
OpenAI Whisperとは?文字起こし・音声認識ライブラリの使い方を解説

WEELメディア事業部AIライターの2scです。
みなさん、OpenAIが無料公開している音声認識モデル「Whisper」をご存知ですか?このWhisperは、日本語を含む98言語の識別・文字起こし・音声英訳ができる優れものなんです!しかも有料のAPI版が出ていて、そちらならインストールなしで使えてしまいます。
当記事では、そんなWhisperのスペックや使い方について徹底解説!さらに使い方のパートでは、文字起こしの結果を実演付きでお届けします。
- 高精度で文字起こしが可能
- 多言語に対応
- 低価格で利用可能
完読いただくと、議事録や字幕の作成から解放されるかも……
ぜひ最後までご覧ください!
\生成AIを活用して業務プロセスを自動化/
文字起こしができる「Whisper」とは?
OpenAIが送る「Whisper」は音声認識モデル、つまり文字起こしができるAIです。そのすごいところは、というと……
● ChatGPT同様、汎用性・理解力に優れた基盤「Transformer」を搭載
● 98言語の識別・文字起こし・音声英訳が単一のモデルで実行可能
● 68万時間分の多言語音声データを学習していて、高精度
以上のとおり、文字起こし機能にとどまらないマルチタスクモデルとなっています。そんなWhisperには2024年12月時点で、以下2つのバージョンが存在します。
- GitHub版:2022年9月公開、無料で使える
- API版(whisper-1):2023年3月公開、有料だが高精度&インストール不要
次の項目でより詳しく、Whisperのスペックをみていきましょう!
Whisperの技術的な仕組み
Whisperは大規模教師あり事前学習を用いて音声処理を行います。特定のデータセットに合わせた微調整を必要とせずに、様々なドメイン、タスク、言語において正確に音声処理することを目指しています。
Whisperは、インターネット上の音声とそれに対応するトランスクリプトから構築された、多様で広範な音声データセットを用いて学習されています。 このデータセットは、68万時間の音声データで構成されており、そのうち11万7000時間は英語以外の96言語をカバー。
また、12万5000時間はX→英語の翻訳データを含んでいます。 データセットの規模は、Whisperのパフォーマンスにとって非常に重要であり、データセットのサイズが大きくなるにつれてパフォーマンスが向上することが確認されています。
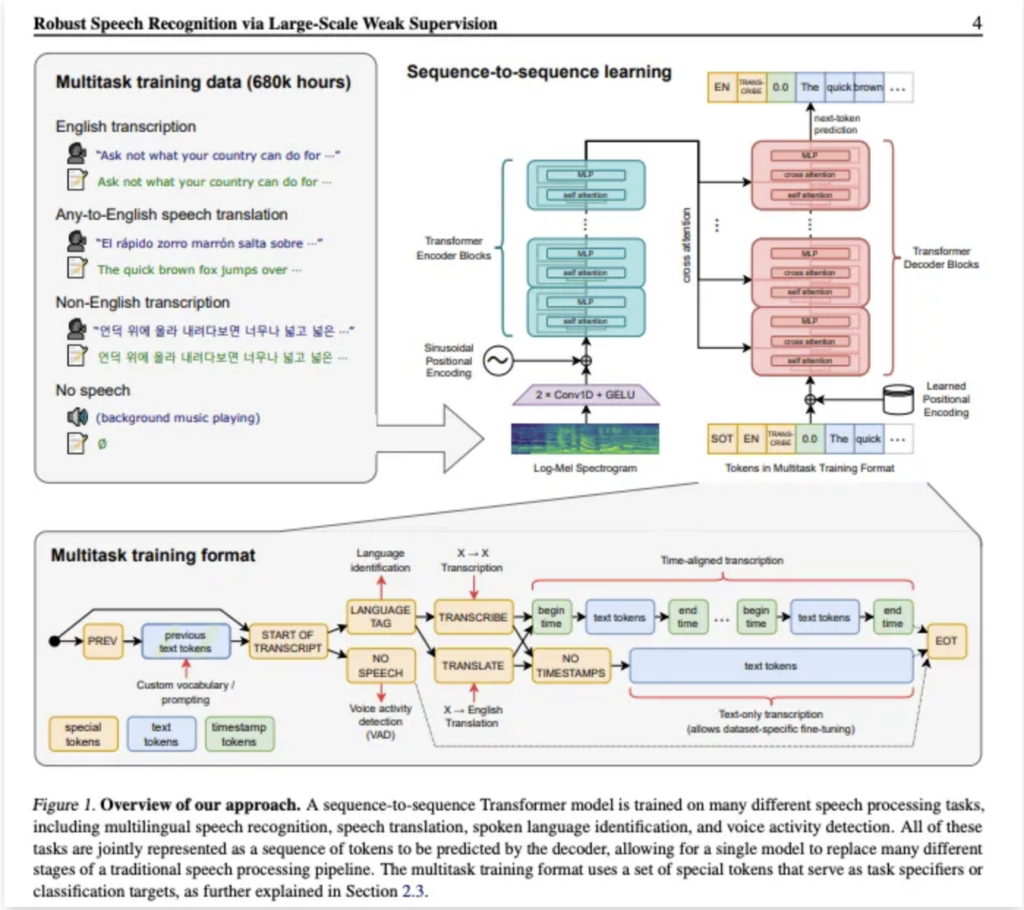
エンコーダ・デコーダ Transformerモデル
Whisperではエンコーダ・デコーダ Transformerモデルを採用しており、音声は16,000 Hz にリサンプリングされ、25ミリ秒のウィンドウと10ミリ秒のストライドで80チャンネルの対数振幅メルスペクトログラム表現が計算されます。
また、エンコーダはこの入力表現を処理し、デコーダは音声の条件付き言語モデルとして、より長い範囲のテキストコンテキストを使用して曖昧な音声を解決。
さらに、すべてのタスクと条件付け情報は、デコーダへの入力トークンシーケンスとして指定されます。これにより、単一のモデルで従来の音声処理パイプラインの多くの異なる段階を置き換えることができます。
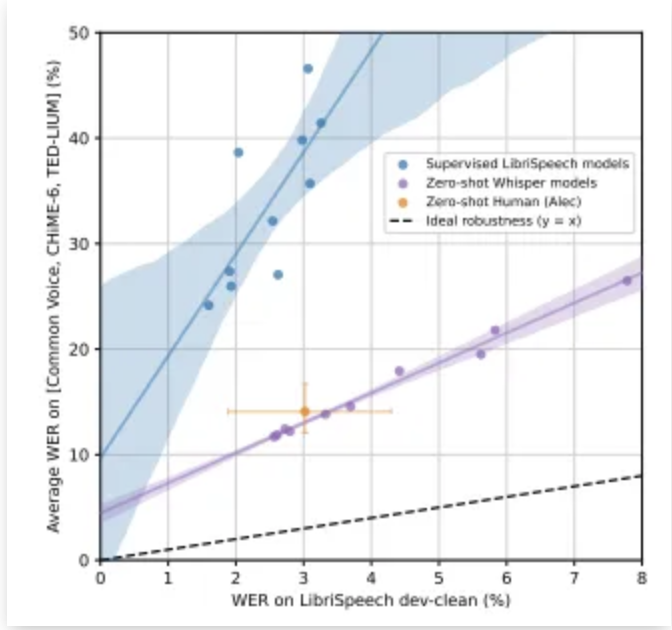
ゼロショット性能
Whisperのゼロショット性能は非常に高く、特定のデータセットに追加のファインチューニングを施さなくても、多言語の音声認識や翻訳タスクで良好な結果を示します。
この高い性能は、マルチタスク学習によって異なるタスク間の相互作用が効果的に活用されていること、またTransformerアーキテクチャの表現力がデータの多様性を活かしていることによって達成されます。
さらに、ノイズ耐性や多言語対応の性能は従来のモデルを上回り、音声認識技術の新たな方向性を示しています。
2025年6月時点アップデート
2024年末〜2025年春にかけて、Whisperには3つの大きなアップデートがありました。
第一に 「large-v3-turbo」 の正式リリースです。large-v3と同等の精度を保ったまま、デコーダ層は32→4層に削減され、API版・OSS版とも平均3倍の高速化が報告されています。
第二にOSS実装の大型アップデートがありました。これによってiOS・WASMビルドが安定し、Metal/Arm環境で推論が15〜25%短縮されています。
そして三つ目は、faster-whisper 1.1系列の登場です。batched inference・VADの再設計によってCPUでも最大 4× のスループットと大幅なメモリ削減を達成し、large-v3-turboにも正式対応しています。
これらの改良によって、従来GPUが必須だった1時間超の長尺ファイルも、M1/M2 Macや中価格帯のノート PCで実用できる速度まで到達しました。
さらに、API側では2025年4月からオーディオ最大100 MB / 90分までのアップロードが順次開放され、分割スクリプト不要で長時間議事録が生成できるようになっています。


Whisperの特徴について
「Whisperは文字起こし+αができるマルチタスクモデル」という説明だけでは、いまいちピンときませんよね。そこでここからは、Whisperのスペックを具体的に掘り下げていきます。Whisperにどんなことができるのか、その底力を以下にてご覧ください。
幅広いファイル形式&言語に対応
会議の文字起こしから動画の翻訳まで、Whisperさえあれば事足ります。その証拠は以下のとおり。そう、Whisperは7種類の音声ファイルと98種類もの言語に対応しているんです!
