
【初心者でも分かりやすい!】画像認識技術の仕組みや活用法をやさしく解説!導入方法なども説明

WEELメディアリサーチャーのいつきです。
近年のAI技術の発達によって画像認識の技術が徐々に普及していますが、そもそも画像認識の仕組み自体がわからない方も多いのではないでしょうか?
自社の業務への導入を進めても、画像認識の仕組みを理解していなければ、正しく使いこなせずにかけたコストを無駄にする結果に終わるかもしれません。
そこで今回の記事では、画像認識の仕組みや種類について解説します。
最後までご覧いただくと、画像認識について詳しくなれるので、自社業務に導入して作業効率が大幅に向上するかもしれません。
\生成AIを活用して業務プロセスを自動化/
画像認識の基本

画像認識技術は、日常のさまざまな場面で活用されています。生活に欠かせなくなったスマートフォンのロックを解除するための顔認証も、カメラを用いた画像認識の一種です。
AIによる高性能化が進み、利用目的や手段も多様化する画像認識は、今後さらに身近なものになるでしょう。細かい話に入る前に、基本的な定義と最近の画像認識AIの動向を確認します。
画像認識とは?
画像認識は、画像に「何が写っているのか?」などの特徴を掴み、認識する技術のことです。パターン認識という手法が使われており、対象物の形や色などの特徴を見極めて判別しています。
あらかじめコンピュータに大量の見本となる画像を学習データとして与え、それらの特徴と一致するかどうかを判別しています。
例えば、何も学習していない状態のコンピュータに犬の画像を与えても何が映っているのか理解できません。事前に犬の特徴を学習していれば、それと一致する画像を犬と判断できます。
しかし犬と言っても、世界には大きさも見た目も異なる多様な種類の犬が存在します。少数の犬の画像でしか事前学習できなかった以前の技術では、犬とその他の動物を正確に判別するのは困難でした。
なお、最新の画像認識の機能について詳しく知りたい方は、下記の記事を合わせてご確認ください。

画像認識へのAIの活用
画像認識技術は古くから開発されてきましたが、ディープラーニング技術の進展によって大幅に精度が向上しました。AIモデルは膨大な量の情報を事前学習でき、画像判別の正確性が低いという以前の課題を克服しています。
例えば、単に画像に映る物体を人間と判断できるだけでなく、画像の特徴から性別や年齢など細かい属性も判定可能です。画像認識の正確性はすでに人間の能力を超えるとも言われており、今後あらゆる面で人間の活動をサポートしてくれるでしょう。
カメラやデジタル技術の発展、ITインフラの拡充、社会的なDx化の推進などもあり、工場などの異常検出や自動運転への応用などAIによる画像認識の活用領域は広がっています。人材が不足する中、作業の自動化や効率化に大きく貢献すると期待されています。
画像認識と画像処理の違い
画像認識と画像処理はどちらも画像を扱う技術ですが、その目的と機能はまったく異なります。画像処理は主に「画像そのものをきれいにする、見やすくする」ための技術です。
たとえば、明るさの調整、ノイズの除去、エッジの強調、画像のリサイズなどが挙げられます。PhotoshopやCanvaなどの画像編集ソフトを使用して画像そのものの画質や構造を改善するのが大きな目的となります。
一方、画像認識は「画像の中に写っているものが何かを判断する」技術で、人工知能(AI)や機械学習の領域です。具体的には、画像に写っている人物や物体を識別したり、画像にタグをつけたりする機能が挙げられます。スマートフォンの顔認証や、自動車が信号や歩行者を検出する技術もすべて画像認識に該当します。
実際のアプリケーションでは、画像処理と画像認識がセットで使われることが多く、処理された画像をもとにAIが認識を行うという流れが一般的です。


