
【gpt-oss-120b/gpt-oss-20b】ローカル利用可能なオープンウェイト推論モデルを徹底解説!

- 1,170億パラメータの「gpt-oss-120b」と、200億パラメータの軽量版「gpt-oss-20b」が同時リリース
- gpt-oss-120bはo4-miniと同等の推論精度、gpt-oss-20bはo3-miniとほぼ同等の精度
- Apache2.0ライセンスのもと公開され、商用利用や改変、再配布も可能
2025年8月6日、OpenAIはオープンウェイトモデルファミリー「gpt-oss」をリリースしました!
1,170億(実稼働51億)パラメータの「gpt-oss-120b」と、より軽量な200億パラメータの「gpt-oss-20b」の2本立てでリリースされており、従来はクローズド環境に置かれがちだった高性能なLLMを、誰でもダウンロードして検証・改変・再配布できるようになっています。
発表直後から研究者・開発者はもちろん、国内外のAIインフルエンサーの間でも「o3/o4-mini に匹敵する推論力を OSSで扱える時代が来た」と話題になっており、GitHubやHugging Face、各種クラウド推論基盤で急速にエコシステムが立ち上がっています。
本記事では、gpt-oss-120bとgpt-oss-20bの概要や性能、使い方まで徹底的に解説します。
ぜひ最後までご覧ください。
\生成AIを活用して業務プロセスを自動化/
gpt-oss-120bとgpt-oss-20bの概要

gpt-ossは、「高い推論力を持つモデルを、法的・技術的ハードルなく誰もが利用できる状態で提供する」ことを目的にリリースされています。
gpt-oss-120bは、36層・約117B パラメータ(MoE方式でトークン当たり約5.1B がアクティブ)という規模ながら、H100(80 GB メモリ)を1枚用意するだけで動作し、OpenAI社内評価ではo4-miniと同等の推論精度を達成しました。
一方の、gpt-oss-20bは単体のGPU環境での利用を想定しており、16GBメモリ環境でも動作可能です。

両モデルともに、最大100万トークンのコンテキストを扱うことができ、Tool UseやRAG、エージェント指向実行など のAPI版GPT-4系列と同じようなフローをOSS環境で組める点が強みとなっています。
また、後述しますがApache 2.0ライセンスのもとで公開されていて、「商用利用・改変・再配布・特許利用を包括的に許諾する」ということで、大胆なオープン方針が打ち出されています。
なお、RAGについて詳しく知りたい方は、以下の記事も参考にしてください。

gpt-oss-120bとgpt-oss-20bの違い
gpt-oss-120bとgpt-oss-20bの最大の違いは、パラメータ数。
120bは約1200億と非常に大規模で、複雑な文脈を保持しながら高精度な文章を生成できる一方、20bは約200億と軽量で、処理速度やメモリ効率に優れています。
