
【OpenEQA】MetaがAGI開発のキーとなるデータセットを大公開

WEELメディア事業部LLMライターのゆうやです。
2024年4月11日、米Meta社からテキストベースの質問を通じて、AIエージェントの物理空間の理解を測定する新しいベンチマーク「OpenEQA」が公開されました。
このベンチマークは、AIエージェントが周囲の環境をテキストによる質問で調査することによって、その環境についての理解を測定するためのベンチマークです。
つまり、家庭用ロボットやスマートグラスの頭脳として機能するようなAIエージェントとしてのモデルの能力を測るためのものです。
実際に、GPT-4VなどのVLMがこのベンチマークで評価されましたが、そのスコアは人間が獲得したスコアより大幅に低く、その差は依然として歴然であることが分かりました。
今回は、OpenEQAの概要を紹介します。
是非最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
OpenEQAの概要
OpenEQAは、米Meta社が公開したオープンボキャブラリーの質問を通じて、AIエージェントの物理空間の理解を測定する新しいベンチマークです。
このOpenEQAは、「ワールドモデル」(言語を通じて問い合わせ可能な、外界のエージェント内部表現)の構築する研究活動の成果として発表されました。
このベンチマークは、エンボディッド質問応答(Embodied Question Answering, EQA)に特化したベンチマークで、ファウンデーションモデルの能力を評価します。
実際ベンチマークを受けるエージェントは、環境内で自由に移動して視覚的手がかりや対話的要素を用いて、自然言語で入力された質問に答えます。
実際に評価をしている様子です。
OpenEQAには、キッチンやオフィスなどの現実世界から抽出された抽出された180を超える環境と、人が生成した1600を超える高品質な質問が含まれています。
また、人間の判断と優れた相関関係を持つ、LLM を利用した自動評価プロトコルも提供されています。
これにより、AIがこれらの環境に存在する物体をどの程度正しく認識しているのか、空間的および機能的推論はどの程度可能か、常識などの知識をどの程度持ち合わせているかなどを、極めて詳細に検証できます。
ここからは、OpenEQAに搭載されているタスクについて解説します。
なお、Metaが開発した動画内の物理世界を機械に理解させるフレームワークについて知りたい方はこちらの記事をご覧ください。
→【V-JEPA】Meta開発、動画内の物理世界を機械に理解させるフレームワークを徹底解説
OpenEQAの使い方
OpenEQAは、公式GitHubのReadmeのBaselines and Automatic Evaluationセクションや、OpenEQA QuickStartノートブックで実装方法が公開されています。
これらを参考にすれば、OpenEQAデータセットを使用して自前のモデルや既存モデルの学習および評価をすることができます。
学習の際には、かなりのリソースが必要になります(具体的な要件についての記載はなし)が、環境がある方は是非試してみてください。
OpenEQAのライセンス
OpenEQAはMITライセンスのもとで提供されており、無料で商用利用することも可能です。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 記載なし |
| 私的使用 | ⭕️ |
OpenEQAに搭載されているタスク
OpenEQAには「エピソード記憶」と「アクティブ探査」の2種類のタスクが搭載されています。
これらのタスクについて、具体例とともに解説していきます。
エピソード記憶
エピソード記憶は、身体化したAIが動画などの過去の記憶をもとに、質問に答えるタスクです。
このタスクでは以下の画像のように、テキストでの質問に対して、AIが過去の記憶(この場合は動画)を遡って質問の答えを導き出せるか検証します。

この例では、「ブラインドは何色?」という質問に対して動画を遡り、正確に白色と答えていますね。
アクティブ探査
アクティブ探査タスクでは、エピソード記憶のように過去の記憶(動画)からではなく、実際に環境内をAI(ロボットに搭載されたAIエージェントなど)が動き回ってリアルタイムで答えを導き出すタスクです。
以下の例では、「家にフルーツはありますか?」という質問に対して、AIを搭載した四足歩行ロボットが家中を歩き回ってフルーツを探します。

そして最終的にダイニングテーブルの上にバナナがあるのを発見し、回答しています。

このようなタスクでAIを評価することで、環境を深く理解していることを示すベンチマークとして機能しています。
ここからは、OpenEQAの質問例とデータセットの統計についてみていきましょう。

