
Stable Diffusionとはどんな画像生成AI?利用方法から日本語化、追加学習の方法を徹底解説!

Stable Diffusionは、イメージをテキストで入力すると画像が生成できる昨今話題の画像生成AIです。ただ、テキストを入力しても自分が思うような画像を生成できなかった方が多いのではないでしょうか。
自分好みの画像を生成するには、作成したい画像のイメージを具体的に伝えるプロンプトの他にも、追加学習と呼ばれる手法が必要です。Stable Diffusionに追加学習をさせると、さらに自分好みの画像を簡単に生成できるようになります。
今回紹介するのは、Stable Diffusionの追加学習についてです。具体的な手法だけでなく、追加学習を行う流れや注意点もまとめているので、生成する画像のクオリティをあげて自分好みに変えたい方はぜひ参考にしてください。
\生成AIを活用して業務プロセスを自動化/
「Stable Diffusion」とはどんな画像生成AIなのか
入力したテキストデータを使って画像を生成するAIの一つがStable Diffusionです。Stable Diffusion以外にも画像生成AIはありますが、主な特徴は以下のとおりです。
- 潜在拡散モデルを採用することでテキストデータから画像生成ができる
- 無料で利用できる
- 作成枚数に制限がない
- リアル調からアニメ調まで画像生成できる
- 商用利用も部分的にできる
Stable Diffusionは、他の画像生成AIと比べると使いやすいため人気があります。
なお、Stable Diffusionについて詳しく知りたい方は、以下をご覧ください。

Stable Diffusionの利用方法を紹介

Stable Diffusionの追加学習を紹介する前にそもそもの利用方法を紹介します。使い方は以下の2種類です。
- ブラウザ環境で利用する
- ローカル環境で利用する
それぞれを解説します。
ブラウザ環境で利用する
Webブラウザを使ってStable Diffusionを利用できます。ブラウザ上で画像生成するため、パソコンにソフトウェアのインストールが不要で誰でもStable Diffusionを扱えるのがメリットです。
しかし、機能が有料であったり、枚数制限があったりと制約があるため、使い方には注意が必要です。制約なしで使いたいという方は、次に紹介するローカル環境で利用するようにしてみてください。
ローカル環境で利用する
自分自身のパソコンにStable Diffusionが使えるように環境を構築する方法があります。前章で紹介したブラウザ環境で利用する場合は枚数制限や有料などの制約がありましたが、ローカル環境では制約はありません。
自由度が高くなる一方で、Stable Diffusion環境構築に必要なパソコンのスペックが高いため、人によっては準備に時間とお金がかかるかもしれません。ローカル環境構築の推奨スペックは以下のとおりです。
- OS:Windows(64bit)
- CPU:Core i5~i7、Ryzen5~7
- GPU:VRAMが12GB以上
- メモリ:16GB以上
- ストレージ:512GB以上
これらのスペックを用意するのが難しい方や初めてStable Diffusionを触る方はブラウザ環境で始めてみるのがおすすめです。その後、本格的に使い始めたいとなったらローカル環境で利用してみるのがよいでしょう。


Stable Diffusionを日本語化する方法
Stable Diffusionをローカル環境構築した直後は、英語表記となっています。英語が苦手な方にとっては使うのに抵抗感を感じるかもしれません。Stable Diffusionを扱いやすくするため、日本語化する方法を紹介します。
- Stable Diffusion Web UIを起動
- 「Extensions」→「Available」を開く
- 拡張機能の一覧から「ja_JP Localization」を選択しインストール
- 「Settings」→「User Interface」を選択
- 「Localization(requires restart)」の右側「更新ボタン」を選択
- 「Localization(requires restart)」欄から「ja_JP」を選択
- 「Apply settings」をクリックして設定を保存
- 「Reload UI」を選択し、Stable Diffusion Web UIを再起動
- 起動時に日本語表記になっていれば、日本語化完了
なお、Stable Diffusionの始め方・導入について詳しく知りたい方は、以下をご覧ください。

Stable Diffusionを日本語化するメリット・デメリット
Stable Diffusionを日本語化するメリットは「誰でも直感的に画像生成ができるようになる」という点に尽きます。こちらは業務や教育等で、初心者がStable Diffusionを活用する際にアドバンテージとなるでしょう。
逆に、デメリットとしては「WebUIの一部拡張機能が日本語に対応していない」ことが挙げられます。英語で使う場合と比べて、Stable Diffusion本来の使い勝手がオミットされてしまうため、個人のプロユーザーには不向きかもしれません。
Stable Diffusionの追加学習とは
Stable Diffusionの追加学習とは、統一したい内容をあらかじめ追加学習させて画像生成に反映させる手法です。
Stable Diffusionでは、モデルをインストールしてプロンプトを入力し、求める画像を生成します。プロンプトだけで画像を生成すると、既存の衣装や髪型・画風などを同じにするのは非常に難しいです。一方、Stable Diffusionに追加学習をさせると、持ち合わせている画像から特徴を抽出して画像に反映できます。
実際に追加学習させるときに必要なのは、LoRAなどの追加学習ファイルです。ダウンロードしたLoRAファイルをディレクトリに保存して追加学習を行います。モデルやプロンプトだけでなく追加学習も活用して思い描いた画像を生成しましょう。
なお、Stable Diffusionのプロンプトについて詳しく知りたい方は、下記の記事を併せてご確認ください。

