
【Gemma 4】スマートフォンでも動作するGoogleの最強オープンモデルの性能・使い方・活用シーンまでを徹底解説

- Gemma 4はパラメータあたりの知能(intelligence-per-parameter)で過去最高水準を達成したオープンソースモデル
- モデルは全4サイズ展開で、スマートフォンでも動く超軽量なE2B、E4B、ワークステーション向けの26B MoE、そしてフラグシップの31B Dense
- Gemmaシリーズとしては初めてApache 2.0ライセンスを採用
2026年4月3日、Googleはオープンモデルシリーズの最新版となる「Gemma 4」を公開しました!
Gemini 3の研究成果をベースに開発されたモデルで、パラメータあたりの知能(intelligence-per-parameter)で過去最高水準を達成しています。
今回のリリースで一番インパクトが大きいのは、ライセンスがGoogle独自のものからApache 2.0に変わった点でしょう。商用利用のハードルが一気に下がり、企業・個人を問わず誰でも自由に使えるようになっています。
そこで本記事では、Gemma 4の概要からアーキテクチャ、性能、具体的な使い方、業界別・課題別の活用シーンまで、徹底的に解説していきます。ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Gemma 4とは?

Gemma 4は、Google DeepMindが開発・公開したオープンソースの大規模言語モデルファミリーです。Googleの最上位プロプライエタリモデルであるGemini 3の研究技術をベースにしており、テキスト・画像・動画・音声をまとめて扱えるマルチモーダルモデルになっています。
モデルは全4サイズで展開されています。スマートフォンやRaspberry Piでも動く超軽量なE2B(実効2.3Bパラメータ)とE4B(実効4.5Bパラメータ)、ワークステーション向けの26B MoE(総パラメータ25.2B、アクティブパラメータ3.8B)、そしてフラグシップの31B Dense(30.7Bパラメータ)です。
注目したいのは、31Bモデルが、業界標準のArena AIテキストリーダーボードでオープンモデル世界第3位にランクインしている点です。26B MoEモデルも第6位を獲得しており、自前のサーバーで完全にオフライン運用できるオープンモデルでありながら、プロプライエタリモデルに迫る性能を持っています。
Gemma 4の仕組み
Gemma 4のアーキテクチャは、効率性と性能を両立させるために複数の新しい技術を組み合わせた設計になっています。ここからは、主要な構成要素を見ていきましょう。
ハイブリッドアテンション機構
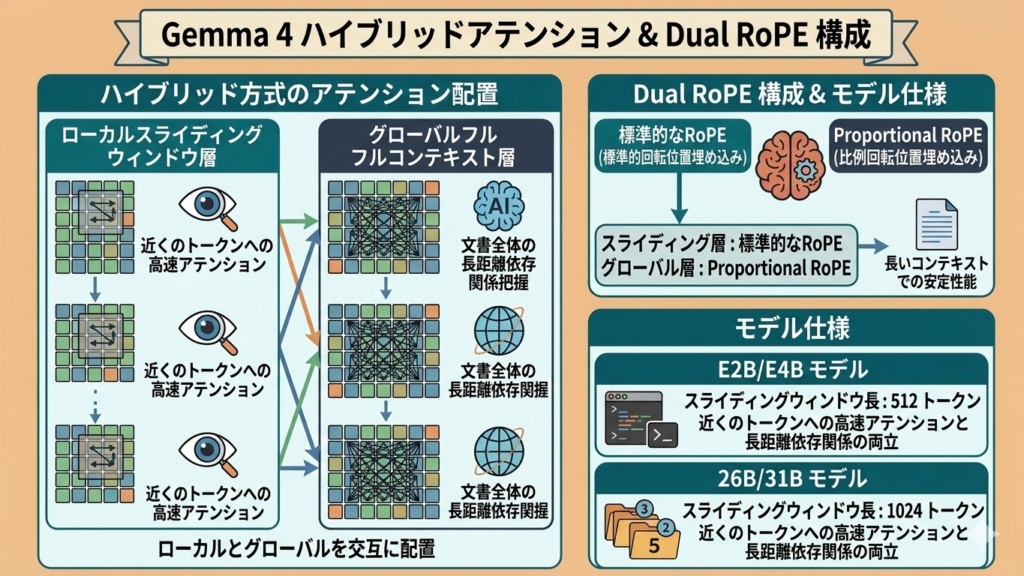
Gemma 4では、ローカルスライディングウィンドウアテンションとグローバルフルコンテキストアテンションを交互に配置するハイブリッド方式が採用されています。
スライディングウィンドウはE2B/E4Bで512トークン、26B/31Bで1024トークンに設定されていて、近くのトークンへの高速なアテンションと、文書全体にわたる長距離の依存関係の把握をうまく両立しています。
Per-Layer Embeddings(PLE)
E2BとE4Bモデルに導入されている独自技術がPer-Layer Embeddings(PLE)です。
