
Stable Diffusion 3.5徹底ガイド!使い方・料金・ライセンス・FLUX比較

- 3モデルとバリエーション豊富
- 画像生成AIが初めての人でも手軽に使えるWebサービスあり
- カスタマイズ性が豊富
2024年10月22日にStability AIから新たなモデル、Stable Diffusion 3.5がリリースされました!
Stable Diffusion 3.5はなんと80億ものパラメータを持つモデルであり、これまでのStable Diffusionモデルの中で最も強力であると発表されています!
また、2024年10月22日に発表されたモデルはStable Diffusion 3.5 LargeとStable Diffusion 3.5 Large Turboで、Stable Diffusion 3.5 Mediumは2024年10月29日にリリースされています。
本記事ではStable Diffusion 3.5 LargeがこれまでのStable Diffusionモデルと何が変わったのか、Google Colabで実装するためにはどうすればいいのかについて解説!
本記事を最後まで読むことで、高品質な画像を生成できるようになります。ぜひ最後までお読みください!
\生成AIを活用して業務プロセスを自動化/
Stable Diffusion 3.5の概要
Stable Diffusion 3.5は、Stability AIが開発した最新の画像生成AIモデルシリーズです。
Stable Diffusion 3.5には、Stable Diffusion 3.5 Large、Stable Diffusion 3.5 Large Turbo、Stable Diffusion 3.5 Mediumの3つのモデルが含まれます。(※1)
- Stable Diffusion 3.5 Large
- 80億のパラメータ、優れた品質、迅速な適合性を持つ。
- Stable Diffusionファミリーの中で最も強力。
- 1メガピクセル解像度で、プロフェッショナル用途に最適。
- Stable Diffusion 3.5 Large Turbo
- Stable Diffusion 3.5 Large の小型モデル。
- わずか4ステップで高品質な画像を生成し、優れた即時適合性を実現。
- Stable Diffusion 3.5 Largeよりも高速。
- Stable Diffusion 3.5 Medium
- 26億のパラメータ。
- 改良されたMMDiT-Xアーキテクチャとトレーニング方法により、カスタマイズのしやすさと画質を両立。
- 一般的な消費者向けハードウェアで「箱から出してすぐに使える」ように設計。
- 0.25~2メガピクセルの解像度の画像が生成可能。
- 0.25~2メガピクセルの解像度の画像が生成可能。
※その他、Stable Diffusion 3.5 Large / Mediumには、GGUF(GPT-Generated Unified Format)形式で保存された量子化モデルも登場しています。こちらは、ComfyUI-GGUFカスタムノードで使える省メモリ性能に優れたモデルです。ライセンス条件・制限については本家のものがそのまま適用されます。
→Stable Diffusion 3.5 LargeのGGUF版はこちら
→Stable Diffusion 3.5 MediumのGGUF版はこちら
なお、Stable Diffusionについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusion 3.5の特徴
ここからは、Stable Diffusion 3.5の特徴4点をご紹介します。まずは、Stable Diffusionシリーズの醍醐味「カスタマイズ性」からみていきましょう!
高いカスタマイズ性
Stable Diffusion 3.5は高いカスタマイズ性と使いやすさを兼ね備えています。特定のニーズに応じてモデルを簡単にファインチューニングできるだけでなく、カスタマイズされたワークフローに基づくアプリケーションを構築することが可能です。

具体的には、一般的な消費者向けハードウェアでも高負荷をかけずに実行できるように改善がなされています。
出力・スタイルのバリエーション
ほかにも、Stable Diffusion 3.5は、多様な出力やスタイルをサポートしており、特定の人物に限らず、世界中のさまざまな肌の色や特徴を持つキャラクターを作成できるのが特徴です。

