
【AlibabaのQwen2.5-VL】動画・画像解析がさらに進化した最新VLMを徹底解説
- 画像とテキストだけでなく長時間の動画解析が可能
- エージェント機能付き
- 物体検知の正確性が向上
2025年1月28日、Alibabaから新たなVLMが登場!
昨日はQwen2.5-1MというLLMがリリースされ、連日のリリースとなりました。
今回リリースされたVLMは「Qwen2.5-VL」で、画像とテキストだけではなく1時間を超える動画を解析し、特定のイベントを識別することが可能。
モデルは3B、7B、72Bの3種類用意されており、用途に応じて使い分けができます。
本記事ではQwen2.5-VLの概要からgoogle colaboratoryでの実装方法までお伝えします。本記事を最後までお読みいただくことで、Qwen2.5-VLの使い方をマスターできるでしょう。
ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Qwen2.5-VLの概要
Qwen2.5-VLはAlibabaが新たにリリースした「Vision-Language Model」です。
Qwen2.5-VLは、花や動物などの物体や画像内のテキストやチャート、レイアウトなどを解析できます。また、画像やテキストのみならず、1時間を超える長時間の動画を解析し、特定のイベントを識別することも可能です。
特に画像の解析では、物体検知の正確性・検出力が向上しており、画像内の物体をバウンディングボックスやポインタとして正確に特定、JSON形式での出力が可能。
また、エージェントとしての役割も果たし、自ら推論しパソコンやスマホでのタスクを実行することもできます。
Qwen2.5-VLの特徴
Qwen2.5-VLはVLMであるため、ドキュメントや図表、スキャンした書類の内容理解などに強みを持ちます。また、視覚情報からの内容理解に優れていることから、後述するベンチマークでは数学のスコアも非常に高い結果になっています。
また、物体検知と画像解析の性能が改善され、画像内のオブジェクトを正確に識別し、バウンディングボックスや座標情報をJSON形式で出力可能。複雑なレイアウトの文書やスキャン画像から、正確なテキストを抽出・解析も可能です。
さらにこれまでのVLMと異なる点は、エージェント機能を有している点です。AndroidのUI操作やタスク実行が可能となり、画面上の要素を特定し、操作を指示できるようになっています。
Qwen2.5-VLの特徴をまとめると以下です。
- マルチモーダル対応(画像+動画+テキスト)
- 数学、文書解析、動画理解で競合モデルを上回る性能
- 物体検知・OCRの精度が向上し、JSON出力可能
- 視覚エージェント機能で、スマホやアプリ操作の自動化が可能
Qwen2.5-VLのパフォーマンス
Qwen2.5-VLは従来モデルであるQwen2-VLよりも大幅に精度が向上し、特に文章や図表の理解でベンチマークを改善しています。
また、Qwen2.5-VLでは新たなアプローチが採用されており、動的なフレームレートや時間エンコーディング技術を導入し、時間的・空間的スケール認識を強化しています。
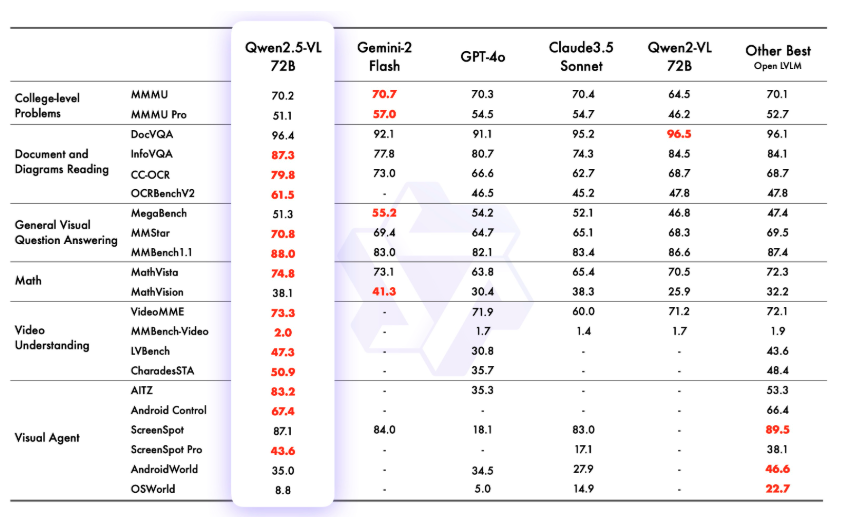
上記ベンチマークで特筆すべきは以下4点でしょうか。
- Document and Diagrams Reading: 文書や図表の理解
- General Visual Question Answering: 一般的な視覚質問応答能力
- Video Understanding: 動画の内容理解
- Visual Agent: 視覚エージェントとしてのタスク遂行能力
いずれもVLMとしての性能を評価するベンチマークです。
Document and Diagrams Reading
