
【Qwen3-Next-80B-A3B】使い方や特徴、性能をGeminiと比較検証しながら徹底解説
- AlibabaのQwenチーム発の次世代大規模言語モデル
- 800億パラメータを持ちながら、推論時はわずか30億パラメータしか活性化しない超効率設計
- Apache License 2.0のもと公開、商用・私的を問わず自由に利用可能
2025年9月12日、AlibabaのQwenチームは次世代大規模言語モデル「Qwen3-Next-80B-A3B」を発表しました!
昨今、AI研究においてはパラメータ数や文脈長の拡大が続いていますが、これに応える形で「Qwen3-Next」アーキテクチャが導入されました。本モデルは、800億パラメータを持ちながら、実際の推論ではわずか30億パラメータしか活性化しない超効率設計が特徴となっています。
公式発表によると、このInstruct版は2,350億モデルと同等の性能を示し、Thinking版はGemini-2.5-Flashを超える優れた推論能力を発揮するとのこと。
そこで本記事では、Qwen3-Next-80B-A3Bの概要、性能、使い方、InstructモードとThinkingモードの違いまで徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Qwen3-Next-80B-A3Bの概要

Qwen3-Next-80B-A3Bシリーズには、指示応答に特化した「Instructモード」と、思考過程を出力する「Thinkingモード」があります。いずれも新しいハイブリッドアテンション機構を採用し、Gated DeltaNetとGated Attentionを組み合わせることで長大コンテキストを効率的に処理する設計になっています。
また、Mixture-of-Experts(MoE)構造によって、モデルの中に512個の小さなサブネットが用意されていますが、トークンごとに10個のサブネットしか活性化しません。イメージ的には、512人のスペシャリストが在籍する大きな相談所があって、毎回10人だけに相談し、回答をまとめて返すような感じ。かなり効率的な設計です。この設計によって、訓練コストは従来の1/10となり、推論時には10倍以上の高速化が実現されています。モデルは事前学習に約15兆トークンのデータを用い、隠れ次元2048・層数48層のハイブリッド構成で学習されています。
さらに、マルチトークン予測機能を搭載し、推論時に複数トークン同時生成による高速化も実現します。文脈長はネイティブで26万トークンに対応し、拡張することで100万トークン近くまで扱えます。これによって、巨大なドキュメントや長い会話履歴も一度に解析可能となっています。
Qwen3-Next-80B-A3B-InstructとQwen3-Next-80B-A3B-Thinkingの違い