さらに、3D画像 / 写真 / 絵画 / 線画…etc.さまざまなスタイルで、美しい画像が生成できます。
忠実性・品質の改善
Stable Diffusion 3.5 Largeは、入力されたプロンプトを忠実に再現し、そのほかの画像生成AIに比べ、画像の品質でもはるかに大きなモデルにも匹敵する性能を発揮します。
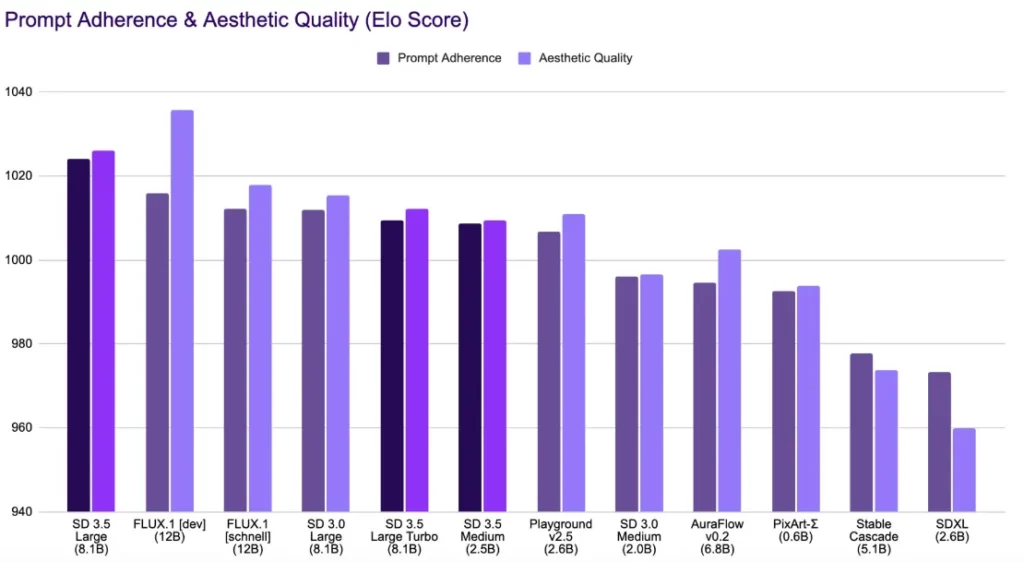
Large Turboのパラメータ数は膨大ですが、高速推論が可能で、画像の品質やプロンプトの再現性もかなり優れているとのことです。
一方、Stable Diffusion 3.5 Mediumは他の中型モデルを上回る性能を誇り、プロンプトの再現性と画像の品質のバランスが非常に優れているそうです。
Stable Diffusion 3.5の仕組み
Stable Diffusion 3.5の開発においては、カスタマイズ性が最優先事項として掲げられ、これはあらゆるクリエイターに広くアクセス可能で最先端のツールを提供するというStability AIのコミットメントを体現。
ユーザーがファインチューニング、LoRA、最適化、アプリケーション開発、アートワーク作成など、パイプライン全体にわたる作業や成果物の配布・収益化を容易に行えるように設計されています。
具体的には、Query-Key Normalizationをトランスフォーマーブロックに統合することで、モデルのトレーニングプロセスを改善し、ファインチューニングや開発の手間を大幅に軽減しているということです。
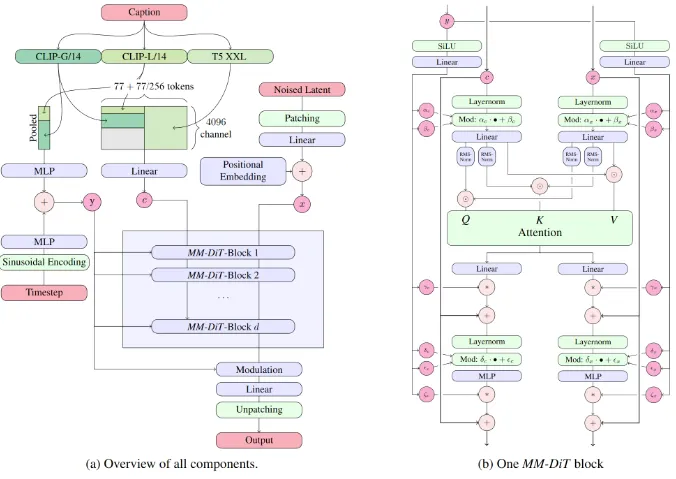
ただし、このカスタマイズ性の向上にはトレードオフが伴い、異なるシードを使用した同じプロンプトからの出力に、より大きなばらつきが生じる可能性もあります。

このばらつきは、ベースモデルにおける広範な知識と多様なスタイルを維持するためには有用です。しかし特定性の低いプロンプトでは、出力が安定せず、一貫性が保てなくなる可能性があります。
そこで、Stable Diffusion 3.5 Mediumでは、品質、一貫性、およびマルチ解像度生成能力を向上させるために、モデル構造と学習方法に工夫が施されました。
その結果、Stable Diffusion 3.5は、テキストプロンプトへの準拠と画像の品質において最高水準のパフォーマンスを維持しながら、カスタマイズ可能で使いやすい画像生成モデルとなっています。
Stable Diffusion 3.5のライセンス
Stable Diffusion 3.5のライセンスはStability AI Community Licenseです。
Stability AI Community Licenseは年間収入が100万ドル未満の個人や組織は研究用、非商用利用、商用利用が可能です。生成物の権利はユーザーに帰属すると明記されています。
もし年間収入が100万ドルを超える場合、商用利用にはStability AIからエンタープライズライセンスの取得が必要なので注意してください。
また、Stability AIのライセンスは3つあります。
- 非商用ライセンス:個人開発者や研究者向けライセンスで無料
- コミュニティライセンス:年間収入が100万ドル未満の個人や組織向けで無料
- エンタープライズライセンス:年間収入が100万ドルを超える企業向けでカスタム価格
用途に応じて、コミュニティライセンス/エンタープライズを選ぶようにしましょう。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | 不明(明記なし) |
| 私的使用 | ⭕️ |
\画像生成AIを商用利用する際はライセンスを確認しましょう/