Stable Diffusionにおける代表的な追加学習の手法
Stable Diffusionでの追加学習方法には3つの方法があります。
- 転移学習(Transfer Learning)
- 蒸留 (Distilation)
- ファインチューニング (fine tuning)
これら3つの手法で追加学習すると、イメージに合った画像を生成しやすくなります。以下、それぞれの学習方法を解説しますので、参考にしてみてください。
転移学習 (Transfer Learning)
Stable Diffusionで代表的な追加学習手法の一つは転移学習(Transfer Learning)です。転移学習とは、別の学習で使用したモデルを活用し、別領域の学習に適用させる技術を指します。
この追加学習手法は、データが少なくても有効なのが特徴的です。対象モデルの一部を取り出して別データを入れ、モデルの追加学習を行います。
たとえば、犬の画像データを学習したモデルがあって、猫の画像を生成したい場合を考えてください。学習済みモデルは動物という知識の土台をすでに持っているので、一部のデータを取り出して猫の画像データを読み込ませると、猫の画像を生成できるようになります。
さらに、土台となる動物のデータはすでにあるので、新たなデータもすぐに学習して画像に反映できるのです。このように、転移学習は学習済みファイルを活用して効率的に追加学習ができます。
蒸留 (Distilation)
次に、Stable Diffusionで代表的な追加学習手法の一つは蒸留(Distilation)です。蒸留とは、教師モデルと呼ばれる膨大な学習済みモデルから重要な情報を抽出し、生徒モデルと呼ばれる小さなデータに情報を伝える手法です。
蒸留は大規模モデルの豊富な情報量を効率よく活用するので、時間や計算コストを抑えられるのがメリットです。また、何も学習していない生徒モデルを使用するので、追加学習させる生徒モデルを小さくできます。
ファインチューニング (fine tuning)
最後に、Stable Diffusionで代表的な追加学習手法はファインチューニング(fine tuning)です。ファインチューニングは転移学習の一種で、事前に学習したモデルにおいて一部のパラメーターを再学習させるプロセスを指します。
再学習するパラメーターに制限はなく、入力層・出力層の全てが再学習の対象です。ファインチューニングを使用すると、大量に追加学習させる際に過学習が起きにくくなります。ただ、学習量が多いので時間と計算量が多くなりやすい点に注意しましょう。
追加学習を行う方法