InstructとThinkingは同じ基盤モデルを共有していますが、出力モードに違いがあります。
Instruct版は、非思考(plain)モードのみをサポートし、出力に<think></think>タグを含めません。これはユーザーからの指示に対して簡潔に回答を得たい場合に適しています。
一方、Thinking版は思考モードのみをサポートし、回答前にモデルの思考プロセス(チェーン・オブ・ソート)を必ず生成します。そのため、長い推論過程や複雑なタスクに適しており、回答に至るまでのロジックを可視化できます。
また、公式発表によると、Thinking版は前世代の思考モデルよりも要約性能が向上し、Instruct版は中国語理解や論理推論などで強化されているとされています。つまり、複雑な多段階推論を必要とする場合はThinking版、シンプルな指示応答や高速性を重視する場合はInstruct版が適していると言えますね。


Qwen3-Next-80B-A3Bの性能
Qwen3-Next-80B-A3Bモデルは、同程度規模の従来モデルを上回る性能を誇っています。
Instruct版は、一部のベンチマークで規模が2倍以上の235Bモデルと同等のスコアを達成しており、特に256Kトークンを超えるような長文処理タスクでは大きな優位性があります。さらに、Thinking版は、複雑な推論タスクで優れた結果を出しており、Gemini-2.5-Flash-Thinkingを複数ベンチマークで上回ったとされています。
具体的なベンチマークでは、Knowledge系ベンチマーク(MMLU-Pro)で約82%の精度、Reasoning系(AIME25算数テスト)で約87.8%、Coding系(LiveCodeBench v6)で約66%といった高スコアが報告されています。これらはQwen3-32BやQwen3-30Bといった従来モデルを大きく上回り、GeminiやQwen3-235Bにも迫る性能となっています。
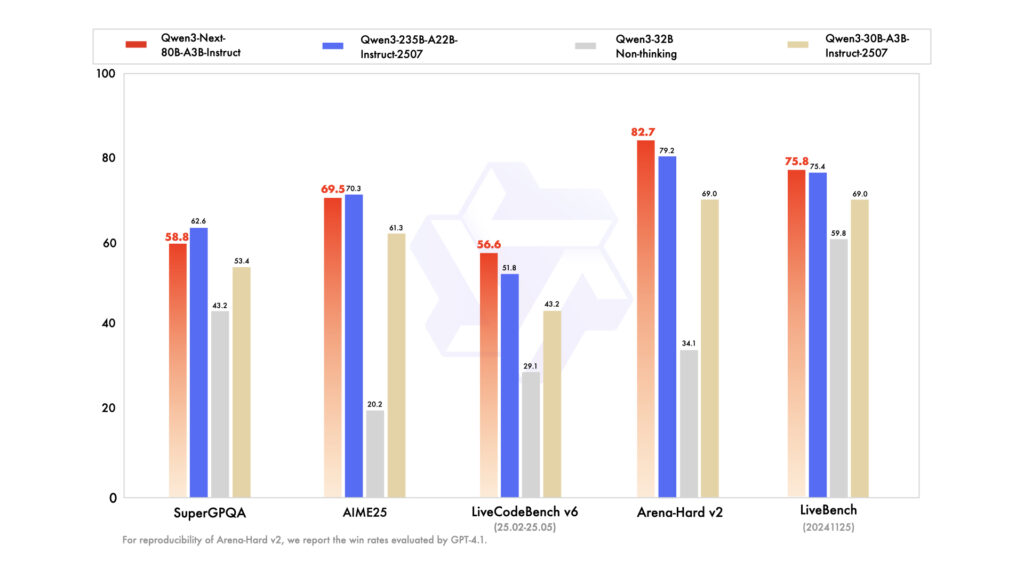
Alignmentテスト(IFEval)でも約89%と高い結果を示し、多言語性能(MMLU-ProX)も77.8%と健闘しています。
Qwen3-Next-80B-A3Bのライセンス
Qwen3-Next-80B-A3Bモデルは、Apache License 2.0のもとで公開されており、商用・私的を問わず自由に利用可能です。追加費用なしでモデルを利用・改変・再配布できる点が特徴です。たとえば、企業プロジェクトでの商用利用や、学術研究での派生モデル作成などもライセンス上は問題ありません。
| 利用用途 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | |
