
【Qwen2-Vl】Alibaba Cloudの視覚言語モデルを使って超有名漫画の1コマ解析してみた!

Qwen2-VLは、アリババクラウドが発表した最新の視覚言語モデルであり、優れた視覚理解能力を持っています。
このモデルは、動画や画像の内容を深く理解し、質疑応答や推論を行うことができるため、様々なアプリケーションにおいて活用できる可能性があります。
特に、複雑なオブジェクトの関係性や多言語のテキストを認識する能力に優れており、教育やビジネス、エンターテインメントなどの分野で多くの場面でその力を発揮します。
今回は、Google Colaboratoryで実際に動かしてみて、あの超有名漫画の一コマを解析してみました!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen2-Vlの概要
Qwen2-Vlはアリババ社の子会社、アリババクラウドが発表した新しいモデルです。
Qwen2-Vlの最も注目すべき点は、優れた視覚理解能力です。アリババの発表によるとQwen2-Vlは20分以上の長時間の動画内容を理解し、高品質な動画内容の質疑応答が可能。また、情報が多い推論や複雑な意思決定をサポートできるため、幅広く様々なアプリケーションに統合できる可能性があります。
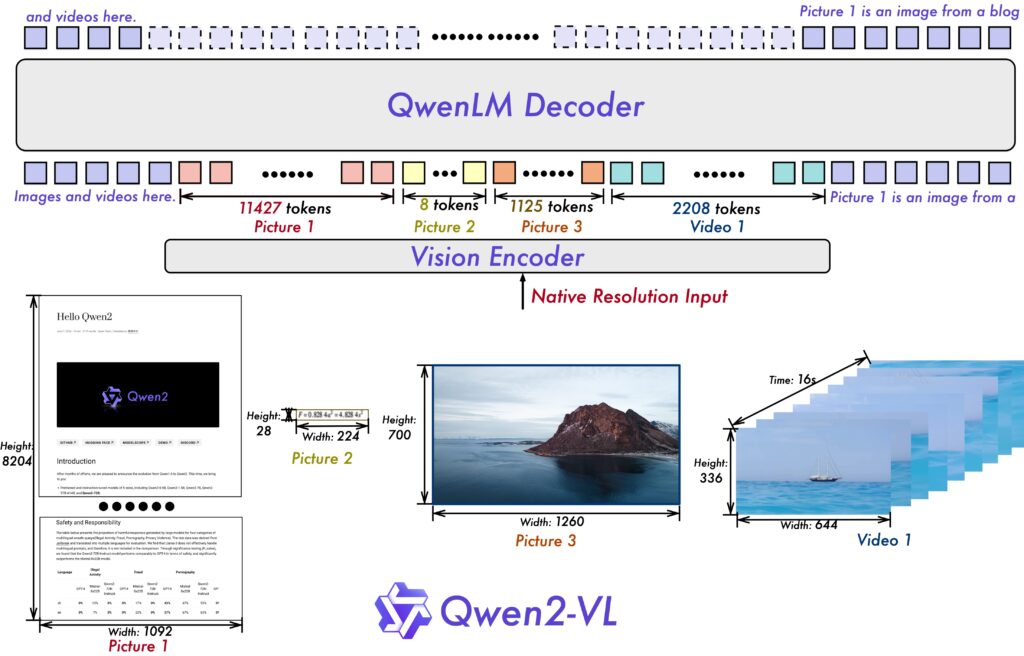
Qwen2-Vlの視覚理解能力
Qwen2-Vlは動画だけではなく、画像やライブチャット、天気予報や荷物の追跡などのビジュアルエージェント機能も有しています。
画像理解では、画像内の複数のオブジェクト間の複雑な関係性を認識することができ、さらに画像内の手書きテキストや多言語の認識能力も大幅に向上。

また、画像や図表から情報を抽出し、指示に従う能力も強化されており、これにより複雑な数学の問題を図表分析によって解釈し、解決することも可能です。
ライブチャットでは、ユーザーの質問に対してリアルタイムで回答ができます。これにより、動画コンテンツから直接情報を提供することで、ユーザーを支援するパーソナルアシスタントとして機能させることも可能。
ベンチマークからもわかるように、「ドキュメントと図の読み取り」や「視覚理解」のタスクで優れたパフォーマンスを示しています。
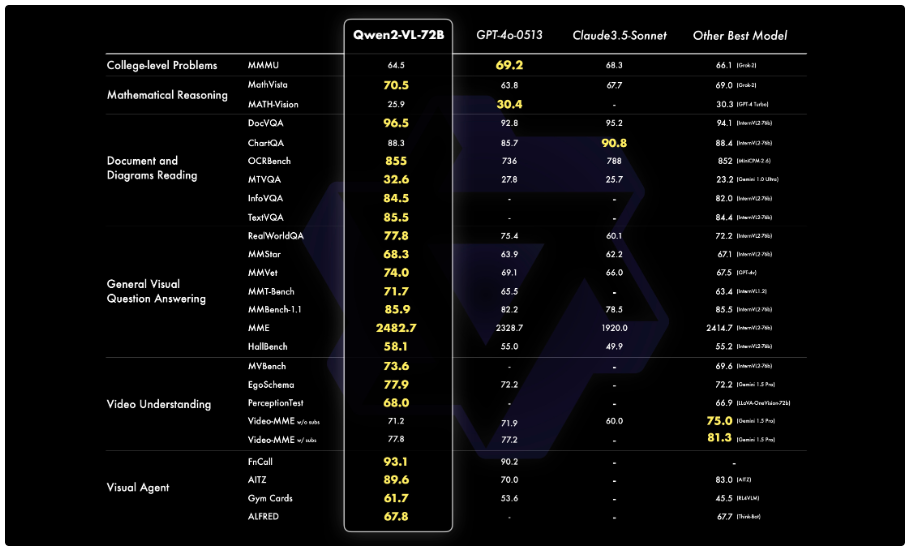
Qwen2-Vlとその他の視覚理解モデルの違い
Qwen2-VLは、他の視覚理解モデルと比較して、次のような違いがあります。
- 幅広い視覚的理解能力
- 高精度な視覚的理解
- 効率的なモデルサイズ
- オープンソース
幅広い視覚的理解能力
Qwen2-VLは、画像の理解や動画の理解、ライブチャット、ビジュアルエージェント機能など、幅広い視覚的理解能力を備えています。様々な内容を理解できるようになったことで、従来の視覚理解モデルでは難しかった、より複雑で現実的なタスクに対応可能。
例えば、動画の内容を理解して要約したり、動画内のオブジェクトに関する質問に答えたり、リアルタイムで視覚情報を用いた対話を行ったりできます。
高精度な視覚的理解
視覚理解ベンチマークにおいて優れた性能を達成しています。 特に、ドキュメント理解タスクや画像からの多言語テキスト理解において優れた性能を発揮。 これは、Qwen2-VLが、画像内のテキスト情報と視覚情報を効果的に統合できることを示唆しています。
効率的なモデルサイズ
Qwen2-VLは、7Bスケールと2Bスケールのモデルを提供しており、7Bスケールでは、画像やマルチ画像、動画入力のサポートを維持しながら、コスト効率の高いモデルサイズを実現。
また、2Bスケールのモデルは、モバイル展開を想定して最適化されており、そのコンパクトなサイズにもかかわらず、画像だけではなく動画や多言語理解において優れた性能を発揮します。
オープンソース
Qwen2-VLの2Bおよび7Bモデルは、オープンソースとして公開されており、Hugging FaceやModelScopeなどのプラットフォームで利用可能。 これにより、開発者はQwen2-VLのコードを自由に利用して、独自の視覚言語モデルの開発や、新しいアプリケーションの開発を行うことができます。
Qwen2-Vlの対応言語
Qwen2-Vlは英語と中国語に加えて、ほとんどのヨーロッパの言語、日本語、韓国語、アラビア語、ベトナム語など、さまざまな言語を理解可能。多言語理解により、Qwen2-Vlは世界中のユーザーにサービスを提供できます。
Qwen2-Vlの活用場面
Qwen2-Vlの特徴は高度な視覚理解能力と多言語理解です。この特徴を活用することで、教育場面やビジネス、エンターテインメントなど様々な場面で利用できます。
例えば、教育場面では、複雑な数学の問題を図表分析によって解釈し、解くことができるので家庭教師的な役割として活用できるでしょう。