また、性能面では120bは専門性の高い文章生成や複雑な会話を得意とし、研究開発や高度なチャットボット開発に最適。それに対して20bは、FAQ自動応答や簡易的な文書生成、コーディング補助といった日常的な処理に適しています。
ハードウェア要件にも明確な差があります。120bはA100やH100といった複数の高性能GPUを必要とし、マルチノード環境が前提となるケースも少なくありません。
一方、20bはシングルGPU、場合によってはCPUでも動作可能で、PoCや中小規模のシステムにも導入しやすいというメリットがあります。
最後に推論速度。推論速度は、120bは精度を優先するため応答までに時間を要し、VRAM消費も大きくなります。そのためリアルタイム性を重視する場面では不向き。
しかし、20bは軽量のため高速に動作し、スループットの高いユースケースにも対応可能です。実用性を考えた際には、精度とコスト・速度のバランスをどう取るかが鍵となります。上記をまとめると大規模で高度なタスクには120b、軽量で迅速な処理やコスト効率を求める場合には20bが適しているでしょう。
gpt-oss-120bとgpt-oss-20bの性能
公開されたモデルカードと外部ベンチマークによると、gpt-oss-120bは、博士レベルの科学問題「GPQA-Diamond」で 81.0%、人類最後の試験「Humanity’s Last Exam」で17.7%、国際数学オリンピックの予選問題「AIME 2024」で 91.4%を記録し、同じモデルサイズ帯のDeepSeek-R1-0528 を一貫して上回りました。※1
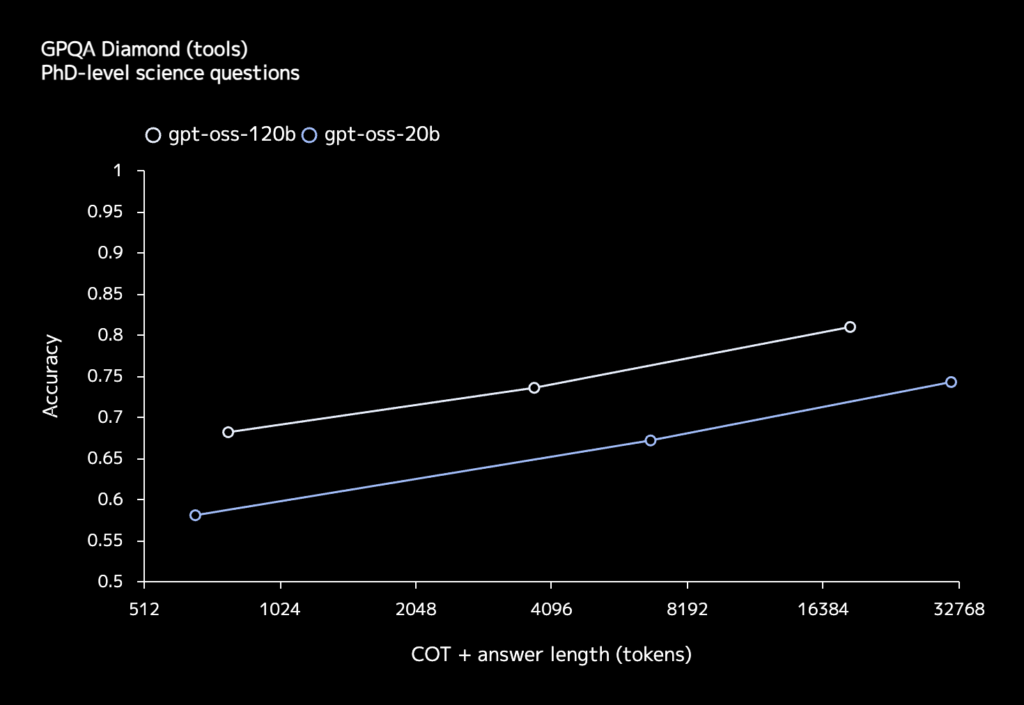
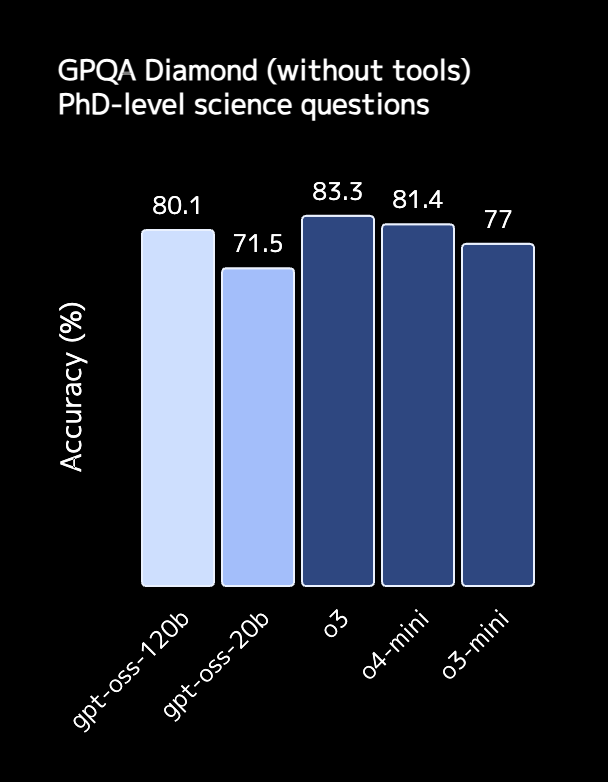
また、SWE-bench Verifiedでは54.6%を記録し、コード修正系タスクでGPT-4oやGPT-4.5を追い抜くケースも報告されています。
一方のgpt-oss-20bは、o3-miniとほぼ同等のMMLUスコアながら、推論速度とメモリ効率が高く、小規模サービスでの常時稼働などにも適しています。
さらに、両モデルともに、HopperまたはBlackwellファミリーのGPUと互換性のあるmxfp4形式で量子化され、ローカル実行する際にも、品質をほとんど落とさずに30〜40%のVRAM削減が見込めるようです。


gpt-oss-120bとgpt-oss-20bの事前学習
gpt-oss-120bおよび20bはいずれも、テキストのみの大規模データセットを用いて事前学習を実施。
データの中心はSTEM領域・プログラミング・一般知識で、学習過程では安全性を確保するため、特に生物安全保障に関わる有害知識の除去フィルタが適用されています。
学習はNVIDIA H100 GPUで行われ、最適化にはPyTorchフレームワークと専門化されたTritonカーネルを使用。gpt-oss-120bの事前学習には約210万H100 GPU時間が必要とされ、gpt-oss-20bはその10分の1程度で完了しています。
また、効率化のためにFlash Attention アルゴリズムが導入され、メモリ削減と高速化が行われています。