Stable Diffusion 3.5の料金
Stable Diffusion 3.5自体は無料で利用できます。
ただし、Stable Diffusion 3.5を使用するそれぞれのプラットフォームでは料金が発生する場合があります。(※2、3)
- Replicate:Large Turbo 0.04ドル/枚、Large 0.065ドル/枚
- DeepInfra:Mediumで0.03ドル/枚、 Largeで0.06/枚
- Models Lab:月額21ドルor年額202ドル〜
- ComfyUI:無料
- Hugging Face:Inference Endpoints/Spacesは分単位のハードウェア課金。無料枠もあるが、GPUを使うと実行時間に応じて課金される仕組み。
- Stability API:1クレジット=0.01ドル、Medium=3.5クレジット、Large Turbo=4クレジット、Large=6.5クレジット目安
ReplicateもDeepImfraもプロンプトを入力するだけで画像生成ができるので、自分の手で環境構築しなくていい分、料金が発生します。
また、Stability AIのAPIを使って画像生成する場合にもAPI料がかかります。
画像一枚の生成にかかるクレジットは以下の画像の通りです。API料は前払い制で最低10ドルからです。10ドルの支払いで1000クレジットもらえます。

なお、たった0.5秒で高精度な3Dモデルを生成できるStable Fast 3Dについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusion 3.5の使い方
Stable Diffusion 3.5は現在以下の4つで利用可能です。特にHugging Faceではモデルのウェイトをセルフホスティング用に利用可能。
- Stability AI API
- Replicate
- DeepInfra
- ComfyUI
- Hugging Face
今回はStability AI API に掲載されているコードを元に、Google Colabで実装します。
また、Stable Diffusion 3.5を使うにはStability AIのAPIキーが必要です
Google ColabでStable Diffusion 3.5を実装
■Pythonのバージョン
Python 3.8以上
■使用ディスク量
32.3GB
■システムRAMの使用量
0GB
■GPU RAMの使用量
25.6GB
Stability AIのAPIを使って実装する場合、Stability AIのホームページにGoogle Colabのページがリンクされています
基本的にはこれに則っていけばOKです。
必要ライブラリのインストールはこちら
#@title Install requirements
from io import BytesIO
import IPython
import json
import os
from PIL import Image
import requests
import time
from google.colab import outputAPIキーの登録はこちら
import getpass
# @markdown To get your API key visit https://platform.stability.ai/account/keys
STABILITY_KEY = getpass.getpass('Enter your API Key')ここでAPIキーを入力する入力欄が表示されるので、そちらに自身のAPIキーを入力しましょう。
関数の定義はこちら
#@title Define functions
def send_generation_request(
host,
params,
):
headers = {
"Accept": "image/*",
"Authorization": f"Bearer {STABILITY_KEY}"
}
# Encode parameters
files = {}
image = params.pop("image", None)
mask = params.pop("mask", None)
if image is not None and image != '':
files["image"] = open(image, 'rb')
if mask is not None and mask != '':
files["mask"] = open(mask, 'rb')
if len(files)==0:
files["none"] = ''
# Send request
print(f"Sending REST request to {host}...")
response = requests.post(
host,
headers=headers,
files=files,
data=params
)
if not response.ok:
raise Exception(f"HTTP {response.status_code}: {response.text}")
return response画像の生成コードはこちら
#@title SD3.5 Large
prompt = "cinematic film still, action photo of a cat riding a skateboard through the leaves in autumn. the cat has a mouse friend resting on their head" #@param {type:"string"}
negative_prompt = "" #@param {type:"string"}
aspect_ratio = "1:1" #@param ["21:9", "16:9", "3:2", "5:4", "1:1", "4:5", "2:3", "9:16", "9:21"]
seed = 0 #@param {type:"integer"}
output_format = "jpeg" #@param ["jpeg", "png"]
host = f"https://api.stability.ai/v2beta/stable-image/generate/sd3"
params = {
"prompt" : prompt,
"negative_prompt" : negative_prompt,
"aspect_ratio" : aspect_ratio,
"seed" : seed,
"output_format" : output_format,
"model" : "sd3.5-large",
"mode" : "text-to-image"
}
response = send_generation_request(
host,
params
)
# Decode response
output_image = response.content
finish_reason = response.headers.get("finish-reason")
seed = response.headers.get("seed")
# Check for NSFW classification
if finish_reason == 'CONTENT_FILTERED':
raise Warning("Generation failed NSFW classifier")
# Save and display result
generated = f"generated_{seed}.{output_format}"
with open(generated, "wb") as f:
f.write(output_image)
print(f"Saved image {generated}")
output.no_vertical_scroll()
print("Result image:")
IPython.display.display(Image.open(generated))生成された画像は以下です。

