
【Qwen-Audio】音声だけで状況認識や多言語翻訳ができるアリババ産LLMを使ってみた
WEELメディア事業部テックリサーチャーの藤崎です。
いまやChatGPTを始めとする生成AIは、テキストだけでなく画像やオーディオを認識したり生成することができるようになりました。
そんな中、2023年11月30日に中国の大手通販サイトを運営するアリババ社から大規模音声モデル「Qwen-Audio」が発表されました。
Qwen-Audioは音源を分析してシーンを判別したり、様々な言語の翻訳ができたりとオーディオ特化のLLMとなっています。
この記事ではQwen-Audioの概要から実際に使ってみた感想などをお伝えします。
音源を使って生成AIを使えないか・・・と思っている方は必読です!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Qwen-Audioの概要
2023年11月30日、中国の大手通販サイトを運営するアリババ社から大規模音声モデル「Qwen-Audio」を公開しました。
Qwen-Audio(Qwen Large Audio Language Model)は、アリババ社の大規模モデルシリーズ、Qwenのマルチモーダルバージョンです。
Qwen-Audioは、人間の話し声、自然音、音楽、歌など様々なオーディオとテキストを入力として受け入れ、テキストを出力することが可能です。

Qwen-Audioの特徴は次の4つです。
- 基本的なオーディオモデル:Qwen-Audioは、基本的なマルチタスク音声言語モデルであり、普遍的なオーディオ理解モデルとして機能します。さらに、Qwen-Audioを元にQwen-Audio-Chatを開発し、対話や様々なオーディオ中心のシナリオをサポートします。
- マルチタスク学習フレームワーク:音声言語の事前トレーニングを拡大するため、異なるデータセットに関連するテキストラベルの変動に対処するマルチタスクトレーニングフレームワークを提案し、知識共有を可能にすることで一対多の干渉を回避します。
- 強力なパフォーマンス:実験結果から、Qwen-Audioはタスク固有のファインチューニングを必要とせずに、様々なベンチマークタスクで印象的なパフォーマンスを達成し、競合他社を上回ります。
- 柔軟なマルチランチャット:Qwen-Audioは、複数のオーディオ分析、音声理解と推論、音楽鑑賞、ツール使用をサポートします。
よくあるマルチモーダルは音声を認識してテキスト化するというものですが、Qwen-Audioはそれだけでなく音声を理解してそのシーンを推論し、提案を行ったり、翻訳したりと音声に特化した生成AIなのです。
色々試してみたのですが、ついにここまできたのか・・・!と感じるほど完成度が高いものになっていました。
早速、Qwen-Audioを使っていきましょう!

Qwen-Audioの使い方
今回、Qwen-Audioを動かすことができた環境はGoogleColab ProのA100でした。結構パワー使いますねぇ。
Pythonやその他、必要なパッケージは下記の通りです。
■Pythonのバージョン
Python 3.8以上
■必要なパッケージ
・Pytorch 1.12以上(推奨 : 2.0以上)
・CUDA 11.4以上が推奨(GPU使用の場合)
・FFmpeg
では、公式のGitの通り進めていきましょう!
まず、Gitから任意のディレクトリにファイルをダウンロードします。
!git clone https://github.com/QwenLM/Qwen-AudioQwen-Audioのディレクトリに移動します。
%cd Qwen-Audio「requirements.txt」を使って必要なパッケージをインストールしていきます。
!pip install -r requirements.txt環境構築は以上です。
次に、トークナイザーやモデルの設定を行います。
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-Audio-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Audio-Chat", device_map="cuda", trust_remote_code=True).eval()最後にqueryで音源ファイルのパスとプロンプトを入力すると、print文で結果が生成されます!
query = tokenizer.from_list_format([
{'audio': 'オーディオファイルのパス'},
{'text': 'プロンプトを入力'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)それでは早速使ってみましょう!
なお、OpenAIのWhisperを高性能にした音声生成AIツールについて知りたい方はこちらの記事をご覧ください。
→【WhisperSpeech】Whisperがさらに高性能になった音声モデルを使ってエミネムにゆっくり喋らせてみた
Qwen-Audioを実際に使ってみた
まずはQwen-Audioの公式サイトに掲載されているコードを試してみます。
query = tokenizer.from_list_format([
{'audio': 'assets/audio/1272-128104-0000.flac'},
{'text': 'what does the person say?'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)1272-128104-0000.flacはセットアップが完了したらassetsのディレクトリに入っていると思います。
英語で話している内容になりますが、果たしてこれを認識できるのでしょうか・・・?
プロンプトは「what does the person say?(この人は何と言っていますか?)」とすごくシンプルなもの。
生成結果はこちらです!

「mister quilter is the apostle of the middle classes and we are glad to welcome his gospel」と表示されています。
最初サンプルを聞いたときは正直「???」でしたが、生成されたテキストを見ながらもう一度聞いてみると、確かにそう言ってますね!
何より驚いたのが生成速度です。
Colabの実行ボタンの左の時間ですが、なんと「1秒」!