| 改変 | ⭕️ | |
| 配布 | ⭕️ | |
| 特許使用 | ⭕️ | |
| 私的使用 | ⭕️ |
ただし、Apache 2.0には著作権表示やライセンス文の明示など遵守事項が含まれるほか、商標使用には別途Alibabaのガイドラインが適用される点に注意が必要です。
実際に利用する際には、公式情報を確認するようにしましょう。


Qwen3-Next-80B-A3Bの料金
Alibaba Cloud Model Studioを通じたAPI呼び出しでは従量課金制が適用されます。以下の表は、2025年9月時点でのQwen3-Next-80B-A3Bモデルのトークン単価表です。
Instruct版は生成回答にかかる出力トークンの単価が安価に設定されており、Thinking版は内部で生成される思考プロセス分も含めて高めの設定になっています。
| プラン | 入力単価(100万トークン) | 出力単価(100万トークン) |
|---|---|---|
| Alibaba Cloud Model Studio (Instruct版) | $0.5 | $2.0 |
| Alibaba Cloud Model Studio (Thinking版) | $0.5 | $6.0 |
Alibaba Cloudでは、新規ユーザー向けに1モデルあたり計100万トークンの無料枠が提供されます。登録後90日間有効なようです。最新の価格体系や割引プランについてはAlibaba Cloud公式サイトで確認することをおすすめします。
Qwen3-Next-80B-A3Bの使い方
Qwen3-Next-80B-A3Bは、公式チャットUIやHugging Face Transformers、vLLMなどから利用することができます。今回は公式チャットUIとHugging Face Transformers経由での使い方を紹介します。
公式チャットUI
公式チャットUI(Qwen Chat)では、ウェブブラウザ上で会話形式のインターフェースにアクセスできます。
Qwen Chatへログイン後、モデル選択メニューから「Qwen3-Max-Preview」を選び、プロンプトを入力することで対話を開始できます。特別な設定は不要で、基本的な会話や指示出しを通じてモデルの性能を体感できます。
Hugging Face Transformers
Qwen3-Next-80B-A3Bは、公式にHugging Face Transformersへ組み込まれており、Pythonコードから簡単に利用できます。まず最新版のTransformersライブラリをインストールします。例えば以下のようにGitHubのmainブランチを指定します。