【対応ファイル形式】
mp3 / mp4 / mpeg / mpga / m4a / wav / webm
【対応言語 / 誤認識50%未満のみ掲載】
アフリカーンス語 / アラビア語 / アルメニア語 / アゼルバイジャン語 / ベラルーシ語 / ボスニア語 / ブルガリア語 / カタロニア語 / 中国語 / クロアチア語 / チェコ語 / デンマーク語 / オランダ語 / 英語 / エストニア語 / フィンランド語 / フランス語 / ガリシア語 / ドイツ語 / ギリシャ語 / ヘブライ語 / ヒンディー語 / ハンガリー語 / アイスランド語 / インドネシア語 / イタリア語 / 日本語 / カンナダ語 / カザフ語 / 韓国語 / ラトビア語 / リトアニア語 / マケドニア語 / マレー語 / マラーティー語 / マオリ語 / ネパール語 / ノルウェー語 / ペルシア語 / ポーランド語 / ポルトガル語 / ルーマニア語 / ロシア語 / セルビア語 / スロバキア語 / スロベニア語 / スペイン語 / スワヒリ語 / スウェーデン語 / タガログ語 / タミル語 / タイ語 / トルコ語 / ウクライナ語 / ウルドゥー語 / ベトナム語 / ウェールズ語…and more !※1
したがって、Whisperひとつで……
- iPhoneで録音した会議内容(m4a)を文字に起こす
- 海外配信者のアーカイブ(mp4)を日本語に翻訳する
といったタスクがこなせてしまいます。まさに「文字起こしの十徳ナイフ」といえる、AIツールですね。
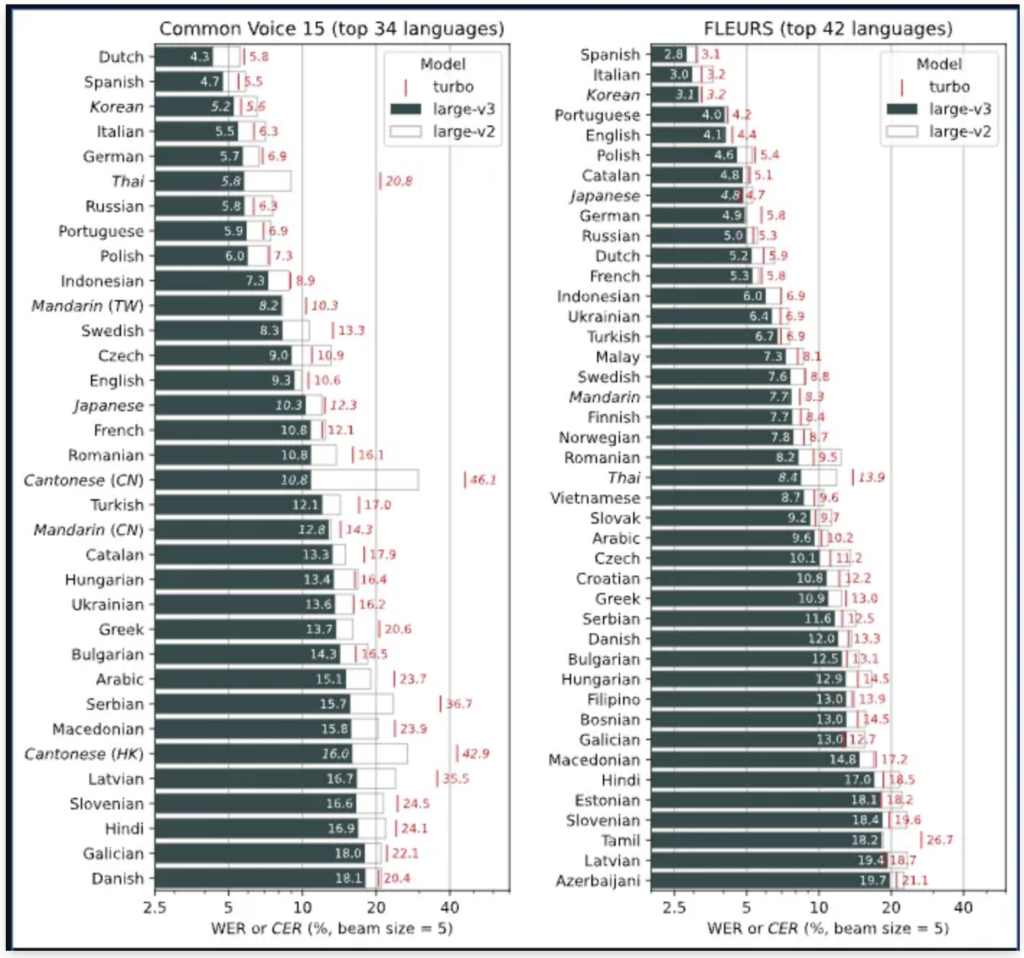
精度の異なるモデルが5つ存在
公開されているGitHub版Whisperでは、6つのモデルが選べます。それぞれモデルサイズ、つまりパラメータ数が違っていて……
- 大きなモデルほど高精度で、漢字・かなの認識が正確
- 小さなモデルほど省メモリで、処理が高速
といった性能差があります。各モデルの詳細については、下表をご覧ください。
| モデル名 | パラメータ数 | 多言語対応モデル | 英語限定モデル | 必要なGPUメモリ |
|---|---|---|---|---|
| tiny | 39 M | tiny | tiny.en | 〜1 GB |
| base | 74 M | base | base.en | 〜1 GB |
| small | 244 M | small | small.en | 〜2 GB |
| medium | 769 M | medium | medium.en | 〜5 GB |
| large | 1550 M | large | なし | 〜10 GB |
| turbo | 809M | turbo | なし | 〜6 GB |
2024年10月2日にWhisper の新バージョン「large-v3-turbo」がリリースされました。
large-v3-turboは「Whisper Turbo」モデルとして使用することが可能。
Turboモデルを使用した一部のユーザーからは、従来のモデルと比較して約3.16倍の高速化が報告されていたり、日本語の音声認識においても、従来のlarge-v2モデルよりわずかに精度が向上しているとの報告があります。
ちなみにAPI版のWhisperこと「whisper-1」では、largeモデル(large-v2)が用意されています。こちらも基本は、GitHub版のlargeモデルと変わりません。ただ、有料ならではの利点もあって……
- インストールが要らない
- 処理速度が優れている
- 推論プロセスが最適化されている
といった、API版限定の恩恵が受けられるんです。要件に応じて使い分けられるのがうれしいですね。※2
また、それぞれのモデルには層・幅・ヘッド数が定められています。
- Tiny:4層、幅384、ヘッド数6
- Base:6層、幅512、ヘッド数8
- Small:12層、幅768、ヘッド数12
- Medium:24層、幅1024、ヘッド数16
- Large:32層、幅1280、ヘッド数20
- Turbo:4層、幅1280、ヘッド数20
それぞれの「層」「幅」「ヘッド数」は、モデルの内部構造に関する仕様であり、主にTransformerアーキテクチャの性能を左右する要素です。
- 層:Transformerモデルには、情報を処理するための「エンコーダ」と「デコーダ」の層が存在します。層の数は、モデルが処理できる情報の深さや複雑さに影響。
- 幅:幅とは、Transformerにおける1つの層の中で情報を保持する次元数(埋め込み次元数)を指します。これは、1つの入力データが層内でどれだけ詳細に表現されるかどうかです。
- ヘッド数:Transformerは「マルチヘッドアテンション」という仕組みを使って情報を処理します。ヘッド数は、このアテンションの計算を並列に行う単位の数を指します。
Turboモデルでは、層が減少したため計算量の大幅な削減が、高速化の鍵となっています。また、幅やヘッド数は従来と同じため、表現力や精度は可能な限り維持されています。
日本語の文字起こしが得意
さてここまで、Whisperの強みを紹介していきました。ですが実際のところ、日本語での文字起こし精度はいかほどなのでしょうか?
「どうせWhisperは海外のAIツールなんだから……」とお思いの方、心配はご無用です。
なんとlarge-v2モデルの場合、日本語での文字起こし精度は全98言語のなかで6位!5位のドイツ語に続いて、「単語誤り率 / WER」が5.3%に抑えられています。詳細は下のグラフをご覧ください。
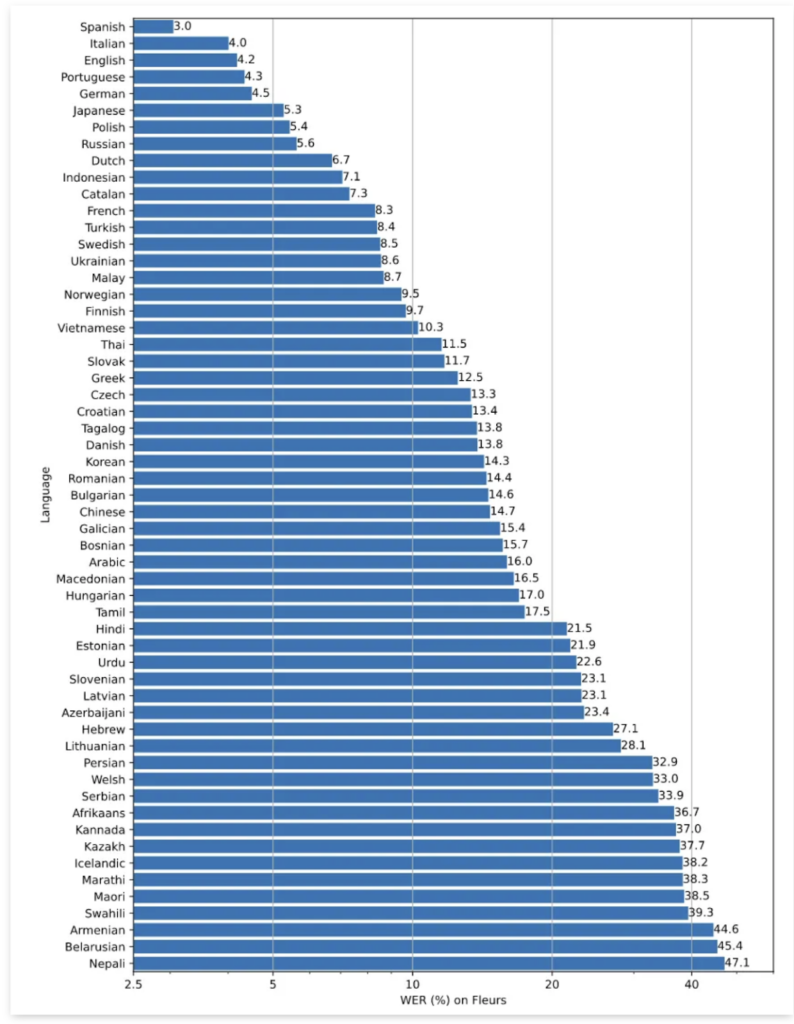
ちなみに、API版での実装が控えている改良版・large-v3では、日本語の単語誤り率が4.9%まで削減されています。公開が待ちきれませんね。※3
AIで議事録・文字起こしを自動化したい方は、以下の記事もご覧ください。

一度に文字起こしできるのは25MBまで
万能選手のWhisperですが、一つだけ欠点があります。それはファイルサイズの制限です。2024年1月時点では、25MB(動画換算で25分)以下の音声ファイルしかアップロードができないのです。
ただOpenAI公式は、制限を回避する方法も公開してくれています。Whisperを使って、25分を超える音声データを文字起こししたい場合は……
● Pythonのパッケージ「Pydub」と「ffmpeg」を使う
● 無音部分で音声を分割する
● 分割後のファイルは、時系列順に番号を振る
といった処理を適宜、行うとよいそうです。
なお、同OpenAIのAPIで使える埋め込みモデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

労働時間の短縮が可能
Whisperが高精度な文字起こしを行ってくれるため、会議があれば作らなければならなかった議事録作成にかかる時間を大幅に削減できます。議事録作成の時間以外にも、話した声をリアルタイムで文字起こしし、翻訳することもできます。
翻訳する言語によって、文字起こしの精度はバラバラですが、日本語や英語であれば精度は高いです。Whisperを活用することで、業務にかかる時間を短縮しやすくなります。
さらには、言語の壁を超えたコミュニケーションが取りやすくなるため、より効率的な業務を行えるメリットがあります。
Pythonなどの実行環境を構築する必要がある