各デコーダ層がトークンごとに固有の小さな埋め込みを持つ仕組みで、追加パラメータではなくルックアップテーブルとして動作するため、計算コストを抑えながらモデルの表現力を高めています。
各層でトークンの識別情報とコンテキスト情報を個別に供給できるのがポイントです。
Mixture-of-Experts(MoE)アーキテクチャ

26BモデルではMoE(Mixture-of-Experts)構成を採用しています。
総パラメータ数は25.2Bですが、推論時にアクティブになるのはわずか3.8Bパラメータだけです。128個のエキスパートモジュールと1つの共有エキスパートから、入力に応じて8つが動的に選ばれます。これによって、31Bモデルに迫る性能を圧倒的に少ない計算コストで実現しているわけです。
ビジョンエンコーダ・オーディオエンコーダ
画像処理には、学習済み2D位置埋め込みと多次元RoPEを組み合わせたビジョンエンコーダ(E2B/E4Bで約150Mパラメータ、26B/31Bで約550Mパラメータ)を搭載。元のアスペクト比を保ったまま、70〜1120トークンの範囲で可変解像度に対応しています。
音声処理には、USMスタイルのConformerベースのオーディオエンコーダ(約300Mパラメータ)がE2BとE4Bモデルに搭載されています。


Gemma 4の特徴
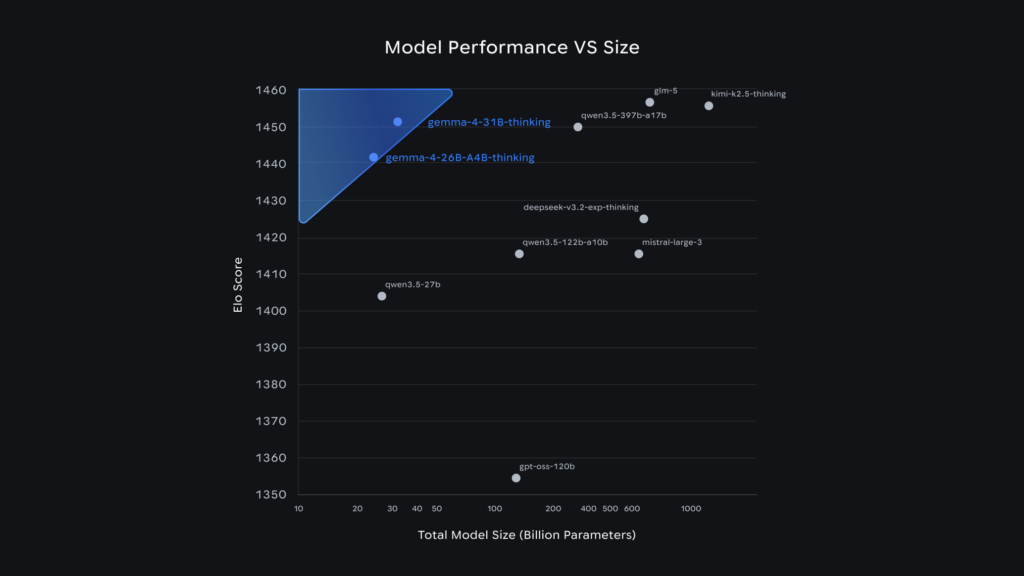
ここからは、ベンチマークの数値を中心に、Gemma 4の実力を深掘りしていきましょう。
推論・コーディング性能がとにかく高い
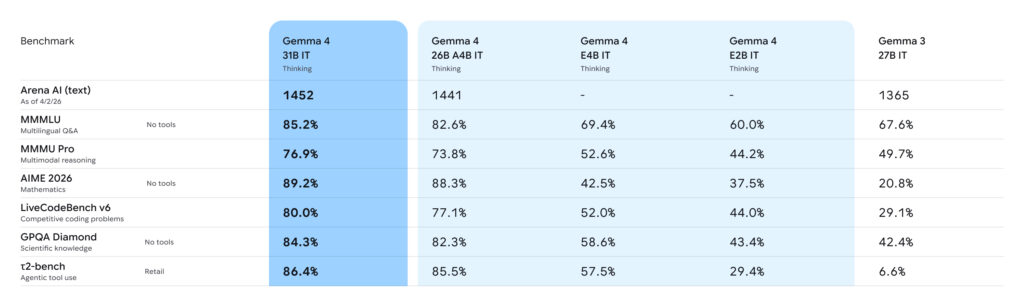
31Bモデルは、数学推論の難関テストAIME 2026で89.2%、コーディング能力を測るLiveCodeBench v6で80.0%、科学知識のGPQA Diamondで84.3%を記録しています。Codeforces ELOレーティングは2150で、競技プログラミングの世界でもかなりの実力です。
| ベンチマーク | 31B | 26B MoE | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| MMMLU(多言語) | 88.4% | 86.3% | 76.6% | 67.4% |
| MMMU Pro(マルチモーダル) | 76.9% | 73.8% | 52.6% | 44.2% |
| MATH-Vision | 85.6% | — | — | 52.4% |
テキスト・画像・動画・音声にネイティブ対応
全モデルがテキスト・画像・動画の入力に対応しています。
E2BとE4Bモデルではさらに音声入力もサポートしていて、音声認識(ASR)や音声翻訳が追加モジュールなしで使えます。動画は最大60秒(1fps)のフレーム解析に対応しており、OCRや図表の読み取り、手書き文字認識でも高い精度を出してくれます。
エージェント機能を標準搭載
ネイティブの関数呼び出しと構造化JSON出力をサポートしているのも大きなポイントです。外部ツールやAPIと連携する自律型エージェントを比較的かんたんに構築できるようになっています。
アプリのナビゲーション、タスクの自動実行、複数ステップの計画立案など、いわゆるエージェンティックなワークフローをモデル単体で回せる設計です。τ2-bench(エージェント性能ベンチマーク)では、31Bモデルが86.4%を達成しています。
Thinkingモードで深い思考にも対応
推論時に段階的な思考プロセスを有効化できるThinkingモードも搭載されています。数学の難問やコーディングタスクなど、じっくり考える必要がある場面で、ステップバイステップの分析を挟みながら回答の質を高めてくれます。
