
OpenAIのSoraとは?革新的な点や仕組みをエンジニアが徹底解説

WEELメディア事業部LLMリサーチャーの中田です。
2024年2月15日、OpenAI社が「Sora」という動画生成AIモデルを公開しました!
これまでの動画生成AIでは、せいぜい数秒の動画しか生成できなかったですが、Soraの場合、最長1分の動画を超高品質で生成できます。
Xの投稿のいいね数は、すでに13万を超えており、世界中でかなり注目されていることが分かります。
この記事では、Soraの技術的な部分を徹底的に解説します。本記事を熟読することで、Soraの内部構造をより理解でき、一般公開が待ち遠しくなるでしょう。
ぜひ、最後までご覧ください。

Soraの概要
2024年2月15日、OpenAI社は動画生成AIモデルの「Sora」を公開しました。このモデルにより、以下のようなタスクが可能になるそうです。
- Text-to-video
- Image-to-video
- Video-to-video(動画のスタイル変換)
- Videoの時間延長
- ループ動画の生成
- 画像生成
例えば、以下のプロンプトをSoraに入力すると、、、
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
和訳:
数頭の巨大な毛むくじゃらのマンモスが雪の草原を踏みしめながら近づいてくる。長い毛むくじゃらの毛が風になびきながら歩くマンモス、雪に覆われた木々、遠くに見えるドラマチックな雪を頂いた山々。
以下のような動画が生成されるそうです。
Soraの登場によって、広告業界やエンタテインメント業界のほか、様々な業界で変革が起こるでしょう。ちなみに、現在はSoraに関する様々な問題点についてテスト中のため、モデルの一般公開はされていません。
なお、Soraの凄さやメリット・デメリットについて詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【Sora】世界に激震を与えたOpenAIの動画生成AI!できることや仕組み、問題点まで徹底解説


Soraの技術構成
Soraの技術的な詳細に関しては、公式サイトのSoraテクニカルレポートに記載されています。ここでは、レポートの内容をもとに、Soraで使われている技術について、詳しく解説します。
Soraは「Diffusion Transformer」という生成AIモデルの一種です。
Importantly, Sora is a diffusion transformer.
引用:https://openai.com/sora
このDiffusion Transformer自体、以下の論文で提案された手法です。
参考記事:Scalable Diffusion Models with Transformers
具体的には、Soraは以下のような要素で構成されています。
- 動画→パッチへの変換
- Diffusion Transformerによる動画生成
- DALL-E3のキャプショニング
各要素について、順番に見ていきましょう。
動画→パッチへの変換
ここでは、生の動画データを、低次元のベクトルへ圧縮しています。こうすることで、Diffusion Transformerで学習する際に、学習効率が良くなるそうです。
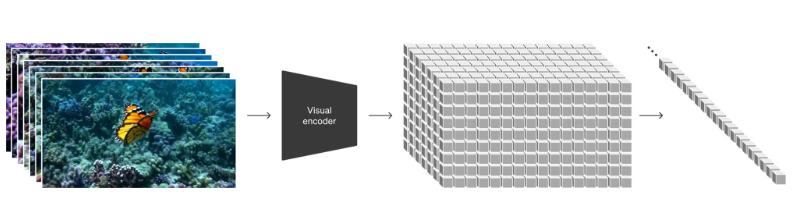
具体的な方法としては、以下の手順の通りです。
- 動画を構成する各画像を用意(動画は画像の集合体)
- 1をVisual Encoderに通すことで低次元に圧縮
- 2で圧縮されたデータを、上図右端の1次元ベクトルに平坦化(パッチ化)
要するに、「画像生成でいうところのVAE」のようなものでデータを圧縮し、それを1次元のベクトルに変換しているのです。そして、この1次元ベクトルを、LLMでいうところの「テキストトークン」として、学習時に扱うそうです。
このSoraのパッチ化では、Vision Transformer(画像をTransformerで扱う技術)やNaViT(Vision Transformerの改良版)の研究で提案された手法が踏襲されているそう。
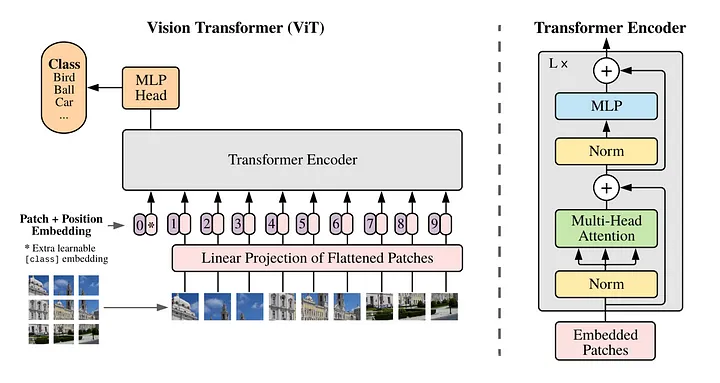
この手法を用いることで、畳み込み処理を使用せず、Transformer(LLM)で画像処理を行えるようになりました。Soraではこの技術を、動画の処理に応用しているのです。
Diffusion Transformerによる動画生成
次に、先ほど生成した動画の低次元ベクトルを、Diffusion TransformerというAIモデルで処理します。このDiffusion Transformerとは、Stable Diffusionなどで用いられている「拡散モデル」という生成AI技術の一種です。
以下の画像は、その拡散モデルを表しているもので、世の中に注目されるきっかけとなったであろう論文で紹介されたアルゴリズム(DDPM)です。