gpt-oss-120bとgpt-oss-20bのモデルアーキテクチャ
両モデルはオートレグレッシブ型Mixture-of-Experts(MoE)がベース。これはGPT-2やGPT-3の設計を発展させた構造であり、特徴は以下の通りです。
層数とパラメータ数
- gpt-oss-120b:36層、総パラメータ数116.8B(そのうち「アクティブ」パラメータは5.1B/トークン)
- gpt-oss-20b:24層、総パラメータ数20.9B(アクティブパラメータは3.6B/トークン)
Mixture-of-Experts構造
- 120bでは128個、20bでは32個の「エキスパート」を持つMoEブロックを採用。
- 各トークンごとにルーターが上位4つのエキスパートを選択し、Softmaxで加重平均。
- 活性化関数には独自実装の SwiGLU を使用。
アテンション機構
- バンド幅128トークンの「バンド型ウィンドウ注意」と「全結合注意」を交互に配置。
- Grouped Query Attentionを採用し、64のクエリヘッドと8のキー・バリューヘッドを組み合わせ。
- Rotary Position Embeddingを導入し、文脈長を最大131,072トークンまで拡張。
正規化と残差接続
- Root Mean Square Normalizationを使用し、各AttentionやMoEブロック前に配置。
- 効率性向上のために MoE重みの量子化 を導入し、120bモデルは単一の80GB GPU上でも動作可能
gpt-oss-120bとgpt-oss-20bのファインチューニングについて
事前学習後、モデルは推論能力とツール利用の強化を目的とした追加訓練が行われています。追加学習ではo3と類似のChain-of-Thought強化学習が用いられ、特徴は次の通りです。
Harmony Chat Format
- 「System」「Developer」「User」「Assistant」「Tool」といったロール階層を導入。
- CoTやツール呼び出しを明示的に扱えるトークンを用意し、マルチターン会話での高度なエージェント的挙動が可能。
可変的推論レベル
- 「low」「medium」「high」の3段階の推論モードをサポート。
- レベルを上げるほどCoTトークン長が伸び、精度向上が見込まれる一方でレイテンシと計算コストが増加。
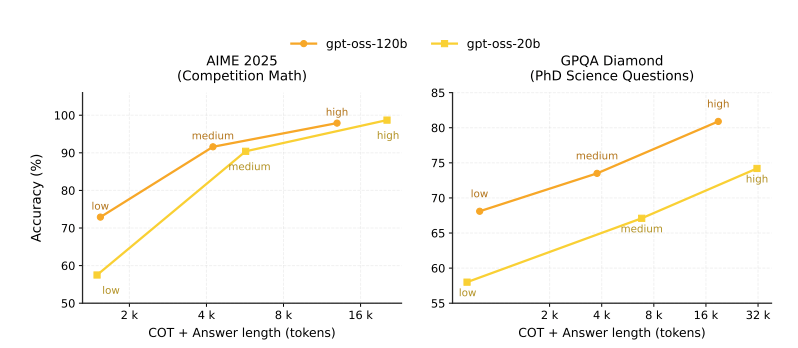
エージェント的ツール利用
- Webブラウジング、Python実行環境、任意の開発者関数を利用可能。
- Harmonyフォーマットと組み合わせることで、思考過程にツール呼び出しを自然に組み込める。
さらに、安全性を担保するため、Deliberative Alignment や Instruction Hierarchy を組み合わせた調整が施されており、危険な指示に対して適切に拒否できるよう設計されています。
gpt-oss-120bとgpt-oss-20bのライセンス
gpt-ossシリーズが注目を集めている理由の1つが、完全オープンソース寄りのApache 2.0ライセンスを採用したことです。