Gemma 4の安全性・制約
Gemma 4は、Googleのプロプライエタリモデルと同じセキュリティプロトコルで開発・評価されています。訓練データにはCSAMフィルタリングや個人情報フィルタリングが適用されていて、有害コンテンツや個人を特定できるデータは除去済みだそうです。
安全性の評価では、GoogleのAI原則に基づく自動評価と人手評価の両方が行われています。児童搾取コンテンツ、危険な情報、ヘイトスピーチ、ハラスメントなどのカテゴリについてスクリーニングが実施され、以前のGemmaモデルと比較してすべてのカテゴリで大幅な改善が確認されたとのことです。
Gemma 4の料金
Gemma 4はApache 2.0ライセンスのオープンソースモデルなので、モデルの重み自体は無料でダウンロード・利用できます。GeminiシリーズのようなAPI従量課金ではなく、自分のハードウェアやクラウド環境にデプロイして使う形が基本です。かかるコストは主にインフラまわりの費用になります。
| 利用方法 | 料金 | 備考 |
|---|---|---|
| モデルのダウンロード(Hugging Face / Kaggle / Ollama) | 無料 | Apache 2.0ライセンスで制限なし |
| Google AI Studio での利用 | 無料 | 31Bおよび26B MoEモデルが利用可能 |
| ローカル実行(自前PC / Mac) | 無料(ハードウェア費用のみ) | Ollamaやllama.cppですぐ動かせる |
| Vertex AI でのデプロイ | インフラ従量課金 | GPU/TPUの利用時間に応じた料金 |
| Cloud Run / GKE でのデプロイ | インフラ従量課金 | コンテナ・ノードの利用料金 |
| NVIDIA NIM での利用 | 環境による | NVIDIA GPUが必要 |
ローカルで動かす場合、31Bモデルの非量子化版(bfloat16)はNVIDIA H100(80GB)1枚に収まります。量子化すればコンシューマ向けGPUでも動作可能です。26B MoEモデルはアクティブパラメータが3.8Bだけなので、推論速度面でもかなり効率的です。
Gemma 4のライセンス
Gemma 4は、Gemmaシリーズで初めてApache 2.0ライセンスを採用しました。従来のGoogle独自ライセンス(Gemma Terms of Use)からの大きな方針転換で、オープンソースコミュニティにとってはかなりインパクトのあるニュースです。
| 項目 | 可否 | 備考 |
|---|---|---|
| 商用利用 | ⭕️ | プロダクトへの組み込み、SaaS提供もOK |
| 改変(モデルの修正・ファインチューニング) | ⭕️ | 独自データでの追加学習や改変が自由 |
| 再配布 | ⭕️ | ライセンス表記と変更箇所の明記が必要 |
| 特許利用 | ⭕️ | Apache 2.0には明示的な特許権の付与条項あり |
| 私的利用 | ⭕️ | 個人の学習・研究目的でも制限なし |
このApache 2.0への移行は、MetaのLlamaシリーズなど競合オープンモデルへの対抗を意識した戦略的な判断とも見られています。
Gemma 4の使い方
Gemma 4は複数のプラットフォームから利用できます。ここからはGemma 4の代表的な使い方を順にご紹介していきます。
Google AI Studioで試す