Whisperを利用するためには、PythonやGitなどの実行環境を用意しなければなりません。実行環境を用意するためには、コマンドをいくつか実行します。
必要なコマンドはインターネット上のものを参考にすれば誰でもわかるようになっているため、スムーズにいけば環境構築に時間はあまりかかりません。
しかし、エラーが発生した場合は対処の必要がありますが、この方法は自分で考える必要があるケースがほとんどなので、専門的な知識がない方が行うのは難しいかもしれません。場合によりますが、Whisperを使うためには専門的な知識が必要になることもあることを念頭に置いてもらう必要があると言えるでしょう。
Whisper APIのメリット
Whisper APIを使用するメリットとしては次の2つが挙げられます。
- 安価に利用できる
- 音声認識の精度が高い
それぞれ解説します。
安価に利用できる
まずWhisper APIは1分あたり1円以下と非常に安価に利用可能です。100万文字あたり約15ドルです。
例えばGoogle CloudのWaveNet音声は100万文字あたり16ドル、Microsoft Azureのニューラル音声は100万文字あたり16ドルになっています。
Whisper APIの他のTTSを比較するとそこまで安価ではないのでは?と感じるかもしれませんが、次の「音声認識の精度が高い」というメリットを踏まえると安価と言えます。
音声認識の精度が高い
Whisper APIの音声認識精度は非常に高く、日本語では精度94%であり、ベンチマークではGoogle CloudやMicrosoft Azureよりも高性能という結果。
かなりの高精度で1分あたり1円以下であれば、非常にメリットの大きいAPIなのではないでしょうか。
Whisper APIのデメリット
一方でWhisper APIのデメリットもあります。
- 実行環境の構築が必要
- データ漏洩の可能性
それぞれ解説をします。
実行環境の構築が必要
まずWhisper APIを使うには、実行環境の構築が必要となります。google colaboratoryでも実装ができるようになっているので、環境構築のハードルは下がっていますが、それでも既存サービスに比べるとデメリットになり得ます。
これまでAPIを使ったことがないけど、Whisper APIを使ってみたいな…という方は、ぜひ本記事を最後までお読みいただければ、実行環境の構築も理解できるでしょう。
データ漏洩の可能性
また、音声データとはいえOpenAIにデータを渡すことになるので、データ漏洩の可能性は否めません。
Whisper APIで音声データを扱う場合には、機密情報が含まれていないかなどを確認することが重要です。また、データ漏洩ではありませんが、権利で守られている音声データを扱い、公開してしまうと権利の侵害につながる可能性もありますので、十分に注意が必要です。
Whisperの料金体系(GitHub版は無料で使える)
Whisperを使う際は、以下の2つのパターンがあります。
- API版Whisper
- GitHub版Whisper
GitHub版Whisperは、無料で利用が可能です。
API版のWhisper「whisper-1」では、処理した音声ファイルの時間に応じて利用料金が発生します。具体的には……
- 音声ファイル1分につき、0.006ドル(約0.86円)
- 「transcriptions / 文字起こし」「translations / 英訳」の処理で料金が発生
- 支払いはクレジットカードにのみ対応
となっています。※4※5
月額シミュレーション例
Whisper APIは$0.006/分が基本料金ですが、ここでは、1ヶ月(30日間)毎日同じ分数を処理した場合の料金概算をまとめます。
| 1日の処理時間 | 30日間合計(分) | 月額 | 想定ユースケース |
|---|---|---|---|
| 30分 | 900分 | $5.40 | 毎日30分の会議記録 |
| 60分 | 1,800分 | $10.80 | 社内スタンドアップ、顧客MTG |
| 120分 | 3,600分 | $21.60 | Podcast、ウェビナー編集 |
Tipsとして、response_format=”json”を指定すると、文字起こしテキストの後処理を省くことができ、総作業コストをさらに圧縮することができます。
Whisperのライセンス
WhisperではMIT Licenseのもと、商用利用等が許可されています。具体的には……
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
以上のとおり!個人から企業まで、気軽にWhisperが使えそうですね。
API版Whisperの使い方(Pythonインストール必要)
ここからはWhisperで文字起こしを実演しながら、その使い方をお伝えしていきます。当記事ではGoogle Colaboratory(以下、Colab)のPython環境上で、API版 / GitHub版の両方を試してみました。
ちなみにWhisperに文字起こしさせた音声は……
- iPhoneで録音したm4aファイル
- 「洗濯 / 選択」「胎児 / 退治 / 対峙」など、同音異義語を原文に含む
このように、Whisperの実用性が測れる内容となっています。原文については、以下をご覧ください。
むかしむかしあるところに、おじいさんとおばあさんが住んでいました。ある日、おじいさんは山にしばかりに、おばあさんは川に洗濯にいきます。おばあさんが川で洗濯をしていると、上流から桃が流れてきました。おばあさんは洗濯を中断して、桃を拾うという選択をします。そして持ち帰った桃をおじいさんと共に食べようとしたところ……桃の中から、胎児が出てきたのです。おじいさんとおばあさんは、その胎児に桃太郎という名前を授けました。そして桃の中にいた胎児・桃太郎は、すくすくと育っていきます。ある日、彼らの住む村の近くで鬼が悪さをしている、という話を聞いた桃太郎。彼は鬼退治を決意します。それに感銘を受けた老夫婦は、きびだんごを桃太郎に与えて送り出します。その道中、桃太郎はきびだんごで犬・猿・雉を従えつつ、鬼の本拠地・鬼ヶ島に到着しました。鬼と対峙した桃太郎は、犬・猿・雉との連携を大事にしつつ、鬼を退治します。
ではまず、API版Whisper「whisper-1」の使い方からみていきましょう!
APIキーの取得
WhisperやGPT-4など、OpenAIのモデルをAPI経由で使いたい場合はキーが必要です。このAPIキーは……
- カード番号を登録したOpenAIアカウントでのみ発行できる
- 1つのAPIキーで、全モデルが呼び出せる
という仕様になっています。当記事では、登録済みのアカウントでAPIを発行するところから、説明していきます。
まずは以下のリンクから、OpenAIのAPIキー管理画面にアクセスしてみてください。
APIキー管理画面:OpenAI Platform
リンクにアクセスすると……
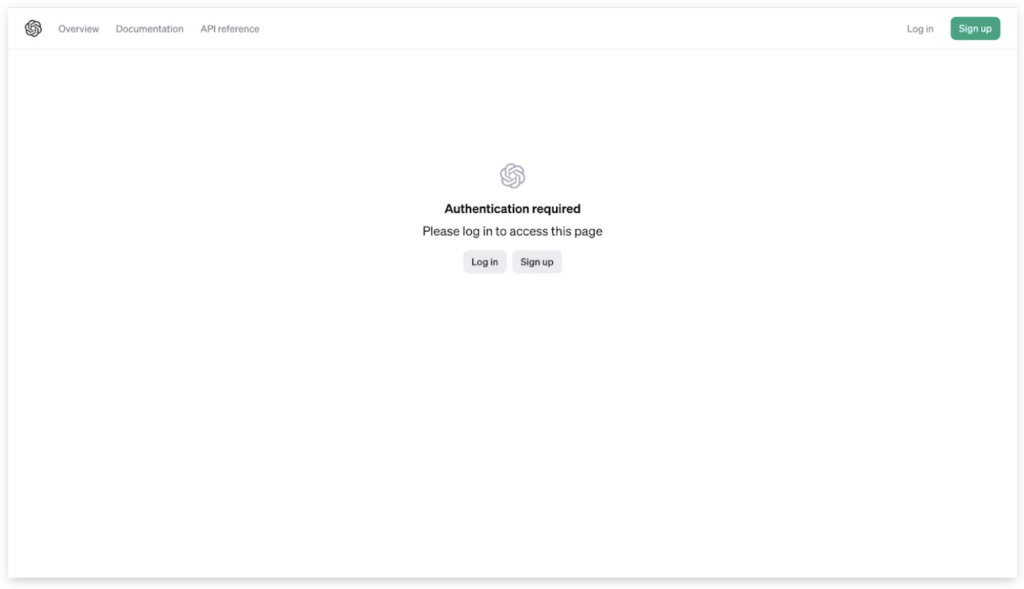
このように、ログイン / サインアップの画面が出てきます。今回は「Log in」をクリックして、登録済みのメールアドレス&パスワードを入れていきましょう。
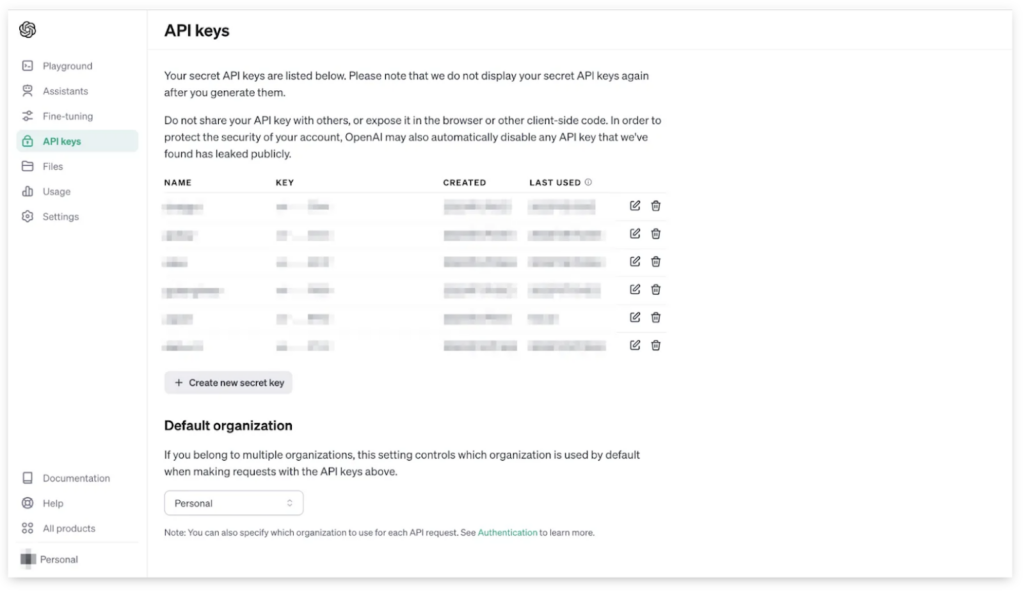
管理画面が現れましたね。過去に発行したAPIキー(モザイク済み)がずらりと並んでいて、その下に「+ Create new secret key」と書かれたグレー色のボタンが付いています。そのボタンをクリックしてみましょう!
