
【Deepgram】文字起こしから感情分析までできる全能音声AIを使ってみた

皆さん、Deepgramという音声AIのプラットフォームはご存知ですか?
音声データからの文字起こしや、さらに高度なタスク(要約や文章整形)などをAPIで展開しています。
え、ご存知ない?
1時間の音声データを12秒で文字起こしできる圧倒的なスピード!OpenAIのWhisperは158秒だから、13倍も違うんです!
ということで、仕事で文字起こしツールを使いたいという皆さんのために、この記事ではDeepgramの概要、導入、実際に使ってみた感想についてまとめています。
この記事を最後まで読むと、APIを使ってDeepgram AIのすごさが理解できるはずです!
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
Deepgramの概要
Deepgramは、音声AIのソリューションを提供するプラットフォームです。
できることは、以下の2つ。
- Speech-to-Text(音声からテキストへ変換)
- Speech Understanding(音声理解)
まずは、Speech-to-Textについて。
先述したように音声情報を入力して、その内容をテキストに書き起こせます。
DeepgramのSpeech-to-textは、以下のような3つの特徴があるそうです。
- 精度: 単語の誤り率(WER)が極めて低い。
- 速度: 推論速度が業界平均よりも圧倒的に速い。
- コスト: 競合他社に比べて3-5倍もコスト効率が良い。
次に、Speech Understandingについて。
これは、入力された音声を理解し、それをもとに複雑なタスクを行うというもの。
以下のようにさまざまなタスクを実行可能です。
- 要約(Summarization): 音声データの特定の部分を要約し、読みやすさと分析の容易さを高めます。
- 感情分析(Sentiment Analysis): この機能は、ポジティブ、ニュートラル、ネガティブな感情を識別します。
- トピック検出(Topic Detection): 重要なトピックを特定し、ラベル付けして洞察を得ます。
- エンティティ検出(Entity Detection): 名前や場所、口座番号などのエンティティを識別します。
- 話者識別(Speaker Diarization): 複数の話者がいる場合に、それぞれを識別します。
- 言語検出(Language Detection): 音声内の主要な言語を自動で識別します。
Speech-to-textと、Speech Understandingのそれぞれ、ユースケースとしては以下が考えられます。
- コール分析(Call Analytics):顧客との通話データをリアルタイムで分析することが可能です。これにより、顧客満足度の向上や、効率的な問題解決が期待できます。