1番かんたんにGemma 4を使うことができるのが、Google AI Studioを使う方法です。ブラウザだけで動くので、インストールは一切不要です。
こちらのURL(https://aistudio.google.com/prompts/new_chat?model=gemma-4-31b-it)からGoogle AI Studioを開き、Googleアカウントでログインします。
画面上部のモデル選択メニューから「Gemma 4 31B」か「Gemma 4 26B」を選びます。
チャット欄にプロンプトを打ち込んで送信すれば、すぐに回答が返ってきます。画像をアップロードしてマルチモーダルな質問を投げることもできます。
Ollamaでローカル実行する
ローカルPCでGemma 4を動かしたい場合は、Ollamaが一番シンプルです。
公式サイト(https://ollama.com)からインストーラをダウンロードします。
- Mac:zipを展開してApplicationsフォルダに配置
- Windows:exeファイルを実行
- Linux:
curl -fsSL https://ollama.com/install.sh | sh
ターミナルを開いて、以下のコマンドを実行するだけです。
クリックで表示
# デフォルト(E4Bモデル、9.6GB)
ollama run gemma4
# 超軽量モデル(E2B、7.2GB)
ollama run gemma4:e2b
# MoEモデル(26B、18GB)
ollama run gemma4:26b
# フラグシップモデル(31B、20GB)
ollama run gemma4:31b初回は自動でモデルがダウンロードされます。完了すると、そのまま対話型チャットが始まります。
プロンプトを入力すれば、Gemma 4が応答を返してくれます。Gemma 3と違い、system / user / assistantの標準ロール構成に対応しているので、システムプロンプトの設定もスムーズです。
Hugging Face Transformersで利用する
Pythonコードから直接動かしたいなら、Hugging Face Transformersを使うのがおすすめです。
pip install -U transformersクリックで表示
from transformers import pipeline
pipe = pipeline("any-to-any", model="google/gemma-4-e4b-it")
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "日本の首都はどこですか?"}
],
}
]
output = pipe(messages, max_new_tokens=200, return_full_text=False)
print(output[0]["generated_text"])画像を使ったマルチモーダル推論もかんたんです。contentにimageタイプを追加するだけで対応できます。
クリックで表示
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "path/to/image.jpg"},
{"type": "text", "text": "この画像に写っているものを教えてください。"}
],
}
]
output = pipe(messages, max_new_tokens=300, return_full_text=False)