画像認識で解決できる課題・得られるメリット
画像認識技術の進化により、これまで人間の目や手で行っていた作業をAIが自動化できるようになりました。正確で高速な認識処理は、多くの業界で課題解決や効率化に貢献しています。ここでは、画像認識がどのような場面で役立ち、どんなメリットをもたらすのかを具体的に見ていきましょう。
作業の自動化と人手不足の解消
画像認識を活用することで、目視による検品作業や監視業務などを自動化できます。たとえば、製造業においては製品の傷や異常をカメラとAIが自動で判別し、不良品を即座に除外することが可能です。
これにより、作業時間の短縮や人件費の削減が実現されるだけでなく、人手不足が深刻な業界でも安定した運用が可能になります。また、夜間の監視や連続的なチェックが必要な業務も、画像認識により効率よく対応できます。
ミスの削減と品質の向上
人間による作業にはどうしても判断のブレや見落とし、個人によって精度が変わるといったリスクが伴いますが、画像認識は常に同じ条件で処理することができるため、ヒューマンエラーを大幅に減らすことができます。
医療現場では、レントゲンやMRI画像からAIが異常箇所を検出し、見逃しを防ぐ取り組みも進んでいます。正確性の高い認識結果が得られることで、業務の信頼性やサービスの品質向上にも直結します。
データ活用による新たな価値の創出
画像認識で得られる情報は単なる認識結果にとどまらず、ビジネスにおける意思決定やマーケティング戦略にも活用できます。
たとえば、店舗に設置したカメラで来店客の年齢層や性別を分析すれば、商品配置や広告展開の最適化に繋がります。農業分野では作物の生育状態を可視化し、収穫時期の予測に役立てる事例もあります。
いままで個人の感覚や経験に大きく頼っていた作業なども画像認識によってデータ化することにより、安定した収穫が見込めたり、技術が失われることなく次世代へ残すことも可能となります。
画像認識の種類
画像認識はさまざまな用途で用いられていますが、主な種類は以下の通りです。
- 物体認識
- 顔認識
- 文字認識(OCR:Optical Character Recognition/Reader)
- コード認識
- 異常検知
それぞれ認識できる画像の種類が異なるので、活躍するシーンも異なります。
特徴を解説していくので、ぜひ参考にしてみてください。
物体認識
物体認識は、画像に含まれる物体を特定し、その物体が何であるかを判断する技術です。例えば、画像内に特定の物体があるかどうかを確認したり、その物体がどのカテゴリに属するかを判定したりします。
この物体認識に関連して、物体の位置を特定する「物体検出」というものがあります。両者は異なるものですが、自動運転など物体の特徴を抽出する際に位置情報も重要となるため、併用されるケースも多いです。
顔認識
顔認識は、顔の画像から特徴的な部分を抽出する技術です。この技術を使うことで個人の顔を識別したり、特定の顔と照合したりできます。スマートフォンやパソコンのロック解除に使われており、馴染みのある技術の一つです。
ほかにも、似た顔を検索したり、顔をいくつかのグループに分けることも可能です。
さらに、表情から感情を読み取る「感情認識」も研究が進んでいます。また、物体認識と同様に「顔検出」という技術があり、顔認識と併せて使われることが一般的です。
文字認識(OCR)
文字認識(OCR)は、手書きの文字や印刷された文字を識別する技術です。この技術を用いることで、画像内に含まれるテキストを抽出できます。
文字認識は長い歴史を持つ分野ですが、近年では翻訳技術と組み合わせたシステムが実現されるなど、さまざまな場面で活用されています。
本や手書きの文章をデータとして活用するには、文字認識技術を用いたデジタル化が必要です。過去の企業活動で蓄積した手書きの社内資料を将来に活用したいというケースも多いでしょう。
コード認識
コード認識は、文字や数字だけでなく、バーコード・QRコード・ARマーカー・Data Matrixといったコードを読み取る技術です。これにより、カメラでコードをスキャンして、画像内の情報を認識できます。
バーコードは画像認識技術の初期から使われています。具体的には、スーパーやコンビニのセルフレジ、工場や倉庫での荷物の仕分けや棚卸などです。近年は、キャッシュレス決済などでQRコードを読み込むケースも多くなってきています。
異常検知
製造業などでは、工場設備や生産ラインに異常が生じた際の迅速な対応と早期復旧が事業継続の鍵となります。画像処理は異常検知にも用いられており、異常の生じ得る場所を24時間365日常時監視して設備故障の予防や早期復旧、製品の品質向上などに役立っています。
画像認識の仕組み
画像認識は、画像とその画像が何であるかを示すラベルをコンピュータに事前学習させ、判別したい画像を学習したデータと照合して判別します。その基本的な仕組みは、以下のように3つの段階に分け、特定の物体やパターンを識別します。
- 画像処理
- 画像から特徴を抽出
- 対象物の識別
それぞれの工程のポイントを解説していくので、ぜひ参考にしてみてください。
画像処理
画像認識の初期段階では、画像のクオリティを向上させるための「画像処理」がおこなわれます。認識させたい画像を入力したあと、AIが画像を認識しやすいように処理しているのが特徴です。
具体的には、ノイズ除去や画像のコントラスト調整などが含まれ、後の処理がスムーズになるよう準備します。
画像から特徴を抽出
次に、画像から「特徴抽出」がおこなわれます。これは、画像の中で対象物を特定するために重要なパターンやエッジ、色などの情報を取り出すプロセスです。
この段階で、画像中の特定の形状や模様が認識され、次の工程である識別に役立ちます。
対象物の識別
最後に、抽出された特徴を基に「対象物の識別」がおこなわれます。識別は、あらかじめ学習させたデータと照合して、対象物を特定する仕組みです。
例えば、りんごの画像を読み込む際は、事前に学習したリンゴの形や色などと照合します。抽出した画像の特徴と事前学習した特徴が一致した場合、物体がリンゴであると判定します。
画像認識の方法
画像認識の導入手順は以下のとおりです。
- データ収集・加工
- モデルの構築
- 実装・検証
- 再学習
導入ハードルが高いと感じる画像認識ですが、おおまかに分ければ上記4つのステップを踏むだけで導入できます。
それぞれの手順でやるべきことなどを解説していくので、ぜひご覧ください。
データ収集・加工
AIを活用した画像認識を実現するためには、学習用の画像データを収集する必要があります。AIに多くの画像データを学ばせれば、画像認識の精度が向上するためです。
また、公開されているデータセットを利用することも一般的で、たとえば自動運転向けや工業製品に特化したものなど、用途別に適したデータセットがあります。
独自に画像を撮影する場合は、対象物がはっきりと識別できるように、適切な明るさや角度で撮影することが大切です。人物を対象とする場合は、プライバシーや個人情報へに配慮したうえで撮影しましょう。
モデルの構築
準備したデータを用いてAIモデルに学習させ、画像認識モデルを構築します。ゼロからモデルを作る場合には、専門的な知識とスキルを持つエンジニアが必要です。
社内に専門人材がいない場合は、AI開発に強い外部の会社に依頼することも視野に入れましょう。
また、学習済みのモデルを利用することも可能で、モデルに自社の画像データを追加学習させ、目的に合わせて調整する方法もあります。
実装・検証
画像認識モデルが完成したら、実装して機能を検証してみましょう。いきなり本格的な運用を試みても、予期せぬエラーが発生して業務に支障をきたす恐れがあります。一度検証のプロセスを挟むことが大切です。
検証で出た課題をリストアップし、一通り解消されてから本格的に実装しましょう。
再学習
画像認識モデルが完成したあとは目的に応じて活用できますが、これで完了ではありません。AIモデルは継続的に学習することで、認識精度が向上します。
そのため、導入後も新たな画像データを集めて学習させることが重要です。学習と結果の検証や評価を繰り返すことで、モデルの精度を少しずつ向上させ、より正確な画像認識ができるよう調整しましょう。
なお、生成AIツールの開発コストを下げる方法を知りたい方は、下記の記事を合わせてご確認ください。

