
【SmolLM3】小規模言語モデルなのに大規模言語モデルに匹敵?性能や使い方を徹底解説
- Hugging Face発の小規模言語モデル
- パラメータ数はわずか3Bと小規模ながら、大規模言語モデルに匹敵する性能
- Apache License 2.0で公開された完全オープンソースのモデル
2025年7月8日、Hugging Face社が、新たな小型言語モデル「SmolLM3」を公開しました。

従来、数百億から数兆パラメータ規模の巨大なAIモデルは高い性能を誇る一方で、その動作には莫大な計算資源が必要でした。しかし、それとは対照的に、数億~数十億パラメータ程度で個人のPCでも扱えるモデルは小規模言語モデル(Small Language Model, SLM)と呼ばれ、近年その需要が高まっています。
Hugging FaceはこのSLM分野で技術的限界に挑戦し、最新作のSmolLM3はわずか3B(30億)という小規模なパラメータ数でありながら、場合によっては大規模モデルさえ凌駕する性能を発揮します。
本記事では、SmolLM3の概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
SmolLM3 概要
SmolLM3は、テキスト生成に特化したDecoderオンリーのTransformer型言語モデルで、パラメータ数は3B(30億)です。
このモデルは、6言語(英語・フランス語・スペイン語・ドイツ語・イタリア語・ポルトガル語)に対応し、最大128,000トークンもの長大な文脈を扱うことができます。
128,000トークンは英文で約9万6000語(300~400ページの本に相当)に相当し、長文の要約や長い対話履歴の保持といった用途において威力を発揮します。
SmolLM3は少ないパラメータ数でありながら、高度な推論能力と汎用的な知識を備えており、推論モードを切り替えるユニークな機能を持っている点も1つの特徴です。システムメッセージに特殊なフラグを与えることで、「モデルが理由を説明しながら考えるモード(/think)」と「すぐに結論だけ答えるモード(/no_think)」を切り替えることができます。
このデュアルモードによって、必要に応じて回答の詳しい説明や根拠を引き出すことが可能となっています。さらに、SmolLM3は完全オープンソースとして公開されており、学習に使用したデータやレシピも含め順次公開予定とされています。コミュニティはこのモデルを自由に利用・改良できるため、小型モデルの新たな可能性を追求する起点として大きな注目を集めています。


SmolLM3 性能
SmolLM3の性能はベンチマークテストにおいて、同程度の規模を持つ他社の3Bモデルを上回る結果を示しています。
Hugging Face社が公開した12種類の一般的なベンチマーク(知識・推論・数学・コーディング能力の評価指標)によると、SmolLM3はAlibaba社のQwen2.5 (3B)やMeta社のLlama 3.2 (3B)といった同じ3B規模のモデルを凌駕し、さらに規模が大きい「Qwen3 (4B)」やGoogle社の「Gemma 3 (4B Base)」と互角のパフォーマンスを発揮しています。
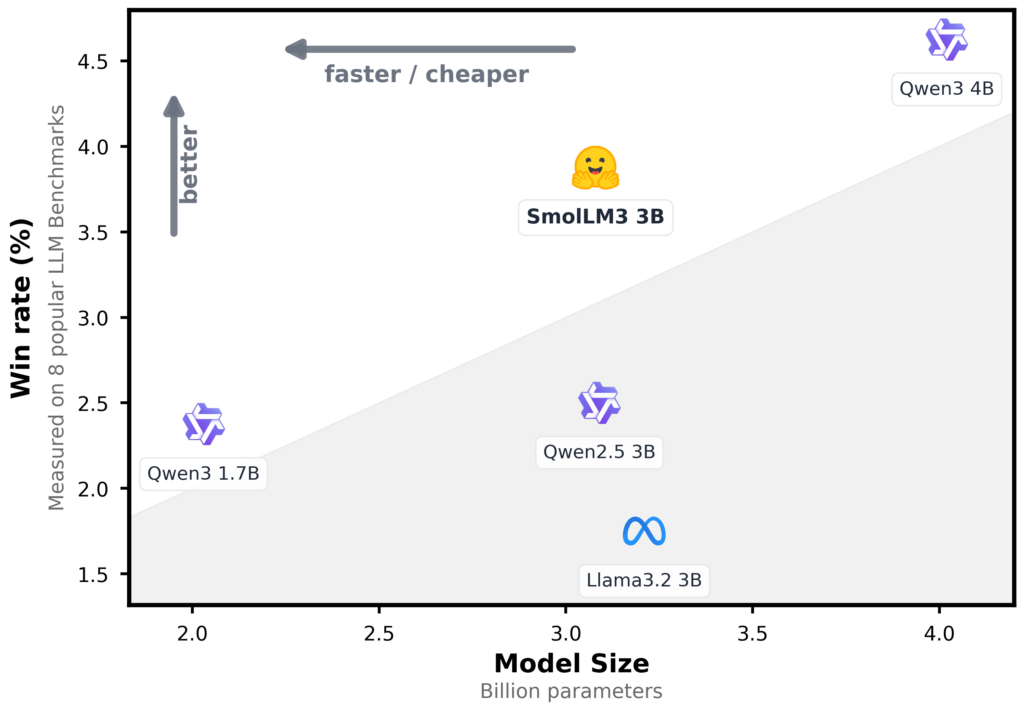
小型モデルでありながら高い性能を実現している背景には、大規模な学習プロセスがあります。SmolLM3は、段階的カリキュラム学習(三段階学習)を採用しており、最初の段階で一般常識や自然言語の基礎を学習し、次の段階でプログラミングや論理的推論能力を強化し、最後の段階で数学やコードに重点を置いて応用力を磨くというアプローチでトレーニングされています。
さらに、11.2兆トークンにも及ぶデータを学習しており、一般的な3Bモデルの50~1000億トークンや、従来のGPT-3(約3000億トークン)を遥かに上回るスケールで訓練されています。この圧倒的な学習データ量と段階的なチューニング戦略、そして中間段階で推論プロセス自体を学習させたことにより、少ないパラメータでも高い性能を発揮できているようです。
実際、数学競技の難問やプログラミング課題など高度な推論を要するテストでもSmolLM3は高い正答率を示し、3Bクラスのモデルとしては群を抜く成績を収めています。