次に、Stable Diffusionで追加学習を行う方法を紹介します。追加学習の方法は、主に以下の4つです。
| アーキテクチャ | 概要 |
|---|---|
| U-Netのファインチューニング | エンコーダの特徴マップをデコーダに連結 |
| LoRA | 特定のタスクやスタイルに合わせて学習 |
| DreamBooth | 特定の内容を事後学習する技術 |
| Testual Inversion | 少ないサンプル画像でも新しい概念を学習できる |
今回は、LoRaを使用して追加学習手法を行います。それぞれの手法と手順について解説しますので、ぜひ参考にしてみてください。
追加学習ファイルの準備
まず、Stable Diffusionで追加学習を行う際は、追加学習ファイルを準備しましょう。画像データや学習プロセスを指定する際の設定ファイルが必要です。設定ファイルには以下の内容を含めたデータを準備してください。
- 学習率
- バッチサイズ
- エポック数
- ハイパーパラメーター
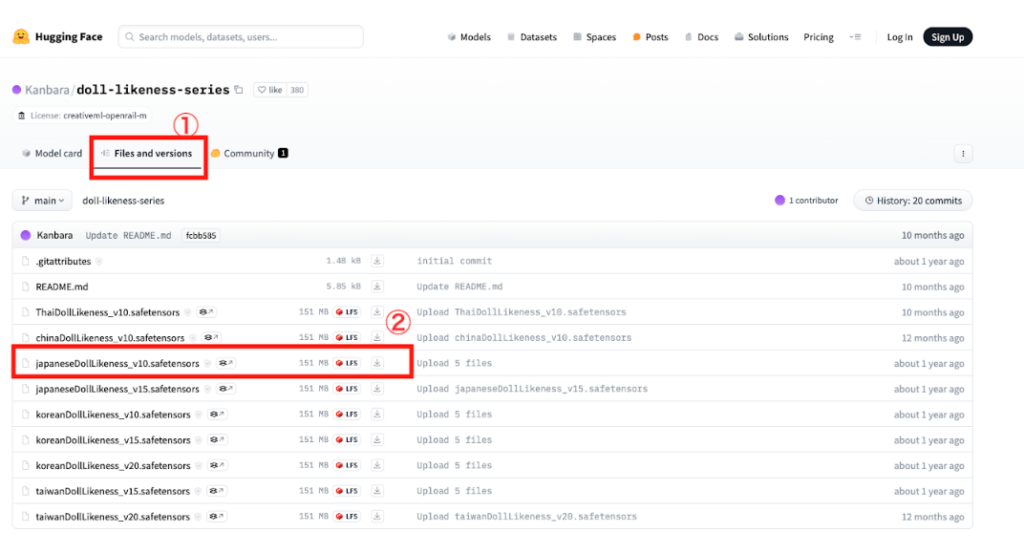
今回は、LoRAモデルであるKanbaraをダウンロードします。まずはHugging Faceのページに移動し、「File and versions」をクリックして、対象のファイルをダウンロードしてください。
追加学習ファイルのセット
次に、追加学習ファイルのセットを行いましょう。stable-diffusion-webui>models>LoRAと順番にアクセスし、ダウンロードしたモデルファイルを格納してください。
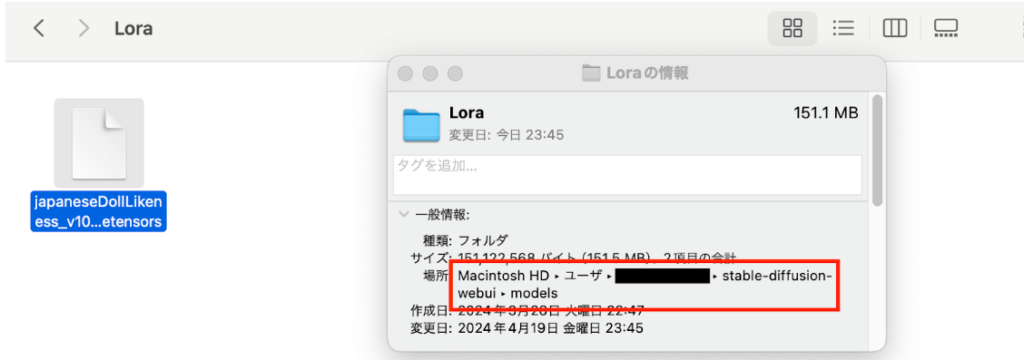
今回はMacでStable Diffusion Web UIのAUTOMATIC11111版を使用しています。下記の場所にあるのがLoRAフォルダなので自身のPCでも探してみましょう。
動作確認
最後に、LoRAモデルを所定の場所にセットしたら動作確認を行います。Stable Diffusion Web UIを起動して、「Lora」をクリックしましょう。
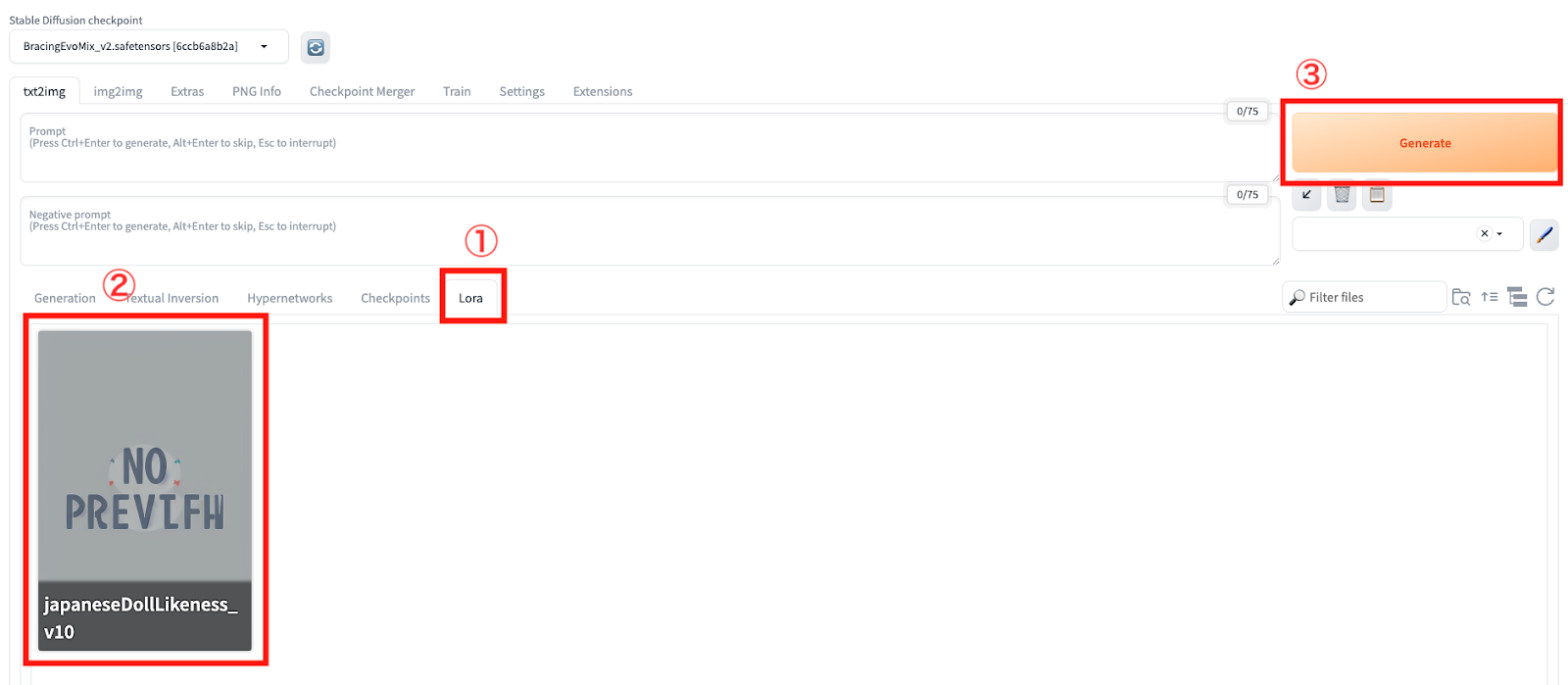
画面下にインストールしたLoRAモデルが表示されていたら成功です。プロンプトを入力して「Generate」をクリックし、追加学習した状態で画像を生成してみましょう。