まずDocument and Diagrams Readingでは、DocVQAはQwen2-VLに劣るもののほぼほぼスコアは変わらない結果です。またそれ以外の3項目ではそのほかのAIモデルよりも好成績を残しています。この結果からQwen2.5-VLが図表や文書の理解において非常に優れた性能を発揮することがわかります。
General Visual Question Answering
続いて、General Visual Question Answeringです。MegaBenchではGemini-2 flashやGPT-4oには劣ってしまうスコアですが、そのほか2項目ではトップスコアを記録しています。
Video Understanding
Video UnderstandingはAIモデルが動画の内容をどれだけ正確に理解し、関連する質問に答えられるかを評価します。
Qwen2.5-VL 72Bは、動画理解においてGPT-4oやClaude3.5 Sonnet、Qwen2-VL 72Bなどその他のAIモデルよりも優れたパフォーマンスを発揮。特にVideoMEとCharadesSTAでトップスコアを記録し、動画内のイベントや全体の理解力が高いと言えます。
Visual Agent
Visual Agentは、AIモデルが視覚情報を基にタスクを遂行する能力を評価する指標です。ScreenSpotは非常に高いスコアで、Gemini-2 FlashやQwen2-VL 72Bよりも優れていることがわかります。
またAndroidWorldでも他のモデルよりも優れたスコアを出しており、視覚情報を活用したインターフェース操作やエージェント機能では一歩抜きん出ているという結果です。
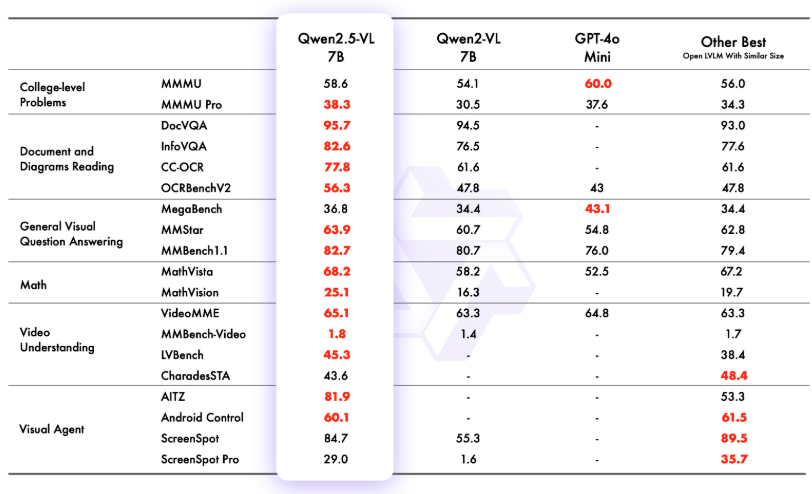
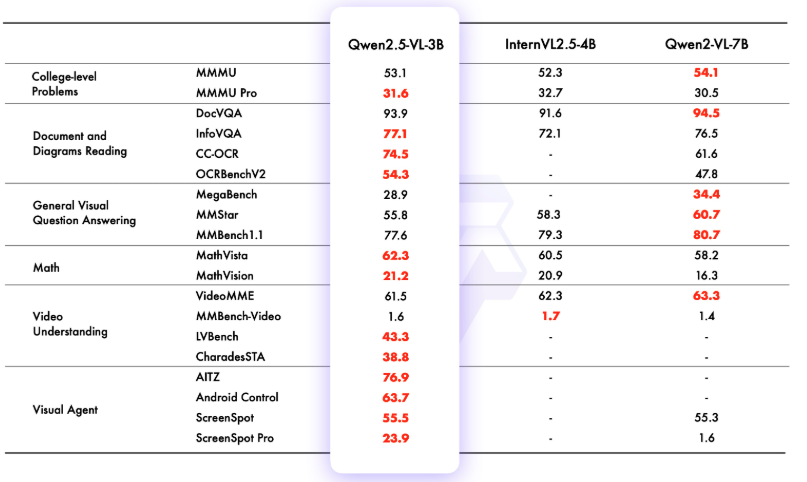
なお、7B、3Bのパフォーマンスは以下のとおりです。


Qwen2.5-VLのライセンス
Qwen2.5-VLのライセンスはQwen RESEARCH LICENSE AGREEMENTです。
Qwen RESEARCH LICENSE AGREEMENTは研究目的での利用を想定しており、商用利用は不可です。
商用利用でQwen2.5-VLを使いたい場合には、Alibaba Cloudからのライセンス取得が必要。
また、特許使用も可能ではありますが、Alibaba Cloudは、Qwen自体の知的財産権を保持。ただし、ユーザーがQwenを基に開発した派生物は、ユーザー自身の所有物になります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ❌ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️(制限あり) |
| 私的使用 | ⭕️ |
ただ、HuggingFaceのライセンスページにはQwen RESEARCH LICENSE AGREEMENTと書かれていますが、GitHubのライセンスページにはApache2.0と記載されています。
Apache2.0であれば商用利用も可能ですが、Qwen RESEARCH LICENSE AGREEMENTでは商用利用が禁止されているので、Qwen RESEARCH LICENSE AGREEMENTに従ったほうが後々大変なことにならずに済むかもしれません。
なお、Qwenベースの推論モデル登場について詳しく知りたい方は、下記の記事を合わせてご確認ください。

Qwen2.5-VLの使い方
Qwen2.5-VLにはChat版が用意されているので、そちらを利用すれば手軽にQwen2.5-VLを使うことができます。
タブからQwen2.5-VLを選択すればOKです。