print(output[0]["generated_text"])llama.cppでローカルAPIサーバーを立てる
OpenAI互換のAPIサーバーとしてGemma 4をローカルで使いたいなら、llama.cppが便利です。
クリックで表示
# macOS
brew install llama.cpp
# Windows
winget install llama.cppクリックで表示
llama-server -hf ggml-org/gemma-4-26b-a4b-it-GGUF起動すると、http://localhost:8080 でOpenAI互換のAPIエンドポイントが使えるようになります。
Apple Silicon(Mac)でMLXを使う
M1〜M4チップ搭載のMacなら、MLXフレームワークで効率よく推論を回せます。
クリックで表示
pip install -U mlx-vlm
mlx_vlm.generate \
--model google/gemma-4-E4B-it \
--prompt "Pythonでフィボナッチ数列を生成する関数を書いてください"Google AI Edge Galleryでスマホから使う
スマートフォンやタブレットでGemma 4を動かしたいなら、Google AI Edge Galleryがおすすめです。完全オンデバイスで動作するので、インターネット接続なしでも使えます。対応モデルはE2BとE4Bの2種類となっています。
Google AI Edge Galleryは、iOSとAndroidの両方に対応しています。
- Android:Google Playストアで「AI Edge Gallery」と検索してインストール(Android 12以上が必要)
- iOS:App Storeで「AI Edge Gallery」と検索してインストール(iOS 17以上が必要)
Google Playが使えない環境の場合は、GitHubリリースページ(https://github.com/google-ai-edge/gallery/releases)からAPKを直接ダウンロードすることもできます。
アプリを起動すると、利用可能なモデルの一覧が表示されます。
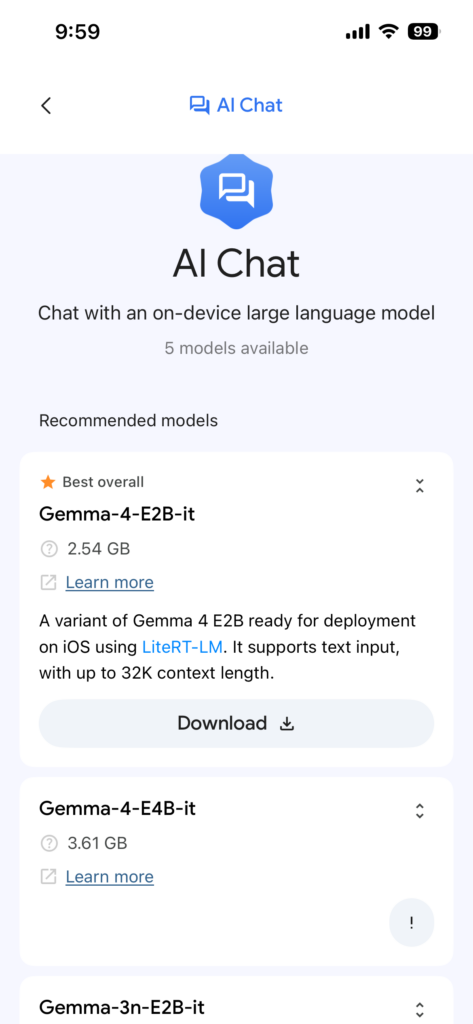
Gemma 4 E2BまたはE4Bを選んでダウンロードしましょう。E2Bモデルであれば必要メモリは1.5GB未満なので、一般的なスマートフォンでも問題なく動きます。
ダウンロードが完了したら、以下の機能がすぐに使えるようになります。
| 項目 | 内容 |
|---|---|
| AI Chat | 通常の対話型チャット。Thinkingモードを有効にすると、モデルの推論過程をステップごとに確認できます |
| Agent Skills | Wikipediaなどの外部ツールと連携して、情報検索やリッチな回答カードの生成ができるエージェント機能です。GitHubのコミュニティで公開されているスキルを読み込んだり、自作スキルをURLから追加したりもできます |
| Ask Image | カメラやフォトライブラリの画像を使って、物体の識別や画像の説明をマルチモーダルで処理してくれます |
| Audio Scribe | 音声をリアルタイムで文字起こし・翻訳する機能です(E2B/E4Bの音声入力対応を活かした機能) |
全処理がデバイス上で完結するので、プライバシーが気になる場面や、オフライン環境でもそのまま使えるのが大きなメリットです。