従来のGPT系列モデルは、API利用に限定されていましたが、今回は重みそのものを誰でも自由にダウンロードして検証・埋め込み・改変できるようになりました。
| 利用用途 | 可否 |
|---|---|
| 商用利用 | ⭕️ |
| 改変 | ⭕️ |
| 配布 | ⭕️ |
| 特許使用 | ⭕️ |
| 私的使用 | ⭕️ |
Apache 2.0ライセンスはコピーレフト義務がないため、例えば、企業が自社モデルとしてフォークして、追加学習を施し、クローズドに再配布することも技術的・法的には可能となっています。
ただし、OpenAI Usage Policyでは「違法・危険行為の禁止」など最低限のガイドラインが定められているため、実際の導入時にはポリシーの確認をするようにしましょう。
gpt-oss-120bとgpt-oss-20bの料金
gpt-ossは、重みのダウンロード自体は無料となっています。ただし、推論をクラウドで高速に回す場合は、各ホスティング・プロバイダーが独自に課金体系を設定しているので、用途やバジェットに応じて選択する必要があります。
| プラン | gpt-oss-120b (Input / Output) | gpt-oss-20b (Input / Output) |
|---|---|---|
| 自己ホスト(オンプレ / 自社クラウド) | – | – |
| Groq API | $0.15 / $0.75 | $0.08 / $0.40 |
| Together AI | $0.16 / $0.60 | $0.10 / $0.38 |
gpt-oss-120bとgpt-oss-20bの料金表
GPU環境を保有していない個人・小規模チームにおいても、上記のようなAPIを利用すれば、数円〜数十円規模でモデルを呼び出すことができます。
なお、Groqについて詳しく知りたい方は、以下の記事も参考にしてください。

gpt-oss-120bとgpt-oss-20bの使い方
gpt-oss-120bおよび20bの利用方法はいくつかありますが、今回は公式で推奨されている最もスタンダードな方法とローカルアプリ経由での利用方法を紹介します。
Hugging Faceのページはこちら。
スタンダードな方法
まず、Python 3.9以上が動くPCを用意します。GPUがあると推論が高速になりますが、GPUがなくてもCPUのみで動かすことも可能です。もし、NVIDIA GPUが搭載されている場合は、ターミナルで nvidia-smi を実行して、CUDA ドライバが正しく導入されているかを確認しておくとベターです。
次に、作業用フォルダーを作り、仮想環境を作成します。Mac や Linux ならターミナル、Windows なら PowerShell で以下を順に入力してください。
python -m venv gptoss-env
source gptoss-env/bin/activate
