
【Reflection70B】GPT-4oやClaude 3.5超えの最強LLM?自らのミスを自動修正する技術搭載!

\生成AIを活用して業務プロセスを自動化/
Reflection70Bの概要
Reflection70BはHyperWriteが新たに発表したオープンソースのAIモデルです。
従来のAIモデルとReflection70Bが異なるのは、Reflection70BはMetaのLlamaをベースに開発されており、Reflection Tuningという技術が採用されています。
Reflection Tuningとは、生成したものを自らの力で誤りを検出・修正することです。つまり、Reflection70Bで生成されたものはReflection Tuningを使って、正確性を確認・評価されてからアウトプットされることになります。
トレーニングデータはGlaiveというシステムで生成された合成データを使用しており、このトレーニング方法がReflection70Bの推論能力を強めています。
Reflection70Bのベンチマーク
Reflection70Bは、LMSysのLLM Decontaminatorを使用してコンタミチェックが行われたベンチマークで性能を評価。
テスト結果が他のデータに影響されないように徹底されており、信頼性のあるデータに基づいてベンチマークが行われています。特に注目すべきは、<output>タグに限定してベンチマークを行う点です。これにより、Reflection70Bが最終的に出力した答えに対して正確に評価が行われます。
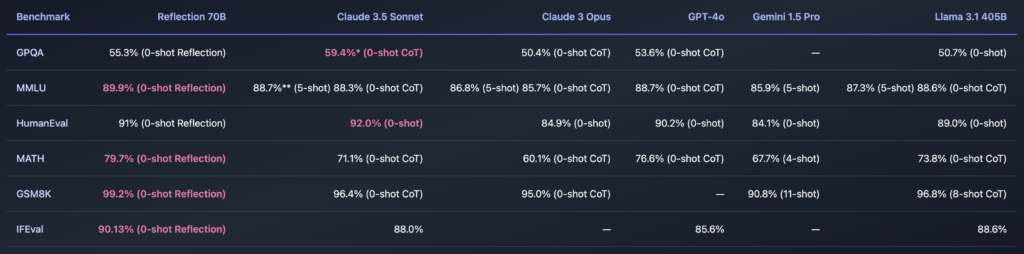
GPQA:一般知識に関するクエリに対するモデルの性能を示すベンチマーク。Reflection 70Bは55.3%の正解率を示しており、「0-shot Reflection」のため事前情報なしでモデルの推論能力を測定しています。他のモデルと比較すると、Claude 3.5 Sonnetが59.4%と少し高くなっていますが、他のモデルも50%前後の結果です。
MMLU:マルチタスク学習をテストするベンチマークで、複数の分野の問題に対するモデルの理解力を測定。Reflection 70Bは89.9%の正解率を示しており、他のモデルと比べると非常に高いパフォーマンスです。Claude 3.5 SonnetやGPT-4oも高いスコアを出していますが、Reflection 70Bがわずかに優れていることがわかります。
HumanEval:コード生成タスクで、モデルがプログラミングの問題にどれだけ正確に解答できるかを測定するベンチマークです。Reflection 70Bは91%のスコアを達成しており、Claude 3.5 Sonnetの92%とほぼ同等の結果です。
MATH: 数学に関する問題に対するパフォーマンスを測定。Reflection 70Bは79.7%の正解率を示しており、これも他のモデルに対して優れた結果を示しています。
GSM8K: 数学的な問題を解く能力を評価するベンチマーク。Reflection 70Bは99.2%という非常に高いスコアを示しています。他のモデルも高い結果を出していますが、Reflection 70Bが最も優れた結果を示しています。
IFEval: このベンチマークは、モデルの一般的な推論力を評価。Reflection 70Bは90.13%を示し、他のモデルと比較しても高いパフォーマンスを発揮しています。
Reflection70Bが発表されたのが、2024年9月6日で、その翌週にはReflection405Bが登場すると発表しています。
Reflection70Bで上記のベンチマークなので、Reflection405Bはそれ以上のベンチマークになることが予想されます。そうなると従来のモデルから頭一つ飛び抜けた性能になるでしょう。
Reflection70Bの仕組み
Reflection70Bは、推論過程を「見える化」するタグシステムです。