- 会話型AI(Conversational AI):Deepgramの音声理解能力は、チャットボットや仮想アシスタントの精度を大幅に向上させます。特に、自然な会話の流れを理解する能力が高いため、より人間らしい対話が可能です。
- コンタクトセンター(Contact Centers):高い精度と速度で音声をテキストに変換できるため、コンタクトセンターでの顧客対応が効率化されます。
- ポッドキャストの文字起こし(Podcast Transcription):ポッドキャストやインタビューの内容を高精度で文字に起こすことができます。これにより、コンテンツのアーカイブや検索性が向上します。
さらにこれまでご紹介した機能はAPIで利用可能です。
なお、OpenAI発の音声認識モデルについて知りたい方はこちらをご覧ください。
→【Whisper】OpenAIの文字起こしツール!モデル一覧、料金体系、APIの使い方を解説
Deepgramの料金体系
DeepgramをAPI経由で利用する際の料金プランも非常に柔軟で、多様なニーズに対応しています。
以下に料金プランをまとめました。
| 項目 | Pay-as-You-Go | Growth | Enterprise |
|---|---|---|---|
| 無料クレジット | $200 | 年間$4Kから | – |
| 対象者 | 個々の開発者、新規プロジェクト | 成長フェーズのスタートアップ、中小企業 | 大規模プロジェクト、エンタープライズ |