仮想環境が有効化されたら、まず PyTorch を入れます。GPU を使うので CUDA 対応版をインストールしてください(PyTorch の公式インストーラページでコマンドを自動生成できます)。そのうえで Transformers と Accelerate を入れます。
pip install -U torch torchvision torchaudio
pip install -U transformers accelerate
GPT-OSS は MXFP4 量子化モデルが公式に配布されています。H100世代以降のGPUであれば、追加でTritonカーネルも入れておくと推論が高速化します。
pip install triton kernels
pip install git+https://github.com/triton-lang/triton.git@main#subdirectory=python/triton_kernels次に Hugging Face Hub からモデルを取得します。容量の小さい 20B モデル(VRAM 16 GB ほどで動作)であれば高性能なコンシューマ GPU 1 枚でも試せます。120B モデルは 60 GB 以上の VRAM やマルチ GPU 構成が推奨です。
# run_gpt_oss.py
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "openai/gpt-oss-20b" # 120B を試す場合は "openai/gpt-oss-120b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 利用可能なら自動で bfloat16 や fp16 を選択
device_map="auto" # GPU があれば自動配置、なければ CPU
)
prompt = "日本語で自己紹介してください。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=120)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
上記のコードでは、まず公開モデルの名前gpt-oss-20b(またはgpt-oss-120b)を指定してトークナイザーとモデルを読み込んでいます。
モデルをロードしたら、プロンプトを与えてテキスト生成を行いましょう。上の例では「日本語で自己紹介してください。」というプロンプトを与えています。実行すると、日本語で自己紹介文が自然に生成されるはずです。
ローカルアプリ経由での利用方法
ここでは Ollama と LMStudio という2つのアプリケーションを使用する方法を紹介します。それぞれのインストール手順、基本的な操作方法、モデルの実行方法などについて説明します。
Ollamaを使った方法
Ollama(オラマ)は、ローカルで大規模言語モデルを手軽に実行できるツールです。CLIベースで動作し、モデルのダウンロードから実行まで一貫して管理できます。まずはインストールから始めましょう。