確かに音声は一言だけでしたが、Qwen-Audioは一瞬で何を言っているか分析しテキスト化することができています。
では、いろいろな音源を試してQwen-Audioの真の実力を見せてもらいましょう!!
Qwen-Audioの推しポイントである音声特化のAIというは本当なのか?
今のLLMは画像や音声から結果を返してくれるマルチモーダルになっているので、先程の音声からテキスト化するというのはあまり目新しくないかもしれません。
ただ、Qwen-Audioの真価はここからです!
今回は音声特化のAIを試してみるため「シーンを理解し、解決策を提案してもらう」と「日本語から英語に訳してもらう」の2つを行ってみたいと思います!
Qwen-Audioにシーンを理解・分析して解決方法を提案してもらう
まず最初は、こちらの音声。
プロンプトは公式と同じものを入力しました。
Recognize the sound information and assume that the sound is happening around the user.
Please provide the user with some handling suggestions.
訳:音の情報を認識し、その音がユーザーの周囲で発生していると仮定してください。ユーザーに対処の提案を行ってください。Qwen-Audioは赤ちゃんが泣いているシーンを把握して、解決方法を教えてくれるのでしょうか!?
結果はこちらです!
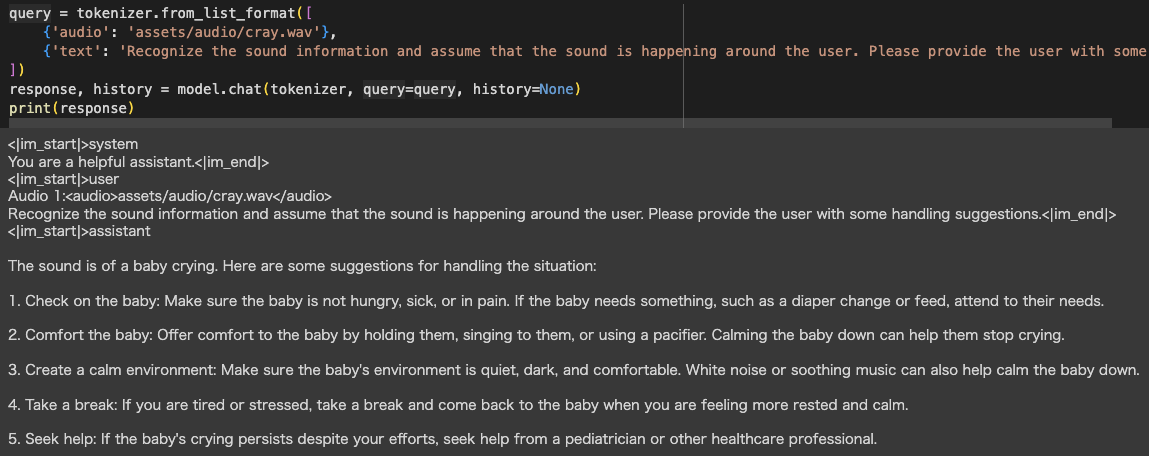
今回も生成は一瞬でしたが、なんと解決方法を5つも提案してくれています!
The sound is of a baby crying. Here are some suggestions for handling the situation:
- Check on the baby: Make sure the baby is not hungry, sick, or in pain. If the baby needs something, such as a diaper change or feed, attend to their needs.
- Comfort the baby: Offer comfort to the baby by holding them, singing to them, or using a pacifier. Calming the baby down can help them stop crying.
- Create a calm environment: Make sure the baby’s environment is quiet, dark, and comfortable. White noise or soothing music can also help calm the baby down.
- Take a break: If you are tired or stressed, take a break and come back to the baby when you are feeling more rested and calm.
- Seek help: If the baby’s crying persists despite your efforts, seek help from a pediatrician or other healthcare professional.
日本語訳:
赤ちゃんが泣いている音です。この状況を処理するための提案は以下の通りです:
- 赤ちゃんの様子を見る:赤ちゃんがお腹が空いていたり、病気であったり痛みを感じていないか確認してください。おむつ替えや授乳など、赤ちゃんが何か必要な場合は、そのニーズに対応してください。
- 赤ちゃんを慰める:抱っこしたり、歌を歌ったり、おしゃぶりを使ったりして、赤ちゃんを慰めてください。赤ちゃんを落ち着かせることが泣き止ませる手助けになります。
- 穏やかな環境を作る:赤ちゃんの周りが静かで、暗く、快適であることを確認してください。ホワイトノイズや穏やかな音楽も赤ちゃんを落ち着かせるのに役立ちます。
- 休憩を取る:疲れていたりストレスを感じている場合は、休憩を取り落ち着いた後に赤ちゃんのもとへ戻ってください。
- 助けを求める:努力にもかかわらず赤ちゃんの泣き声が続く場合は、小児科医や他の医療専門家に助けを求めてください。
赤ちゃんが泣いている状況を把握して、適切な解決方法を提示してくれています。
英語で回答が生成されたものをChatGPTで訳してもらったんですが、泣いている赤ちゃんへの対応って万国共通なんですね。
一般的な解決方法とはいえ、音声から判断して一瞬でこの回答を返すことができるのはすごいですねぇ・・・。
多言語の音声・動画を自動で文字起こしするツールを知りたい方は、以下の記事もご覧ください。
Qwen-Audioで多言語翻訳を試す
では次に日本語から英語に訳してもらいましょう!