主なパラメータ
cfg_scale:どの程度プロンプトに厳密に従うかを指定する(デフォルトは7)
samples:生成する画像の数(デフォルトは1)
steps:Diffusionステップの数(デフォルトは30)
sampler:生成に使用するサンプラー
seed:ランダムノイズシード(デフォルトは0でランダム)
Replicateを用いる方法
ReplicateでStable Diffusion 3.5を使用する場合、まずはアカウント登録が必要です。ReplicateのGitHubのアカウントでログインできるので、GitHubのアカウントを持っている方は、そちらでログインするのが手軽です。
ログイン後、設定にアクセスして任意の料金を支払います。Replicateは従量課金制ではなく、前払い制なので気をつけるようにしましょう。
Stripeを経由して、支払いを行うことになります。
支払いを終えたらStable Diffusion 3.5のページにいき、プロンプトを入力して生成すればOKです。
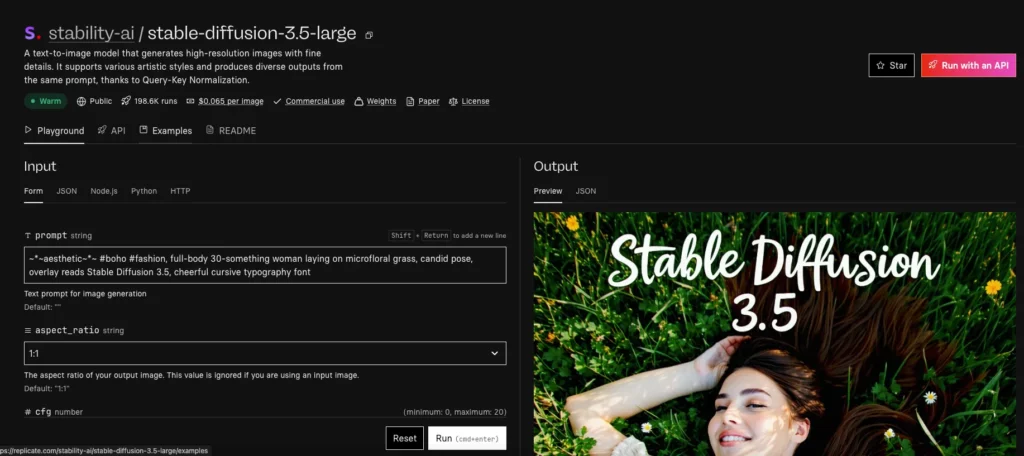
プロンプトは「A beautiful woman with long flowing hair, wearing a flower crown, soft lighting, realistic portrait」としました。
和訳:長い髪をなびかせた美しい女性、花の冠をかぶっている、ソフトな照明、リアルなポートレート
生成された画像がこちらです。