画像認識の活用事例
画像認識技術を既に活用して成果を挙げている事例を見ることで、導入に向けたアイデアがより具体的になるでしょう。ここでは、実際に画像認識を活用している企業の事例を解説します。
今回紹介するのは、以下の2社です。
- 羽田空港
- アサヒビール
それぞれの事例を解説していくので、参考にできる点を見つけてみてください。
事例①羽田空港
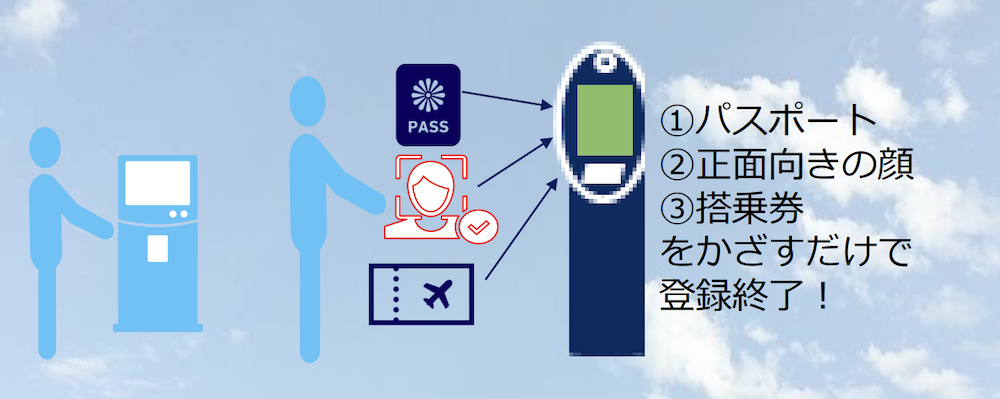
羽田空港は、顔認証技術を使って開発された「Face Express」を搭乗手続きに活用しています。※1
従来のように、搭乗券やパスポートを提示する手間がなくなるので、搭乗手続きがよりスムーズになったのが魅力です。
実際に利用されているのは、手荷物預け・保安検査場の通過・搭乗ゲートの手続きなど。日本航空と全日本空輸の2社で利用が開始されており、今後も順次拡大予定とのことです。
事例②アサヒビール