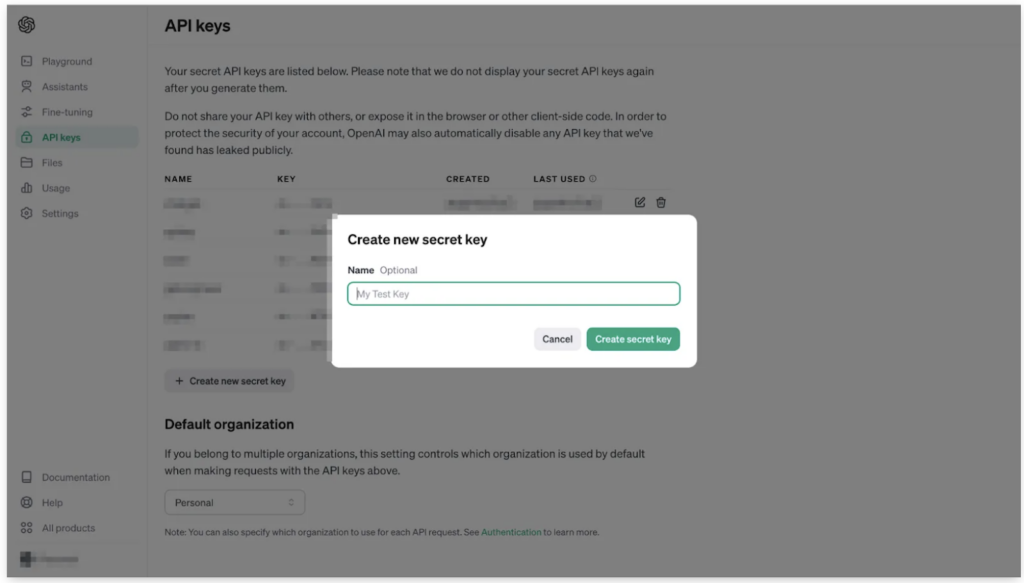
すると、新しいAPIキーの発行画面がポップアップで表示されます。では早速、画面中央部のテキストボックスに適当なAPIキーの名前を入れて、緑色の「Create secret key」ボタンを押してみましょう。
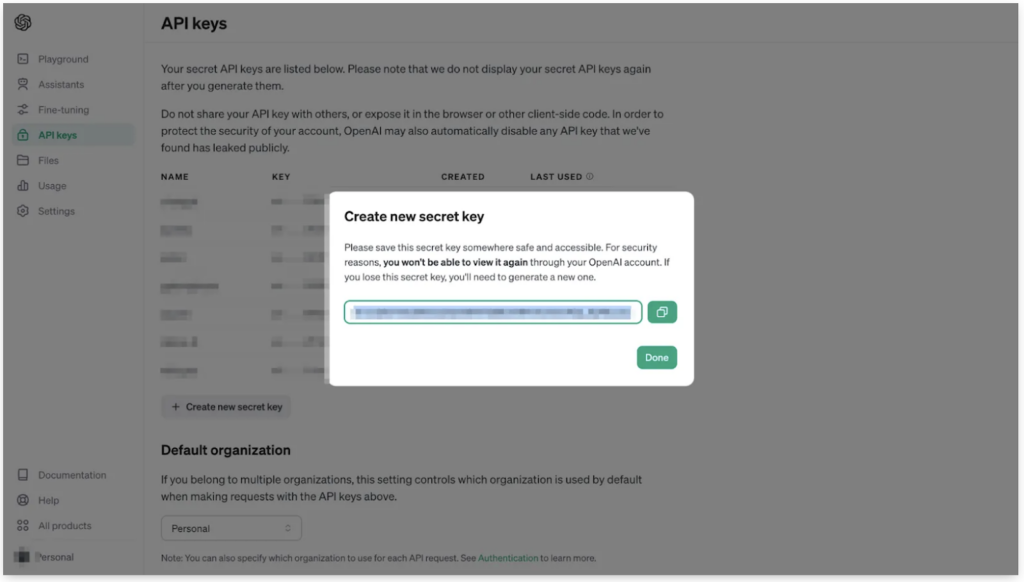
「Create secret key」を押すとこのように、新たなAPIキーが発行されます。あとはテキストボックス右側のボタンをクリックすれば、APIキーがコピーできます。
APIキーが表示されるのは一回限りです。メモ帳等へのペースト&保存を、お忘れなく。
ライブラリの準備&APIキーの入力
次に、ColabのPython環境上での操作に移ります。まずは、以下の3つが実行環境にインストールされているかをご確認ください。
- OpenAI Pythonライブラリ(openai)
- OSモジュール(os)
- getpassモジュール(getpass)
今回はデフォルトの実行環境に存在しない、OpenAI Pythonライブラリのインストールを実演します。といっても、以下のソースコードを実行するだけです。
!pip install openaiこちらを試してみると……
インストールが完了しましたね。引き続き、下記のコードを使ってAPIキーを入力していきます。
import os
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass('OpenAI API Key:')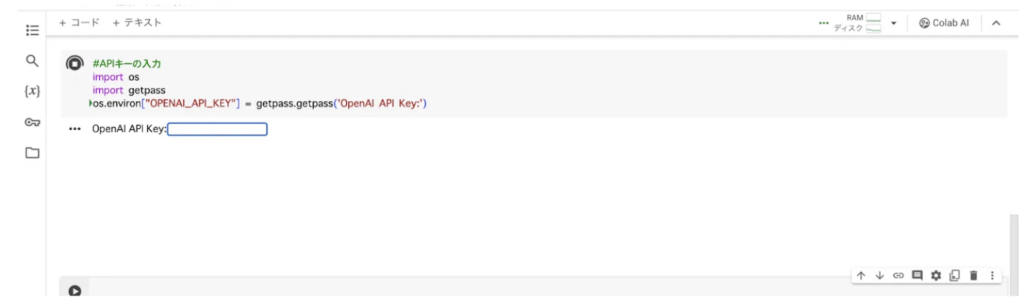
コードを実行すると、テキストボックスが現れました。ここに先ほど発行したAPIキーを入力して、Enterを押せば下準備は完了です。
API版の文字起こし精度を検証!
では早速、以下のコードを実行してAPI版Whisperを動かしていきます。
from openai import OpenAI
client = OpenAI()
audio_file= open("ファイル名.拡張子", "rb")
#transcriptions、つまり文字起こしを指定。modelはwhisper-1のみ選択可能。
transcript = client.audio.transcriptions.create(model="whisper-1", file=audio_file, response_format="text")
print(transcript)音声については、Colabの画面左側のファイルを選択して、マウス操作でアップロードしました。Whisperの実力の程はいかに……

お見事です!冒頭の部分は、正確に文字起こしができていますね。API版Whisperが返してくれた全文を以下に示します。ちなみに、青色でマーキングしているのが誤字の箇所です。
昔々あるところにおじいさんとおばあさんが住んでいました。 ある日、おじいさんは山に芝刈りに、おばあさんは川に洗濯に行きます。 おばあさんが川で洗濯をしていると上流から桃が流れてきました。 おばあさんは洗濯を中断して桃を拾うという洗濯をします。 そして持ち帰った桃をおじいさんと共に食べようとしたところ、桃の中から胎児が出てきたのです。 おじいさんとおばあさんはその胎児に桃太郎という名前を授けました。 そして桃の中にいた胎児、桃太郎はすくすくと育っていきます。 ある日、彼らの住む村の近くで鬼が悪さをしているという話を聞いた桃太郎。 彼は鬼退治を決意します。 それに感銘を受けた老夫婦はきび団子を桃太郎に与えて贈り出します。 その道中桃太郎はきび団子で犬、猿、キジを従いつつ鬼の本拠地鬼ヶ島に到着しました。 鬼と胎児した桃太郎は犬、猿、キジとの連携を大事にしつつ鬼を胎児します。
やはりWhisperをもってしても、同音異義語の判別は難しいようですね。これは日本語特有の欠点かもしれません。
音声の英訳も試してみた
続いて先ほどのコードを一部変更した下記のコードを使って、音声の英訳も試してみます。変更箇所は#の部分、コメントアウトをご覧ください。
from openai import OpenAI
client = OpenAI()
audio_file= open("ファイル名.拡張子", "rb")
#translations、つまり音声の英訳を指定。modelはwhisper-1のみ選択可能。
transcript = client.audio.translations.create(model="whisper-1", file=audio_file, response_format="text")
print(transcript["text"])
print(transcript)こちらを実行してみると……
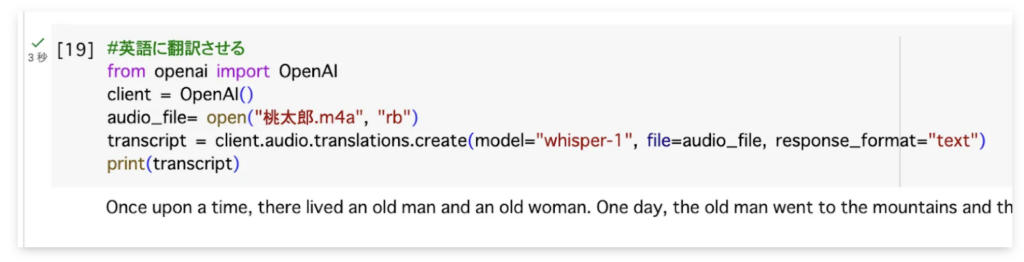
Once upon a time, there lived an old man and an old woman. One day, the old man went to the mountains and the old woman went to the river to do the laundry. While the old woman was doing the laundry in the river, a peach flowed from the upstream. The old woman stopped doing the laundry and picked up the peach. And when she was about to eat the peaches she brought home with the old man, a pig came out of the peach. The old man and the old woman gave the pig the name Momotaro. And the pig in the peach, Momotaro, grew up quickly. One day, Momotaro heard that a demon was doing evil near the village where they lived. He decided to exterminate the demon. The old couple, impressed by this, gave Momotaro a kibidango. On the way, Momotaro arrived at the demon’s home, Onigashima, following the dog, the monkey, and the pig. After exterminating the demon, Momotaro took good care of the dog, the monkey, and the pig, and exterminated the demon.