| 料金 | Novaモデル: $0.0044/分 Streamingモデル: $0.0059/分 Whisperモデル: $0.0048/分 | Novaモデル: $0.0036/分 Streamingモデル: $0.0049/分 Whisperモデル: $0.0048/分 | 個別見積もり |
| オプション(Audio Intelligence) | $0.0043/分 | $0.0035/分 | – |
| サポート | コミュニティサポート | コミュニティサポート | プレミアムレベルのSLA、専用サポートチーム、優先メールサポート |
それでは、導入方法を見ていきましょう。

導入方法
まずは、以下のリンクにアクセスします。

次にSign Up Free をクリック。
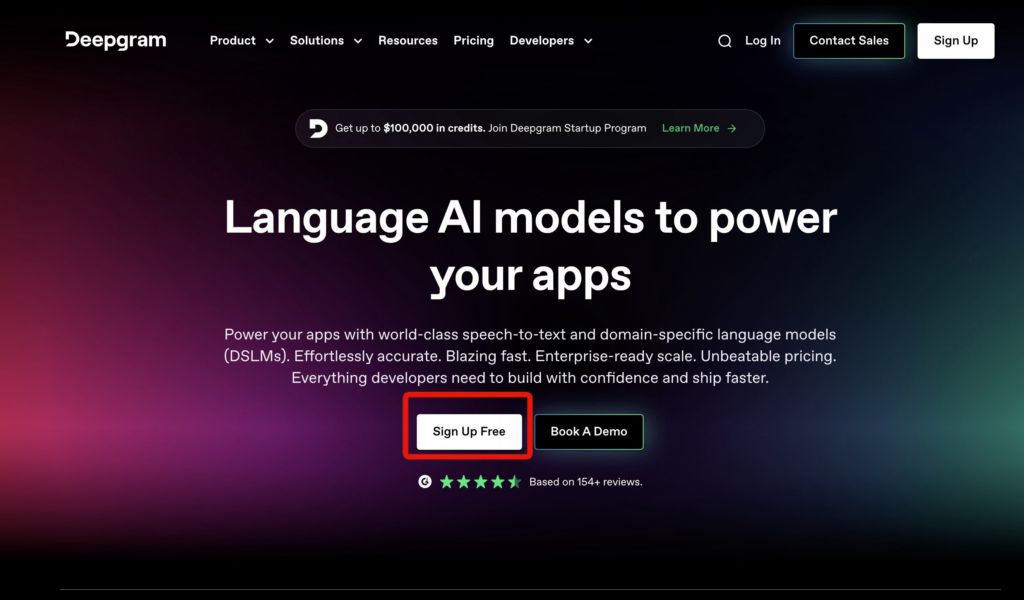
Sign up with Google します。
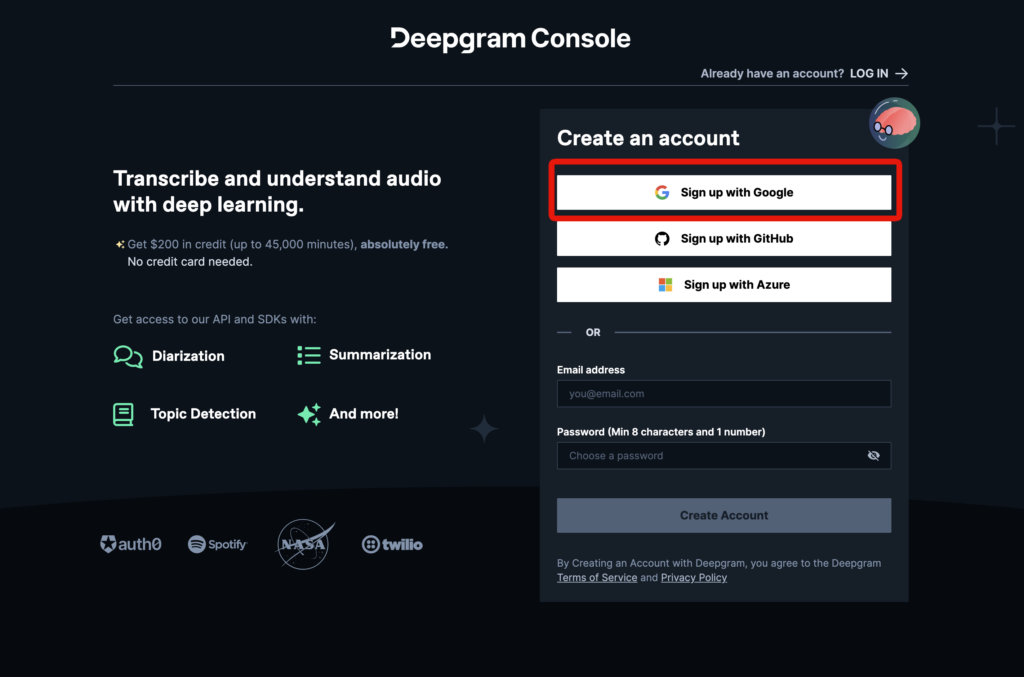
これで準備は完了です。
なお、その他の文字起こし用AIツールについて知りたい方はこちらをご覧ください。
→ChatGPTを使って文字起こし・議事録作成!プラグインやGPTs、プロンプトも紹介
実際に試してみた
先程説明した通りですが、2つのソリューションが提供されています。
それぞれ試してみましょう。