MacではHomebrewを使ったインストールが簡単です。ターミナルを開き、brew install ollama とコマンドを入力すると、自動的にOllamaがダウンロード・インストールされます。インストール後、ollama コマンドが使えるようになります(※Homebrewがインストールされていない場合は、先にHomebrew自体のインストールが必要です)。
Windows向けには公式サイトからインストーラー(.msi または .exeファイル)をダウンロードできます。まず Ollama公式サイトにアクセスし、ダウンロードページからWindows版インストーラーを取得してください。ダウンロードしたインストーラーをダブルクリックし、画面の指示に従ってOllamaをインストールします。
次に、Ollamaを用いて gpt-oss-20b モデルをダウンロードし、実行します。gpt-oss-20bはパラメータ約200億(20B)の大規模なオープンソースモデルで、初回利用時にはデータのダウンロードが必要です。実行コマンドは以下の通りです。
ollama pull gpt-oss:20b
ollama run gpt-oss:20bLM Studioを使った方法
LMStudio はデスクトップ向けのローカルLLM実行環境です。GUIで動作し、プログラミング知識がなくても比較的簡単にモデルを扱うことができます。
まず、LMStudio公式サイトにアクセスし、アプリケーションをダウンロードしてモデルをダウンロードしましょう。
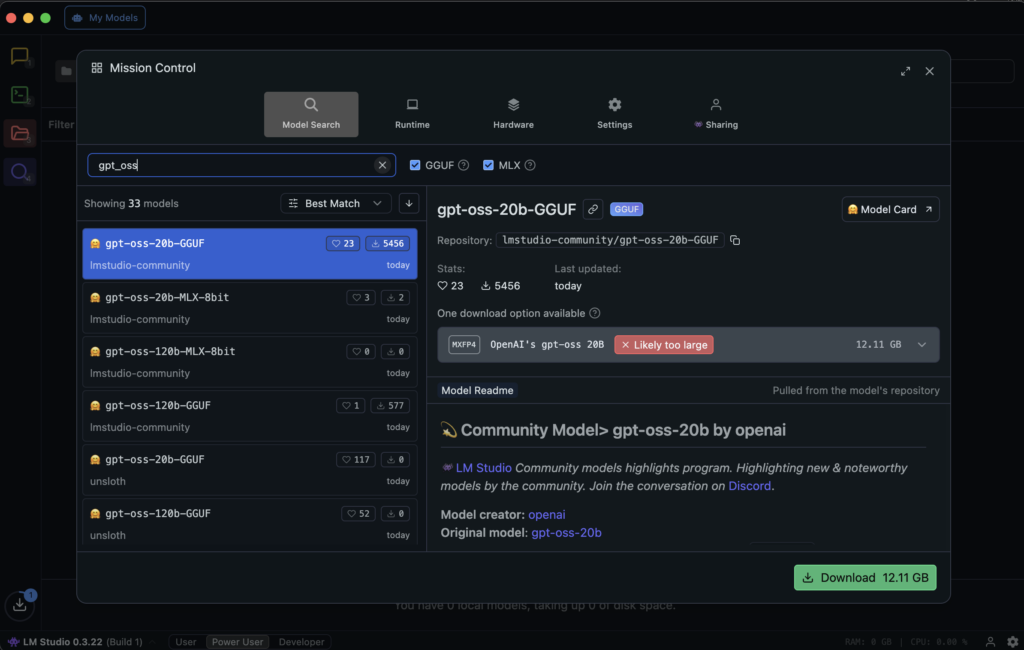
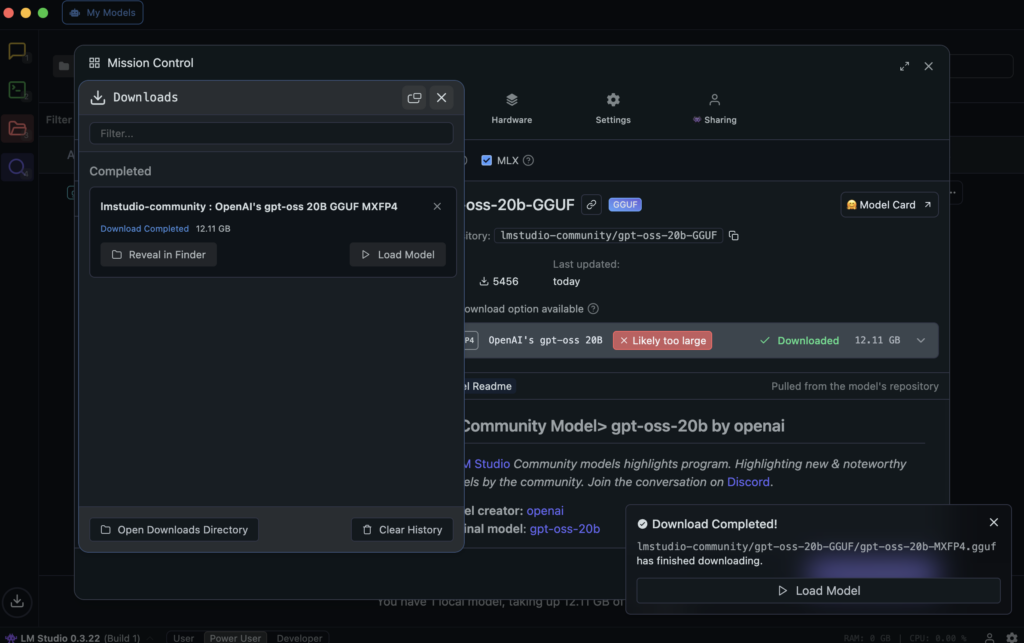
モデルがロードされたら、対話をすることができる状態になります。
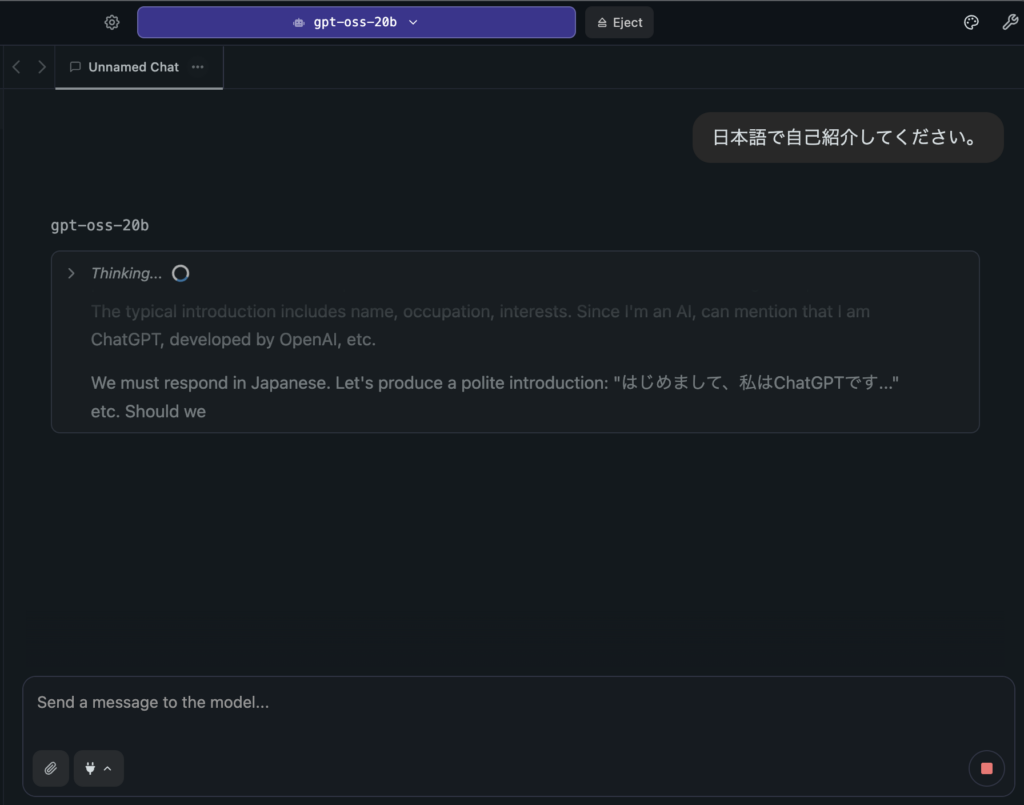
ローカル環境でもちゃんと推論してくれていますね。


gpt-oss-120bとgpt-oss-20bを動かすためのスペック
OpenAIが報告しているモデルカード内に記載されている情報を整理するとgpt-oss-120b gpr-oss-20bを動かすために必要なスペックは下記のようになります。※1
gpt-oss-120b の実行要件
GPU要件
- NVIDIA A100 / H100 クラス の複数GPU。
- H100を用いた学習で、210万GPU時間を消費。
メモリ要件
- 80GB GPUメモリ以上
- MoE重みを MXFP4 (4.25bit) 形式 に量子化することで、1台の80GB GPUに収まる
gpt-oss-20b の実行要件
GPU要件
- 単一GPUで動作可能。
- 16GBクラスのGPUでも限定的に動作。
メモリ要件
- チェックポイントサイズは 12.8GBと小さく、比較的手軽にロード可能。
CPU実行
- CPUでも制限付きで動作可能と記載。
- ローカルマシンやエッジ環境も条件によっては利用可能。
gpt-oss-120bとgpt-oss-20bの活用事例
最後にgpt-ossの活用事例をご紹介します。
H100環境での120b利用
gpt-oss-120bは、H100(80GBメモリ)での利用が推奨されていますが、上記ポストではH100(65GBメモリ)にて利用されています。サクサクと文章生成できていることが確認できますね。