なお、大規模言語モデルについて詳しく知りたい方は以下の記事も参考にしてみてください。
とは?仕組みや代表例、サービス、できることを徹底解説.jpg)
SmolLM3 ライセンス
SmolLM3はApache License 2.0で公開されている完全オープンソースのモデルです。Apache License 2.0は世界中で広く利用されている寛容なOSSライセンスで、商用利用を含めソフトウェアの自由な利用・改変・再配布を認め、さらに利用者に対する特許許諾も含まれていることが特徴です。以下に主要な利用条件をまとめます。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
Apache License 2.0には特許の利用に関する明確な条項が含まれており、モデル提供者の保有する特許について利用者に許諾を与える仕組みになっています。このような特許面の保護もあるため、企業利用においても安心感が高いと言えると思います。
総じて、SmolLM3はライセンス面で非常に扱いやすく、オープンソースコミュニティと商用利用の双方にフレンドリーなモデルとなっています。
SmolLM3 料金プラン
SmolLM3はオープンソースで提供されているため、モデルの利用自体は無料です。
利用にあたってAPIキーを購入したりライセンス料を支払ったりする必要はなく、誰でもHugging Faceのモデルページから重みデータをダウンロードして使い始めることができます。
これは、OpenAIのGPT-4などの従量課金制で利用料が発生するクローズドな大規模モデルと比べても、大きなメリットですね。もちろん、実際にモデルを動かすにはそれなりの計算リソースが必要ですが、SmolLM3は小型モデルゆえ1台のGPU環境でも問題なく動作可能です。
SmolLM3 使い方
それでは、SmolLM3を実際に使う方法について、ステップ・バイ・ステップで説明します。
まず環境の準備ですが、PythonとTransformers(v4.53.0以降)ライブラリが必要です。また、本モデルの重みはSafeTensors形式(約5GBと1.2GBのファイルに分割)で提供されているため、SafeTensorsライブラリも導入します。
今回はGoogleColabで実装していきますので、以下コマンドを実行します。
!pip install -U transformers safetensors
上記コマンドでTransformersライブラリがアップグレードされ、SafeTensorsもインストールされます。
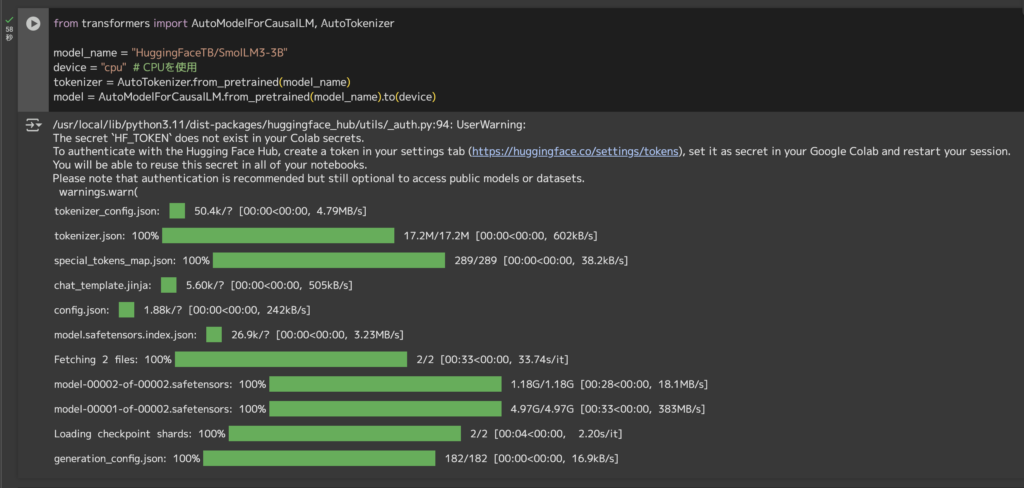
ライブラリの準備ができたら、モデルをロードします。以下のコードを実行すると、トークナイザとモデル本体がHugging Face Hubから自動的にダウンロードされます。モデルデータが約6GBありますので、ダウンロードと読み込みに少し時間がかかるかもしれません。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "HuggingFaceTB/SmolLM3-3B"
device = "cpu" # CPUを使用
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)上記コードでmodel_nameとして指定したモデル(HuggingFaceTB/SmolLM3-3B)がロードされ、CPUメモリ上に配置されます。
推論モード実行例(/thinkモード)
SmolLM3は、Extended Thinking Mode(拡張思考モード)と呼ばれる推論付きの応答モードを持っており、デフォルトで有効になっています。このモードでは、モデルが質問に答える際に途中の考え過程(チェーン・オブ・ソート)を示してくれるため、論理的な問題解決の様子を確認できます。
実際に簡単な数学問題を例に、モデルに推論付きで解答させてみましょう。
コードはこちら
# 数学問題を含むユーザーメッセージを用意
messages = [
{"role": "user", "content": "2 * 7 + 6は?"}
]
# チャットテンプレートにメッセージを適用してモデル入力テキストを生成
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