ビジネス場面では、ドキュメント理解タスクに優れているため、契約書や報告書などのビジネス文書の分析に役立ちます。また、画像内のテキストを理解できるため、プレゼンテーション資料の内容を理解したり、議事録を作成したりすることも可能。
また、エンターテインメントの活用方法として、動画の内容を要約したり、動画に関する質問に答えたり、リアルタイムで会話をしたりできます。これらの機能を活用することで、映画やドラマの解説、スポーツ中継のリアルタイム分析、ゲームの攻略情報の提供など、エンターテイメント分野においてもQwen2-Vlが活躍するでしょう。
Qwen2-Vlのライセンス
Qwen2-Vlのライセンスはアパッチライセンス2.0であるため、基本的には商用利用や改変、私的使用などが可能なオープンソースライセンスです。
使用条件としては、著作権表示とライセンスのコピーを維持すること、改変があればその通知を行う必要があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、スマホで動くMicrosoftの最新LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen2-Vlの使い方
ここからはQwen2-Vlをgoogle colaboratoryで実際に動かしていきたいと思います。
Qwen2-Vlのモデルはいくつか用意されています。
- Qwen2-VL-2B-Instruct
- Qwen2-VL-7B-Instruct
- Qwen2-VL-2B-Instruct-AWQ
- Qwen2-VL-7B-Instruct-AWQ
- Qwen2-VL-2B-Instruct-GPTQ-Int4
- Qwen2-VL-7B-Instruct-GPTQ-Int4
- Qwen2-VL-2B-Instruct-GPTQ-Int8
- Qwen2-VL-7B-Instruct-GPTQ-Int8
今回は最もモデルサイズの小さいQwen2-VL-2B-Instructで実装をします。
Hugging Faceにサンプルコードが掲載されていますが、GitHubの方が少しだけ詳しく書かれているので、参考にする場合にはGitHubの方がいいかもしれません。
基本的には本記事内で実装完了までできるようにお伝えしていくので、本記事をそのまま読み進めていってもらえればOKです
Qwen2-Vlを動かすのに必要な動作環境
Qwen2-Vlモデルを実行した時の環境は以下です。google colaboratoryで実装する場合にはランタイムをGPUに変更する必要があります。画像を読み込み、解析する場合には無料バージョンでも十分実装可能です。
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
37.0GB
■システムRAMの使用量
3.6GB
■GPU RAMの使用量
5.5GB
Qwen2-Vlのgoogle colaboratoryでの実装方法
まずはGitHubのリポジトリからライブラリをインストールしていきましょう。
ライブラリのインストールはこちら
!pip install git+https://github.com/huggingface/transformers accelerate
#基本的にはこれだけでOKですが、これで実装してエラーが出た場合には、下記も実行
!pip install qwen-vl-utils準備はこれだけです。あとはサンプルコードを実行していきます。サンプルコードでは画像を説明するコードになっており、用意されている画像はこちら。

Qwen2-Vlのサンプルコードはこちら
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-2B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)Qwen2-Vlのサンプルコードの結果はこちら
The image depicts a serene beach scene with a woman and her dog. The woman is sitting on the sand, wearing a plaid shirt and black pants, and appears to be smiling. She is holding up her hand in a high-five gesture towards the dog, which is also sitting on the sand. The dog has a harness on, and its front paws are raised in a playful manner. The background shows the ocean with gentle waves, and the sky is clear with a soft glow from the setting or rising sun, casting a warm light over the entire scene. The overall atmosphere is peaceful and joyful, capturing a moment of connection between the