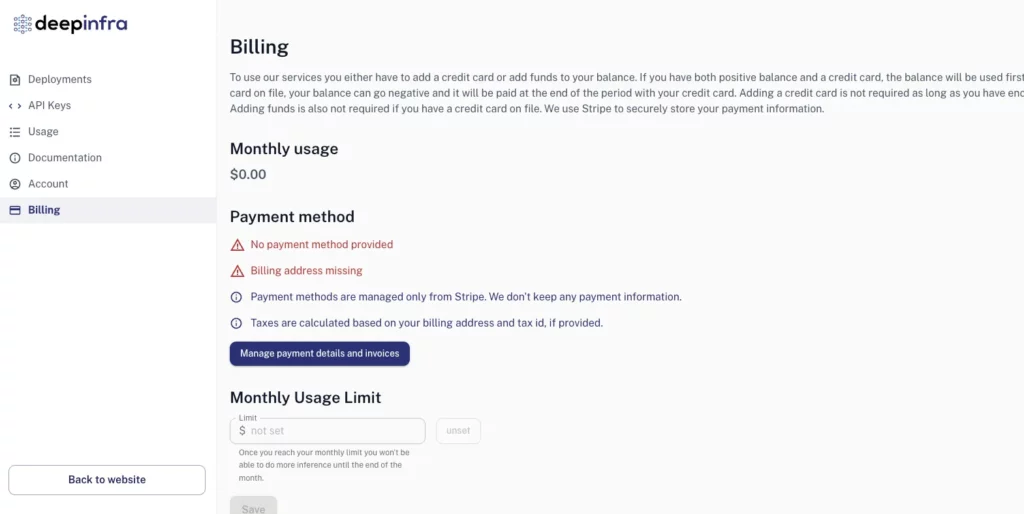
DeepInfraを用いる方法
DeepInfraもReplicateに近いサービスです。Stripe経由で任意の料金を支払うことで利用することができます。ログイン後、「Dashboard」→「Billing」で支払いを行えます。
ReplicateもDeepInfraもWeb上で画像を生成することもできますし、APIを使ってローカル環境で画像生成することも可能です。
ReplicateもDeepInfraもAPIタブがあるので、そこからプログラミング言語を選択後、コピペすればOKです。
ComfyUIを用いる方法
ComfyUIを使うにはいくつか準備が必要です。
まずはStability Matrixをダウンロードします。Stability Matrixを使うことでComfyUIを簡単にインストールできます。
このページから最新バージョンをダウンロードしましょう。
ダウンロード後、Stability Matrixのインストールを進めていきます。インストールが終了するとStability Matrixが起動して、インストールするパッケージが表示されるので。Stable Diffusionを選択します。
Stable Diffusionのインストールが完了すると下記画像のように「Launch」と表示されますので、ここをクリック。
launchが終わるとWebUIが表示されます。
これでStable Diffusion自体のインストールは終了です。次にComfyUIをインストールしていきます。
パッケージのタブを開くと「パッケージの追加」があるので、そちらをクリックします。
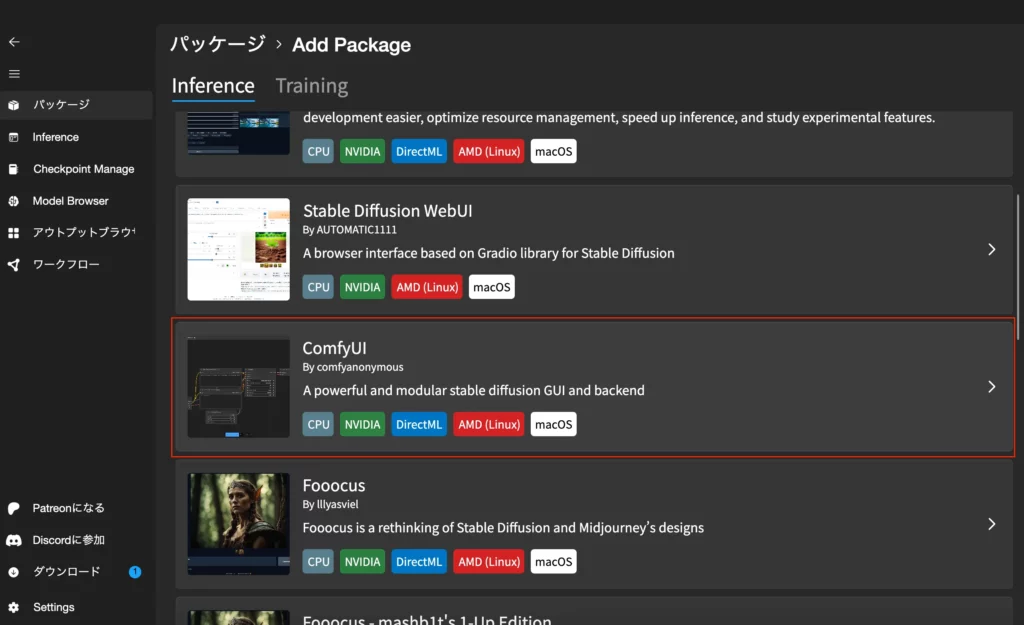
ComfyUIが出てくるので、そちらをクリック。
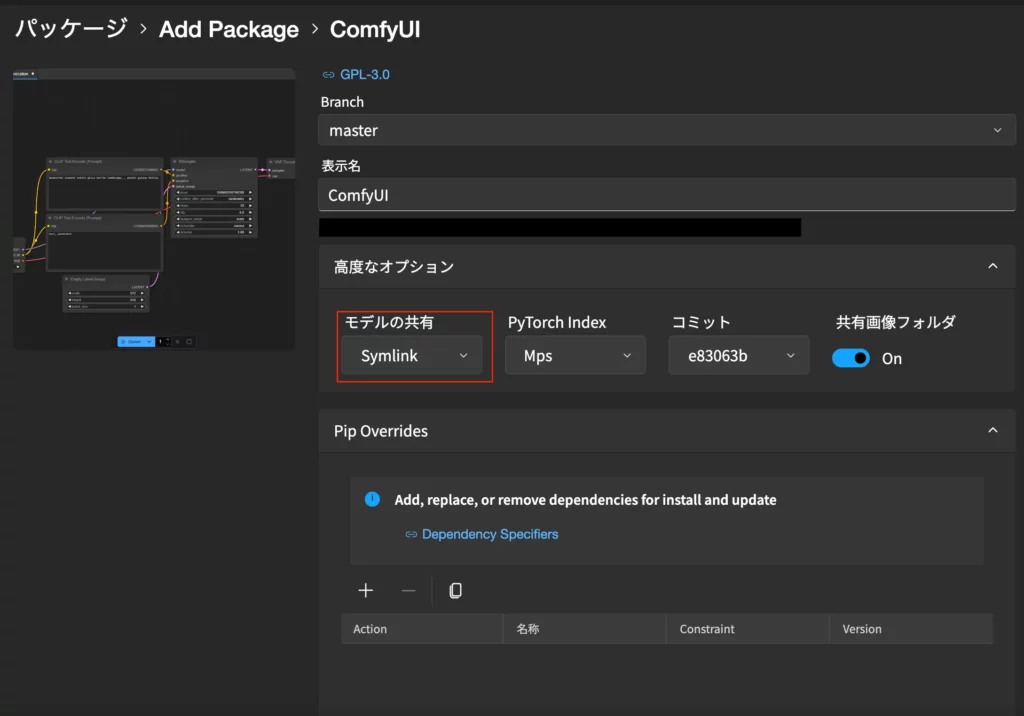
ComfyUIの「高度なオプション」からモデルの共有を選び「Symlink」を選択。その後インストールされます。
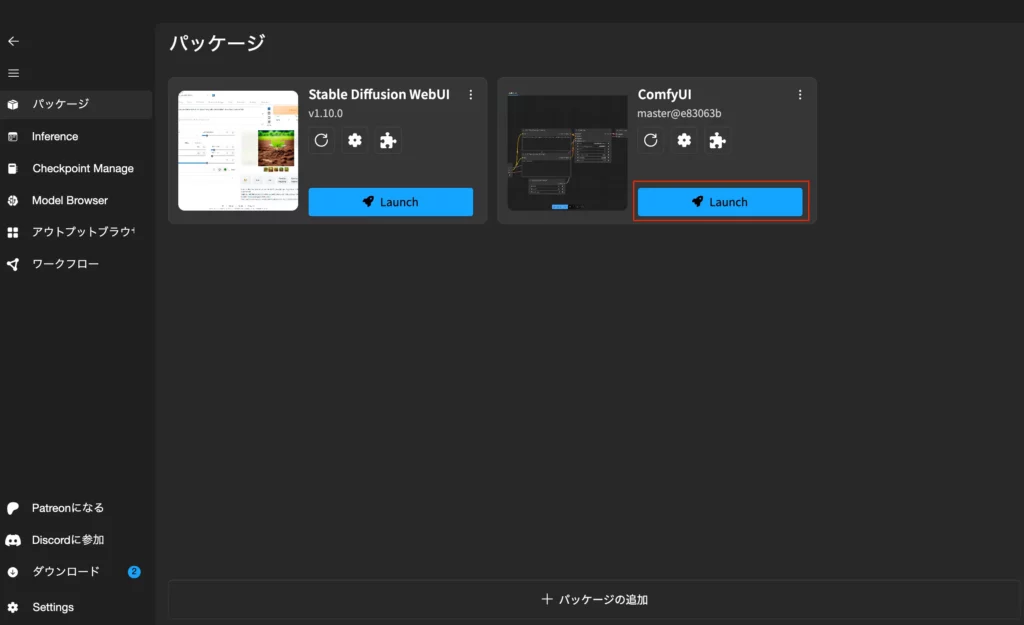
インストールが完了したら「Launch」をクリックすればOKです。
次に必要なモデルなどをダウンロードします。
Hugging Faceのページにいき「sd3.5_medium.safetensors」「clip_g.safetensors」「clip_l.safetensors」「t5xxl_fp8_e4m3fn.safetensors」の4つをダウンロードしましょう。
それぞれダウンロード先のリンクを埋め込んでいるので、ダウンロードするものをクリックしてもらえれば、ダウンロードページに飛ぶことができます。
ダウンロードが完了したら「clip_g.safetensors」「clip_l.safetensors」「t5xxl_fp8_e4m3fn.safetensors」の3つはCLIPフォルダに、「sd3.5_medium.safetensors」はCheckpointsフォルダに格納します。
ComfyUIではワークフローというものを使用します。1から自分で作ることもできますが、それは結構大変です。
なので「sd3.5-t2i-fp8-scaled-workflow.json」もしくは「SD3.5M_example_workflow.json」どちらかをダウンロードして、ダウンロードしたものをComfyUIにドラッグ&ドロップします。
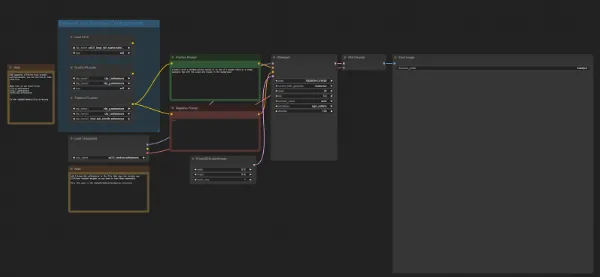
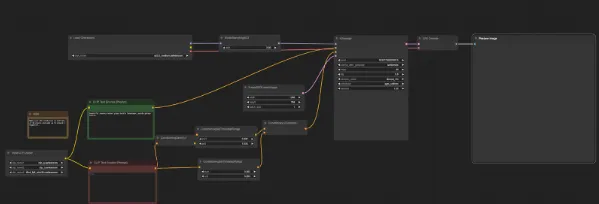
そうするとワークフローが表示されます。どちらも同じですが、「TripleCLIPLoader」と「Load Checkpoint」は画像と同じ名称がくるように設定をします。
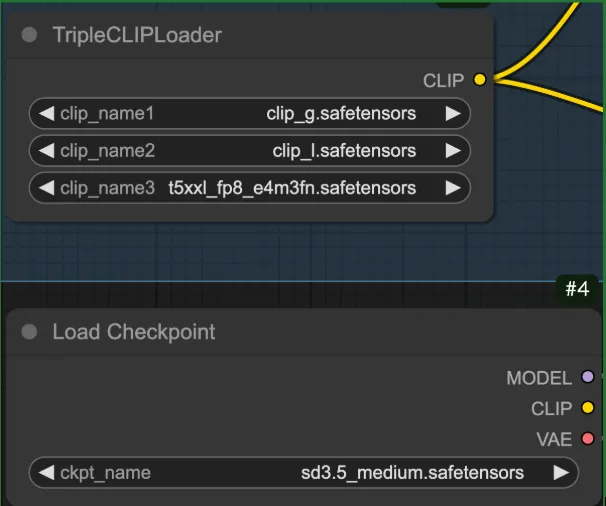
先ほどダウンロードしたものが適切なフォルダに格納されていれば選択できるようになっているはずです。
後はそれぞれNegative PromptとPositive Promptにプロンプトを入力して、「Queue」をクリックすれば画像生成がされます。
生成された画像がこちら。M2 Macbook Proで実行しましたが、かなり時間かかりました。