# モデルに推論させ、応答を生成(最大新規生成トークン数を制限)
output_ids = model.generate(**inputs, max_new_tokens=512)[0]
# 元の入力部分を除去し、新規生成部分のみデコード
output_ids = output_ids[len(inputs.input_ids[0]):]
print(tokenizer.decode(output_ids, skip_special_tokens=True))結果はこちら
<think>
Okay, let's see. The problem is 2 times 7 plus 6. Hmm, I need to remember the order of operations here. I think it's PEMDAS—Parentheses, Exponents, Multiplication and Division (from left to right), Addition and Subtraction (from left to right). So in this case, there are no parentheses or exponents, so I should do the multiplication and division first, then the addition.
Starting with the multiplication part: 2 times 7. Let me calculate that. 2 multiplied by 7 is 14. Okay, so that gives me 14. Then I need to add 6 to that result. So 14 plus 6. Let me add those numbers together. 14 plus 6 is 20. Wait, is that right? Let me check again. 2 times 7 is definitely 14. Then 14 plus 6 is 20. Yeah, that seems correct. I don't think I made any mistakes here. The order of operations was followed correctly. Multiplication comes before addition, so first do the multiplication, then the addition. Yep, that's right. So the answer should be 20.
</think>
The problem is calculated using the order of operations (PEMDAS):
1. **Multiplication**: \(2 \times 7 = 14\).
2. **Addition**: \(14 + 6 = 20\).
\[
\boxed{20}
\]
(和訳)
<think>
さて、見てみよう。問題は2の7乗+6だ。うーん、ここで演算の順序を覚えておく必要があるな。確かPEMDAS-括弧、指数、掛け算と割り算(左から右へ)、足し算と引き算(左から右へ)だったと思う。だからこの場合、括弧も指数もないから、まず掛け算と割り算をやって、それから足し算をやればいいんだ。
まずは掛け算から。計算してみよう。2に7をかけると14。よし、これで14が出た。その結果に6を足す必要がある。つまり、14+6。この数字を足してみよう。14と6を足すと20になる。待って、これで合ってる?もう一度確認してみよう。2の7乗は間違いなく14だ。じゃあ、14+6は20だ。うん、正しいようだ。ここで間違えたとは思わない。演算の順序は正しく守られている。掛け算は足し算の前に来るから、まず掛け算をしてから足し算をする。そう、その通り。だから答えは20になるはずだ。
</think>
この問題は演算順序(PEMDAS)を使って計算する:
1. **掛け算: \(2×7=14)。
2. **足し算: \(14 + 6 = 20\).