OpenEQAの質問例とデータセットの統計
以下の画像は、EQAの質問例と人間が生成した質問とそれに対するAIの回答、データセットの統計をまとめたものです。
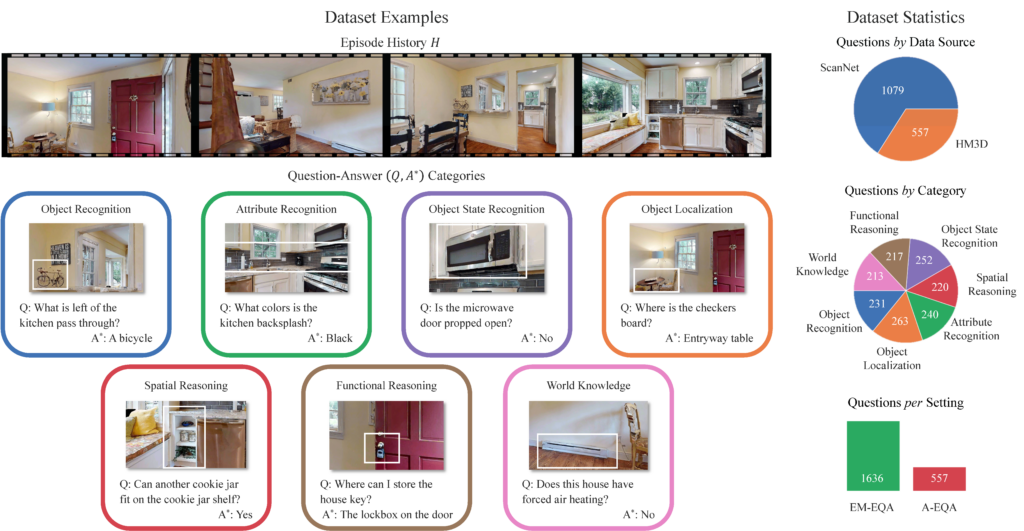
これを見ると、AIに対する人間の質問は、7つのカテゴリ(機能的推論、物体の状態認識、空間推論、属性の認識、物体の位置特定、物体認識、知識)に分けられていることが分かります。
AIは、これらの質問に対してA*の答えと一致するものを出力することを目指します。
右側のデータセットの統計を見ると、7つのカテゴリの質問がほぼ均等に含まれており、質問数もエピソード記憶が1,636個、アクティブ探査が557個と豊富に含まれています。
続いて、OpenEQAの自動化された評価ワークフローについて紹介します。
自動化された評価ワークフロー
OpenEQAのオープンボキャブラリーという性質は、EQAを現実的なものにする一方で、正解が複数存在するため、評価には困難が伴います。
その評価の1つのアプローチは人間による評価ですが、特にベンチマークの場合、法外な時間とコストがかかります。
そこで、別の手法としてLLMを用いて、EQAエージェントが生成したオープンボキャブラリーの回答の正しさを評価します。
LLMによる評価のワークフローです。
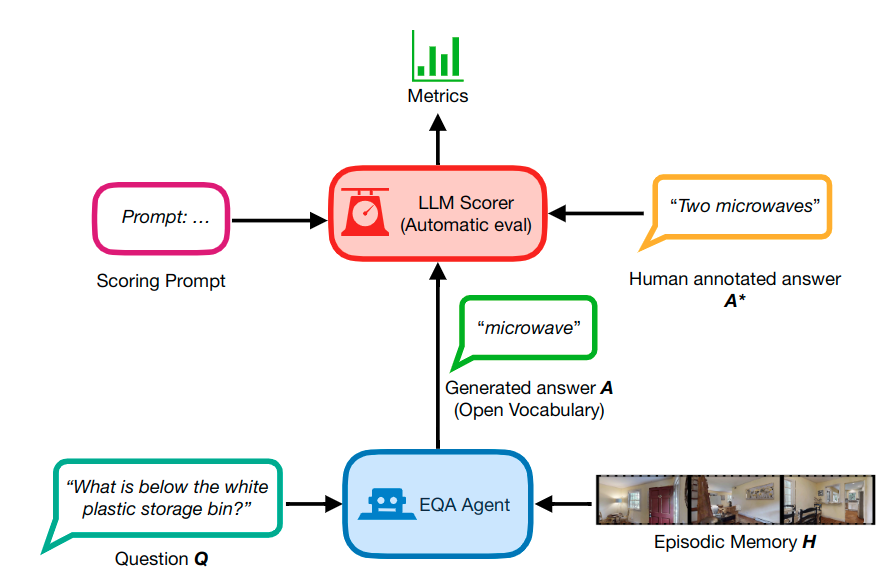
LLMによる評価では、スコアリングのためのプロンプトと人間がアノテーションした解答をLLMに入力し、評価を行います。
これにより、人間の手であれば膨大なコストがかかる評価作業がはるかに効率化されます。
最後に、OpenEQAでいくつかの最先端モデルを評価した結果を紹介します。