これでComfyUIを使ったStable Diffusionの使い方は以上です。プロンプトを変えてみたり、「KSampler」をいじってみたり、色々試してみてください。
Hugging Faceを用いる方法
Hugging FaceにはSpaceというものが用意されており、ここからStable Diffusion 3.5 Largeを使うことができます。
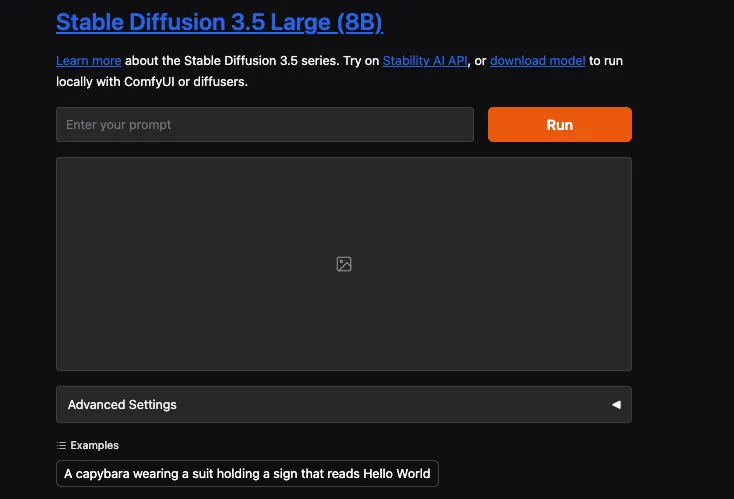
このページでプロンプトを入力すれば、画像生成可能です。実際に生成した画像がこちら。