それらしい英文が返ってきました。DeepLで再び日本語に戻すと……
昔々、あるところに老人と老婆が住んでいた。ある日、老人は山へ、老婆は川へ洗濯に行きました。老婆が川で洗濯をしていると、上流から桃が流れてきた。老婆は洗濯の手を止め、桃を拾った。そして、持ち帰った桃を老人と一緒に食べようとすると、桃の中から豚が出てきた。老人と老婆はその豚に桃太郎という名前をつけた。桃の中の豚、桃太郎はすくすくと育ちました。ある日、桃太郎は自分たちの住む村の近くで鬼が悪さをしていると聞きました。桃太郎はその鬼を退治することにした。それに感心した老夫婦は、桃太郎にきびだんごを与えた。途中、桃太郎は犬、猿、豚を追って鬼の住む鬼ヶ島に着いた。鬼を退治した桃太郎は、犬、猿、豚を大切にし、鬼を退治した。
本来「胎児 / fetus」であった箇所が、「豚 / pig」に置き換わってしまっています。
ただそれ以外の部分は、程よくまとめてくれていました。回りくどい表現を避けたいときには、translationsからの再和訳がおすすめです。


GitHub版Whisperの使い方
ここからは、無料で使えるGitHub版Whisperについても、文字起こしを試していきます。こちらも、Colab上のPython環境に先ほどの音声をアップロードして実験しています。まずは推奨環境から、詳しくみていきましょう!
GitHub版Whisperで必要なPCのスペック
GitHub版Whisperを動かすのに必要なPCのスペック・環境は……
◼︎Pythonのバージョン
Python 3.8以上
◼︎使用ディスク量
10.5 MB
◼︎RAMの使用量
1~10GB
以上のとおりです。次項にて、この要件を満たすColabのランタイムをみていきましょう!※6
インストールなどの下準備
GitHub版Whisperを使う場合、Pythonのライブラリは一切不要です。
ただ、大掛かりなモデルを実行環境にインストールして動かすため、ランタイムのタイプを「T4 GPU」に変更しなくてはいけません。まずはColabの画面上部、「ランタイム」をクリックしてみましょう!
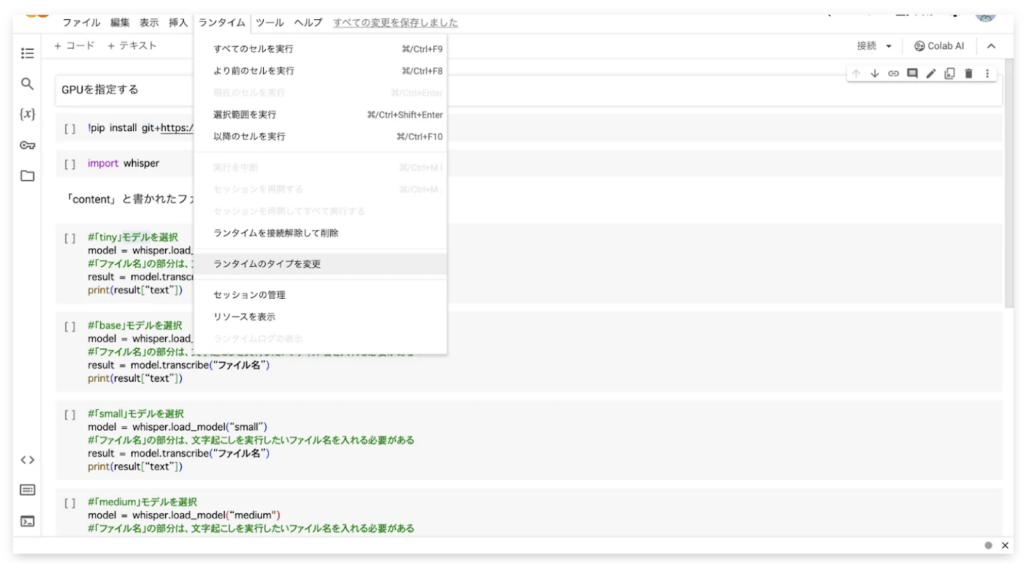
するとこのように、ポップアップが表示されます。ここで「ランタイムのタイプを変更」をクリックしてみてください。
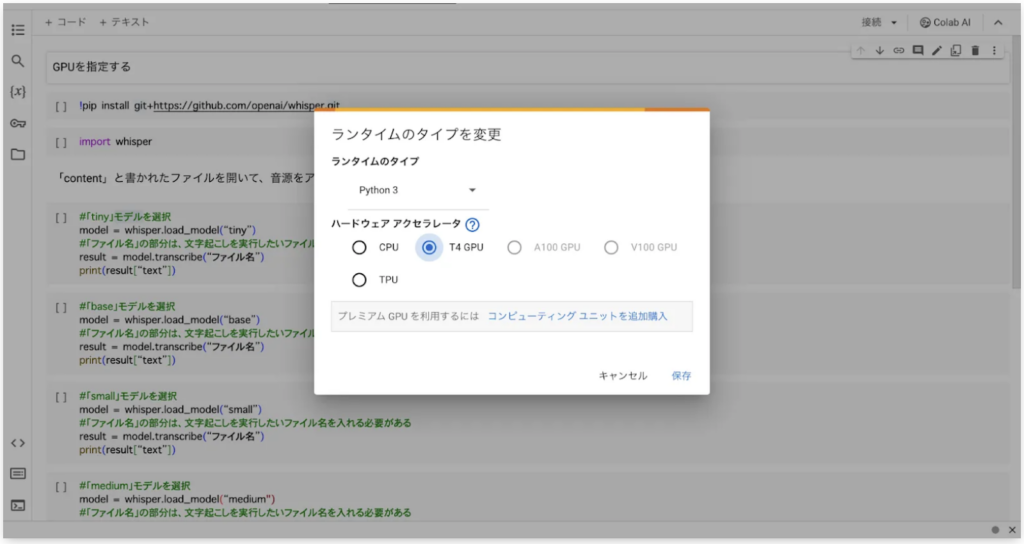
以上のように、CPU / T4 GPU / TPUなどのプロセッサ選択画面が出てきます。あとはデフォルトのCPUから「T4 GPU」に変更すれば設定完了です。
続いて下記のコードを実行して、Whisperを実行環境上にインストールしていきます。
!pip install git+https://github.com/openai/whisper.git
これでWhisperを動かす準備は整いました。次は音源のアップロードについても、みていきましょう!
音声ファイルのアップロード
続いてAPI版同様に、マウス操作で音源をアップロードしていきます。まずはColabの画面左側のファイルを選択してみましょう。
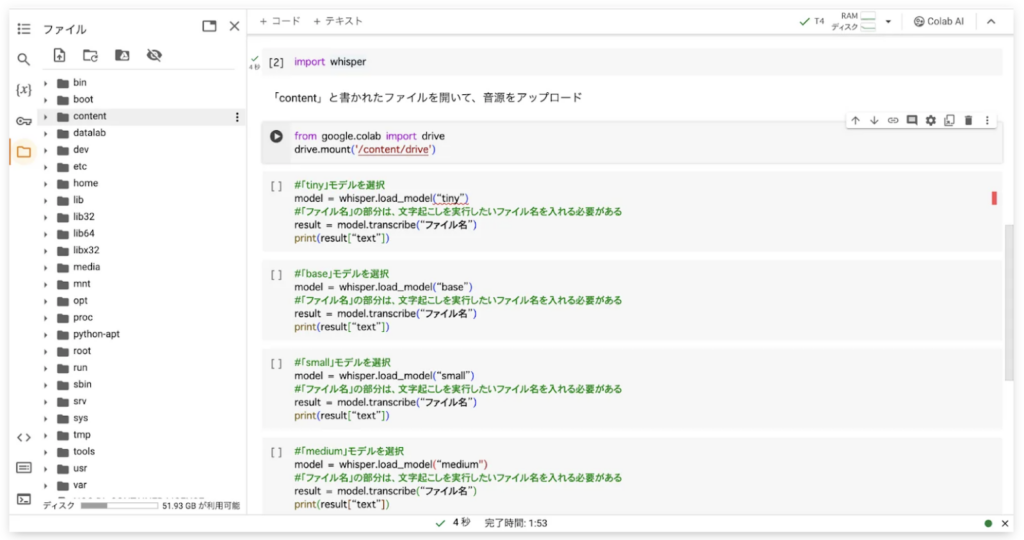
このように、Whisperを構成しているファイルがずらりと並んでいます。音源をアップロードするのは、「content」内の「sample_data」ファイルです。
カーソルを合わせると現れる「⋮」をクリックして、音源をアップロードしてみてください。
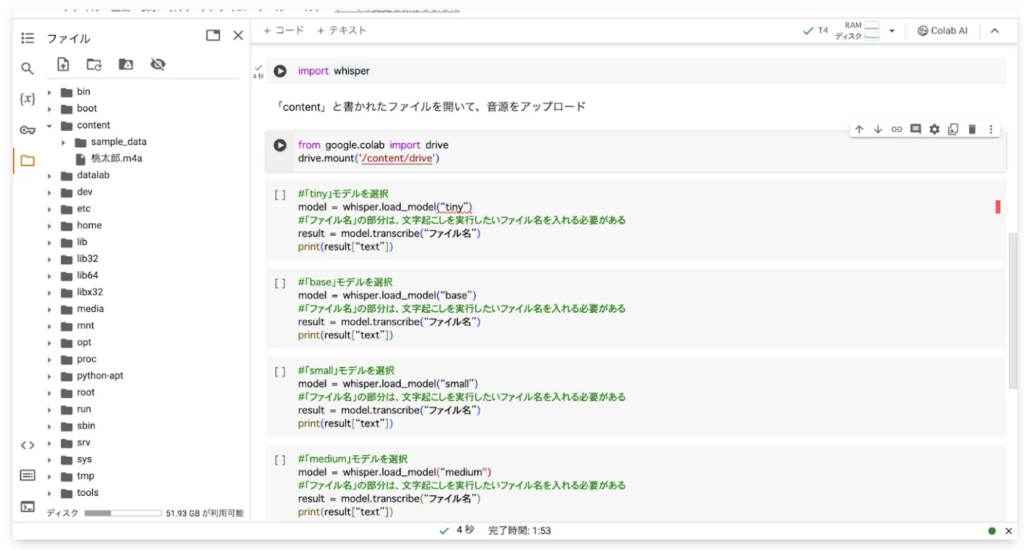
上の画面左側のように音声ファイルが格納できれば、アップロード成功です。
5モデルの文字起こし精度を検証!