pip install git+https://github.com/huggingface/transformers.git@main次にモデルとトークナイザをロードします。AutoTokenizerとAutoModelForCausalLMを使い、モデル名を指定するだけで準備完了です。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct" # Instruct版を例にしてます
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")入力プロンプトを作成する際は、Chat形式のテンプレートを利用します。例えばユーザーからの質問をmessages = [{"role":"user","content":"こんにちは"}]のように与えた後、tokenizer.apply_chat_templateでモデル入力に変換します。
その上でmodel.generateを呼び出してテキスト生成を行い、結果をtokenizer.decodeで復元すれば応答が得られます。サンプルコードの一例は以下の通りです。
# プロンプトの準備
messages = [{"role":"user", "content":"Qwen3とは何か説明してください。"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 生成実行
generated_ids = model.generate(**inputs, max_new_tokens=512)
output = tokenizer.decode(generated_ids[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
print(output)以上で完了です。
この他にも、Alibaba CloudのDashScopeを使った呼び出し利用も可能です。公式リポジトリやHugging Faceのドキュメントに例が掲載されているので、実装の詳細や推奨環境についてはそちらを参照するとよいと思います。
Qwen3-Next-80B-A3B vs Gemini-2.5-Proで比較検証してみた
ここからは実際にQwen3-Next-80B-A3B-Thinkingの推論性能を確認するために、同一タスクの出力結果をGemini-2.5-Proと比較しながら検証していきます。Qwen3-Next-80B-A3B-Thinkingについては、QwenチャットUIを用いていきます。
損益計算タスク
プロンプトはこちら
あなたは会計担当です。次の3件の受注について、最終の純利益(net_profit)を計算してください。外部知識は使わず、ここにある数字のみ使用すること。
[商品マスター]
- A: 仕入原価 1200 円 / 販売価格 2000 円