和訳:女性と犬がいる穏やかな浜辺の風景が描かれている。女性は砂浜に座り、チェックのシャツと黒いズボンを身につけ、微笑んでいるように見える。同じく砂浜に座っている犬に向かって、彼女は手を上げてハイタッチのジェスチャーをしている。犬はハーネスをつけ、前足を上げて遊んでいる。背景には穏やかな波の海が広がり、空は澄み渡り、夕日や朝日が柔らかな光を放ち、シーン全体に暖かい光を投げかけている。全体的な雰囲気は穏やかで楽しげであり、犬同士のつながりの瞬間をとらえている。かなり忠実に画像について説明をしてくれており、Qwen2-Vlの性能の高さがわかります。また、細部までも解説をしており、従来の視覚理解モデルに比べても性能が上がっていますね。
Qwen2-Vlで漫画のワンシーンを読み込ませて理解できるかを検証
次にQwen2-Vlで漫画のワンシーンを読み込ませて、理解できるかを検証します。Qwen2-Vlの特徴はやはり高性能な資格理解であるため、より詳細に解説してくれることを期待しつつ実装していきましょう。
まずは漫画の一コマを画像として読み込ませ、解析をしてもらいます。漫画に関する情報は特に与えてはいません。
使用した画像はこちら

デモコードはこちら
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-2B-Instruct", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "/content/normal.jpg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
結果はこちら
This image is a manga panel from the "One Piece" series, featuring a dynamic and intense scene. The central figure is Luffy, a character known for his strength and combat skills. He is surrounded by a cloud of smoke and fire, indicating a powerful attack or battle.\n\nLuffy is wearing a black outfit with a red and white pattern, and he appears to be in a fighting stance, ready to engage with an opponent. His expression shows determination and focus.\n\nIn the background, there are other characters, including one who seems to be a member of the Straw Hat Pirates, given their distinctive attire. This character is shouting and appears
和訳:この画像は『ONE PIECE』シリーズの漫画コマで、ダイナミックで激しいシーンが描かれている。中央の人物はルフィで、その強さと戦闘能力で知られるキャラクターである。黒地に赤と白の模様が入った服を着ており、戦闘態勢に入っているように見える。背景には麦わらの一味と思われるキャラクターがいる。このキャラクターは叫んでいる。漫画の情報については特に何も提供していませんし、解析してもらった画像内にもワンピースという単語が入っていないにも関わらず、提供した画像がワンピースのワンシーンであり、さらに「麦わらの一味」という単語まで出てきています。
Qwen2-Vlはテキストや画像を処理するために様々な内容を学習しているため、その影響が大きいと言えるでしょう。
Qwen2-Vlでは動画の解析もできるのですが、google colaboratoryのGPU A100でもGPUメモリ不足になってしまい、今回は検証できませんでした。
動画の解析を行う場合には、動画関連のライブラリをインストールしつつ、若干コードを変更します。
動画解析時の必要ライブラリインストールはこちら
!pip install av