この拡散モデルを簡単にいうと、「いったん画像を粗くし、もう一度その画像を修復する」という訓練を通じて、画像を生成する能力を得たモデルです。
これは、動画でも同じことができます。

また、拡散モデルには通常、以下のような「U-Net」と呼ばれる「画像のセマンティックセグメンテーション用モデル」が使用されます。
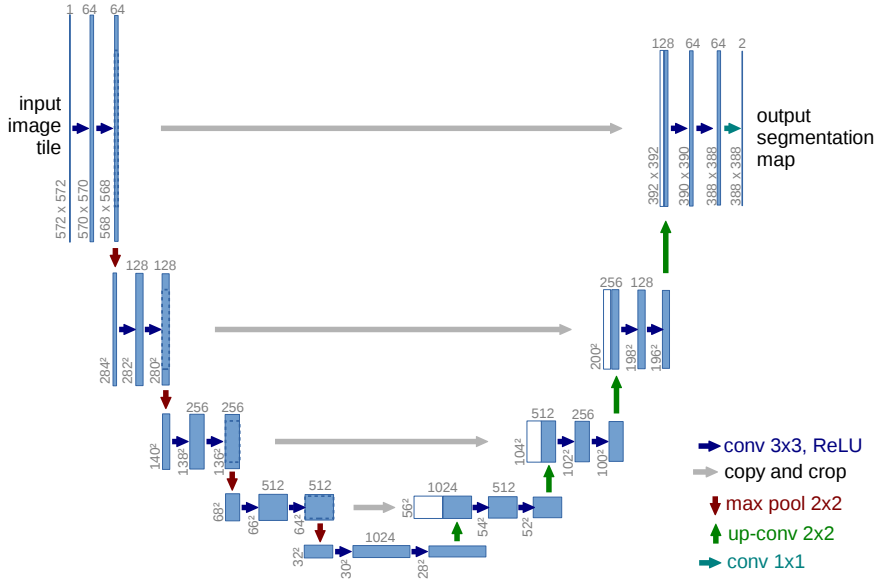
一方、SoraではU-Netではなく、Transformerを用いているのです。そうすることで、「画像を画像として処理するというアプローチ」から、「画像をテキストとして処理するアプローチ」に変換しているのでしょう。
以下が、Diffusion Transformerの概略図です。
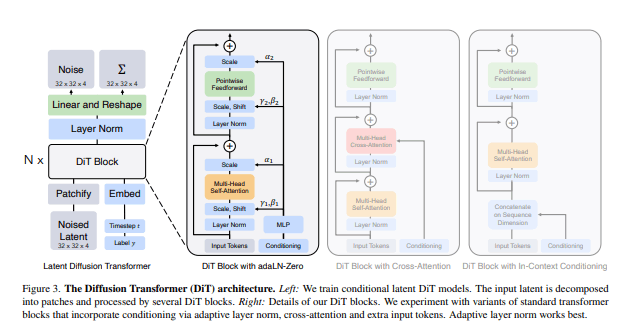
このアーキテクチャを用いることで、テキストを生成するかのように、動画を生成しているのでしょう。
DALL-E3のキャプショニング
ここでは、学習に利用するテキストデータの品質向上テクニックが用いられています。具体的には、DALL-E3でも用いられていた画像キャプショニングを、動画に応用しています。
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. We apply the re-captioning technique introduced in DALL·E 3 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model. This enables Sora to generate high quality videos that accurately follow user prompts.
和訳:テキスト-ビデオ生成システムのトレーニングには、対応するテキスト・キャプションを持つ大量のビデオが必要である。我々は、DALL-E 3で導入されたリキャプション技術を動画に適用する。まず、高度に記述的なキャプションモデルを学習し、そのモデルを用いて、学習セット内のすべての動画に対してテキストキャプションを生成する。記述性の高い動画キャプションを学習することで、動画の全体的な品質だけでなく、テキストの忠実度も向上することが分かる。
また、DALL-E 3と同様に、GPTを活用して短いユーザープロンプトを長い詳細なキャプションに変換し、ビデオモデルに送信します。これにより、Soraはユーザーのプロンプトに正確に従った高品質のビデオを生成することができます。
引用:https://openai.com/research/video-generation-models-as-world-simulators
具体的な手法として、以下の手順の通りです。
- ユーザーがテキストプロンプトを入力
- 1のテキストをLLMによって、より具体的な文章に変換
- 2のテキストを拡散モデルに送り込み、テキストに沿った画像を生成