Speech-to-text(音声からテキストへ変換)
こちらは、デモがあるので試してみましょう。
以下の画面で、「Demo:Transcribe pre-recorded files」をクリック。
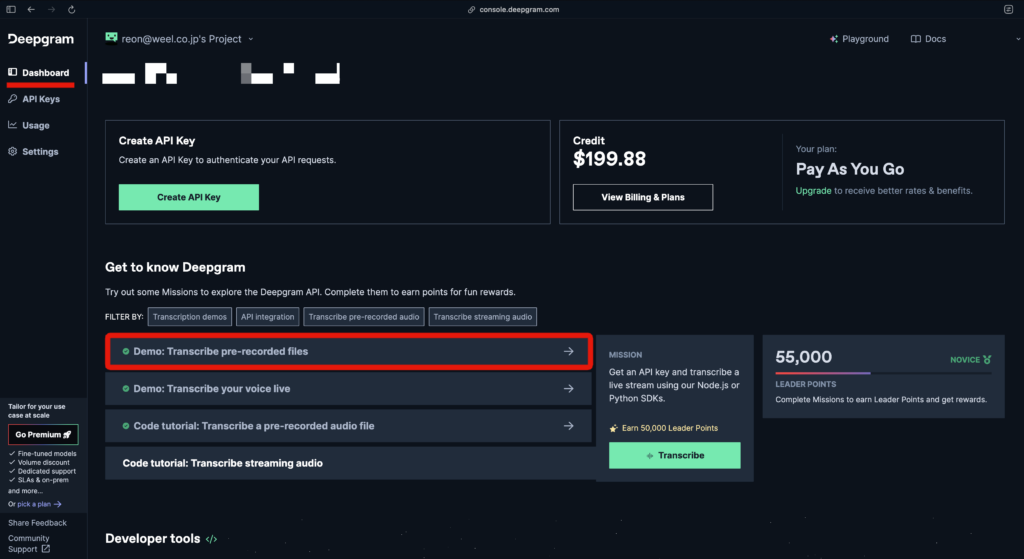
すると以下の画面になるので、まずは言語を英語に。そして、既存を動画を選びましょう。
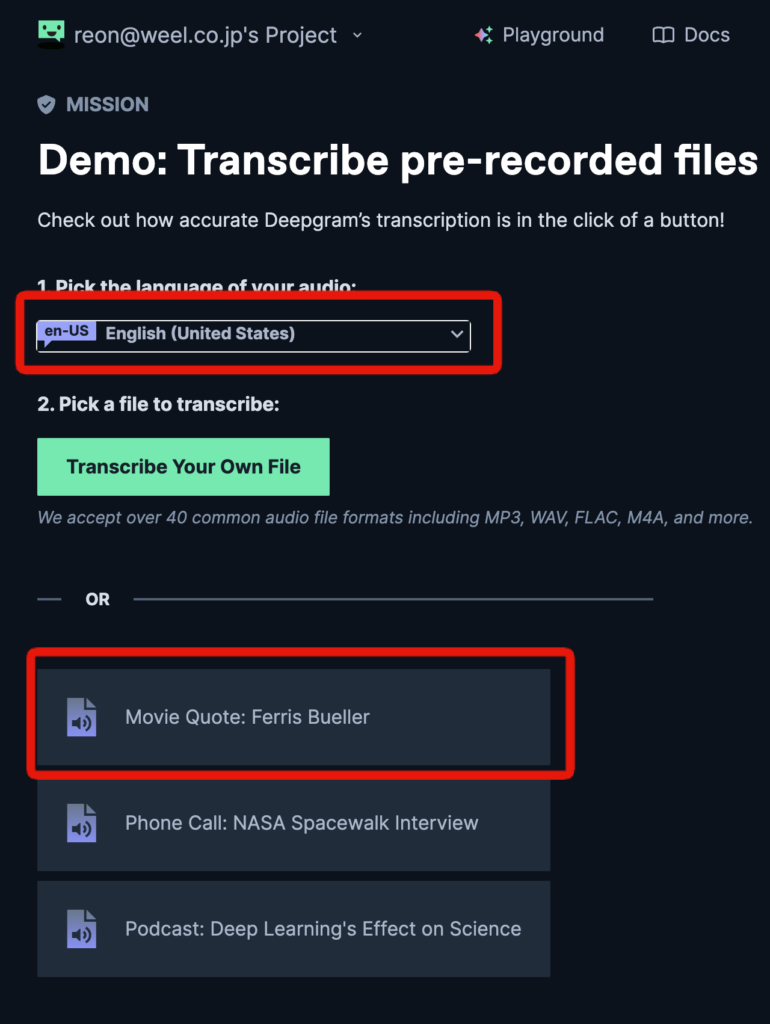
すると以下のようになり、音声からテキストが生成されます。再生ボタンを押して確認してみましょう。
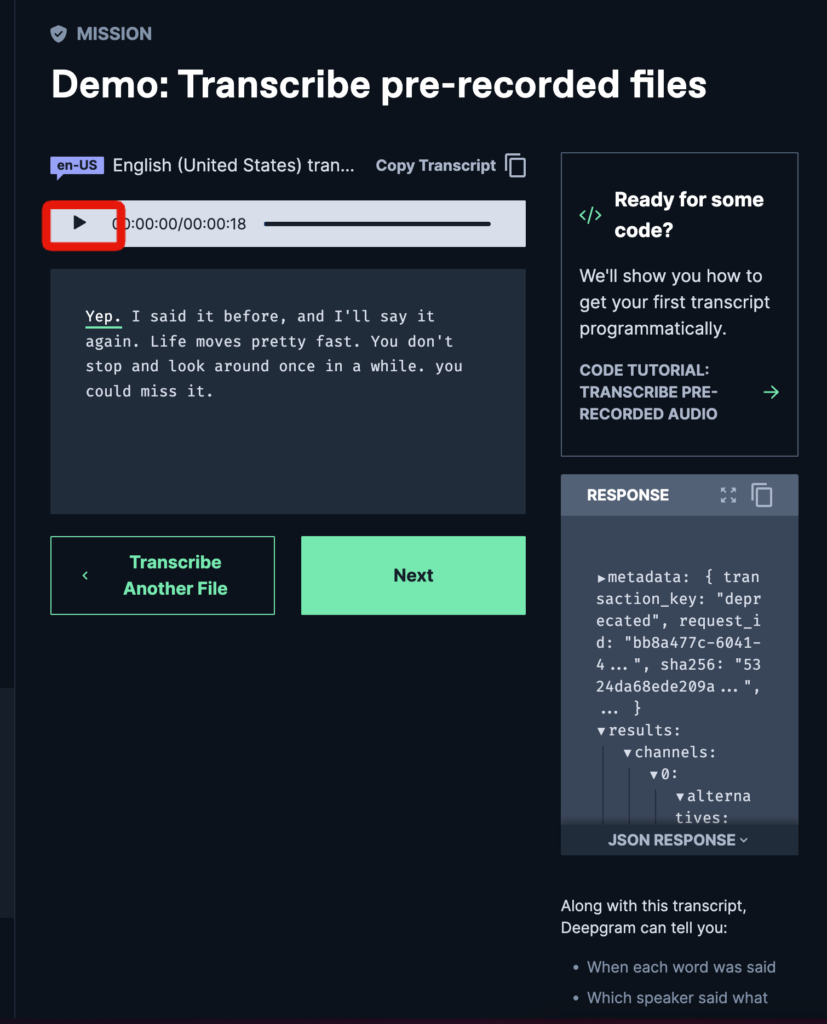
正しくテキストに変換できてました。
動画の文字起こしから感情分析まで自動化したい方は、以下の記事もご覧ください。
Speech understanding(音声理解)
音声理解に関しては、Play Ground を通じて利用可能です。
先程の登録では、As Pay You Goプランに登録しているので、200ドル分のクレジットが付与されています。
まずは以下のリンクから、PlayGroundにアクセスします。
この画面になったら、音声ファイルを選びます。自信でアップロードもできますが、今回は用意されているファイルを選びます。
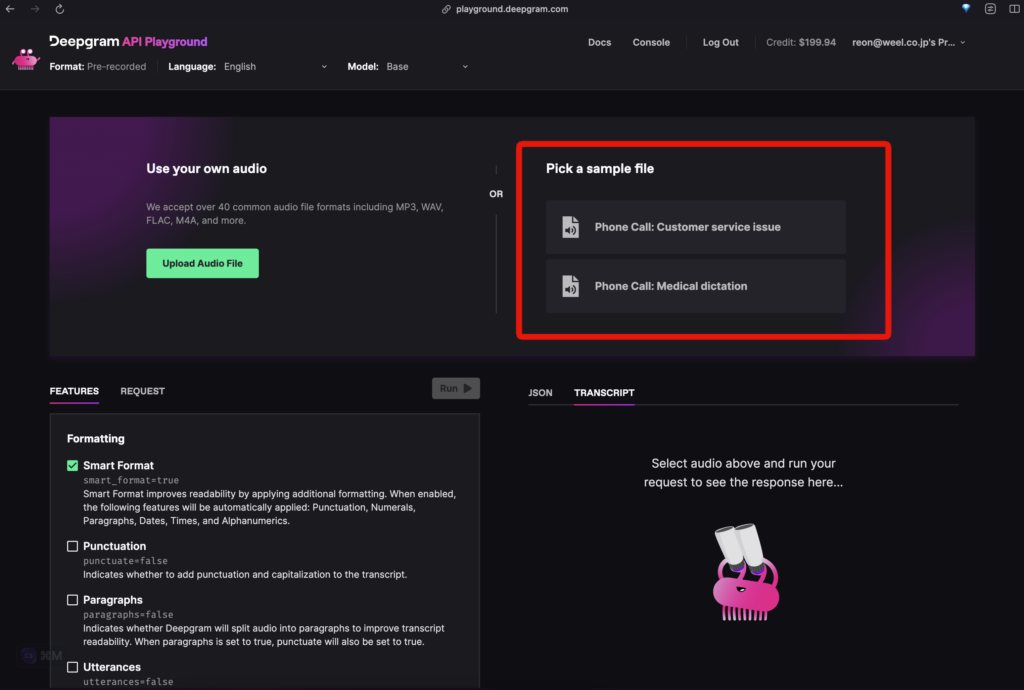