また、HuggingFaceにもアップされているので、google colaboratoryでも実装が可能です。
Qwen2.5-VLのgoogle colaboratoryでの使い方
google colaboratoryの実行環境
■Pythonのバージョン:Python3.9
■システム RAM:4.5 / 83.5 GB
■GPU RAM:26.5 / 40.0 GB
■ディスク:38.5 / 235.7 GB
■プラン:有料
■GPU:A100
まずは必要ライブラリのインストールです。
!pip install git+https://github.com/huggingface/transformers accelerate
!pip install qwen-vl-utils[decord]==0.0.8次にモデルのダウンロードと画像読み込み、実行です。
モデルのダウンロードと画像読み込みはこちら
import torch
from transformers import AutoModelForVision2Seq, AutoProcessor
from qwen_vl_utils import process_vision_info
from PIL import Image
import requests
from io import BytesIO
model_name = "Qwen/Qwen2.5-VL-3B-Instruct"
device = "cuda" if torch.cuda.is_available() else "cpu"
model = AutoModelForVision2Seq.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_name)
image_path = "/content/my_image.jpg"
image = Image.open(image_path)
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image}, # 画像
{"type": "text", "text": "この画像を説明してください。"}
],
}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text], images=image_inputs, videos=video_inputs,
padding=True, return_tensors="pt"
).to(device)
generated_ids = model.generate(**inputs, max_new_tokens=128)
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print("### 画像の説明:")
print(output_text[0])結果はこちら
OutOfMemoryError: CUDA out of memory. Tried to allocate 252.57 GiB. GPU 0 has a total capacity of 39.56 GiB of which 13.10 GiB is free. Process 33848 has 26.46 GiB memory in use. Of the allocated memory 22.09 GiB is allocated by PyTorch, and 3.87 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)上記のコードだとA100でもメモリ不足になってしまい、実行完了できませんでした。
HuggingFaceにデモ版も用意されているので、そちらで実行してみます。
