
【図解付き】Rerankとは?検索精度を劇的に上げる最新AI技術を徹底解説

- RAG構成の一部として検索結果を文脈に基づいて再評価・並び替え、情報の精度と信頼性を高める技術。
- チャットボットや社内ナレッジ検索など多様な場面で活用され、検索UXや業務効率の向上に直結する。
- CohereやColBERTなど用途に応じたモデル選定が重要で、精度重視か速度優先かに合わせた導入が効果的。
生成AIの進化に伴い利用者が増えたことで、回答の精度や文脈理解がより求められる時代になりました。そんな中で注目されている技術が、情報検索の精度を高められるRerank(リランク)です。
今回は、RAGの一部として情報の信頼性を高めることができるRerankの仕組みや活用事例について解説します。なるべくわかりやすいように図解もしておりますので、ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
Rerankとは?
近年のAI技術の進化により、大規模言語モデル(LLM)が生み出す回答の正確さや信頼性がより重要視されるようになっているため、RAGを活用して外部知識を取り入れ、回答の質を向上させる方法が注目されています。
しかし、RAGは質問に対して関連する文書をデータベースなどから情報検索を行い、キーワードの一致や単純に類似している情報をLLMへの出力として利用するため、質問と関連性の低い情報が出力されてしまうことも多いのが現状です。
そこで登場するのがRerank。
Rerankとは、LLMの精度を高めるための仕組みであるRAGの中に情報検索結果を見直して並び替えるプロセスのことで、簡単に言えば初期の情報検索で得られた情報をもう一度評価し直して、よりユーザーの意図に合った順序に整える役割を担っています。
従来の情報検索では、クエリと文書の類似度を計算し、スコアが高い順に並べる方法(Embedding検索)が主流でしたが、意味は似ていても文脈的に不適切な結果が上位に表示されてしまうことがありました。
そのため、ユーザーにとって本当に有用な情報を届けることのできるRerankが今注目されています。
なお、RAGについて詳しく知りたい方は、下記の記事も合わせてご覧ください。