なお、上記の関連ポストで触れられている通り、gpt-oss-120bの学習データのカットオフ日は2024年6月となっているようです。
MCPツール利用
こちらのポストでは、LM Studioにおいて、特段プロンプトで指示せずとも、モデル側が必要と判断してMCPツールを呼び出していることが確認できます。単なる推論にとどまらず、ツール呼び出しもローカル環境でしてくれるのはありがたいですね。
なお、MCPを活用した業務効率化について詳しく知りたい方は以下の記事も参考にしてみてください。

既存ページのAIラッピング
こちらのポストでは、gpt-oss-20bを使って、既存のHTMLサンプルページをAIでラッピングするデモが紹介されています。システムプロンプトに基準となるHTMLを入力して、ユーザープロンプトでアクセス情報を与えると、モデルが瞬時にHTMLを再構成して、新しいアクセスページを生成しているようです。
Groqによる推論で、毎秒1,000トークン超の応答が得られているようです。
まとめ
今回は、オープンソースで公開されたgpt-oss-120bとgpt-oss-20bについて、その性能や使い方を紹介しました。
これだけ高性能な言語モデルを自分たちの手元で制御して活用できるというのは、プライバシーやカスタマイズ性の観点で非常に価値があります。
今後はこれらのモデルをベースとして、各種タスクに特化したチューニングやさらなる高速化が進みそうで今後の展開が期待されます。
本記事を参考に、ぜひgpt-ossをお手元で試してみてください。

最後に
いかがだったでしょうか?
自社の事業に生成AIを導入する際の活用シナリオや導入設計を、gpt-ossモデルの特徴を踏まえて具体的にご提案します。
株式会社WEELは、自社・業務特化の効果が出るAIプロダクト開発が強みです!
開発実績として、
・新規事業室での「リサーチ」「分析」「事業計画検討」を70%自動化するAIエージェント
・社内お問い合わせの1次回答を自動化するRAG型のチャットボット
・過去事例や最新情報を加味して、10秒で記事のたたき台を作成できるAIプロダクト
・お客様からのメール対応の工数を80%削減したAIメール
・サーバーやAI PCを活用したオンプレでの生成AI活用
・生徒の感情や学習状況を踏まえ、勉強をアシストするAIアシスタント
などの開発実績がございます。
生成AIを活用したプロダクト開発の支援内容は、以下のページでも詳しくご覧いただけます。
➡︎株式会社WEELのサービスを詳しく見る。
まずは、「無料相談」にてご相談を承っておりますので、ご興味がある方はぜひご連絡ください。
➡︎生成AIを使った業務効率化、生成AIツールの開発について相談をしてみる。

「生成AIを社内で活用したい」「生成AIの事業をやっていきたい」という方に向けて、生成AI社内セミナー・勉強会をさせていただいております。
セミナー内容や料金については、ご相談ください。
また、サービス紹介資料もご用意しておりますので、併せてご確認ください。