解説してもらう画像はこちらです。
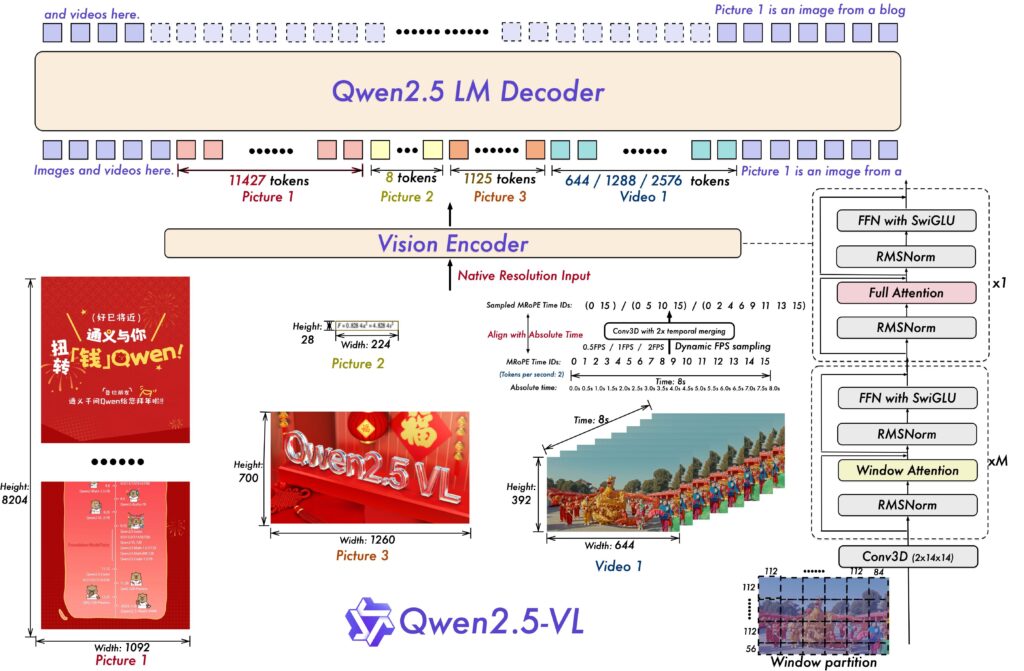
結果はこちら
この画像は、Qwen2.5-VLというマルチモーダルな大規模言語モデルのアーキテクチャを示しています。以下に各部分の詳細な解説を行います。
1. Vision Encoder
Native Resolution Input: 入力として画像やビデオが与えられます。これらの入力は元の解像度で処理されます。
Picture 1, Picture 2, Picture 3: それぞれ異なる画像が示されており、そのサイズ(高さと幅)が記載されています。
Picture 1: 高さ8204ピクセル、幅1092ピクセル
Picture 2: 高さ28ピクセル、幅224ピクセル
Picture 3: 高さ700ピクセル、幅1260ピクセル
Video 1: ビデオのフレーム数と時間長が示されています。フレームレートは0.5FPS、1FPS、2FPSで動的にサンプリングされ、絶対時間(0.0sから8.0s)に対応するトークンIDが生成されます。
2. Conv3D with 2x temporal merging
このブロックでは、3次元畳み込み(Conv3D)が行われ、時間方向に2倍のマージングが適用されます。これにより、時系列データの特徴を効率的に抽出します。
3. Window Attention
窓ごとの自己注意メカニズムが適用されます。これは、局所的な情報の相互作用を捉えるために使用されます。図には窓分割の例が示されており、各窓のサイズ(112x112など)が記載されています。
4. FFN with SwiGLU
Feed-Forward Network (FFN) にSwish-Gated Linear Unit (SwiGLU) アクティベーション関数が使用されています。これは非線形性を導入し、モデルの表現力を向上させます。
5. RMSNorm
Root Mean Square Normalization (RMSNorm) が適用されます。これは、学習過程での勾配の安定化と収束速度の向上に寄与します。
6. Full Attention
全体的な自己注意メカニズムが適用されます。これは、グローバルな情報の相互作用を捉えるために使用されます。
7. Qwen2.5 LM Decoder
最終的に、Qwen2.5 Language Model Decoderが動作し、出力を生成します。ここでは、画像やビデオからの情報を統合して、適切な応答や生成結果を出力します。
8. Token Counts
各画像やビデオからのトークン数が示されています。例えば、Picture 1からは11427トークン、Picture 2からは8トークン、Picture 3からは1125トークン、Video 1からは644/1288/2576トークンが生成されます。
このアーキテクチャは、画像やビデオなどの視覚的情報を効果的に処理し、言語モデルと統合することで、より豊かなマルチモーダルな理解と生成能力を実現しています。適切に画像を解説してくれているように思います。
画像読み込み性能と数学の能力を検証
Qwen2.5-VLは画像内の物体検知やテキスト検出の性能が非常に高く、数学のベンチマークも好成績でした。数学の問題を読み込ませて、解いてもらうタスクと機械学習関連の画像を読み込んで解説するタスクの2つを行なってみます。
数学の問題では、問題文を適切に読み込めているかを確認するため、問題文も出力してもらいます。
数学タスク
今回タスクとして与えるのは、京大入試問題です。

プロンプトとしては以下です。
添付した問題を解いてください。回答する際には、問題文も出力してから回答を出力してください。回答はこちら
問題文: tan1°は有理数か.