RAGの流れとRerankの位置づけ
RAGは、ユーザーからの入力に対して、まず関連する外部知識を検索(Retriever)し、それを元にLLMが回答を生成するという2段階のプロセスで構成されます。
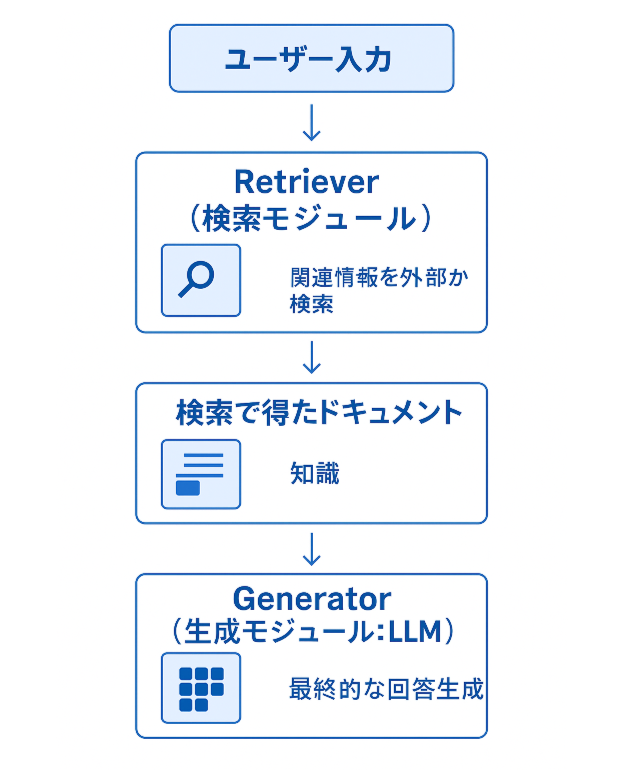
Rerankは、Retrieverで収集した関連文章を再評価するため、Rerankの位置付けとしては下記の画像の通りRetrieverの後に動作します。
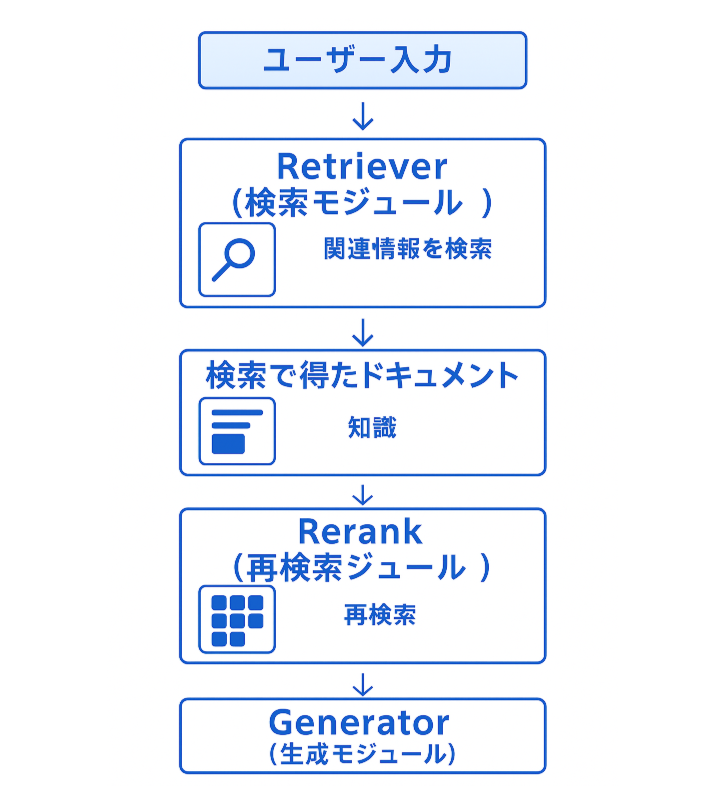
「Retriever」と「Rerank」の違い
Retrieverは、主にベクトル検索により大量の文書群から類似性の高い候補を高速に抽出する役割を担います。簡単に言うとユーザーの検索意図などをあまり考慮せず、入力したキーワードや情報と類似している情報を抽出します。
それに対してRerankerは、その候補を文脈や関連性に基づいて再評価し最終的にどの情報を使うかを判断するため、よりユーザーが求める情報に辿りつきやすくなります。
Embeddingベース検索とは
Embedding検索とは前述でも簡単に触れた通りクエリと文書の類似度を計算し、スコアが高い順に並べる方法のことで、スピードと拡張性に優れますが表面的な類似性に引きずられやすく、ユーザーの検索意図を深く理解できないケースもあります。