お題はこちら!
公式より長いテキストを「VOICEVOX:ずんだもん」に読みあげてもらいました!
台本はしなりおやさんからお借りしました。
今日は晴れだって言ってたじゃん。天気予報の嘘つき。
あれ、君も傘忘れ組? 私も。やだね、雨。
置き傘も無いし。うーん。
折りたたみ持ってなかったっけ……あった!
小さいけど、入ってく? 近くのコンビニぐらいまで。
じゃ、持って。傘。君のが背高いんだから。
ナレーションのような文章ではなく、会話形式となっています。
「傘忘れ組」や「君のが背高いんだから」といった言い回しは難しいかもしれませんね。。。
このテキストを翻訳してもらうプロンプトは下記の通りです。
recognize the speech, and translate it into English
訳:話し言葉を認識し、それを英語に翻訳する
果たして、Qwen-Audioはうまく翻訳してくれるのか・・・!?
結果はこちらです!
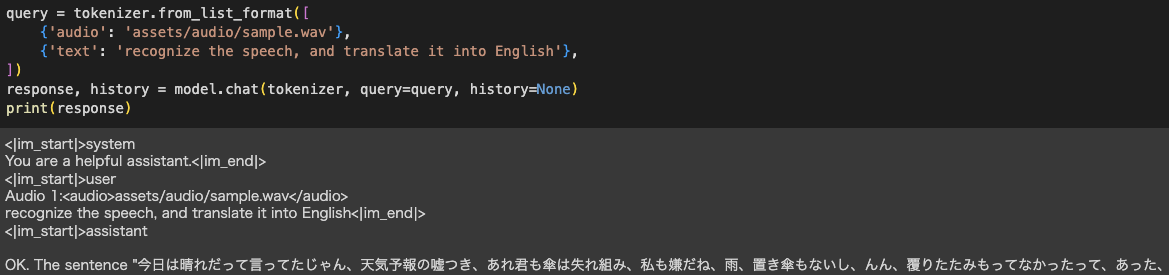
OK. The sentence
“今日は晴れだって言ってたじゃん、天気予報の嘘つき、あれ君も傘は失れ組み、私も嫌だね、雨、置き傘もないし、んん、覆りたたみもってなかったって、あった、小さいけど、入ってく、近くのコンビニブルーまで、じゃあ、持って傘、君逃げせ高いんだから”
translated into English is
“Today is sunny, right? The weather forecast is a lie, huh? And you, you don’t have an umbrella either, me neither. I don’t like rain or wind. And, the umbrella that I had, it wasn’t even with me. And it was small, but I went to the convenience store nearby. So, I’m carrying an umbrella, you run away and it’s expensive, so…”.
まず驚くべきは日本語の認識率の高さですね。。。
100%完璧ではなく、やはり会話の言い回し部分などで間違いはありますが、十分読める文章に仕上がっています。
それだけでなく、しっかりと文脈を認識して漢字までテキスト化してくれています!
ではどこまで英語に翻訳されたのか確認してみましょう。
生成されたテキストをChatGPTで翻訳してみると・・・
今日は晴れですよね?天気予報は嘘だったんだな?
そしてあなたも、傘を持っていないんですよね、私も同じです。雨や風が好きじゃないんです。
それに、私が持っていた傘は私の所にさえなかったんです。
それは小さい傘だったけど、近くのコンビニに行きました。
だから、傘を持っていますが、あなたは走って逃げるし、それに高いし…
前半は完璧ですねぇ。中盤以降は少し文脈がおかしいですが、これはQwen-Audioが日本語をテキスト化した時点で原文とずれていたので仕方ない部分かなと思います。
今回は音声ソフトを使用しましたが、生成速度も早く、無料でこのレベルを使えるのであれば十分ではないでしょうか?
Qwen-Audioに入力するプロンプトを工夫したり、認識しやすいオーディオを使うなどすればまだまだ精度をあげることができそうです!
なお、Metaの音声生成AIについて知りたい方はこちらの記事をご覧ください。
→【MAGNeT】Meta開発のテキストから音楽や音声を生成できるAIの使い方~実践まで
まとめ
見ていただいた通り、Qwen-Audioはオーディオに特化した生成AIとなります。
シーン理解のテストでは音源から周囲の状況を認識し、解決方法を提示してくれました。
また、翻訳に関しては100%完璧ではないですが、十分使える精度だったと思います。
もっと誰でも使いやすくなれば、という課題点は残りますが、Qwen-Audioはシーン理解など翻訳以外の機能もすごいので、スタートレックの宇宙翻訳機以上のポテンシャルをもっているのでは、と感じました。
テキストだけでなく音源を使って生成AIで何かやりたい!と思っている方はぜひQwen-Audioを使ってみてはいかがでしょうか?

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