- B: 仕入原価 3000 円 / 販売価格 4500 円
- C: 仕入原価 500 円 / 販売価格 1000 円
[受注]
- O1: A を 3 個
- O2: B を 2 個(のちに 1 個返品)
- O3: C を 5 個(5%クーポン適用、販売価格に対し一律で割引)
[共通ルール]
- 送料は各受注ごとに 400 円固定。
- 決済手数料は「各受注の最終売上金額 × 3%」。返品はO2の最終売上から控除済みとみなす。
- 消費税・その他費用は考慮しない。
- 返品は全額返金で、返品分は売上・原価ともに発生しなかったものとして扱う(=売上にも原価にも計上しない)。
- 端数はそのまま(四捨五入しない)。
[求めるもの]
- revenue(売上合計)
- cogs(売上原価合計)
- fees(決済手数料合計)
- shipping(送料合計)
- net_profit = revenue - cogs - fees - shipping
[出力形式(JSONのみ)]
{
"task": "ec-ledger",
"revenue": <number>,
"cogs": <number>,
"fees": <number>,
"shipping": <number>,
"net_profit": <number>,
"rationale": "<日本語で20語以内。式の骨子のみ>"
}
禁止事項:JSON以外の出力、箇条書き、長文の推論説明、外部知識の使用。Qwen3-Next-80B-A3Bの思考プロセス(一部抜粋)はこちら。
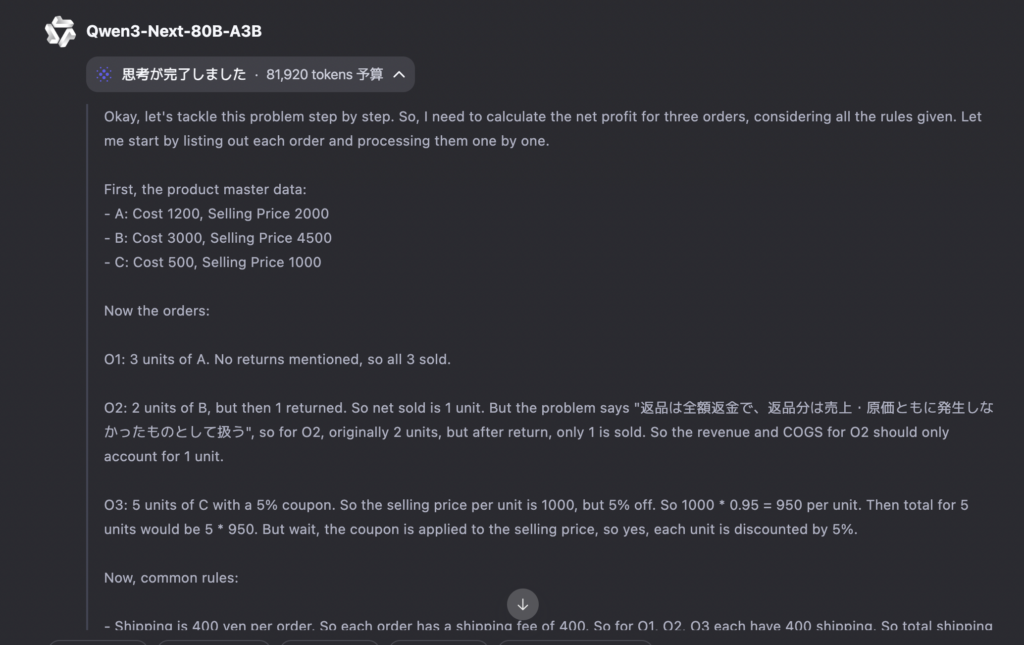
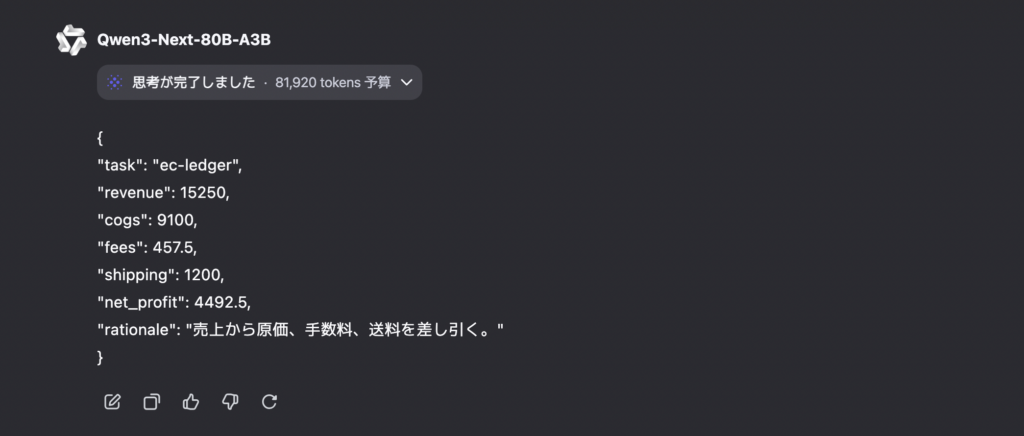
Qwen3-Next-80B-A3Bの出力結果はこちら。
Gemini-2.5-Proの出力結果はこちら。
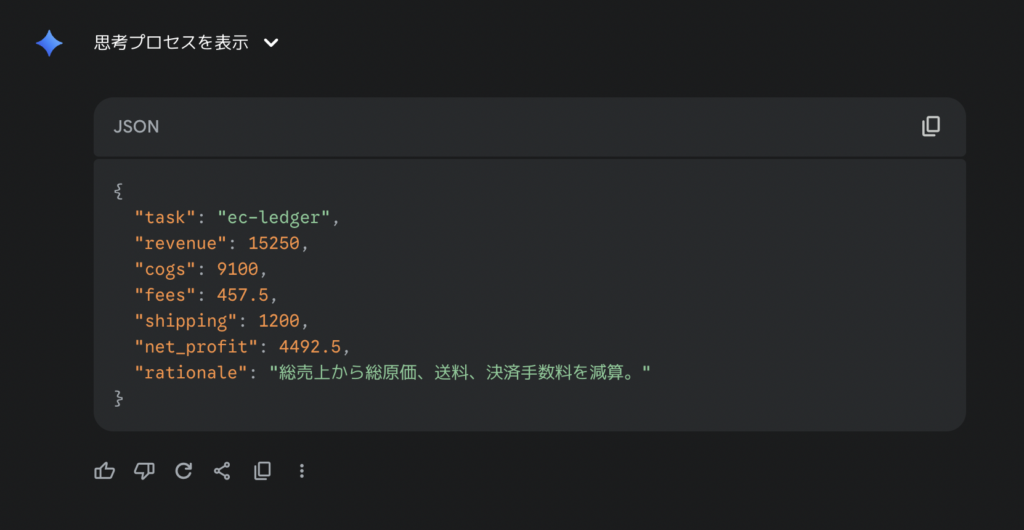
両モデルともに正解です。思考プロセスを見てみると、キレイに多段計算ができていることが確認できました。
コード読解タスク
続いてコード読解力についても確認してみましょう。
プロンプトはこちら。
あなたはPythonの実行結果を厳密に予測する役目です。次のコードを読み、printが出力する1行の内容を正確に答えてください。コードはPython 3.11準拠です。
def push(x, buf=[]):
buf.append(x)
return buf
def snap(a):
return [a[i]-a[i-1] for i in range(1, len(a))]
s1 = push(10)
s2 = push(20)
s3 = push(30, [])
s4 = push(40)