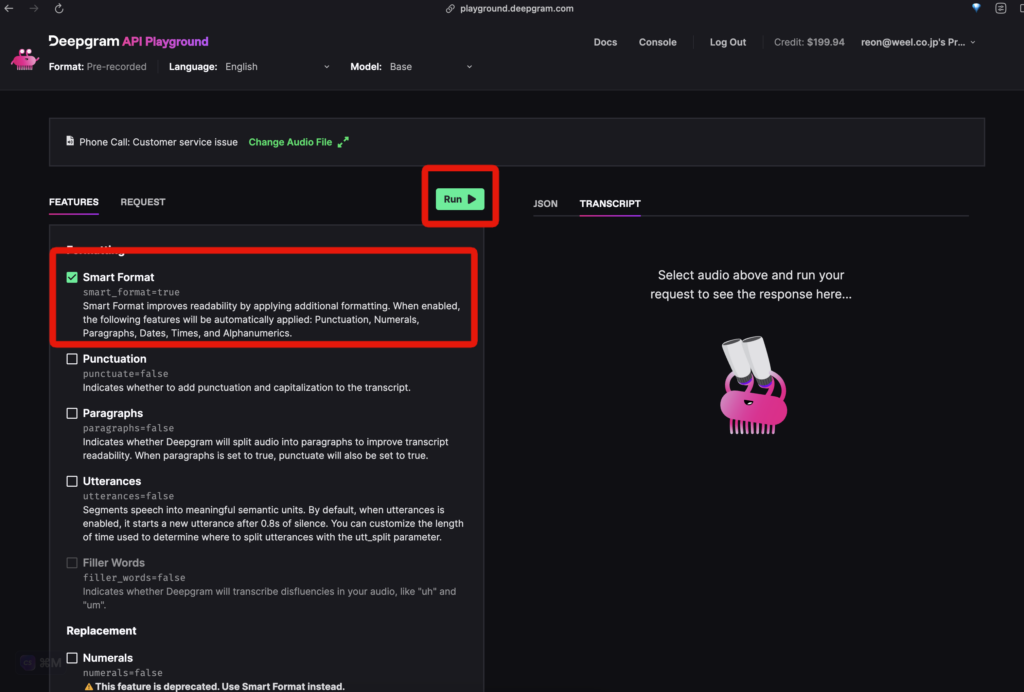
次に、音声に対して行いたいタスクを選びます。今回は「Smart Format」を選択し「Run」をクリック。
これを選択すると、音声から変換したテキストに、句読点や数字を付けて読みやすくするんだとか。
実行するとこのようになります。実行結果のすべてを載せたかったのですが、長文すぎたのでキャプチャだけです。
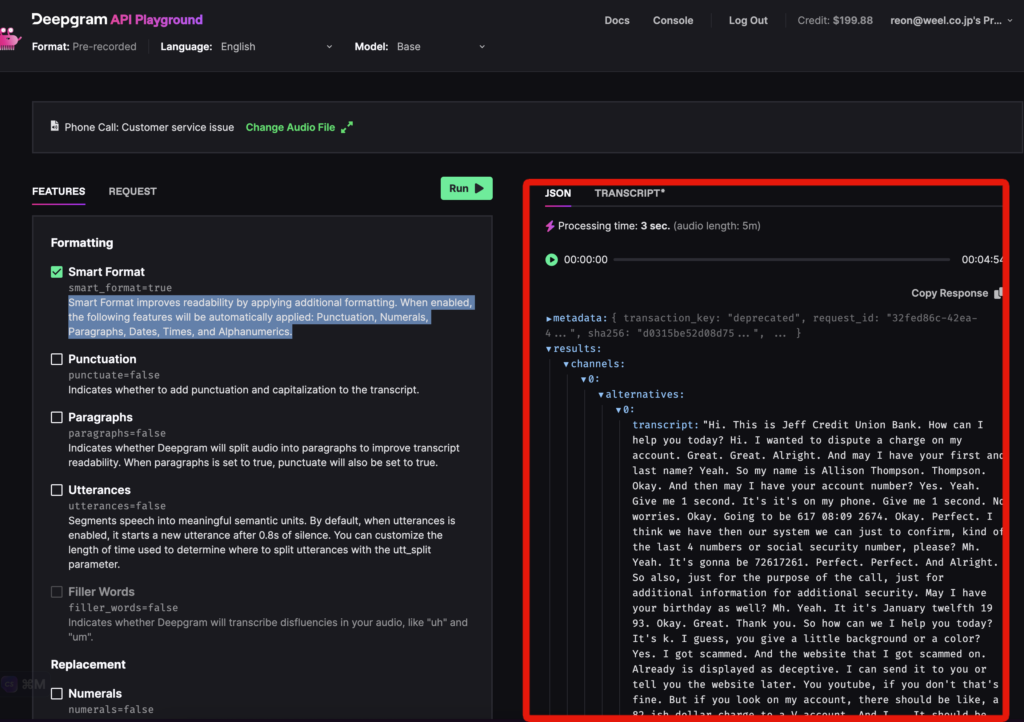
ちなみにレスポンスには以下のような情報が含まれています。
- transcript(トランスクリプト):処理された音声セグメントに対するテキストです。
- confidence(信頼度):0から1までの浮動小数点値で、トランスクリプトの全体的な信頼性を示します。値が大きいほど信頼度が高いです。
- words(単語配列):トランスクリプト内の各単語に関する情報が格納された配列です。
今回は、フォーマッティング(文章の整形)を試しました。
他にも、リプレースメント(置換)や推論などもあるみたいなのでぜひ色々試してみてください。
なお、音声を手掛かりに状況理解までこなすLLMについて知りたい方はこちらをご覧ください。
→【Qwen-Audio】音声だけで状況認識や多言語翻訳ができるアリババ産LLMを使ってみた
生成AI搭載の自動議事録作成ツールを比較したい方は、以下の記事もご覧ください。