こうすることで、ユーザーがDALL-E3に入力した「抽象的なプロンプト指示」を、より詳細なプロンプト指示文に変えられます。そのプロンプト情報をText Encoderを通して拡散モデルに送り込むことで、ユーザーの意図に沿った画像を生成できるのです。
このDALL-E3のキャプション技術を、Soraにも応用しています。
このキャプション技術については、以下のソニーのYouTube動画の6分30秒あたりから、詳しく解説されています。
こうすることで、高品質なテキストでキャプションされた動画のデータセットを得ることが可能です。
機械学習においては学習データの品質が、モデルの精度を大きく左右するので、Soraの高品質な動画生成は、こうした工夫のたまものなのでしょう。
なお、Soraの活用事例について詳しく知りたい方は、下記の記事を合わせてご確認ください。
→【OpenAI Soraのおすすめ活用事例】一晩で世界を変えた動画生成AIのヤバい使い方10選


Soraが今すぐ使えるようになっていない理由
冒頭でも述べたとおり、Soraは現在のところ一般公開されていません。その理由は、OpenAIの「レッドチーム」と呼ばれる「AIの悪用のリスクを検証するチーム」によって、危険性のテストがされているからです。
やはり、これほど高品質な動画を生成できるようになれば、それをディープフェイクに悪用する人も現れると予想されます。これを利用して、芸能人の不祥事に繋げたり、政治的な不安を煽ったりする事態にもなりかねません。
そういった観点からも、Soraの十分な検証が欠かせないのでしょう。
今後のSoraの動きに要注目
本記事では、Soraで使われている技術について焦点を当てて、解説しました。個人的には、Soraで用いられている技術自体には、それほど革新的なものはなく、これまで世に出てきた研究の成果に、かなり沿っているように思いました。
やはり、莫大なコストを割いて、強力な計算資源を利用するのが大事なんだなという印象です。
また、Soraはリスクもある一方で、様々な可能性を秘めているAIです。一般公開までまだ先ですが、今のうちにSoraの凄さを改めて理解し、Soraに関する来たるチャンスをいち早くものにしましょう。
ちなみに、Xユーザーの投稿によると、K-POPアイドルのMVもSoraで作成できるとのこと。しかし、当ツイートのリプライ欄にもある通り、実在するアイドルグループのMVだそうです。そのため、下記のXの投稿にある「OpenAIのSoraで作成した」というのは嘘になります。
このようなフェイク情報には気をつけてくださいね(この手の投稿が、ある種のミーム化されています)。
最後に
いかがだったでしょうか?
弊社では
・マーケティングやエンジニアリングなどの専門知識を学習させたAI社員の開発
・要件定義・業務フロー作成を80%自動化できる自律型AIエージェントの開発
・生成AIとRPAを組み合わせた業務自動化ツールの開発
・社内人事業務を99%自動化できるAIツールの開発
・ハルシネーション対策AIツールの開発
・自社専用のAIチャットボットの開発
などの開発実績がございます。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