通信環境を気にせずGemma 4を持ち歩けるので、ちょっとした検証や日常的なAIアシスタントとして試してみると面白いと思います。
【業界別】Gemma 4の活用シーン
オープンモデルならではの柔軟性を活かして、Gemma 4はさまざまな業界での活用が期待されています。こちらでは、業界ごとに相性のいいユースケースを整理していきます。
製造業・IoT
Gemma 4のE2BやE4Bモデルは、スマートフォンやエッジデバイス上で完全にオフライン動作するので、ネットワーク環境が限られた工場現場でも導入しやすいのが強みです。
製造ラインの異常検知、品質検査画像の解析、機器マニュアルの多言語翻訳といった用途と相性がよく、データを外部に出さずに済むのでセキュリティポリシーが厳しい現場でも使いやすいかと思います。
製造業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

ソフトウェア開発
Codeforces ELO 2150のコーディング性能は、コードレビュー補助やバグ修正の提案、テストコードの自動生成にそのまま活きてきます。
Android Studioでは公式にGemma 4がサポートされていて、ローカル環境でのエージェンティックなコーディング支援が可能です。Function Calling機能を組み合わせれば、CI/CDパイプラインへの統合も現実的でしょう。
教育・研究機関
Apache 2.0ライセンスなので、教育機関や研究者がモデルを自由に改変・実験できます。
140以上の言語に対応しているため、多言語NLP研究のベースモデルとしても優秀です。学生向けの個別学習支援AIや、論文ドラフトの作成補助ツールの開発にも向いていると思います。
教育業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

医療・ヘルスケア
MMMU Pro 76.9%に裏付けされた画像理解能力を活かした医療画像の事前スクリーニングや、診断補助レポートの生成に応用できそうです。
患者データをクラウドに送らずオンプレミスで処理できるので、医療データのプライバシー保護要件にも合わせやすい構成が組めます。
医療業界における生成AI活用について、詳しく知りたい方は以下の記事も参考にしてみてください。

【課題別】Gemma 4が解決できること
ここからは、業界横断で共通する技術課題に対して、Gemma 4がどう貢献できるかを整理していきます。
クラウドAPIコストの削減
大規模言語モデルをクラウドAPI経由で使っていると、トークン数に比例してコストがどんどん膨らみます。
そこに対して、Gemma 4はオープンモデルとしてローカル実行ができるので、利用量が多いユースケースではAPI課金をまるごとカットできます。特に、26B MoEモデルはアクティブパラメータが3.8Bしかなく、推論速度とコスト効率のバランスが非常に優れています。
データプライバシーの確保
個人情報や機密データを扱う業務では、外部クラウドへのデータ送信自体がリスクになります。
そこで、Gemma 4をオンプレミス環境やエッジデバイスに入れてしまえば、データを一切外に出さずにAI処理を完結させられます。E2Bモデルならスマートフォン上での完全オフライン動作にも対応しています。
複雑な推論タスクの自動化
AIME 2026で89.2%という数学推論能力と、Thinkingモードによるステップバイステップ分析を組み合わせれば、従来は人が介在しないと難しかった分析・判断タスクの自動化が見えてきます。財務分析レポートの下書きや、技術文書の論理的整合性チェックなどが具体的なイメージです。