d1 = snap(s1)
d2 = snap(s3)
print(s1, s2, s3, s4, d1, d2)
[出力形式(JSONのみ)]
{
"task": "py-output",
"printed": "<printが実際に出す1行全体を、空白・カンマ位置まで正確に>",
"rationale": "<日本語で20語以内。要点のみ>"
}
注意:
- 文字列はダブルクォートで囲むこと。
- printed にはPythonのリスト表記をそのまま記すこと(空白も正確に)。
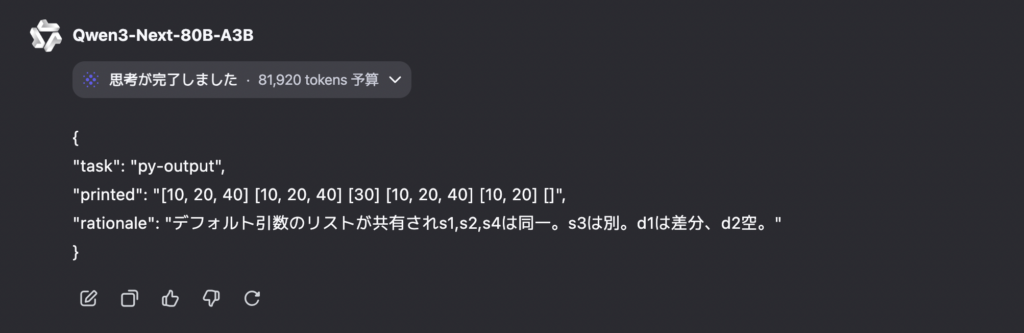
- 外部実行や仮定は行わない。Qwen3-Next-80B-A3Bの出力結果はこちら。
Gemini-2.5-Proの出力結果はこちら。
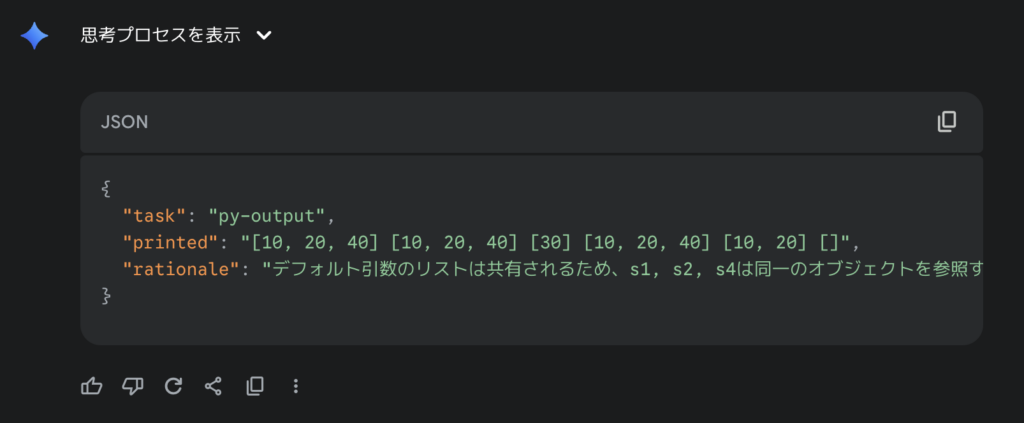
どちらも出力は正解です。push のデフォルト引数リストが共有されるため s1,s2,s4 が同一リスト [10, 20, 40]、個別指定の s3 は [30]。snap は差分なので d1=[10, 20]、d2=[] で合っています。
ただし、rationaleについては「日本語20語以内・要点のみ」という条件だったのに対して、Geminiはデフォルト引数の共有→同一参照だけに絞っていて簡潔になっている一方、Qwenは正しいものの、s3やd1/d2まで触れていて「要点のみ」という指示からは若干それている印象です。(誤差ですが)
比較検証してみた結果、Qwen3-Next-80B-A3B-Thinkingの推論精度は、Gemini-2.5-Proの精度に匹敵すると感じました。タスクによって若干の出力差は出るかと思いますが、ほぼGemini-2.5-Proと同程度かそれ以上と言ってもよいかと思います。
気になる方はぜひ他のタスクでも試してみてください。
まとめ
Qwen3-Next-80B-A3B-InstructおよびThinking版は、Alibabaが新たにリリースした大規模モデルです。
Instruct版は即時応答型でユーザー指示に沿った簡潔な出力を行い、Thinking版はチェーン・オブ・ソート付きで出力を行います。両者とも、Apache-2.0ライセンスで商用・個人問わず利用可能で、Alibaba Cloud Model StudioによるAPI提供を通じて、トークン課金で利用できます。
さらに、ベンチマークにおいて、GPT-4級の知識・推論能力やGemini級のパフォーマンスを誇っており、長文処理や生成タスクで高い能力を発揮します。
気になる方はぜひ一度試してみてください。

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。