また、「Advanced Settings」から画像サイズやSeed値などを変更できます。
なお、ComfyUIについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

Stable Diffusion 3.5の活用シーン
Stable Diffusion 3.5はこれまでの画像生成AI同様に、以下のような使い方ができます。
- Web記事の挿入画像
- バナー広告
- ゲーム制作
- その他コンテンツ制作
…and more!
著作権・肖像権の侵害リスクには注意が必要ですが、うまく活用するとコンテンツ制作の効率化が図れるかもしれません。


Stable Diffusion 3.5をSD3とFLUXと比較してみた
Stable Diffusion 3.5は過去のモデルよりも遥かにハイパフォーマンスであると発表しています。
また、FLUXは1.1が登場したことにより、従来よりも高品質で細かなディテールを再現できるようになっています。そこで、Stable Diffusion 3.5とSD3、FLUXそれぞれ同じプロンプトを入力して、どれが最も美しい画像を生成できるかを比較検証してみたいと思います!
入力するプロンプトは以下です。プロンプト自体はChatGPT-4oに生成してもらいました。
“A futuristic cityscape at sunset, with flying cars, towering skyscrapers, and detailed reflections on glass windows. The sky is filled with vibrant colors ranging from orange to deep purple, and people in futuristic clothing are walking on the streets.”
こちらのプロンプトでは「高度なディテールと複雑さ」を見れるように。
“A close-up of a medieval knight’s armor, showing intricate engravings, scratches, and reflections of light. The knight is holding a polished sword, and behind him, a castle can be seen in the distance, with a cloudy sky overhead.”
こちらのプロンプトでは「質感とリアリズム」
“A serene beach at sunrise, with calm blue waves gently hitting the shore. The sky is painted with pastel shades of pink, orange, and light purple, and a single palm tree sways in the breeze. The soft light casts gentle shadows on the sand.”
こちらのプロンプトでは「色彩と光の描写」を見れるようにしています。
コードは先ほどと同じなので、プロンプトだけ変更すれば動作します。
検証コードはこちら
#@title SD3.5 Large
prompt = "cinematic film still, action photo of a cat riding a skateboard through the leaves in autumn. the cat has a mouse friend resting on their head" #@param {type:"string"}
negative_prompt = "" #@param {type:"string"}
aspect_ratio = "1:1" #@param ["21:9", "16:9", "3:2", "5:4", "1:1", "4:5", "2:3", "9:16", "9:21"]
seed = 0 #@param {type:"integer"}
output_format = "jpeg" #@param ["jpeg", "png"]
host = f"https://api.stability.ai/v2beta/stable-image/generate/sd3"
params = {
"prompt" : prompt,
"negative_prompt" : negative_prompt,
"aspect_ratio" : aspect_ratio,
"seed" : seed,
"output_format" : output_format,
"model" : "sd3.5-large",
"mode" : "text-to-image"
}
response = send_generation_request(
host,
params
)
# Decode response
output_image = response.content
finish_reason = response.headers.get("finish-reason")
seed = response.headers.get("seed")
# Check for NSFW classification
if finish_reason == 'CONTENT_FILTERED':
raise Warning("Generation failed NSFW classifier")
# Save and display result
generated = f"generated_{seed}.{output_format}"
with open(generated, "wb") as f:
f.write(output_image)
print(f"Saved image {generated}")
output.no_vertical_scroll()
print("Result image:")
IPython.display.display(Image.open(generated))ちなみにStable Diffusion 3.5のページ下部にはSD3のコードもあるので、そのままプロンプトを入力すればSD3で画像も生成可能です
ちなみにFLUXはReplicateでFLUX1.1 [pro]を使用して生成します!