GitHub版Whisperの使い方は、API版よりもシンプルです。下記のコードを実行するだけで、文字起こしができてしまいます。
import whisper
#モデル名はtiny / base / small / medium / large / turboのいずれか
model = whisper.load_model("モデル名")
result = model.transcribe("ファイル名.拡張子")
print(result["text"])ちなみにmodel.transcribe()の部分には……
- verbose=True:処理の過程を可視化
- language=”ja”:日本語として認識
- task=”translate”:英訳して文字起こし
といった変数・オプションが追加できます。API版と基本は同じですね。
では次の項目から、サイズが小さい順に文字起こしの精度をみていきます。まずはtinyモデルの結果からご覧あれ。
Whisperのtinyモデルを使ってみた
早速、オプションなしでtinyモデルを試してみました。以下のように、コードを実行すると……
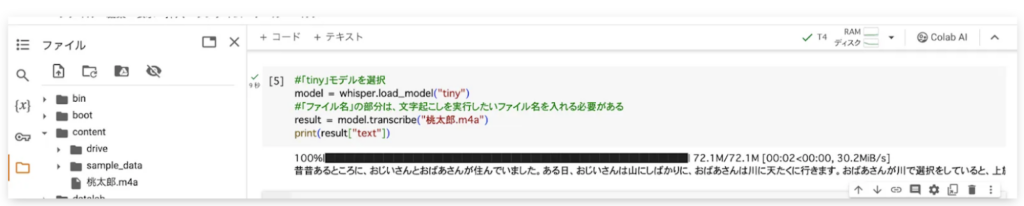
昔昔あるところに、おじいさんとおばあさんが住んでいました。ある日、おじいさんは山にしばかりに、おばあさんは川に天たくに行きます。おばあさんが川で選択をしていると、上旅からももが流れてきました。おばあさんは選択を中断してももひろうという選択をします。そして、もちかえったももおおじいさんと一つもりたべをとしたところを、ももの中から大事が出てきたのです。おじいさんとおばあさんはその体重にももたろうという名前を撮ってました。そして、ももの中に行って体重、ももたろうは、すくつくとすかっていきます。ある日、彼らのスム、むやの近くで、お人が悪さをしているという話を聞いたももたろう。彼はおりたい字を決しています。それに関名を受けたローフーは、キビ団語をももたろに与えておくりでします。その道中、ももたろはキビ団語で、いる、さる、気字をしたがいつつ、おりの本気ち。おりが島にとおちゃくしました。おりと体重したももたろうは、いる、さる、気字との連携を大事につつ、おりを体重します。
わずか2秒で上記の文章が返ってきました。ただ、ご覧のとおり誤字が多く、文字起こしになっていません。
Whisperのbaseモデルを使ってみた
次に、ひと回り大きいWhisperのbaseモデルでも、文字起こしを試してみます。
昔、昔、あるところに、おじいさんとおばあさんが住んでいました。ある日、おじいさんは山にしばかりに、おばあさんは川に選択に行きます。おばあさんが川で選択をしていると、上流からももが流れてきました。おばあさんは選択を中断して、もも広うという選択をします。そして、持ち帰ったももお、おじいさんと共に食べようとしたところ。ももの中から、体次が出てきたのです。おじいさんとおばあさんは、その体次に、ももたろという名前をさつけました。そして、ももの中に行った体次、ももたろは、すくすくと育っていきます。ある日、彼らの住む、むらの近くで、おにがわるさをしていうという話を聞いたももたろを、彼はおに体次を決意します。それに関名を受けたロフフは、キビダンゴをももたろに与えておくりです。その道中、ももたろはキビダンゴで、いぬ、さる、生地をした街つつ、おりの本拠地、おにがしまにとお着しました。おにと体次したももたろは、いぬ、さる、生地との連携を大事に出つ、おにを体次します。
するとbaseモデルは、なんと1秒で文字起こしを終えてくれました。しかもtinyモデルと比べて、誤字が少なくなっていますね。さすが「base / 基礎」という名前だけあって、バランスが取れています。
Whisperのsmallモデルを使ってみた
さて、Whisper5モデルの中間・smallモデルの出番です。先ほどと同様にコードを実行してみると……
昔々あるところに、おじいさんとおばあさんが住んでいました。ある日、おじいさんは山にしばかりに、おばあさんは川に選択に行きます。おばあさんが川で選択をしていると、上流から桃が流れてきました。おばあさんは選択を中断して、桃を拾うという選択をします。そして、持ち帰った桃を、おじいさんと共に食べようとしたところ、桃の中から、太字が出てきたのです。おじいさんとおばあさんは、その太字に桃太郎という名前を捌けました。そして、桃の中にいた太字、桃太郎はすくすくと育っていきます。ある日、彼らの住む村の近くで、鬼が悪さをしているという話を聞いた桃太郎を、彼は鬼太字を決意します。それに勘迷を受けた老夫婦は、鬼火団子を桃太郎に与えておくりでします。その道中、桃太郎は鬼火団子で、犬、猿、騎士を従えつつ、鬼の本居地、鬼が島に到着しました。鬼と太字した桃太郎は、犬、猿、騎士との連携を大事にしつつ、鬼を太字します。
6秒かかってしまいましたが、誤字がかなり改善されています。ただ「鬼火団子」や「騎士」など、桃太郎らしからぬ単語がまだまだ混じっていますね。
Whisperのmediumモデルを使ってみた
今度はWhisperの中で2番目に大きいmediumモデルでも、文字起こしを行ってみます。結果は以下のとおりです。
昔々あるところにおじいさんとおばあさんが住んでいました。ある日、おじいさんは山にしばかりに、おばあさんは川に洗濯に行きます。おばあさんが川で洗濯をしていると、上流から桃が流れてきました。おばあさんは洗濯を中断して、桃を拾うという洗濯をします。そして、持ち帰った桃をおじいさんと共に食べようとしたところ、桃の中から大事が出てきたのです。おじいさんとおばあさんは、その大事に桃太郎という名前を授けました。そして、桃の中にいた大事、桃太郎はすくすくと育っていきます。ある日、彼らの住む村の近くで、鬼が悪さをしているという話を聞いた桃太郎。彼は鬼大事を決意します。それに感銘を受けた老夫婦は、きび団子を桃太郎に与えて送り出します。その途中、桃太郎はきび団子で、犬、猿、キジを従いつつ、鬼の本拠地、鬼ヶ島に到着しました。鬼と大事した桃太郎は、犬、猿、キジとの連携を大事にしつつ、鬼を大事します。
このようにmediumモデルは、API版Whisperに匹敵する精度で文字起こしを終えてくれました。ただ処理時間は22秒と、大幅に増えています。
Whisperのlargeモデルを使ってみた
最後にWhisperの真打・largeモデルの精度を確認します。API版にも採用されたその実力の程はいかに……
昔々あるところにおじいさんとおばあさんが住んでいましたある日おじいさんは山にしばかりにおばあさんは川に洗濯に行きますおばあさんが川で洗濯をしていると上流から桃が流れてきましたおばあさんは洗濯を中断して桃を拾うという洗濯をしますそして持ち帰った桃をおじいさんと共に食べようとしたところ桃の中から胎児が出てきたのですおじいさんとおばあさんはその胎児に桃太郎という名前を授けましたそして桃の中にいた胎児桃太郎はすくすくと育っていきますある日彼らの住む村の近くで鬼が悪さをしているという話を聞いた桃太郎彼は鬼胎児を決意しますそれに感銘を受けた老夫婦はきびだんごを桃太郎に与えておくりとしますその道中桃太郎はきびだんごで犬猿キジを従いつつ鬼の本拠地鬼ヶ島に到着しました鬼と胎児した桃太郎は犬猿キジとの連携を大事にしつつ鬼を退治します
ご覧のとおり、精度はAPI版Whisperをも上回っています。ただ、仕様なのか句読点がなくなってしまいましたね。しかもタスク完了には、1分17秒もかかっているんです。
これまでの結果を総括すると、GitHub版Whisperではmediumモデルが最優なのかもしれません。みなさんもぜひ、お試しください!