サンプリング中にReflection70Bはまず<thinking>タグ内に推論内容を表示し、Reflection70Bが自分の推論に納得した段階で最終的な答えを<output>タグ内に出力。このプロセスにより、Reflection70Bがどのように考え、答えに至るかをユーザーが理解しやすくなります。
さらに、Reflection70Bは推論中にエラーを検知した場合、冒頭でも紹介したように、自動的にそれを修正するReflection Tuning機能も備えています。
この時、<reflection>タグが使われ、Reflection70Bは自らの推論のミスを確認・修正をします。Reflection Tuningにより、最終的にユーザーに提供される答えがより正確になります。
Reflection70Bは、Llama 3.1シリーズの他のモデルと同様に、既存のコードやパイプラインをそのまま使って簡単に実装可能です。また、Reflection70Bはチャットをベースにしながら、推論と自己修正を助ける特別なトークンも新たに学習させているため、より高度な推論や自己修正ができます。
Reflection70Bのライセンス
Reflection70BのライセンスはLlama3.1のライセンスに則っています。基本的には商用利用や改変、配布など全て可能です。
しかし、製品やサービスの月間アクティブユーザーが700万人を超える場合、Metaから商用ライセンスを取得する必要があります。そのため、もし700万人を超える場合には、Metaの許可を取得しましょう。
また、改変した場合は「Llama」をモデル名の最初に含める必要があります。配布時には、ライセンスのコピーと「Built with Llama」という表示を行う義務があります。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
なお、405BパラメータMeta製LLMについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Reflection70Bの使い方
Reflection70Bを動かすコードはHuggingFaceに掲載されています。
そちらを参考にgoogle colaboratoryで実装しようと思いましたが、モデルのダウンロードが2GB×162個であっという間にディスク容量をオーバーしてしまい、モデルをダウンロードしてのgoogle colaboratoryでの実装は難しいです。
GPUを積んでいる方は、以下のコードで実装可能です。
Reflection70Bのサンプルコードはこちら
!pip install transformers
#セルを変更する
#パイプラインを使った実装
from transformers import pipeline
# ユーザーからのメッセージを定義
messages = [
{"role": "user", "content": "Who are you?"},
]
# モデルを使ってテキスト生成を実行
pipe = pipeline("text-generation", model="mattshumer/Reflection-Llama-3.1-70B")
output = pipe(messages)
# 結果を表示
print(output)
#モデルを直接ロードして実行
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("mattshumer/Reflection-Llama-3.1-70B")
model = AutoModelForCausalLM.from_pretrained("mattshumer/Reflection-Llama-3.1-70B")
inputs = tokenizer("Who are you?", return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Reflection70Bのplayground