Rerankモデルの仕組みと代表的な手法
Rerankはこれまで説明してきた通り、検索システムで一度候補として抽出された文書に対し「本当にそのクエリと関連性が高いのか?」を再評価する役割を持つモデルです。
そのため、従来の検索システムよりもユーザーが求める情報に近い検索結果を得ることができます。
以下は、現在注目されている主要なRerankモデルとその特徴です。
| モデル名 | 特徴 | 精度 |
|---|---|---|
| Cohere Rerank | APIで提供されており使いやすく、LLMを活用した高度な文脈理解が可能。 設定不要で高精度なランキングが実現できる。 | 高 |
| ColBERT | 各トークンごとにマッチングを行う構造なため、高速かつ軽量。特に低レイテンシが求められる場面に活用されることが多い。 | 中〜高 |
| BGE Reranker | オープンソースで提供され、事前学習済みモデルが複数公開されている。日本語にも対応しやすい。 | 高 |
ColBERTのようにトークンごとに細かくマッチングを行うモデルや、CohereやBGEのように全体的な意味を重視するモデルがあり、それぞれに強みがあります。
導入時には精度を重視するのか、スピードを優先するのかなど目的に応じた選定が必要です。
Rerankの活用事例と導入の流れ
Rerankは、検索結果の質を高めるためにさまざまな業務やシステムで活用されています。
ここでは具体的な活用事例や導入の流れについて解説します。
Rerankの活用事例
チャットボットの精度向上
FAQや顧客サポートなどに用いられるチャットボットでは、ユーザーの質問に対して正確かつ文脈に沿った回答を返すことが重要です。
Rerankは、初期検索で得た候補の中から最も関連性の高いものを選び出すため、曖昧な問い合わせにもユーザーが求めるような適切に対応可能です。回答の質が安定することで、チャットボットの信頼性も高まり、顧客満足度の向上も見込めます。
企業内ナレッジ検索
社内に蓄積された文書やマニュアルは膨大で、目的の情報を探すのに時間がかかることがあり、Embedding検索だけでは限界があることもあるでしょう。
そんな、膨大な文章やマニュアルから情報を探す際にもRerankを導入すれば、意味や文脈に合った情報が優先して表示されます。
求める情報へのアクセスが効率的に行えるようになれば、社員の作業効率や意思決定のスピードが向上し、全体の生産性を底上げすることも可能でしょう。
学術文献のリコメンド
研究者が必要とする文献は、単なるキーワード一致だけでは見つけにくいものが多く、従来のEmbedding検索ではなかなか必要とする文献に辿り着くことができないことがあります。
しかし、Rerankを導入すれば、研究背景や文脈との関連性を重視しより的確な文献を選び出すことができるようになるため、従来の情報検索よりも関連性の高い情報を探すことができます。
これにより、新しいアイデアの発見や研究の深掘りにも役立つでしょう。
導入方法
導入までの流れ
RerankはCohereなどのAPIを活用すれば比較的手軽に導入できます。
大まかにはなりますが、Retrieverで抽出した候補をRerank APIに送信し、スコアに基づいて再順位付けするという流れなので、導入の技術的なハードルは高くなく、ドキュメントやサンプルコードも充実しており、短期間で実装が可能です。
Rerankツール導入のポイント
導入する際には、何を重視するかを明確にすることが重要です。
例えば、出力スピードを求めるならColBERT、精度優先ならCohereやBGEなど、利用用途によって導入するモデルを選ぶ必要性があったり、機密情報を扱う場合には、オープンソースモデルをローカルで動かす選択肢もあります。
それぞれの環境で、求めるものや取り扱う情報が異なるので、自身の環境に沿ったモデルを選択することで、より効果的にRerankを活用できるでしょう。
Rerankのメリット・デメリット
Rerankの導入には明確なメリットがありますが、同時にいくつかのデメリットも存在します。
次に、Rerankのメリットとデメリットについてご紹介します。
メリット
回答精度の改善(誤回答の減少)
Rerankを導入する最大の利点は、誤った情報や文脈違いの回答を大幅に減らせる点にあります。
初期検索で抽出された候補の中から、意味や文脈的にもっとも関連性の高い情報を選別するため、ユーザーの質問に的確な回答を返せます。このように、すぐにほしい情報へアクセスできるようにあるため、作業効率の向上や新しいアイデアの創出時にも役立つでしょう。
ユーザー意図への適合性が高い情報提示
単にキーワードが含まれているだけでなく、ユーザーの本当の目的や背景に合った情報を提示できる点もRerankの魅力です。
文脈を考慮した再評価により、表面的な一致だけではなく、意味のある情報が優先されるためユーザー意図への適合性が高い情報を出力することが可能となります。
検索の信頼性向上によるUX向上
Rerankを導入していないチャットボットを利用していた一部のユーザーは、ほしい情報に辿り着くまでに時間がかかったため、チャットボットを利用せず自分で検索するというユーザーも少なくありません。
しかし、Rerankを導入したチャットボットでは、ほしい情報へ辿り着く確率が上がっており、精度の高い結果が安定して得られることで、チャットボットを活用するユーザーを増やすことにもつながるでしょう。
また、繰り返し使っても期待通りの情報が得られる環境は、サービス全体のユーザー体験(UX)の底上げにもつながるため、利用者数や利用頻度を高めることにつながります。
デメリット
レイテンシの発生
再ランキングには処理時間がかかるため、出力スピードが求められるシーンでは注意が必要です。
特に、Cohereのような高精度モデルを使うと、ユーザーが求める情報へ辿り着く可能性は上がりますがその分レイテンシも増加します。
場合によっては、精度よりも出力スピードが求められるケースもあるため、高速性を重視する場合は軽量モデル、正確性を重視する場合は高精度モデルを利用するなど使い分けが必要となるでしょう。
実装が難しい場合がある
最適なモデルの選定やパラメータ調整など、実装には一定の技術的な知見が求められます。
また、プロジェクトの要件に合ったRerank設計を行うには、実際のユースケースを踏まえた上での試行錯誤も必要となるため、実装が一筋縄では行かない場合もあります。