最先端モデルのパフォーマンス評価
ここからは、OpenEQAのエピソード記憶タスクで、LLaMA-2 や GPT-4 などのテキストのみLLMと、Claude 3、Gemini Pro、GPT-4V などのマルチモーダルLLMを評価した結果を紹介します。

この結果を見ると、マルチモーダルLLMはテキストのみのLLMと比べて一貫して高いパフォーマンスを発揮しているようです。
ただ、人間のパフォーマンスと比較すると、最先端のマルチモーダルLLMでもその差は歴然で、まだまだ空間を理解して回答する能力は人間には遠く及ばないことが分かります。
各カテゴリの質問ごとのパフォーマンスも示されていたので、そちらも紹介します。
カテゴリ別のパフォーマンス
以下のグラフは、先ほど紹介した7つのカテゴリごとのモデルのパフォーマンス評価を示したものです。

ここでは、GPT-4、GPT-4とLLaVA-1.5のSocraticモデル、構造化メモリとGPT-4、GPT-4V、人間が評価されています。
この結果から、視覚情報にアクセスできるモデルは、物体や属性の位置を特定して認識することに優れており、知識を必要とする質問に答えるためにこの情報をより有効に活用していることがわかりました。
ただし、それ以外のカテゴリの質問(特に空間理解を必要とする質問)に対しては、GPT-4Vのような最高レベルのVLMでもほぼ「ブラインド状態」であり、テキストのみのモデルとほぼ変わらないスコアです。
これは、視覚情報を利用するモデルが視覚情報から実質的な恩恵を受けておらず、パフォーマンスが最大限発揮できていないことを示しています。
例えば、「私はリビングルームのソファに座ってテレビを見ています。私の真後ろにある部屋はどれですか?」という質問に対して、モデルは空間の理解をもたらすはずの視覚的なエピソード記憶の恩恵をあまり受けずに、基本的にランダムにさまざまな部屋を推測してしまいます。
この結果は、AIモデルに知覚と推論の両方の面でさらなる改善が必要であることを示唆しています。
なお、Meta開発のテキストから音楽や音声を生成できるAIについて知りたい方はこちらの記事をご覧ください。
→【MAGNeT】Meta開発のテキストから音楽や音声を生成できるAIの使い方~実践まで
OpenEQAはAIエージェントの物理空間の理解を評価するベンチマーク
OpenEQAは、オープンボキャブラリーの質問を通じて、AIエージェントの物理空間の理解を測定する新しいベンチマークです。
このベンチマークには、キッチンやオフィスなどの現実世界から抽出された抽出された180を超える環境と、人が生成した1600を超える高品質な質問が含まれています。
また、「エピソード記憶」と「アクティブ探査」の2種類のタスクが搭載されています。
質問は7つのカテゴリ(機能的推論、物体の状態認識、空間推論、属性の認識、物体の位置特定、物体認識、知識)に分けられており、AIの環境理解をより詳細に評価できます。
このベンチマークを用いて、GPT-4やGPT-4V、Claude 3などの最先端のモデルを評価したところ、最良スコアのGPT-4Vでも人間のスコアには全く及ばないという結果になりました。
また、空間理解を必要とする質問については、GPT-4VなどのVLMはほぼ「ブラインド(目隠し)」状態であり、そのスコアはテキストのみのLLMとほぼ変わりませんでした。
これは、AIの知覚と推論の両方の面でさらなる改善が必要であることを示唆しており、MetaはこのベンチマークがAI が物理空間を理解し、コミュニケーションできるようにするためのさらなる研究の動機となることを願っています。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