アサヒビールは、日本電気株式会社と共同で画像処理技術を活用した「輸入ワイン中味自動検査機」を開発しました。※2
導入の決め手となったのは、近年日本においてワインの需要が拡大しているなかで、より効率的で最適な検品体制を確立するためです。
今回導入した機器では、赤外光照明やカメラおよび画像処理技術を活用して、ワインに異物が混入していないかを確認しています。今後も導入数を増やして、時間あたりの検品生産性を3倍以上にするのが目標とのことです。


画像認識を活用する際の注意点

検品の精度や生産性向上に役立つ画像認識の技術ですが、活用する際は以下のような注意点も存在します。
- 適切な学習データが大量に必要
- 誤認識の可能性がある
これらの注意点を知らずに導入を進めてしまうと、問題に直面した際に後悔する可能性があります。
それぞれの注意点を解説していくので、画像認識の技術を導入したい方は押さえておきましょう。
適切な学習データが大量に必要
画像認識技術を活用する際は、モデルに適切な学習データを大量に学習させる必要があります。
少数のデータしか学習していないモデルを画像認識に活用すると、学習していない画像を読み込んだ際に識別できません。
なお、集めたデータはそのまま使えるわけではありません。画像データを学習させる前に「データクレンジング」という作業が必要です。
例えば、重複した画像や不鮮明な画像、誤ったラベル付けがされたデータなどは学習に悪影響を及ぼすため、取り除いたり修正したりする必要があります。
誤認識の可能性がある
ディープラーニングの進化により、画像認識の精度は大幅に向上しましたが、誤認識の可能性が完全に排除されたわけではありません。現時点でも、AIによる画像認識には誤りが発生する可能性があります。
スタンフォード大学の研究者であり、機械学習アプリ「gradio」の創設者でもあるアブバカル・アビド氏は、ディープラーニングによる画像認識モデル「Inception Net」の誤認識例を紹介しています。
車の画像を上下逆さまにすると「アナログ時計」と誤認識したり、半月型にスライスされたりんごを「きゅうり」や「バナナ」と認識したりすることがあるようです。
誤認識の可能性については、今後も向き合い続けなければならない課題のため、まずは理解して対策を立てておくことが大切です。
なお、生成AIを開発する際のリスクについて詳しく知りたい方は、下記の記事を合わせてご確認ください。

画像認識についてのよくある質問
画像認識技術を導入して仕事の精度や効率を高めよう!
画像認識は、読み込んだ画像の特徴を掴んで認識する技術です。以下のように複数の種類に分かれているので、自社に適したタイプの技術を取り入れる必要があります。
- 物体認識
- 顔認識
- 文字認識
- コード認識
- 異常検知
画像認識は、以下のように複数の工程に分けて認識する仕組みです。
- 画像処理
- 画像から特徴を抽出
- 対象物の識別
実際に導入する際は、以下の4ステップを踏む必要があります。
- データ収集・加工
- モデルの構築
- 実装・検証
- 再学習
画像認識は便利な技術ですが、以下のような点に注意が必要です。
- 適切な学習データが大量に必要
- 誤認識の可能性がある
特に、誤認識の可能性はどうしても排除できないので、画像認識の技術を過信しすぎないことが大切です。
画像認識技術は、導入までのハードルは高いものの、活用すればさまざまな分野で効率化を図れます。本記事の内容を参考に、ぜひ自社業務への導入を検討してみてください。

最後に
いかがだったでしょうか?
画像認識を活用することで、AI技術の導入で精度向上やコスト削減が期待できます。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。

【監修者】田村 洋樹
株式会社WEELの代表取締役として、AI導入支援や生成AIを活用した業務改革を中心に、アドバイザリー・プロジェクトマネジメント・講演活動など多面的な立場で企業を支援している。
これまでに累計25社以上のAIアドバイザリーを担当し、企業向けセミナーや大学講義を通じて、のべ10,000人を超える受講者に対して実践的な知見を提供。上場企業や国立大学などでの登壇実績も多く、日本HP主催「HP Future Ready AI Conference 2024」や、インテル主催「Intel Connection Japan 2024」など、業界を代表するカンファレンスにも登壇している。