今後の展望と技術動向
Rerank技術は今後さらに高度化し、多様な応用が期待されています。
最後に、主要企業の動向や技術的トレンドについてご紹介します。
OpenAIの動向
OpenAIは、ChatGPTの法人向け機能において、RetrieverとRerankを組み合わせた構成を導入しています。これにより、単なるキーワードの一致ではなく、文脈を深く理解した回答生成が可能になりました。
このように、OpenAIは従来の検索精度を大きく超えるチャットボットを提供しており、RAG構成の実用性と有効性を証明しています。
今後、OpenAIをはじめとする大手ベンダーが、Rerankを標準機能として広く採用する流れが強まることが予想されるため、OpenAIもユーザー体験のさらなる向上に向けて、技術開発が加速していくことが予想されます。
Cohereの技術革新
Cohereは、商用利用に特化した高性能なRerank APIを提供しており、その精度の高さと導入の手軽さが高く評価されています。特に、スコアリングの正確さと低レイテンシの両立に注力している点やAPIを通じて手軽に導入できる点が大きな強みといえるでしょう。
Cohereは今後、より軽量なモデル展開やカスタマイズ性の強化にも取り組むと見られており、カスタマイズ性が強化されれば、企業規模を問わずRerank技術を導入しやすくなる環境が整うでしょう。
MetaのOSS戦略
Metaは、軽量で高速な再ランキング手法であるColBERTをオープンソースで公開しており、特に開発者コミュニティで広く活用されています。文書内の各トークンを個別に扱うことで、高速かつ文脈に強い評価ができるのが特徴です。
また、オープンソースということもあり、APIに頼らずに高性能なRerankを構築できるため、研究用途や企業内検索、エッジデバイスへの展開など多様な場面で導入が進んでいます。
このように、MetaのOSS戦略は、技術普及とRerankの一般化を大きく後押していると考えられます。
Multimodal Rerankの進化
テキストだけでなく、画像、音声、動画といった複数の情報形式を一貫して扱うMultimodal Rerank技術の開発が活発になっています。
例えば、音声入力に対する文書検索や、画像とテキストを組み合わせた製品検索など、従来では扱いきれなかった複雑な検索にも対応可能になります。
生成AIが活用される分野が拡大する中、こうしたマルチモーダルな再評価技術は今後の情報検索を大きく変える鍵となるでしょう。
オープンソース vs APIの選択肢
Rerank技術を導入する際には、APIを使うのか、それともOSSを活用するのかを慎重に検討する必要があります。
APIは、すぐに高精度の結果が得られる点やメンテナンスの負担が少ない点で利便性が高い一方、継続的な利用コストやデータ送信に関する懸念があります。
対して、OSSは自由度が高く、セキュリティ要件にも柔軟に対応できますが、初期構築や運用に技術力が必要となるでしょう。
そのため、利用シーンやリソースに合わせた、最適なモデル選びが必要です。
なお、生成AI導入の成功事例について詳しく知りたい方は、下記の記事も合わせてご覧ください。

精度とUXを支える次世代技術

Rerankは、生成AIにおける回答の質と信頼性を大幅に向上させる重要な技術です。
従来のEmbedding検索では取りこぼしがちな文脈や意図を再評価し、より正確な情報を抽出することで、検索体験そのものを変える力を持っており、現状でもCohereやColBERT、BGEなど、目的に応じた選択肢もあるため用途や実装環境に合わせた導入が可能です。
また、OpenAIやMetaなどの大手企業が牽引する技術革新や、Multimodal Rerankの登場など、今後の可能性も広がりを見せています。
Rerankは、単なる情報検索の精度をあげるツールとしてだけではなく、UX改善や生産性の底上げも可能な注目すべき技術といえるでしょう。

最後に
いかがだったでしょうか?
自社ナレッジの活用やチャットボット精度の向上にRerank導入を検討中の方へ。最適なモデル選定や導入フローをご提案できます。
「生成AIで新しいプロダクトを作りたい」「もっと本格的に生成AIを業務に組み込みたい」とお考えの方は、ぜひ株式会社WEELにご相談ください。
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
アイデア段階でも構いません。まずは無料相談でお気軽にご相談ください。
➡︎生成AIを活用したプロダクト開発・業務効率化について相談する

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