正直、どれもクオリティ高いな…!って思いましたが、生成された画像を見てすごさを感じたのでやはりStable Diffusion3.5で生成された画像でした。
特に2枚目にある鎧の画像はかなり細かい模様も鮮明に作られており、天候も鎧にマッチしており、非常に精密に作られているな…と感じました。
ただ、ここは個人の嗜好の問題によっても左右されるとは思いますので、生成された画像を見比べてみて、最もクオリティが高いなと思うものを考えてもらえるといいかもしれません。
また、SD3.5とSD3を比較してみると、鮮明さや質感、色彩と光の描写など全体的にSD3.5の方が上かな、という印象を受けます。
ちなみにこちらはアートスタイルをゴッホ風に変えてSD3.5で生成した画像です
2枚目はゴッホっぽいですかね…?



アートスタイルを変更するには、プロンプトでスタイルを指示すればOKです。
今回の場合は、「painted in the style of Van Gogh」というプロンプトを追加しただけです。
それ以外にも、“A futuristic city in cyberpunk style”(サイバーパンク風の未来都市)や”A highly detailed 3D render of a futuristic car”(未来的な車の高精細な3Dレンダリング)などもあるので、色々試してみてください
なお、ラフスケッチからリアルタイムで高画質な画像を生成する方法について詳しく知りたい方は、下記の記事を合わせてご確認ください。

プロンプト設計のコツ
プロンプトを入力する際のコツを紹介します。
重要なのは、誰を/何を(主体)+どんな構図・動き+場所・時間帯+光の4点を1文で決めることです。
例えば:「雨の夜、ネオン街を走る赤いバイクのクローズアップ、濡れた路面に反射、映画的ライティング」のようなイメージです。
次に、質感・レンズ・色味・時代などを少しずつ加えていくと、自分がイメージしているアウトプットに近づいていくと思います。ただし、盛り込みすぎは破綻のもとになるので注意が必要です。
また、ネガティブプロンプトとして、不要要素(文字崩れ、余計な手、ロゴ)を抑え、アスペクト比は用途から逆算するようにしましょう。
Stable Diffusion 3.5に限った話でいうと、検証フローとしては、Turbo低解像→良ければLargeで解像度UPがコスパもよいかと思います。
生成物の権利と注意点
Stable Diffusion 3.5で作った画像の権利は、基本的には“つくった人”に帰属します。
ただし、使える範囲はモデルのライセンス次第。とくにSCL(Stability AI Community License)は収益規模などで商用可否が変わるため、最新版の規約を必ず確認するようにしましょう。
人物の顔や体型が写る場合は肖像権、企業ロゴや有名キャラに似せた表現は商標・著作権のリスクがあります。また、配布時はクレジット表記やNG用途の有無も要チェックです。社内で使う場合は、生成日時・プロンプト・シードを記録して、後からの説明責任に備えておくと安心です。
まとめ
本記事ではStable Diffusion3.5を使って、Google Colabで画像を生成する方法についてお伝えしました!
Stable Diffusion3と比べると、全体的に生成されるクオリティは上がっている印象を受けます。かなり精緻に作られており、質感もリアリティがあります。ぜひ本記事を参考に、Stable Diffusion3.5で画像を生成してみてください!
作られた画像のAI感のなさに驚きます…!

最後に
いかがだったでしょうか?
高品質な画像生成で、コスト削減と生産性向上を実現する最適なソリューションをご提案いたします。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。