!pip install ffmpeg画像以外の解析のサンプルコードはこちら
messages = [
# Image
## Local file path
[{"role": "user", "content": [{"type": "image", "image": "file:///path/to/your/image.jpg"}, {"type": "text", "text": "Describe this image."}]}],
## Image URL
[{"role": "user", "content": [{"type": "image", "image": "http://path/to/your/image.jpg"}, {"type": "text", "text": "Describe this image."}]}],
## Base64 encoded image
[{"role": "user", "content": [{"type": "image", "image": "data:image;base64,/9j/..."}, {"type": "text", "text": "Describe this image."}]}],
## PIL.Image.Image
[{"role": "user", "content": [{"type": "image", "image": pil_image}, {"type": "text", "text": "Describe this image."}]}],
## Model dynamically adjusts image size, specify dimensions if required.
[{"role": "user", "content": [{"type": "image", "image": "file:///path/to/your/image.jpg", "resized_height": 280, "resized_width": 420}, {"type": "text", "text": "Describe this image."}]}],
# Video
## Local video path
[{"role": "user", "content": [{"type": "video", "video": "file:///path/to/video1.mp4"}, {"type": "text", "text": "Describe this video."}]}],
## Local video frames
[{"role": "user", "content": [{"type": "video", "video": ["file:///path/to/extracted_frame1.jpg", "file:///path/to/extracted_frame2.jpg", "file:///path/to/extracted_frame3.jpg"],}, {"type": "text", "text": "Describe this video."},],}],
## Model dynamically adjusts video nframes, video height and width. specify args if required.
[{"role": "user", "content": [{"type": "video", "video": "file:///path/to/video1.mp4", "fps": 2.0, "resized_height": 280, "resized_width": 280}, {"type": "text", "text": "Describe this video."}]}],
]Qwen2-VlのGradioが用意されていたので、そちらを使って動画を解析してもらいました。元動画は15秒程度に短くしているのですが、解析には5-6分くらいかかりました。
解析してもらった動画はワンピースの新刊告知の動画で、結果は以下です。
この動画は、アニメーションの予告編です。最初に、黄色と黒の渦巻き模様が表示され、次に、黄色と黒の渦巻き模様が表示されます。その後、アニメーションのキャラクターが登場し、様々なシーンが表示されます。最後に、アニメーションのタイトルが表示されます。
情報が足りなかったのか、静止画の時のように漫画のタイトルまでは解析できませんでした。
動画自体は20分以上のものでも解析できるようですが、解析時間は解析環境に左右されてしまうため、GPUを積んでいないパソコンでは動画解析はなかなか難しいかもしれません。
なお、未来予測ができるGPT-4V超えの生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