Reflection70Bにはplaygroundが用意されているので、google colaboratoryで実装できない方は、playgroundを使ってReflection70Bを体験しましょう。
本記事執筆時にはサーバーが落ちてしまっているのか、playgroundを使うことができませんでした。
ただ、使い方は非常に簡単で、「Send a message」と書かれているチャット欄にテキストを入力して送信するだけです。
Llama 3.1 70Bがベースになっていますが、Llama 3.1 70B自体日本語があまり得意ではないので、日本語での文章生成は少し怪しい部分があるかもしれません。
Basetenを使った実装例
実装方法についてXを探していたら、以下のツイートを見つけました。
Basetenというサービスを使うとモデルのダウンロードなくReflection70Bをgoogle colaboratoryで使えるようなので、実際に実装してみました。
こちらのサービスは初回に30ドル分のクレジットをもらえ、google colaboratoryで動かすときにはCPUで動かすことができるので、試すだけなら無料で出来ます。
Basetenは機械学習モデルを簡単にデプロイでき、APIとして公開できるプラットフォームです。そのサービスを使ってReflection70Bを使っていきます。
実装する前にBasetenの登録を済ませておきましょう。サインアップはGoogleでできるので、そこまで大変じゃないと思います。

トップページにアクセスしたら、APIキーの発行とHugging Faceのトークンを入力しておきます。
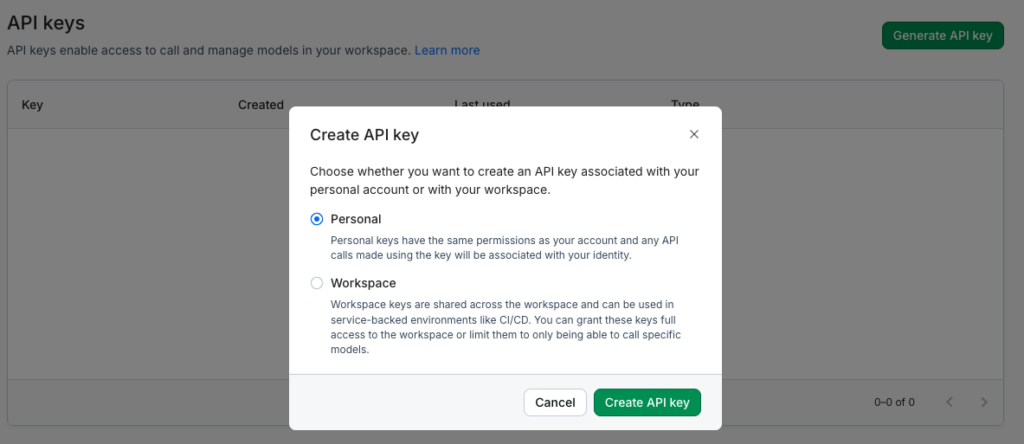
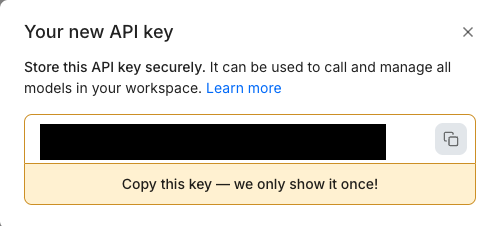
上記で表示されるAPIキーは一回しかコピペできないので、このときにコピペしておきましょう。
次にHugging Faceのアクセストークンを入力します。
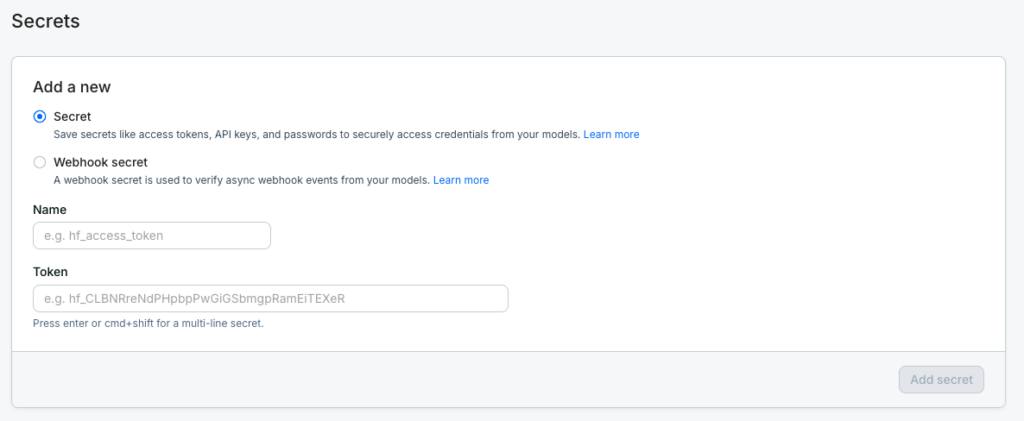
Secretにチェックを入れてnameは「hf_access_token」にして、Tokenの部分にHugging Faceのトークンを入力して「Add secret」を押せばOKです
あとはGitHubの順に沿って実装していけば大丈夫です。
Basetenにモデルをデプロイするのはこちら
!truss push --publish --trustedデプロイが完了するのに5分くらいかかると思います。
デプロイをしたら一度ワークスペースに戻って、以下のようにモデルが表示されているかを確認しましょう。
時間差で表示されることもあるので、少し待ってみてください。
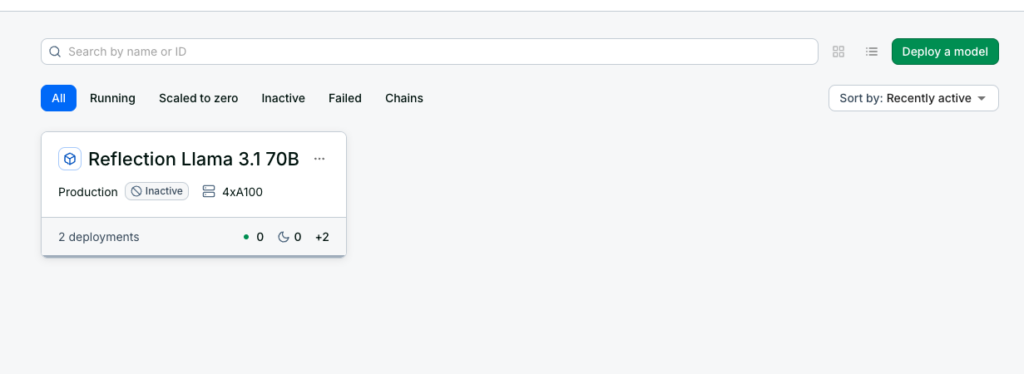
上の図のようにモデル名が表示されていればそちらをクリックして、詳細を確認しましょう。
赤枠内に書かれているものがコーディングの際に必要になる「model_id」です。クリックすればコピペできます。
Reflection70Bのサンプルコード
import requests
import os
# Basetenから取得したモデルIDとAPIキーを設定
model_id = "" # BasetenダッシュボードからモデルIDを取得
baseten_api_key = "" # APIキーを設定
# Call model endpoint
resp = requests.post(
f"https://model-{model_id}.api.baseten.co/production/predict",
headers={"Authorization": f"Api-Key {baseten_api_key}"},
json={
"messages": [