Gemma 4を使ってみた
それでは実際に、Gemma 4の実力を確認していきましょう。Google AI Studioの31Bモデル(gemma-4-31b-it)を使って、3つの観点から検証しています。
検証1:日本語での複雑な推論タスク
まずは日本語の論理的推論能力を確認するため、多段階の思考が必要な問題を投げてみました。
プロンプト:
AさんはBさんより年上で、CさんはBさんより年下です。DさんはCさんより年上でAさんより年下です。4人を年齢順に並べてください。また、この情報だけでBさんとDさんの年齢の上下を確定できるか、論理的に説明してください。結果はこちら:
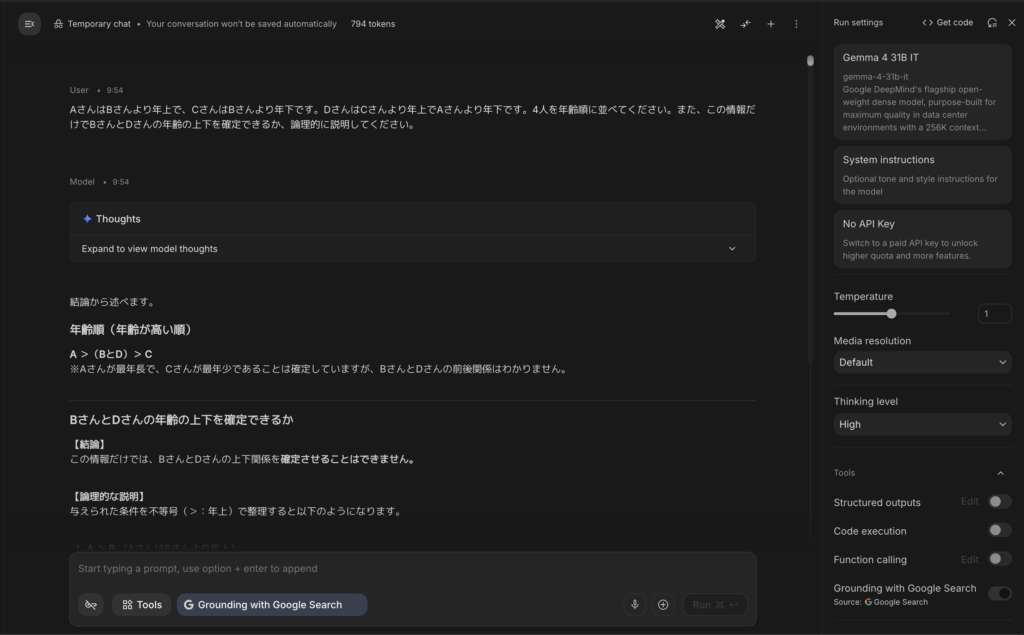
Thinkingモードを有効にすると、各条件を一つずつ整理しながら推論を進めていき、最終的に「A > D > Cは確定するが、BとDの関係は与えられた条件からは確定できない」という正しい結論にたどり着きました。
曖昧な部分をちゃんと「確定できない」と切り分けられているのは、実務で使う上でかなり頼もしいですね。
検証2:Google AI Edge Galleryでスマホから使ってみた
次に、スマートフォン(iOS)にGoogle AI Edge Galleryをインストールし、Gemma 4 E4Bモデルをオンデバイスで試してみました。Wi-Fiでモデルをダウンロードしたあとは機内モードに切り替えて、完全オフラインの状態でAI Chatを検証してみます。
プロンプト
日本の三権分立について小学生にも分かるように説明して結果はこちら
たとえ話を交えた分かりやすい回答を返してくれました。回答スピードの速さも素晴らしいですね。
オンデバイスとは思えないほど自然な日本語で、体感的なレスポンスも十分実用的なレベルです。通勤中やオフラインの出先でもサッと使えるAIアシスタントとして、かなり実用性が高いと思います。
Gemma 4のよくある質問
最後に、Gemma 4に関して、多くの方が気になるであろう質問とその回答をご紹介します。


Gemma 4を導入してみよう!
Gemma 4は、Googleがパラメータあたりの知能で世界最高を目指して開発したオープンモデルです。Gemini 3の研究成果を活かした4サイズのラインナップ、Apache 2.0ライセンスへの移行、テキスト・画像・動画・音声をまとめて扱えるネイティブマルチモーダル対応によって、エッジデバイスからサーバーまで幅広い環境で高度なAI処理を実現しています。
26B MoEモデルであれば、わずか3.8Bのアクティブパラメータで高い性能が出せる効率のよさも魅力です。APIコストを抑えたい企業、データプライバシーを重視する組織、エッジAIに取り組みたい開発者にとって、有力な選択肢になるのではないでしょうか。
気になった方は、ぜひ一度お試しください!

最後に
いかがだったでしょうか?
弊社では、AI導入を検討中の企業向けに、業務効率化や新しい価値創出を支援する情報提供・導入支援を行っています。最新のAIを活用し、効率的な業務改善や高度な分析が可能です。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、大規模言語モデル(LLM)を対象に、言語理解能力、生成能力、応答速度の各側面について比較・検証した資料も配布しております。この機会にぜひご活用ください。

