訳して字幕表示するライブキャプションへの応用も考えられますね。
GPT-4o Mini Transcribeの高速リアルタイム転写機能を使えば、例えば、日本語の講演内容をほぼ遅延なくテキスト化できます。さらに、そのテキストを別途翻訳モデル(GPT-4など)に流すことで英語や他言語に即座に翻訳し、スクリーンに字幕表示するといった仕組みが構築可能です。
従来の同時通訳では人間の通訳者が必要でしたが、GPT-4oを中心としたAIシステムで自動通訳が実現できれば、人手不足の解消やコスト削減につなげることができます。
GPT-4o TranscribeをGoogleColab上で使ってみた
今回は、GoogleColab A100 GPU環境で「GPT-4o Transcribe」の文字起こし機能を使ってみます。
サンプル音声はオープンソースのサイト参照。(※1)今回は、屋久島に関する30秒ほどのサンプル音声を使います。
初期設定コードはこちら
import os
# APIキーを設定(このセルを実行後、セキュリティのためにキーを削除することをお勧めします)
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# または.envファイルから読み込む場合
# from dotenv import load_dotenv
# load_dotenv()
# 基本的な文字起こし機能実装
from openai import OpenAI
# クライアントの初期化
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def transcribe_audio(file_path, model="gpt-4o-transcribe"):
"""音声ファイルを文字起こしする関数
Args:
file_path (str): 音声ファイルのパス
model (str): 使用するモデル("gpt-4o-transcribe" または "gpt-4o-mini-transcribe")
Returns:
str: 文字起こし結果
"""
with open(file_path, "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model=model,
file=audio_file
)
return transcript.text
文字起こし実行コードはこちら
# 文字起こしの実行
# GPT-4o Transcribeの文字起こし
gpt4o_result = transcribe_audio(audio_file_path, "gpt-4o-transcribe")
# GPT-4o Mini Transcribeの文字起こし
gpt4o_mini_result = transcribe_audio(audio_file_path, "gpt-4o-mini-transcribe")
# 結果の表示
print("【GPT-4o Transcribe結果】")
print(gpt4o_result)
print("\n" + "=" * 50 + "\n")
print("【GPT-4o Mini Transcribe結果】")
print(gpt4o_mini_result)実行結果はこちら
30秒ほどのサンプル音声をものの2秒で文字起こししてくれました。
ただ、屋久島のテキストだけ誤字っているのが惜しい・・
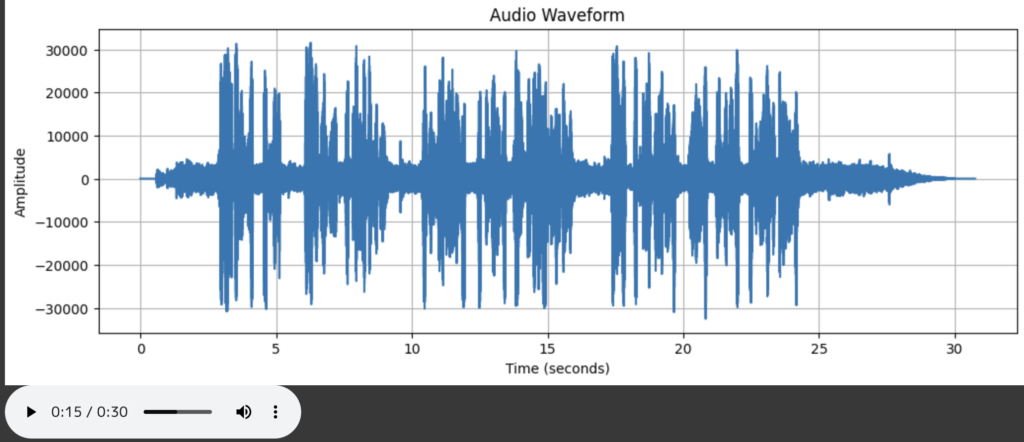
【オプション】音声ファイルの可視化(波形プロット)コードはこちら
# 音声ファイルの可視化
!pip install pydub
from IPython.display import Audio
import matplotlib.pyplot as plt
import numpy as np
from pydub import AudioSegment
import io
def visualize_audio(file_path):
"""音声ファイルを視覚化し、再生可能にする
Args:
file_path (str): 音声ファイルのパス
"""
# 音声ファイルの読み込み
audio = AudioSegment.from_file(file_path)
# 波形データの取得
samples = np.array(audio.get_array_of_samples())
# ステレオの場合はモノラルに変換
if audio.channels == 2:
samples = samples.reshape((-1, 2))
samples = samples.mean(axis=1)
# 波形のプロット
plt.figure(figsize=(12, 4))
plt.plot(np.linspace(0, len(samples) / audio.frame_rate, len(samples)), samples)
plt.title("Audio Waveform")
plt.xlabel("Time (seconds)")
plt.ylabel("Amplitude")
plt.grid(True)
plt.show()
# 再生可能なオーディオウィジェットを表示
return Audio(file_path)
# 音声ファイルの可視化と再生
audio_widget = visualize_audio(audio_file_path)
audio_widget【オプション】実行結果はこちら
以上、GPT-4o Transcribeを使った文字起こし試行例のご紹介でした!
いろいろなパターンの音声ファイルで試してみるとより精度の高さを実感いただけると思います。
ぜひ、お手元で試してみてください。
まとめ
最後に、GPT-4o TranscribeとGPT-4o Mini Transcribeの特徴をおさらいしておきましょう。
- 従来のWhisperモデルに比べ、誤認識を大幅に削減
- 100以上の言語に対応
- 高速版(廉価版)モデルを用意
- 基本的な商用・私的利用はOK
- 利用にはOpenAI APIキーが必要
上述しましたが、早口で高速な音声ファイルや難易度の高い専門用語を並べた音声ファイルを読み込ませて試行してみると、GPT-4o TranscribeとGPT-4o Mini Transcribeの精度の高さをお分かりいただけると思います。
ぜひ試してみてください!
最後に
いかがだったでしょうか?
音声認識モデルを活用し、会議録作成、字幕生成、多言語対応のリアルタイム通訳の可能性を広げませんか?最先端の生成AI導入に向けた具体的な活用方法や、最適な実装手法について専門家が詳しくご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