なお、Whisperを応用したText-to-Speechモデルについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

リアルタイム文字起こしの実装フロー
リアルタイムで音声を文字に起こす仕組みは、大きく「入力」「変換」「仕上げ」「表示」の4段階で進みます。
はじめに入力段階では、ブラウザならMediaRecorder、スマホアプリならAVAudioEngineを使って、16 kHz・モノラルのPCMデータを取得します。
音声はそのままでは扱いにくいため、1秒ごと、すなわち1万6千サンプル単位で細かく区切り、後段の処理に渡せる形に整えます。
次の変換段階では、遅延をなるべく抑えたASR(自動音声認識)エンジンを動かします。オンプレミス環境なら、whisper.cpp –stream や faster-whisper の transcribe() を呼び出せば、Metal 対応Macのlarge-v3-turboモデルでも平均300ミリ秒台で文字列が返り、クラウドへ送らなくても十分に実用的です。
一方で、クラウドで処理したい場合は、ブラウザ側で10秒分ずつWAVにまとめてWebSocket経由でサーバに送り、APIから戻ってくる文字列を非同期で受け取る構成が安定します。
変換されたテキストはそのままでは読みづらいので、仕上げ段階で句読点を自動補完するpunctuatorを通し、さらに pyannote-audioで話者を分離して「誰が話したか」まで整理します。
ここでまとめた全文を最後に一次バッチとしてOpenAIの whisper-1 APIに再送すると、誤変換が補正され、議事録としてそのまま使える品質になります。
仕上がったテキストはフロントエンドに送り返し、SSEやWebSocketで約200ミリ秒ごとに差分をプッシュすれば、React側では useEffect と useRef でスクロールを同期させながら、発言がリアルタイムに流れていくインターフェースを簡潔に実装することができます。
WhisperでエミネムのRap Godの歌詞を文字起こししてみた
Whisperの実力を測るために、エミネムのRap Godの歌詞を文字起こしさせてみます。
1秒間に10.65音節という快挙でギネスに登録もされている曲なので、Whisperの実力を測るには最適でしょう。
結果はこちら
Look, I was going to go easy on you not to hurt your feelings. But I'm... Are you going to get this one chance? Wait a minute. Stop. Wait a minute. I can feel it. Just... It's so sad here. I'm feeling that stuff. By something it's about to happen. But I don't know what's. If that means what I think it means, we're in trouble. It's big trouble. And if he is, but that is, as you say, I'm not taking any chances. You're just what the fuck. Are we getting the feel like a rap? Or am I people from the front to the back? No, no. Now, things are on so long enough to slap. But they said I rap like a roll box. I'll call me rap. But for me to rap, I can compute them as be a my jeans. I got a laptop and my back pocket. My pinnacle walk when I have cock. I got a fat now from that rat. Profit made on the vanilla killin' off it. Ever since Bill Clay, who was still an office with Malacola wins deep filling on his nutsack. I'm an incestal as honest, but as rude as in these things are how syllables kill a halting. Kill a word. This living activity hit pop. You really want to get into a person's ass with this property. Rat packet a mac in the back. Get a jack back. Rat, rat, rat, rat. Get a jack neck. The exact same time I took. These nirvana lack of ass guns while I'm practicing. That'll still be able to break them on the fucking table. Look at the back of a couple of the faggot to crack it in half. Only realising was ironic. I was under after a math after the fact. How could I not blow? Well, I'd be a drop F-form. Do my wrath of attack rat was a habit. A rough time period. Here's a maxi pad. That's actually disaster's to bad. For the back of the master league. A drop in this master p.s. I'm beginning to feel like a rap. Or am I people from the front to the back? Bad, not bad, not. Not good things at all. I'm so long enough to slap. Bugs, slaps. Bugs, slaps. Let me show you maintain in this shitty bet. For that. Everybody with a key in a secret to rap and mortality. Like I have got. Well, the recruit for the blueprint. Submargin, youth for the exuberance. Everybody loves the blueprint. No sense, if the girl flag an asteroid. Nothing but true for the muncents. P-n-c's get taken as gold. The music cause I use it. That's a vehicle. The host, the rock. Yeah, well, the new school for the students. Me? I'm a product, the rock him. Lock him, so best to rock him. W-a-q-h-q-h-d-d-r-ing. L-e-e-z-e-t-q-h-g-t-g-t-s-lim. This part enough to take rope up, up, up, in-be in a position. To make one game see, and duck them into the motherfucking rocking. Go haul the fame even though I walk in the church in person. Go haul the flames only haul the fame. I peed duck it in as y'all go haul the fame on the wall. Sure. You fang's the guitar, the game. To the walk of flock of dreams. Offer the flanking. Tell me what in the fuck are you thinking? Little K-looking boy. So gay, I can barely say it with a street face to the boy. You're innocent and innocent. That's a girl like a watchin' a church gathering. Take a place to the cowboy. Boy, ready for his kid. So they see the good boy. You get a thumbs up pad in the back and a way to go from your label to the be gay look and boy. Hey look and boy, what you say look and boy? I get a hat from trade look and boy. I'm a work-fuck. Everything gonna happen if it asks nobody to shit. Get out my place to the boy. Basically boy, he never can be capable of keeping up with the same case. The good boy can sound beginin' in the feel like a rap. Go, rap, go. For my people from a country to a bad. No, back now. The way I'm racing around the track, homie, less calm. They're in the heart of the trailer, part-per-way trash guard. New before dinner was on this plan, it's Krypton. No, ask God, ask God, say you be thorn. I'll be old, be broke, I'm omnipotent. That off the non-reloading immediately because he's fine, I'm totalling. And that should not be woken. I'm a walkin' dead, but I'm just a talkin' head, as I'm be floating. But I got your mind, be throaten. I'm out my ramen noodle. We have nothing in common, cool, though. I'm a don't remember pinch yourself, and the y'all, I'm a pay-harmist, you want to meet me. My honest, he's cool, but it's honestly feudal, the final due to last what I do though for good at these months. And the last one, I want to make sure somewhere, and the chicken's got a child's scribbling, dude, and the nup-fronts, that's maybe try to help get some people through tough times. But I gotta keep a few puns, slats, just in case, because even you unsight, rats are hungry, looking at me like it's lunchtime. I know there was a time where one side was king, and I got a ground, but I still wrapped like a moth, bare-row, munch, grinds, and one crunch, but sometimes when you come by, a peer with a skin colour, up, mind, you get too big, and hit, come, try and duck, and say you like that one line of set, on a back from the mathers, out P1 without, try to set, take set, and hit from column, buy, put them all in a line, and a nake, what a set, and never bother, and not, see if I get away with it now, that I ain't as big as I've was, but I, I'm almost into an immortal, come and do the portal, you're stuck in a time war, you're just a thousand four dollars. I know what the fuck that you're buying for, and you point this as my puns, I'm with fucking corn rolls, you might know I'm a fucking normal, and I just bought a new rake on from the future, just to come and shoot, I'm like when fabulous made, Ray J. Matt, the spats that he with the fact, and Ray was casting his own man on the pay pay, you know, man, that was a 24-7 special on the K-Bode channel. So Ray J. went straight to the radio station, the very next day, hey, fat, I'm a kill you, leave it coming at you with Suicide, excuse me. Ah, someone, I'm a killman, I'm a killman, you were someone, I'm a human, what I got a new diggy, to throw the U.M. Supee, human, then a better, then a better, then a better raffle, something anything you say, a sicker singing off of me, and a new raffle, you never stay anymore, then never stay, then never stay, how to give him a month, or the fucking audience, I feel like I'm never fatting, and I know the haters, if I ever wait for the day to think, I feel like they'll be celebrating, cause I know the way to get him motivated, I make a living music, you make elevator music. Oh, he's too mainstream, but that's what they do when they get jealous, like a music. It's not hip hop, it's hip hop, cause I found a teleweight of music with Ray, chakra, with that, throwing moves up, stuff, I make a music. I don't know how to make songs like that, I don't know what words to use, let me know when it occurs to you, while I'm ripping anyone of these verses, you and curtains, I'm inadvertently hurting you, how many verses I got a murder to prove that if you had this nice and songs, you'd be like, I swear just to us, school flunky, pill zone, but look at the acolyte, the skills grown, full of myself, but still hungry, I bully myself, cause I make me do what I put my mind to, when I'm a male, young, leaks above, air when I speak and tongue, but it's still tongue, and she fuck you and drugs, Satan take the fucking wheel, a muscle even the front, spurping, heavy-d, and a voice, still chunky but fun, but in my head there's something I can feel, talking and struggling, angels fight with devils, and here's what they went from me, to ask a meter when they're minates, I'm on the women hate, but if you take a n****** iteration, the better hatred I had, then you may be a little patient, and more sympathetic, so that's a duration, and understand that there's discrimination, but fuck it, life's hanging, you limits, make women hate them, but if I can't bear the women, how the fuck am I supposed to be a c*****, I'm a st***, if the shoot is a f***ing mistake, if the thing I need to be overseas, and take it to the case,