{"role": "system", "content": "You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside <thinking> tags, and then provide your final response inside <output> tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside <reflection> tags."},
{"role": "user", "content": ""}#テキストを入力
],
"max_tokens": 1024,
"temperature": 0.7,
"top_p": 0.95
},
stream=True
)
# Print the generated tokens as they get streamed
for content in resp.iter_content():
print(content.decode("utf-8"), end="", flush=True)
日本語でテキストを入力していますが、出力はどうしても英語になってしまいます。
他の生成AIモデルと同じプロンプトで性能を比較してみた
Claude 3.5 sonnetとChatGPT4-o、Gemini 1.5 Proで同じプロンプトを入力して比較してみました。
入力したプロンプトはこちらです。
取引先に対して、アポイントメントのメールを作成してください。
英訳:Compose an appointment e-mail to your business partners.
Reflection70Bの出力が英語になってしまうので、その他のモデルでも英語で出力されるよう、英語でプロンプトを与えます。
実際に4つのモデルで比較してみましたが、アポイントメールを作成するのはChatGPTが良いかもです。
というのも、具体的な日にちを提示しつつ、相手の都合が悪ければ別日程をいくつか送ってもらうように依頼しています。そして最後に所属や連絡先をちゃんと書いているので、もし私がビジネス向けメールを作るならChatGPTを選ぶかもです。
Reflection70Bの活用例
最後にReflection70Bの活用例を考えていきたいと思います。Reflection70Bの強みはなんと言っても自己修正機能であるReflection Tuningが実装されている点です。このReflection Tuningをうまく使うことで、さまざまな活用ができるでしょう。
技術サポート
例えば技術サポートやカスタマーサポートでReflection70Bを活用できるかもしれません。
ユーザーからの問い合わせを<thinking>で分析して適切な解決策を提案。
もし<thinking>で誤っていた場合には<reflection>で自己修正を行い、より正確な解決策を提案するようにします。
そして最終的な答えを<output>で出力することで、技術サポートやカスタマーサポートとして、ユーザーとのやり取りができるようになるかもしれません。もし実現できるならLINEなどのチャット機能を持っているサービスに組み込むことで業務負担軽減にもつながるでしょう。
ストーリーの作成
また、小説や短編映画などの脚本を生成できるかもしれません。<thinking>と<reflection>でストーリーに一貫性を持たせるようにすることで、整合性のあるストーリーを作成できるようになるかもしれません。
さらに、ストーリーができたらStable Video 4Dなどの動画生成AIを使って映像化することで、低コストでハイクオリティな映像が作れるようになるかもしれませんね。
なお、世界に激震を与えたOpenAIの動画生成AIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

最後に
いかがだったでしょうか?
GPT-3.5 Turboの最新アップデートで、より高速かつ低コストでのAI活用が可能になりました。自社での導入・活用を検討する際に、最適なモデル選定や活用方法について、一緒に考えてみませんか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