回答:
tan1°は有理数ではありません。
証明の概要を以下に示します:
まず、tan3°が無理数であることを示す。
tan3° = (3tan1° - tan^3(1°)) / (1 - 3tan^2(1°))
この式から、tan1°が有理数だと仮定すると、tan3°も有理数になってしまいます。
次に、tan3°が無理数であることを直接示す。
tan3° = √(3-√3)/√(3+√3)
この形から、tan3°が無理数であることがわかります。
よって、tan1°が有理数だと仮定した場合に矛盾が生じるため、
tan1°は有理数でないことが結論付けられます。
この証明は、三角関数の性質と代数的な操作を用いています。tan1°が有理数でないことは、角度の単位度と弧度の間の複雑な関係を反映しています。tan1°は有理数ではありません。と適切に回答することができています。また、問題文も適切に読み込めていますね。
機械学習関連画像の解説
今回の論文はQwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyondで、ここから画像を使って解説してもらいます。
画像はこちらです。

回答はこちら
この画像は、様々な質問とそれに対する回答が表示されたスクリーンショットのコレクションです。各セクションには異なるトピックや形式の情報が含まれています。
人物の比較: 2人の男性の顔写真が示され、その特徴を比較する質問があります。
病院のフロア案内: 病院のサインボードが示され、特定の診療科(耳鼻咽喉科)がどのフロアにあるか尋ねる質問があります。
都市の比較: 中国の重慶と北京の都市風景が示され、両者の違いについて説明する質問があります。
論文の要約: 論文の一部が示され、その内容を要約する質問があります。
プログラミング問題: コードが示され、そのコードが何をするのかを説明する質問があります。
画像認識: 人々が集まっている場面の画像が示され、特定の人々(例えば「赤い帽子をかぶった人」)を探す質問があります。
複雑な論文の要約: より詳細で専門的な論文の一部が示され、その内容を要約する質問があります。
これらのセクションは、人工知能や自然言語処理のシステムが様々な種類の情報を理解し、適切な回答を生成できる能力を示しています。適切に解説できている部分とできていない部分がありますね。特に1つ目の回答の人物の比較では4人の人物がいるのに2人の男性と回答をしています。一方で、都市の比較は適切に解説ができているように思います。
なお、Microsoftがリリースしたマルチモーダルモデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

まとめ
本記事ではQwen2.5-VLの概要からgoogle colaboratoryでの使い方について解説をしました。
これまでのVLMの中でもQwen2.5-VLはベンチマークで良好なスコアを残しています。
今後Qwen2.5-VLが商用利用できるようになると、医療画像やレントゲンの解析を行い、異常箇所を特定する診断支援ツールとして活用したり、学生向けに複雑な図表や数学問題を視覚的に解釈し、わかりやすい解説を生成など、さまざまな場面で活用が期待できますね。
ぜひ本記事を参考にQwen2.5-VLを使ってみてください!
最後に
いかがだったでしょうか
LLMの活用で画像や動画解析、視覚情報を基にしたタスク自動化が可能になり、業務効率化やプロセス改善ができます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