流石に一文字ずつ適切に文字起こしができているかを確認するのは大変なので、最初と最後を確認してみましたが、Whisperでは最後まで文字起こしができていませんでした。
また、冒頭の「gonna」を「going」と誤って文字起こししています。上記はtinyで実施をしたためかもしれないので、turboでも行ってみたら、誤りなく文字起こしをしてくれました。
音声のみではなく楽器の音が入っていたり、音声が高速な場合には、小さいモデルで正確な文字起こしはなかなか難しいのかもしれません。
Whisperを使ったアプリやサービスを紹介
API版Whisperを使ったアプリやシステムは、既に私たちの身の回りで使われています。
例としてChatGPTと連携したアプリは以下のとおりです。
- 学習プラットフォーム「Quizlet」
- 食料品の即日配達サービス「Instacart」
- eコマースプラットフォーム「Shopify」
- 言語学習アプリ「Speak」
Quizlet

Quizletはオンライン学習ツールです。
単語カードや音声内容を正しく入力する音声チャレンジ、過去の回答正否傾向に応じたテスト問題などが出題されます。
QuizletはWhisperが発表される前からありましたが、Whisperが発表された後にAPIを採用しており、オンライン学習ツールとして飛躍しています。
Instacart
Instacartは食料品の購入・配送サービスを提供しているサイトです。InstacartではWhisperのみならずOpenAIのAPIを導入しており、その結果従来の検索機能に加え、料理方法や商品の属性についての詳細情報も提供されるため、ユーザーはアプリ内で直接情報を得ることができます。
また、ユーザーは自分のショッピング履歴に基づいて、特定のニーズに合った商品を提案してもらえます。
Shopify
ShopifyでもGPTとWhisperのAPIが使われています。
Shopifyではユーザーが商品を検索すると、ショッピングアシスタントはそのリクエストに基づいてパーソナライズされたおすすめ商品を提案。
Shopifyの新しいAIを搭載したショッピング・アシスタントは、何百万もの商品をスキャンし、ユーザーが探しているものを素早く見つけたり新しいものを発見したりすることで、アプリ内ショッピングを効率化しています。
Speak
SpeakはAIを搭載した語学学習アプリで、スムーズな会話を習得することを目的としています。韓国で成長している英語アプリで、すでにWhisper APIを使用して新しいAIスピーキングを開発し、世界中に提供しています。Whisperの精度は、あらゆるレベルの語学学習者に対応し、会話の練習と非常に正確なフィードバックを提供しています。
今後はWhisperを使った仕組みが増えていくと予想できるため、今後の期待が高まりますね。
Whisper以外の文字起こしツール
Whisper以外にも文字起こしツールは普及しており、目的や環境に応じて使い分けるのがいいでしょう。
ここからはWhisper以外の文字起こしツールをいくつか紹介します。
kotoba-whisper-v2.0
Kotoba-Whisper v2.0は、日本語音声認識のために最適化されたモデルで、Kotoba TechnologiesとAsahi Ushioによる共同開発です。Kotoba-Whisper v2.0は、OpenAIのWhisper large-v3モデルをベースとして、知識蒸留を用いて作られた軽量化版。
Whisper large-v3を「教師モデル」として使用し、その知識を「生徒モデル」に伝達することで、モデルを軽量化しながら精度を維持しています。蒸留プロセスでは、大規模な擬似ラベルを用いて、モデルの一般化能力を向上させています。
学習データには、ReazonSpeechの約720万クリップが使用されており、各クリップは平均5秒の音声と18トークンの文字起こしから構成されています。
AIGIJIROKU
AI GIJIROKUは、株式会社オルツが開発したAI自動議事録ツールで、音声認識や話者識別、要約機能などを備えた最先端のソリューションです。
話者識別精度は最新のアルゴリズムによって99.62%に向上しています。この技術により、複数人が参加する会議やインタビューなどの場面でも、正確な話者特定が可能になり、リアルタイムで高精度な議事録作成を実現。
利用を重ねるごとに、AIがユーザーのデータ(SNS、メール、カレンダー、辞書など)を自動学習し、議事録のパーソナライズが進みます。また、声紋判断を活用して話者特定をより正確に行えるようになります。
Rimo Voice
Rimo Voiceは、AIを活用した文字起こしツールで、動画や音声ファイルをアップロードするだけで自動的に文字起こしを行うクラウド型サービスです。主にオンライン会議の議事録作成や情報整理に活用されています。
機械学習による高精度な音声認識技術を採用しており、ノイズ除去機能や不要な言葉(「えー」「あの」など)の自動削除により、修正作業の手間を削減し、1時間の動画ファイルを約5分で文字起こし可能で、効率的です。
多言語に対応しており、対応言語数は20か国語以上。Zoom、Google Meet、Microsoft Teamsと連携可能で、会議の録音データを自動的に文字起こしして議事録として記録もできます。
Notta
Nottaは、日本のNotta株式会社が提供するAI文字起こしサービスです。このサービスは、音声や動画ファイルを自動的にテキストに変換し、議事録作成や情報共有の効率化をサポート。
多様な音声ファイルや動画ファイルに対応しており、さまざまな場面での文字起こしが可能です。ICレコーダーやスマートフォンで録音・録画したデータもすぐにテキスト化できます。
マイク入力を利用したリアルタイムでの文字起こし機能を提供しており、会議やインタビュー中の即時利用が可能であり、対応言語は58言語にもおよびます。
スマート書記
ピックベース株式会社が開発・提供するAIを活用した議事録作成支援サービスです。会議やインタビューの録音データをもとに自動で文字起こしを行い、議事録の作成や情報共有を効率化。
録音データから高精度で文字起こしを行い、「えー」や「あー」といったフィラーの自動除去、発言者の自動分離機能、専門用語登録機能があり、議事録の質を向上させます。
対面会議やオンライン会議の両方で利用可能で、最大20名の話者分離に対応しており、会議や打ち合わせが多く、議事録作成に時間がかかる場面などで活用できます。
Whisper派生プロジェクト
Whisperを使ったアプリやサービス以外にもWhisperの派生プロジェクトがいくつかあります。
派生プロジェクトはOpenAIのWhisperとは異なる特徴を持っており、必要に応じて使い分けると良いでしょう。
| 言語 | 処理速度 | 使い道 | |
|---|---|---|---|
| Whisper | Python | 標準 | 汎用的 |
| Whisper.cpp | C++ | 高速 | 軽量環境 |
| Faster-Whisper | Python | 非常に高速 | 高速推論 |
| Mlx-Whisper | Python | 高速 | Macに最適 |
whisper.cpp
whisper.cppはGPUがなくてもCPUで高速処理が可能なTTSです。C++で実装されており、外部ライブラリに依存しません。そのため組み込みシステムや低スペックなデバイスでも動作可能です。
google colaboratoryでの実装はこちら
!apt update && apt install -y ffmpeg git cmake build-essential
!git clone https://github.com/ggerganov/whisper.cpp.git
%cd whisper.cpp
!bash ./models/download-ggml-model.sh base.en
!cmake -B build -DGGML_CUDA=OFF
!cmake --build build --config Release
!wget -O jfk.wav https://github.com/ggerganov/whisper.cpp/raw/master/samples/jfk.wav
!./build/bin/whisper-cli -m models/ggml-base.en.bin -f jfk.wav結果はこちら
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.faster-whisper
Faster-Whisperは、OpenAIのWhisperをCTranslate2を使用して再実装した高速なTTSです。OpenAI Whisperの約4倍の速度で動作し、同じ精度を維持しており、メモリ使用量も削減されています。
また、OpenAI WhisperはFFmpegを必要とするが、Faster-WhisperはPyAVを使用し、FFmpegのインストールが不要という特徴も持っています。
google colaboratoryでの実装はこちら
!pip install faster-whisper
!pip install ffmpeg-python
!wget -O jfk.wav https://github.com/ggerganov/whisper.cpp/raw/master/samples/jfk.wav
from faster_whisper import WhisperModel
# モデルのサイズを選択(small, medium, large-v3 など)
model_size = "large-v3"
# GPU を使用する場合は device="cuda", CPU の場合は "cpu"
model = WhisperModel(model_size, device="cuda", compute_type="float16")
# 音声ファイルのパス
audio_path = "jfk.wav"
segments, info = model.transcribe(audio_path, beam_size=5)
print(f"Detected language: {info.language} (Probability: {info.language_probability:.2f})")
for segment in segments:
print(f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}")結果はこちら
Detected language: en (Probability: 0.91)
[0.00s -> 10.38s] And so, my fellow Americans, ask not what your country can do for you, ask what you can do for your country.mlx-whisper
AppleのMLXフレームワークを活用したWhisper。MLXは、AppleのM1/M2チップで最適化された機械学習ライブラリであり、mlx-examplesはWhisperをMLXで動作させます。
Metalバックエンドを利用し、高速な推論が可能であり、コマンドラインやPython APIで簡単に使用できます。
こちらはM1/M2のMLXフレームワークを使用するため、google colaboratoryでの実装はできませんが、もしMacを使っている場合には試してみるのもいいかもしれません。
競合サービスとの比較表
声認識APIは価格だけで選びがちですが、精度やリアルタイム性、無料枠の有無が運用コストやサービス品質を大きく左右します。
議事録作成か字幕生成、どちらを重視するか決めてから比較すると効果的です。判断基準がはっきりすると、数字の差が示すリスクとメリットがより立体的に見えてきます。
| サービス | 1分単価 | 日本語WER | ストリーミング | 対応言語 | 無料枠 |
|---|---|---|---|---|---|
| Whisper-1 | $0.006 | 4.9% | 🔺 | 98 | なし |
| Google Cloud Speech-to-Text | $0.009 | 6.0% | ⭕️ | 125 | 60分/月 |
| Azure Speech Service | $0.011 | 5.8% | ⭕️ | 110 | 5時間/月 |
| Amazon Transcribe | $0.012 | 6.3% | ⭕️ | 100+ | 60分/月 |
Whisperを使って動画を自動文字起こしする方法を知りたい方は、以下の記事もご覧ください。
Whisperの活用事例
Whisperは精度高く文字起こしできるのが特徴的ですが、同じように文字起こしに活用している例があります。
非常に高い精度で文字起こしをしてくれるので、今後はもしかしたらクラウドソーシングでの文字起こしの仕事がWhisperに取って代わられるかもしれません。
また、こちらも文字起こしに活用していますが、その活用方法が斬新です。
以下の方は、Youtubeで学びたい動画をDL→Whisperで文字起こし→Deeplで翻訳という一連の作業を行い、海外の動画で勉強されているようです。
※YouTubeで動画をダウンロードする場合には、YouTubeの利用規約に従ってください。
Whisperのセキュリティ
OpenAI APIを使う際、通信経路と保存先の両方で強固な暗号化がなされている点は安心できます。
まず、ネットワーク上のやり取りはTLS 1.2以上で暗号化され、第三者が途中で盗み見ることはほぼ不可能なものになっています。
サーバ側に到達した音声ファイルやログは AES-256方式で保存され、鍵管理も分離されているため、データが物理的に流出しても内容を復号することは極めて困難です。
さらに企業向けプランでは、アップロード済みデータや実行ログが最長30日で自動的に消去され、その間も機械学習の追加学習には利用されません。
2025年3月には第三者監査によるSOC 2 Type IIが取得されており、内部統制の運用実態まで証明済みです。
欧州クライアント向けにはGDPRに準拠した DPA(データ処理契約)テンプレートが更新され、医療分野で求められる HIPAA BAA も発行されたことで、電子カルテや遠隔診療アプリなど機密性の高い音声を扱うSaaSでも採用事例が増えています。とはいえ、社外クラウドに音声を置くこと自体がポリシー違反になる組織もあるでしょう。
その場合は、オープンソース実装であるwhisper.cppやfaster-whisperをオンプレミスや専用VPに配置し、データを一切外に出さない構成を選ぶことで、内部監査や ISMS の要求にも応えられます。
結論として、自社の情報セキュリティ方針や業界規制を確認し、「クラウドで利便性を取るか、ローカルで完全隔離を徹底するか」を事前に決めておくことが、Whisper 導入時の最重要ポイントと言えるでしょう。
よくある質問
ここではWhisperに関するよくある質問をまとめていきます。ご自身の疑問に応じて、参考にしてください。
文字起こし&音声の英訳が無料で試せるWhisper
当記事ではOpenAIが誇るマルチな音声認識モデル「Whisper」について紹介しました。以下でもう一度、Whisperの機能を振り返っていきましょう!
● 音声の文字起こし / 英訳 / 言語検出ができる
● 98種の言語と7種のファイル形式に対応している
● 無料のGitHub版と有料のAPI版が選べる
また今回は、Whisperの各モデルについて実験も行っています。結果としては、「API版のwhisper-1」と「GitHub版のmediumモデル」が使い勝手に優れていましたね。
SNS上では「文字起こし精度が高くてびっくり」「Whisperだけでそこそこの議事録ができる」なんて声も……
インストールできる環境がある方はぜひ、GitHub版から無料で試してみてください!

最後に
いかがだったでしょうか?
文字起こしや音声の英訳を活用して、会議記録やグローバル対応を効率化しませんか?音声生成AIの導入や開発の可能性について、具体例を交えてご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