\(14+6=20)です。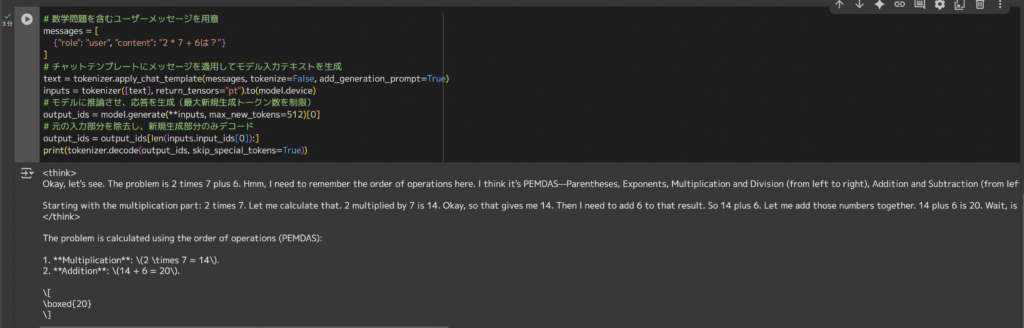
モデルが考えた手順がthink部分で順を追って表示され、最終的な答えである20が示されています。
SmolLM3はこのように**推論モード(/think)**によって複雑な問題でも段階的に解答を導き出すことができます。チェーン・オブ・ソートを確認できるのは、小規模モデルでありながら高度な推論能力を持つSmolLM3の強みと言えるでしょう。
自然言語対話の実行例(/no_thinkモード)
次に、推論モードをオフにした場合のシンプルな対話生成を試してみましょう。
システムメッセージに/no_thinkフラグを指定すると、モデルは思考プロセスを省略し直接回答を生成します。以下のコードでは、創造的な依頼に対してモデルがどのような応答をするか確認してみます。
コードはこちら
# システムメッセージで推論モード無効化し、ユーザーからの依頼を用意
messages = [
{"role": "system", "content": "/no_think"},
{"role": "user", "content": "2 * 7 + 6は?"}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
output_ids = model.generate(**inputs, max_new_tokens=100)[0]
output_ids = output_ids[len(inputs.input_ids[0]):]
print(tokenizer.decode(output_ids, skip_special_tokens=True))結果はこちら
2 * 7 + 6 は、2乗して7を足し合わせると 14 + 6 = 20 になります。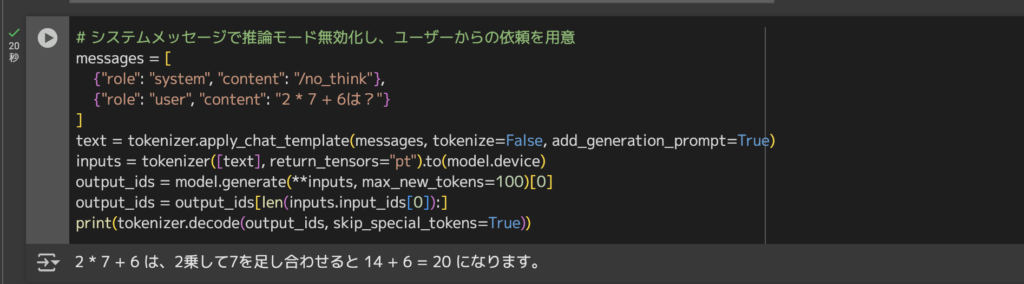
上記を実行すると、モデルは/no_think指定により推論過程を挟まず、直接ユーザーの指示に対する回答を生成してくれます。
先ほどのthinkモードでは結果が返ってくるまで5分以上かかっていましたが、no_thinkモードでは数十秒で結果が返ってきました。
大規模言語モデルのdeep research機能などと同様に、用途に応じて使い分けをするのが良さそうですね。
今回は計算タスクを試しましたが、SmolLM3は計算だけでなく様々なタスクに利用できます。
例えば、与えられた英語テキストを要約したり、簡単なコードを書いたり、知識に基づく質問に答えたりといったことも可能です。
複数の言語に対応していますので(日本語は公式のサポート言語に含まれていませんが、基本的な質問であれば上記タスクのように反応することもあるようです)、英語以外の文章生成や翻訳補助などにも活用できると思います。ぜひご自身のユースケースで試してみてください。
なお、Deep Researchについて詳しく知りたい方は以下の記事も参考にしてみてください。

まとめ
SmolLM3は、小型でありながら高性能な次世代の言語モデルです。わずか3Bという軽量さで大規模モデル並みの能力を発揮するということで、ローカル環境で高度なAIを活用したい開発者にとっても朗報だと思います。
多言語対応や長文コンテキスト処理能力、さらには思考プロセスをオンデマンドで開示できるデュアルモード機能は、これまで大規模モデルに頼っていたユースケースを小規模モデルで代替する道を拓いてくれています。
しかも完全オープンソースであることから、コミュニティによる独自の改良や他プロジェクトへの統合も促進されることが予想されます。
巨大なモデルだけがAIの未来ではなく、こうしたスモールでスマートなモデルが今後も次々と登場し、私たちの開発現場を支えてくれることに期待したいですね。

最後に
いかがだったでしょうか?
生成AIを事業にどう活かせるか、具体的な活用方法や効果的な導入事例を元に専門家が最適なソリューションをご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