追加学習の注意点

Stable Diffusionで追加学習を行う際は、学習済みモデルの更新内容に注意する必要があります。そのほか、以下の点で注意が必要です。
- 使用するモデルファイルのライセンス
- エラーが発生する可能性もある
Stable Diffusionで生成した画像を安心して使用するためにも、事前に確認しておきましょう。
ダウンロードファイルのライセンス制限
Stable Diffusionで画像を生成する場合、モデルによってはライセンスに制限があり、商用利用が許可されていない場合があります。追加学習に必要なLoRAモデルでも、それぞれライセンス制限の設定が異なるのです。
例えば、モデル自体を販売できない条件や、生成したあとの画像を販売してはならないなどの条件が記載されている場合もあります。規約に違反しないように注意しましょう。
導入時にエラーが発生する可能性
またファインチューニングの性質上、Stable Diffusionで追加学習する際は、学習モデルの全てを更新するのではなく新しく追加した部分を更新しましょう。
学習済みモデルを全て更新してしまうと過学習の状態に陥ってしまうことがあります。過学習になってしまうとモデルの性能の低下を招き、エラーが発生する可能性も高まるのです。
なお、ファインチューニングの注意点について詳しく知りたい方は、下記の記事を併せてご確認ください。

Stable Diffusionを理解して、自分好みの画像を生成しよう!
今回は、Stable Diffusionの利用方法や日本語化、追加学習の方法について詳しく解説しました。Stable Diffusionでは、プロンプトを入力すれば画像を生成できますが、Webブラウザを使うのか、ローカル環境を使うのかで使い方に違いが出てきます。さらに、特定の要素を同じにした画像を生成するには追加学習が必要です。
Stable Diffusionの利用方法は以下の2通りです。
- ブラウザ環境で利用する
- ローカル環境で利用する
また、追加学習には以下の方法があります。
- 転移学習
- 蒸留
- ファインチューニングなど
LoRAなどの追加学習ファイルを準備してセットするだけで簡単に学習させられます。ただ、ライセンスに制限があったり、エラーが発生したりする可能性があるので注意してください。
Stable Diffusionの画像生成では、画像の使用目的や使用するモデルを選択し、適切な追加学習方法を見つけて追加学習しましょう。

最後に
いかがだったでしょうか?
追加学習を活用すれば、企業独自のブランド表現も画像生成で実現可能。活用の幅は想像以上に広がります。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。
「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、通勤時間に読めるメルマガを配信しています。
最新のAI情報を日本最速で受け取りたい方は、以下からご登録ください。
また、弊社紹介資料もご用意しておりますので、併せてご確認ください。

